
- 1Llama大型语言模型原理详解_lllama 模型结构
- 2【干货来了】大语言模型训练优化秘籍
- 3计算机毕业设计Java医院诊疗信息管理(系统+源码+mysql数据库+Lw文档)_医院线上诊疗系统数据库设计
- 4C#使用StreamWriter类写入文件文件
- 5你还不知道ai智能写作小说怎么样?三个方法带你体验
- 6保姆级教程安装tensorflow对应的CUDA和CUDRNN_tensorflow和cuda版本对应
- 7【数学建模暑期培训】CUMCM历年题分类 2000-2021年数模国赛赛题及求解模型_cumcm2000b
- 8基于STM32的四旋翼无人机项目(一):基础知识篇_stm32无人机制作全过程教程
- 9Centos 7 + Openstack + PCI passthrough(透传)_please ensure all devices within the iommu_group a
- 10用简单易懂的例子解释隐马尔可夫模型_隐马尔可夫模型例子
医学图像多模态融合_医学图像处理多模态
赞
踩
多模态医学图像能够为医疗诊断、治疗规划和手术导航等临床应用提供更为全面和准确的医学图像描述。由于疾病的类型多样且复杂,无法通过单一模态的医学图像进行疾病类型诊断和病灶定位,而多模态医学图像融合方法可以解决这一问题。
融合方法获得的融合图像具有更丰富全面的信息,可以辅助医学影像更好地服务于临床应用。
融合方法分为传统方法和深度学习方法两类并总结其优缺点。结合多模态医学图像成像原理和各类疾病的图像表征,分析不同部位、不同疾病的融合方法的相关技术并进行定性比较。总结现有多模态医学图像数据库,并按分类对 25 项常见的医学图像融合质量评价指标进行概述。总结 22 种基于传统方法和深度学习领域的多模态医学图像融合算法。此外,本文进行实验,比较基于深度学习与传统的医学图像融合方法的性能,通过对 3 组多模态医学图像融合结果的定性和定量分析,总结各技术领域医学图像融合算法的优缺点。 最后,对医学图像融合技术的现状、重难点和未来展望进行讨论。
图像融合是计算机视觉和图像处理领域的一个热门课题,包括多聚焦图像融 合 、多曝光图像融合和多模态图像融合等。
图像融合过程由预处理、图像配准、图像融合和性能评价 4 部分组成。
预处理阶段:识别出图像中的噪声和伪影并完全去除,获得高质量的医学图像。然后,选取一幅参考图像,对剩余图像进行几何变换,使其与参考图像同步,获得配准后的待融合图像 ,这是与图像融合直接相关的步骤,它纠正了输入图像之间的偏差,补偿了原始信号重建、平移、旋转和缩放过程中造成的变化,从根本上保证了图像融合的精度。在融合过程中,图像融合等级按照作用的层次分为像素级、特征级和决策级,如图 1所示。像素级融合对图像像素进行综合分析,能够保持尽可能多的现场数据; 特征级融合对图像特征进行综合分析,可以压缩信息使其具有良好的实时性; 决策级融合对图像进行特征提取和特征分类,通过大量的决策系统对分类后的图像特征进行融合。

