
- 1Python学习之推导式的用法(3)_使用集合推导式生成一个由元组元素构成的集合
- 2简单的嵌入式web服务器设计_嵌入式网页设计
- 3Git命令修改提交用户名和邮箱_cannot overwrite multiple values with a single val
- 4uni-app 经验分享,从入门到离职(年度实战总结:经验篇)——上传图片以及小程序隐私保护指引设置_uni.choosemedia 隐私
- 5自动驾驶 | 路径规划算法Dijkstra与A*
- 6UWP 2018 新版 NavigationView 尝鲜_uwp navigationview
- 7VRChat简易教程3-往世界里导入模型和VRC接口初探
- 8米哈游1024小解密记录(自用)_米哈游 登录 算法
- 9docker安装MongoDB(指令安装)_unable to find image 'mongo:latest' locally
- 10OpenMMLab AI实战营Day2 图像分类_openmmlab 训练分类神经网络
ESMFold conda安装、使用及与AlphaFold的简单比较_esm fold
赞
踩
前言
ESMFold 是一款由 Meta AI 团队开发的高精度蛋白质结构预测工具。它可以从单一蛋白质序列中进行端到端原子级别的结构预测,并且具有较高的准确性。相较于其他蛋白质结构预测方法,例如 AlphaFold2 和 RoseTTAFold,ESMFold 具备更快的预测速度。
(1)ESMFold官方提供安装指引较为繁琐,本文提供了conda版本的快速便捷安装方法。
(2)通过案例介绍ESMFold单个结构序列和批量结构序列的预测方法。
(3)直观比较了ESMFold与AlphaFold2.3预测结果与速度。
一、ESMFold是什么?
github:https://github.com/facebookresearch/esm
文章:https://www.biorxiv.org/content/10.1101/2022.07.20.500902v1.full.pdf
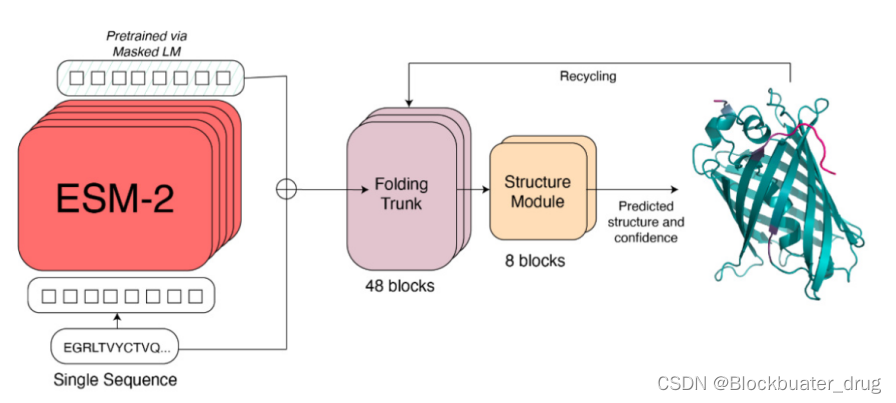
将预训练好的语言模型ESM-2的蛋白质序列embedding和attention map接入与48层folding trunk和8层Structure Module来预测蛋白质全原子的结构。这里structure module与AF2相同,而folding trunk是退化版的evoformer,因为只有单序列所以axis attention 机制就退化成了普通的self-attention,而节点与边embbeding的更新方式保持相同。
与AlphaFold2模型类似,ESMFold模型的架构也可以分为四部分:数据解析部分、编码器部分(Folding Trunk)、解码器部分(Structure Module)、循环部分(Recycling)。
