
- 1大模型部署避坑指南--OSError: Unable to load weights from pytorch checkpoint file for_pytorch_model-00001-of-00002.bin
- 2Xshell 修改中文字体大小的方法
- 3【小沐学NLP】Python实现聊天机器人(ChatterBot,集成web服务)_python chatterbot 中文
- 4报错:Property or method “value“ is not defined on the instance but referenced during render. 的解决办法_property or method "value" is not defined on the i
- 5word2vec-词向量模型_代码实现word2vec词向量模型
- 6面试算法-93-交错字符串
- 7Unable to load class 'org.gradle.api.internal.component.Usage_your project may be using a third-party plugin whi
- 8售货机大数据大屏可视化设计_制作无人售货机库存分析可视化大屏
- 9QEMU安装和使用@Ubuntu(待续)
- 10CentOS7安装MySQL5.7_centos7 安装mysql 5.7
支持向量回归(SVR)的详细介绍以及推导算法
赞
踩
1 SVR背景
2 SVR原理
3 SVR数学模型
-
SVR的背景
SVR做为SVM的分支从而被提出,一张图介绍SVR与SVM的关系

这里两虚线之间的几何间隔r= d ∣ ∣ W ∣ ∣ \frac{d}{||W||} ∣∣W∣∣d,这里的d就为两虚线之间的函数间隔。
(一图读懂函数间隔与几何间隔)

这里的r就是根据两平行线之间的距离公式求解出来的

-
SVR的原理
SVR与一般线性回归的区别
| SVR | 一般线性回归 |
|---|---|
| 1.数据在间隔带内则不计算损失,当且仅当f(x)与y之间的差距的绝对值大于 ϵ \epsilon ϵ才计算损失 | 1.只要f(x)与y不相等时,就计算损失 |
| 2.通过最大化间隔带的宽度与最小化总损失来优化模型 | 2.通过梯度下降之后求均值来优化模型 |

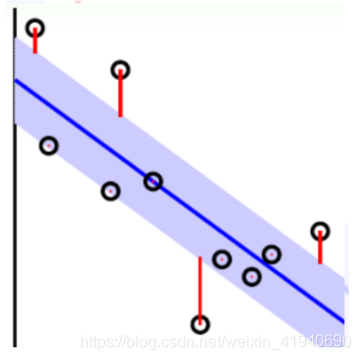
原理:SVR在线性函数两侧制造了一个“间隔带”,间距为 ϵ \epsilon ϵ(也叫容忍偏差,是一个由人工设定的经验值),对所有落入到间隔带内的样本不计算损失,也就是只有支持向量才会对其函数模型产生影响,最后通过最小化总损失和最大化间隔来得出优化后的模型。
注:这里介绍一下支持向量的含义:直观解释,支持向量就是对最终w,b的计算起到作用的样本(a>0)
如下图所示, "管道"内样本对应a=0,为非支持向量;
位于“管壁”上的为边界支持向量,0<a<
ϵ
\epsilon
ϵ
位于"管道"之外的为非边界支持向量,a>
ϵ
\epsilon
ϵ(异常检测时,常从非边界支持向量中挑选异常点)
- SVR的数学模型
3.1线性硬间隔SVR