图 1 图像融合等级
计算机扫描成像(计算机断层扫描技术CT),磁共振成像(MRI)
CT 获取的图像可以提供丰富的解剖细节,MRI 能够显示丰富的生理和生化信息。
多模态融合技术(Multimodality Fusion Technology,MFT)主要包括模态表示、融合、转换、对齐技术。由于不同模态的特征向量最初位于不同的子空间中,即具有异质性,因此将影响多模态数据在深度学习领域的应用
多模态融合架构
多模态融合的主要目标是缩小模态间的异质性差异,同时保持各模态特定语义的完整性,并在深度学习模型中取得较优的性能。多模态融合架构分为: 联合架构,协同架构和编解码器架构。联合架构是将单模态表示投影到一个共享语义子空间中,以便能够融合多模态特征。协同架构包括跨模态相似模型和典型相关分析,其目标是寻找协调子空间 中模态间的关联关系。编解码器架构是将一个模态映射到另一个模态的多模态转换任务中。3 种融合架构在视频分类、情感分析、语音识别等领域得到广泛应用,且涉及图像、视频、语音、文本等融合内容。
| 架构 | 应用领域 | 融合内容 |
| 联合架构 | 视频分类 | 语音、视频、文本 |
| 事件检测 | 语音、视频、文本 | |
| 情绪分析 | 语音、视频、文本 | |
| 视觉问答 | 图像、文本 | |
| 情感分析 | 语音、视频、文本 | |
| 语音识别 | 语音、视频 | |
| 协同架构 | 跨模态搜索 | 图像、文本 |
| 图像标注 | 图像、文本 | |
| 跨模态嵌入 | 图像、视频、文本 | |
| 转移学习 | 图像、文本 | |
| 编解码器 | 图像标注 | 图像、文本 |
| 视频解码 | 视频、文本 | |
| 图像合成 | 图像、文本 |
联合架构
多模态融合策略是集成不同类型的特征来提高机器学习模型性能,消除不同模态的异质 性 差 异。联合架构是将多模态空间映射到共享语义子空间中,从而融合多个模态特征,如图 1 所示。每个单一模态通过单独编码后,将被映射到共享子空间中,遵循该策略,其在视频分类、事件检测、情感分析、视觉问答和语音识别等多模态分类或回归任务中都表现出较优的性能。

图 1 联合融合架构示意图
协同架构
多模态协同架构是将各种单模态在一些约束的作用下实现相互协同。由于不同模态包含的信息不同,因此协同架构有利于保持各单模态独有的特征和排它性,如图 2 所示。

图2 协同融合架构示意图
协同架构的优点是每 个 单 模 态 都 可 以 独 立 运行,这一特性有利于跨模式迁移学习,其目的是在不同模态或领域之间传递知识。其缺点是模态融合难度较大,使跨模态学习模型不容易实现,同时模型很难在两种以上的模态之间实现迁移学习。