ESMFold是一个完全端到端的序列结构预测方法,可以完全在GPU上运行,无需访问任何数据库。
EsmFold训练时不仅使用了PDB数据库中实验解析的单链结构,还使用了AF2预测的高置信度的蛋白结构。ESMFold和AlphaFold2之间的一个关键区别是使用语言模型表示来消除对显式同源序列(以MSA的形式)作为输入的要求。语言模型表示作为输入提供给ESMFold的折叠主干。通过将处理MSA的计算量大的Folding Block模块替换为处理序列的Tranformer模块来简化AlphaFold2中的Evoformer。这种简化或优化意味着ESMFold会比基于MSA的模型快得多。
作为大型语言模型,ESMFold的原理与ChatGPT基本相似,只不过,训练它的内容不是自然语言,而是生物基因语言。它基于语言学习模型内部表征,而不是像AlphaFold2一样基于结构和序列匹配算法,这样就消除对显式同源序列作为输入的要求,即ESMFold蛋白质模型只需一个序列作为输入。ESMFold表明可以建立语言模型与蛋白结构预测的关系,模型参数量与预测准确率的相关。
虽然ESMFold预测精度不错,尤其是预测速度很快,特别是在单序列输入的时候精度明显好于AlphaFold2。但是也有不足之处,ESMFold在多序列输入的情况下,其精度比AlphaFold2还是略有差距。
以无监督学习为目标的语言模型在一个大型的进化多样化的蛋白质序列数据库中训练,能够对蛋白质结构进行原子级的分辨率预测。将语言模型的参数扩大到15B,就可以系统地研究规模对蛋白质结构学习的影响。
ESM-2与ESMFold让我们看到,蛋白质结构预测的非线性曲线是模型规模的函数,并且观察到了语言模型对序列的理解程度与结构预测之间的强烈联系。
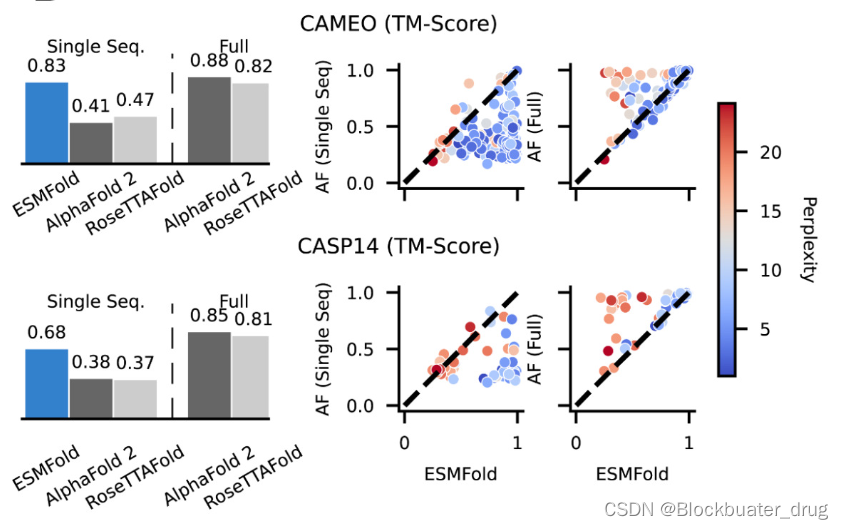
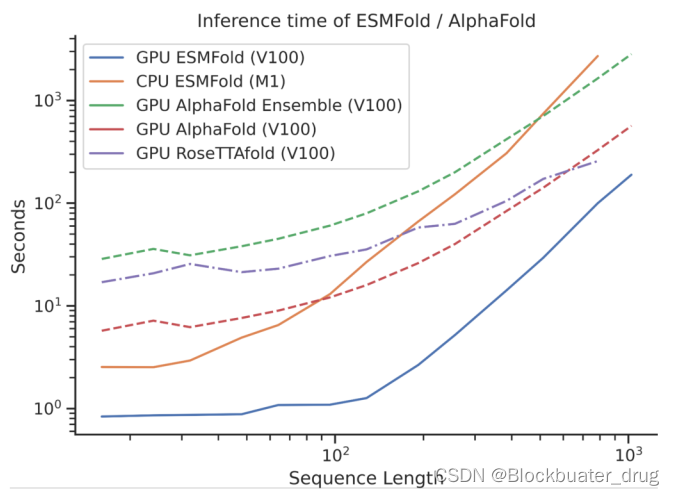
二、安装步骤
安装环境:Ubuntu 22.04, CUDA runtime版本11.8,RTX3060。
1. 确认安装环境:cuda toolkit版本
要求CUDA runtime 版本不低于 ESMFold conda安装环境的CUDA版本(如下文,cudatoolkit:11.3.*)
通过 nvcc -V命令查看CUDA runtime版本,如图为11.8。

2. 创建ESMFold conda环境并安装
采用说明文档中的environment.yml采用conda安装后, 仍需要补充一些依赖,笔者已收集到相应的安装包以及需要注意的版本匹配,可按照如下指引 conda+pip 2步安装。
Step 1:创建conda环境,下载需要的包
将以下内容保存为:conda_environment.yml,然后执行:conda env create -f conda_environment.yml,创建esmfold_env环境