3.2线性软间隔SVR
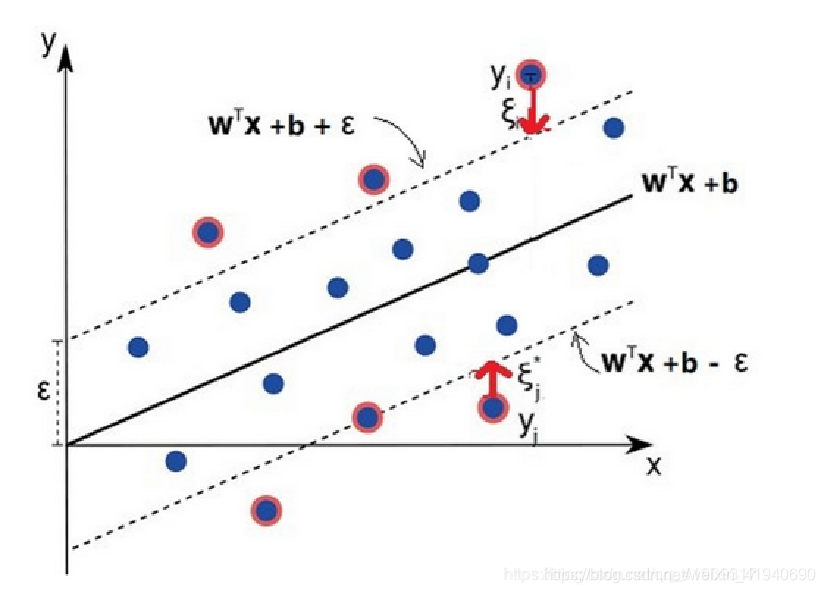
原因:在现实任务中,往往很难直接确定合适的
ϵ
\epsilon
ϵ ,确保大部分数据都能在间隔带内,而SVR希望所有训练数据都在间隔带内,所以加入松弛变量
ξ
\xi
ξ ,从而使函数的间隔要求变的放松,也就是允许一些样本可以不在间隔带内。
引入松弛变量后,这个时候,所有的样本数据都满足条件:
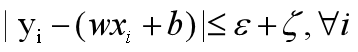
这就是映入松弛变量后的限制条件,所以也叫-------软间隔SVR
注:对于任意样本xi,如果它在隔离带里面或者边缘上,
ξ
\xi
ξ 都为0;在隔离带上方则为
ξ
>
0
,
ξ
∗
=
0
\xi>0,\xi^*=0
ξ>0,ξ∗=0
在隔离带下方则为
ξ
∗
>
0
,
ξ
=
0
\xi^*>0,\xi=0
ξ∗>0,ξ=0


参数推导:
拉格朗日乘子法(可将约束条件变成无约束的的等式方程)
设
u
i
⩾
0
,
u
i
∗
⩾
0
,
a
i
⩾
0
,
a
i
∗
⩾
0
u_i\geqslant0,u^*_i\geqslant0,a_i\geqslant0,a^*_i\geqslant0
ui⩾0,ui∗⩾0,ai⩾0,ai∗⩾0为拉格朗日系数
构建拉格朗日函数:

3.3非线性(映射,核函数)

启发:提高维度,低维映射到高维(非线性变线性)
之前的SVR低维数据模型是以内积xi*xj的形式出现:
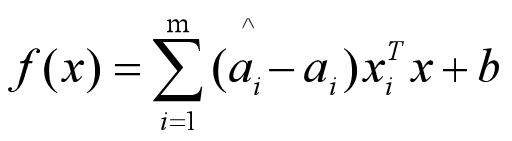
现定义一个低维到高维的映射
Φ
\varPhi
Φ: 来替代以前的内积形式:
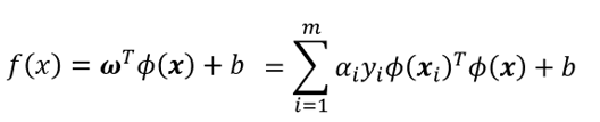
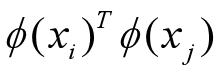
表示映射到高维特征空间之后的内积
映射到高维的问题:
2维可以映射到5维
但当低维是1000映射到超级高的维度时计算机特征的内积
这个时候从低维到高维运算量会爆炸性增长
由于特征空间维数可能很高,甚至是无穷维,因为直接计算 Φ ( x i ) T Φ ( x j ) \varPhi(x_i)^T\varPhi(x_j) Φ(xi)TΦ(xj) 通常是困难的,这里就要设计到核函数

结果表明:核函数在低维计算的结果与映射到高维之后内积的结果是一样的
主要改变:非线性转化,主要通过改变内积空间替换成另外一个核函数空间而从而转化到另外一个线性空间

核函数的隆重出场:核函数是对向量内积空间的一个扩展,使得非线性回归的问题,在经过核函数的转换后可以变成一个近似线性回归的问题


- 实战案例
代更。。。。。。。