编解码器架构
编解码器架构通常用于将一种模态映射到另一种模态的多模态转换任务中,主要由编码器和解码器两部分组成。编码器将源模态映射到向量 v 中,解码器基于向量 v 生成一个新的目标模态样本。该架构在图像标注、图像合成、视频解码等领域有广泛应用,如图 3 所示。
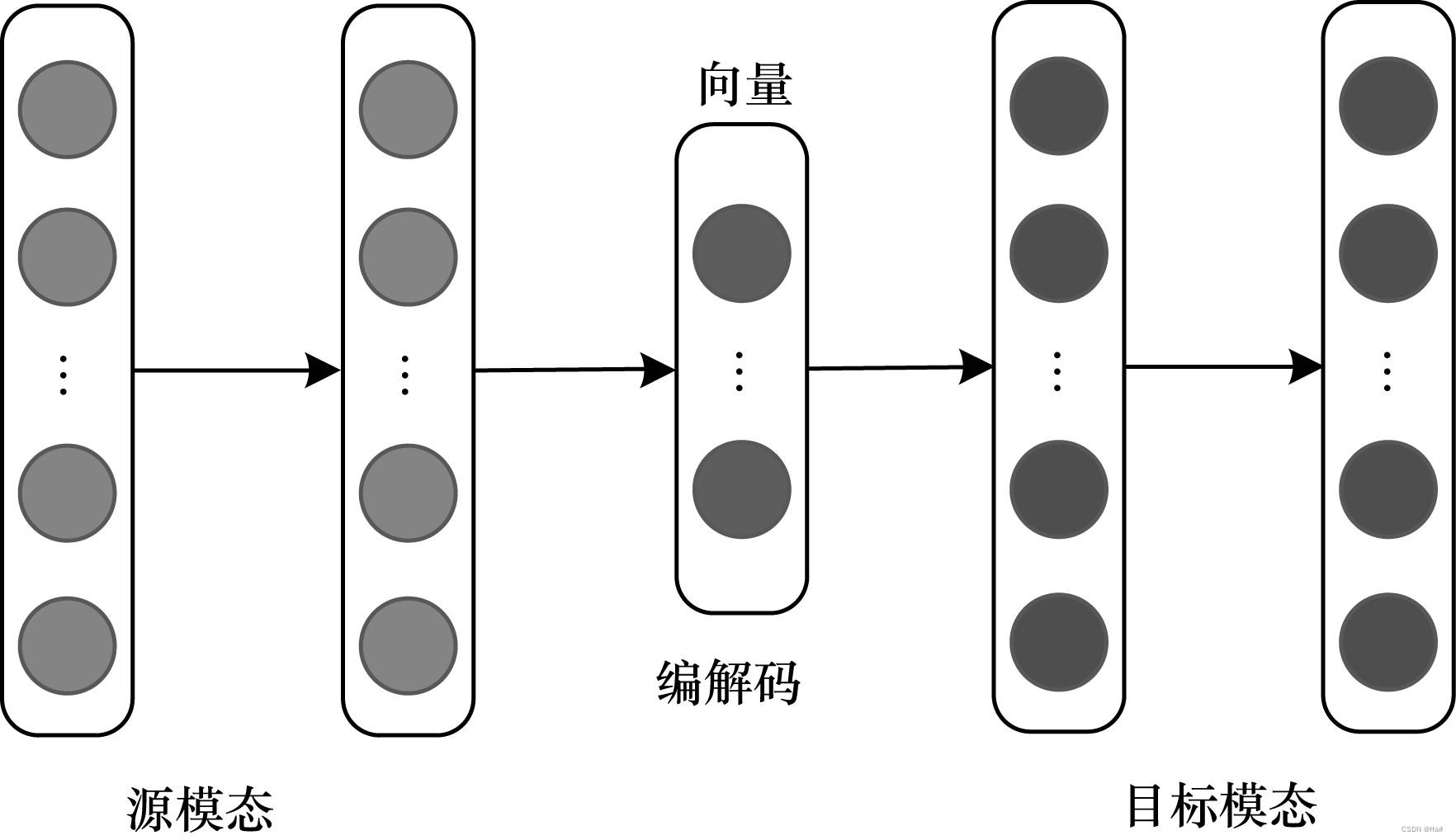
图3 编解码器融合架构示意图
多模态融合方法
| 融合方法 | 融合类型 | 输出 | 时序模型 | 典型应用 |
| 模型无关的方法 | 早期融合 | 分类 | 否 | 情感识别 |
| 晚期融合 | 回归 | 是 | 情感识别 | |
| 混合融合 | 分类 | 否 | 事件检测 | |
| 基于模型的方法 | 多核学习 | 分类 | 否 | 对象分类 |
| 分类 | 否 | 情感识别 | ||
| 图像模型 | 分类 | 是 | 双模语音 | |
| 回归 | 是 | 情感识别 | ||
| 分类 | 否 | 媒体分类 | ||
| 神经网络 | 分类 | 是 | 情感识别 | |
| 分类 | 否 | 双模语音 | ||
| 回归 | 是 | 情感识别 |
将多模态融合方法分为模型无关的方法和基于模型的方法,前 者 不 直 接 依 赖 于特定的深度学习方法,后者利 用 深 度 学 习 模 型 显 式 地 解 决 多 模态 融 合 问 题,例 如 多 核 学 习 ( M ultiple Kernel Learning,MKL ) 方 法、图 像 模 型 ( Graphical Model,GM ) 方 法 和 神 经 网 络 ( Neural Netw ork,NN )方法等
模型无关的融合方法
模型无关的融合方法可以分为早期融合( 基于特征) 、晚 期 融 合 ( 基 于 决 策) 和 混 合 融 合。早期融合在提取特征后立即集成特征( 通常只需连接各模态特征的表示) ,晚期融合在每种模式输出结果( 例如输出分类或回归结果) 后才执行集成,混合融合结合早期融合方法和单模态预测器的输出。

图4 3种模型无关的多模态融合方法
早期融合方法
为缓解各模态中原始数据间的不一致性问题,可以先从每种模态中分别提取特征的表示,然后在特征级别进行融合,即特征融合。
由于深度学习本质上会涉及从原始数据中学习特征的具体表示,从而导致有时需在未抽取特征之前就进行数据融合, 因此特征层面和数据层面的融合均称为早期融合。
模态之间通常是高度相关的,但这种相关性在特征层和数据层提取难度很大。研究人员通常采用降维技术来消除 输入空间中的冗余问题此外,多模态早期融合方法还需解决不同数据源之间的时间同步问题(如卷积、训练和池融合等,能较好地将离散事件序列与连续信号进行整合,实现模态间的时间同步。)