name: esmfold_env channels: - conda-forge - bioconda - pytorch dependencies: - conda-forge::python=3.7 - conda-forge::setuptools=59.5.0 - conda-forge::pip - conda-forge::openmm=7.5.1 - conda-forge::pdbfixer - conda-forge::cudatoolkit==11.3.* - conda-forge::cudatoolkit-dev==11.3.* - conda-forge::einops==0.6.1 - conda-forge::fairscale - conda-forge::omegaconf - conda-forge::hydra-core - conda-forge::pandas - conda-forge::pytest - bioconda::hmmer==3.3.2 - bioconda::hhsuite==3.3.0 - bioconda::kalign2==2.04 - pytorch::pytorch=1.12.* - ehmoussi::gxx_linux-64

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Step 2:激活conda环境,继续pip安装
激活conda环境:conda activate esmfold_env
将以下内容保存为:pip_requirements.txt,然后执行:pip install -r pip_requirements.txt,完成整个安装。
biopython==1.79 deepspeed==0.5.9 dm-tree==0.1.6 ml-collections==0.1.0 numpy==1.21.2 PyYAML==5.4.1 requests==2.26.0 scipy==1.7.1 tqdm==4.62.2 typing-extensions==3.10.0.2 pytorch_lightning==1.5.10 wandb==0.12.21 biotite==0.39.0 matplotlib joblib fair-esm git+https://github.com/facebookresearch/esm.git fair-esm[esmfold] git+https://github.com/NVIDIA/dllogger.git git+https://github.com/aqlaboratory/openfold.git@4b41059694619831a7db195b7e0988fc4ff3a307
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
pip安装出现一个版本提醒,如下图,忽略即可。

3. 运行结构预测
保持 esmfold_env 激活状态。
将以下内容保存为:reproduce.py,然后执行:python reproduce.py,会完成model下载,一个示例sequence的结构预测,保存为result.pdb。65个残基的蛋白,运行时间约25s。
import torch import esm model = esm.pretrained.esmfold_v1() model = model.eval().cuda() # Optionally, uncomment to set a chunk size for axial attention. This can help reduce memory. # Lower sizes will have lower memory requirements at the cost of increased speed. # model.set_chunk_size(128) sequence = "MKTVRQERLKSIVRILERSKEPVSGAQLAEELSVSRQVIVQDIAYLRSLGYNIVATPRGYVLAGG" # Multimer prediction can be done with chains separated by ':' with torch.no_grad(): output = model.infer_pdb(sequence) with open("result.pdb", "w") as f: f.write(output) import biotite.structure.io as bsio struct = bsio.load_structure("result.pdb", extra_fields=["b_factor"]) print(struct.b_factor.mean()) # this will be the pLDDT # 88.3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
NOTE 1:
遇到的问题: reproduce.py 执行过程可能会提醒CUDA error:
 解决方法: 经过检索,一般是由错误的LD_LIBRARY_PATH引起的,在esmfold_env环境中重置即可:
解决方法: 经过检索,一般是由错误的LD_LIBRARY_PATH引起的,在esmfold_env环境中重置即可:
unset LD_LIBRARY_PATH
- 1
NOTE 2:
如果GPU显存较小而终止,可以调小chunk_size。
即去掉 reproduce.py 文件中 model.set_chunk_size(128)的注释,或者调整到64、32。
NOTE 3: model下载路径:$USER/.cache/torch/hub/checkpoints/,3个文件如下,大小约8G。
所以默认使用ESM2模型是esm2_t36_3B_UR50D,ESMFold模型是 esmfold_3B_v1。

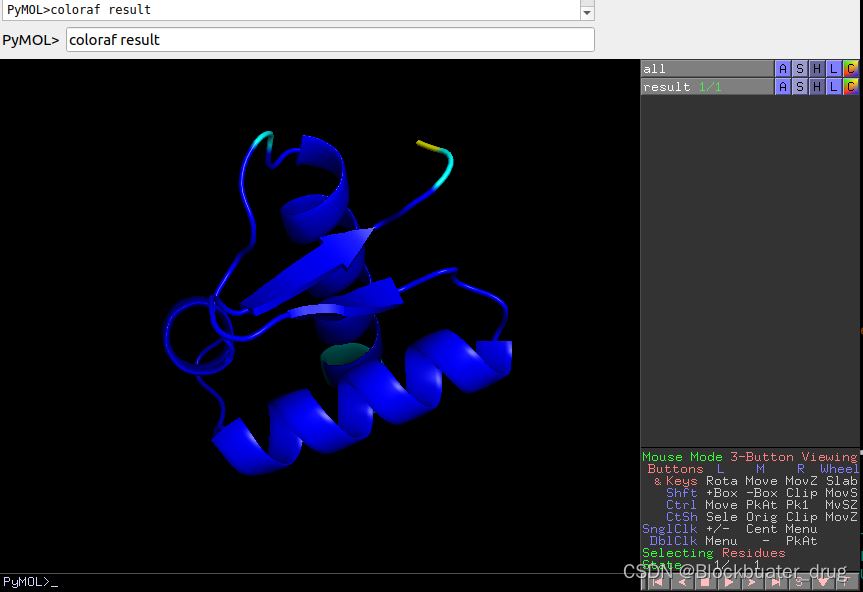