晚期融合方法 晚期融合方法也称为决策级融合方法,深度学习模型先对不同模态进行训练,再融合多个模型输出的结果。
该方法的融合过程与特征无关,且来自多个模型的错误通常是不相关的,因此该融合方法普遍受到关注。目前,晚期融合方法主要采用规则来确定不同模型输出结果的组合,即规则融合,例如最大值融合、平均值融合、贝叶斯规则融合以及集成学习等规则融合方法。
当模态之间相关性比较大时晚期融合优于早期融合,当各个模态在很大程度上不相关时,例如维数和采样率极不相关,采用晚期融合方法则更适合。
混合融合方法
混合融合方法结合了早期和晚期融合方法,在综合两者优点的同时,也增加了模型的结构复杂度和训练难度。
比较适合使用混合融合方法,因此在多媒体、视觉问答、手势识别等领域应用广泛。
早期融合能较好地捕捉特征之间的关系,但容易过度拟合训练数据。晚期融合能较好地处理过拟合问题,但不允许 分类器同时训练所有数据。尽管混合多模态融合方法使用灵活,但研究人员针对当前多数的体系结构需根据具体应用问题和研究内容选择合适的融合方法。
基于模型的融合方法
基于模型的融合方法是从实现技术和模型的角度解决多模态融合问题。
多核学习方法
该方法能更好地融合异构数据且使用灵活,在多目标检测、多模态情感识别和多模态情感分析等领域均具有非常广泛的应用。
图像模型方法
GM 是一种常用的多模态融合方法,主要通过图像分割、拼接和预测对浅层或深度图形进行融合,从而生成模态融合结果。GM 融合方法的优点是能够有效利用数据空间和时间结构,适用于与时间相关的建模任务,还可将人类专家知识嵌入到模型中,增强了模型的可解释性,但是模型的泛化能力有限。
神经网络方法
NN 是目前应用最广泛的方法之一,已用于各种多模态融合任务中。
视觉和听觉双模语音识别( AVSR) 是最早使用神经网络方法进行多模态融合的技术,目前神经网络方法已在很多领域得到了应用,例如视觉和媒体问答、手势识别和视频描述生成等,这些应用充分利用了神经网络方法较强的学习能力和分类性能。近期神经网络方法通过使用循环神经网络( RNN ) 和长短 期 记 忆 网络( LSTM ) 来融合时间多模态信息,有研究使用 LSTM 模型进行连续多模态情感识别,相对于 MKL 和 GM 方法表现出更优的性能。此外,神经网络多模态融合方法在图像字幕处理任务中表现良好,主要模型包括神经图像字幕模型、多视图模型等。神经网络方法在多模态融合中的优势是具备大数据学习能力,其分层方式有利于不同模态的嵌入,具有较好的可扩展性,但缺点是随着模态的增多,模型可解释性变差。
多模态对齐方法
多模态对齐是多模态融合的关键技术之一,指从两个或多个模态中查找实例子组件之间的对应关系。例如,给定一个图像和一个标题,需找到图像区域与标题单词或短语的对应关系。多模态对齐方法分为显式对齐和隐式对齐。显式对齐关注模态之间子组件的对齐问题,而隐式对齐则是在深度学习模型训练期间对数据进行潜在对齐。