pymol查看运行结果, 根据pLDDT显示(pymol 命令行输入coloraf result):
pymol result.pdb
- 1
三、使用步骤
除了以上测试中通过python运行,也可以通过CLI方便地运行预测,即esm-fold命令,由pip从https://github.com/facebookresearch/esm.git安装,位置在esmfold_env/bin目录下。
使用esm-fold预测结构:
usage: esm-fold [-h] -i FASTA -o PDB [--num-recycles NUM_RECYCLES] [--max-tokens-per-batch MAX_TOKENS_PER_BATCH] [--chunk-size CHUNK_SIZE] [--cpu-only] [--cpu-offload] optional arguments: -h, --help show this help message and exit -i FASTA, --fasta FASTA Path to input FASTA file -o PDB, --pdb PDB Path to output PDB directory --num-recycles NUM_RECYCLES Number of recycles to run. Defaults to number used in training (4). --max-tokens-per-batch MAX_TOKENS_PER_BATCH Maximum number of tokens per gpu forward-pass. This will group shorter sequences together for batched prediction. Lowering this can help with out of memory issues, if these occur on short sequences. --chunk-size CHUNK_SIZE Chunks axial attention computation to reduce memory usage from O(L^2) to O(L). Equivalent to running a for loop over chunks of of each dimension. Lower values will result in lower memory usage at the cost of speed. Recommended values: 128, 64, 32. Default: None. --cpu-only CPU only --cpu-offload Enable CPU offloading
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1. 单个结构序列预测
以rcsb下载的pdb_8I55序列为例。
unset LD_LIBRARY_PATH
## 使用GPU
esm-fold -i rcsb_pdb_8I55.fasta -o result_rcsb_pdb_8I55.pdb
## 仅使用CPU
esm-fold -i rcsb_pdb_8I55.fasta -o cpu_result_rcsb_pdb_8I55.pdb --cpu-only
- 1
- 2
- 3
- 4
- 5
运行结果:
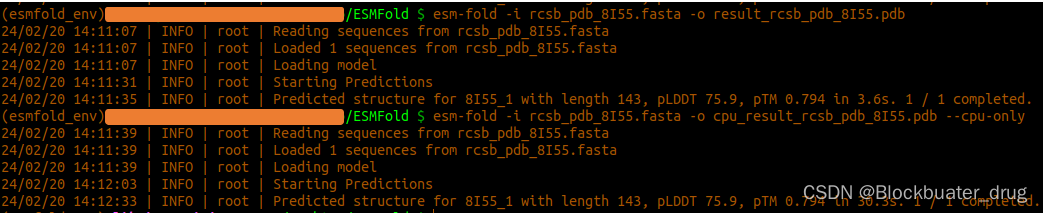
(1)143残基,GPU和CPU-only耗时分别为3.6s和30.3s,pLDDT为75.9。
(2)相对于AlphaFold,用时25min,最优结果为pLDDT为87.7。参考:AlphaFold2.3 conda版本详细安装与使用
2. 批量结构序列预测
esm-fold -i fasta_batch.fasta \
-o result_fasta_batch \
--max-tokens-per-batch 1 \
--chunk-size 128
- 1
- 2
- 3
- 4
将多个序列放进fasta_batch.fasta文件中,如果是单GPU,需要调小max-tokens-per-batch等于 1; 如果GPU显存不足,尝试调小chunk-size。

3. 与AlphaFold预测结果比较
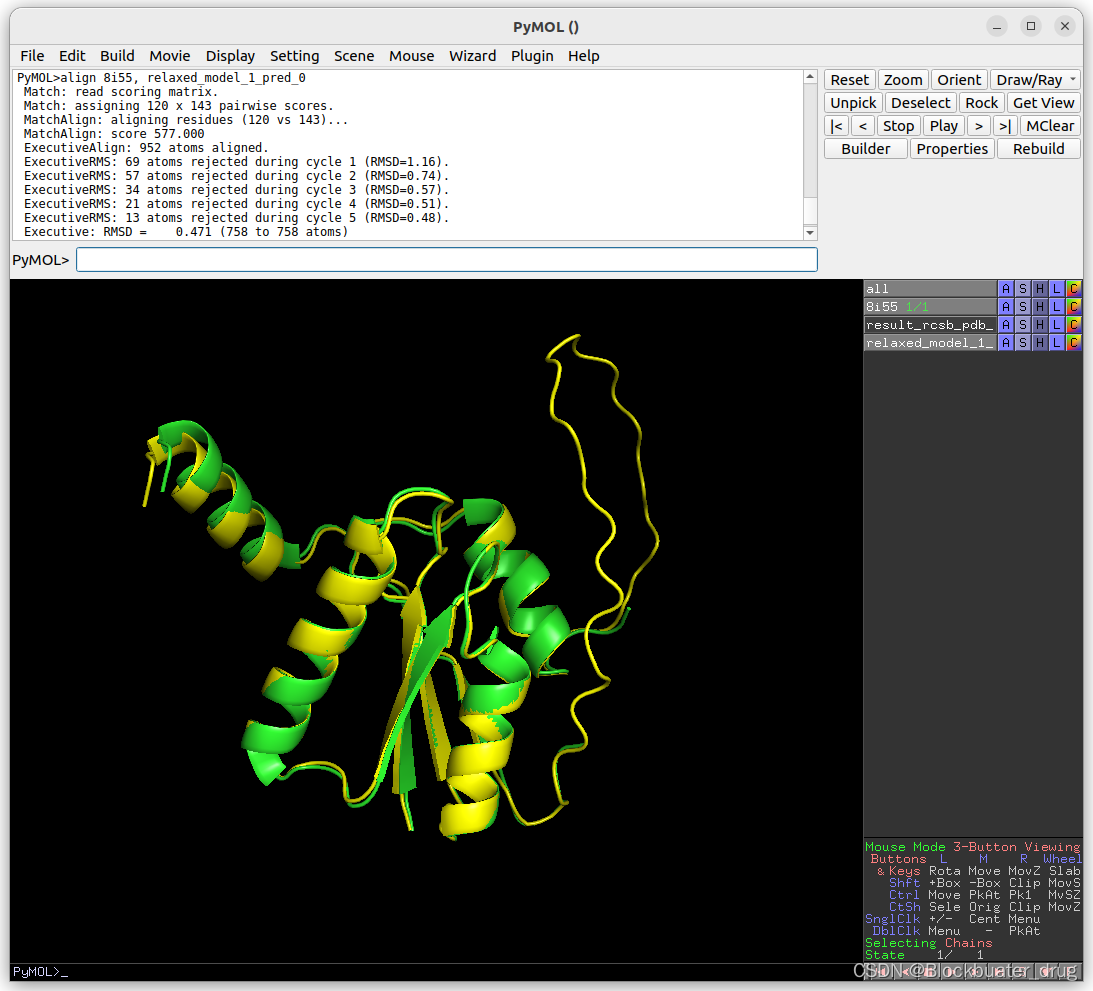
以rcsb下载的pdb_8I55序列为例,分别将AlphaFold与ESMFold预测结果与RCSB PDB 8I55 结构作比较。
AlphaFold预测可参考:AlphaFold2.3 conda版本详细安装与使用
AlphaFold预测结果与PDB 8I55的RMSD为0.471。
 ESMFold预测结果与PDB 8I55的RMSD为0.462。
ESMFold预测结果与PDB 8I55的RMSD为0.462。
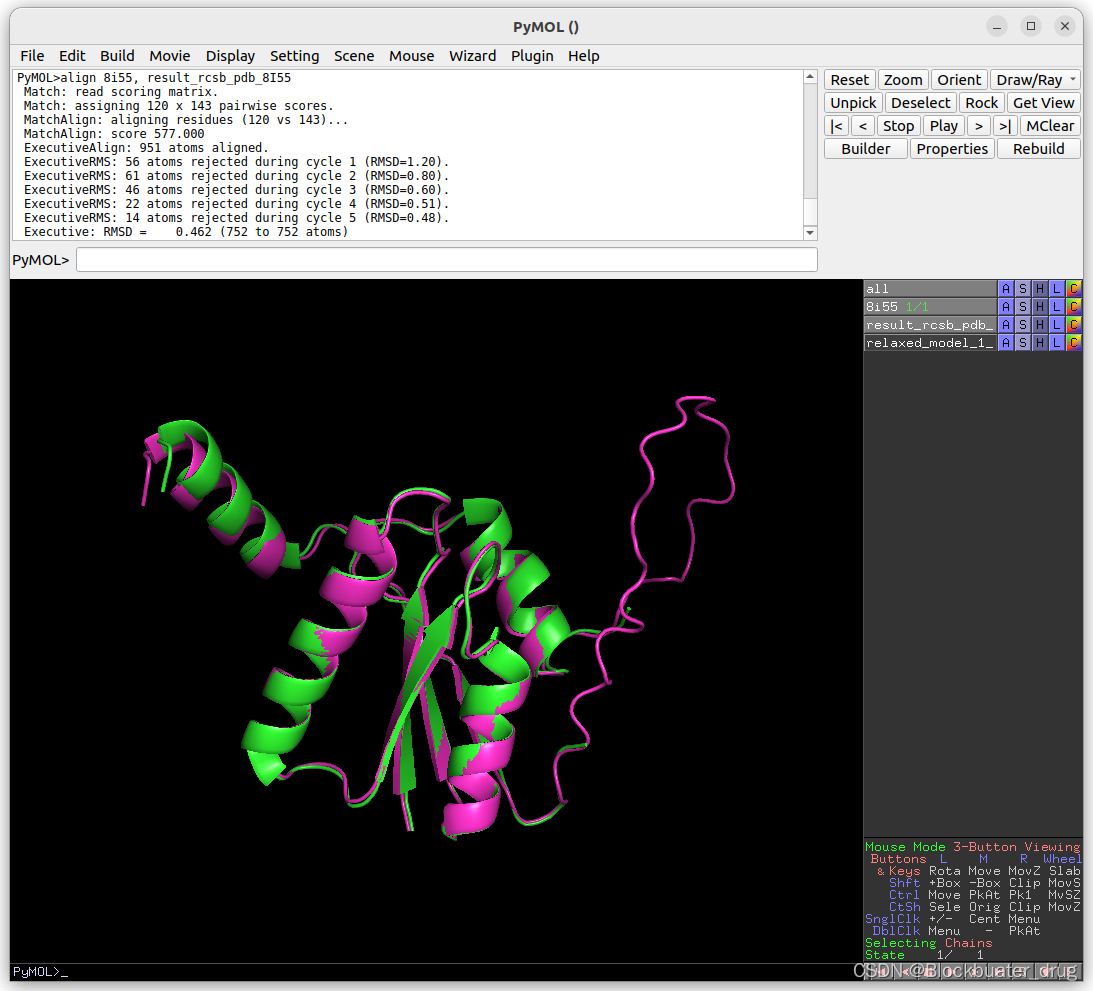
AlphaFold与ESMFold均表现良好。
总结
(欢迎关注我的CSDN: Blockbuater_drug https://bbdrug.blog.csdn.net/)
本文提供了ESMFold conda版本的快速便捷安装方法;避免官方安装指引的繁琐。
通过案例介绍ESMFold单个结构序列和批量结构序列的预测方法。
直观比较了ESMFold与AlphaFold2.3预测结果。
参考资料
- https://www.biorxiv.org/content/10.1101/2022.07.20.500902v2.full.pdf
- https://bbdrug.blog.csdn.net/article/details/135993286
- https://zhuanlan.zhihu.com/p/572904008

