
深度强化学习
赞
踩
策略学习:用神经网络来近似策略函数Π(a|s)
用策略网络Π(a|s;θ)去近似策略函数Π(a|s);
其中θ为神经网络的训练参数
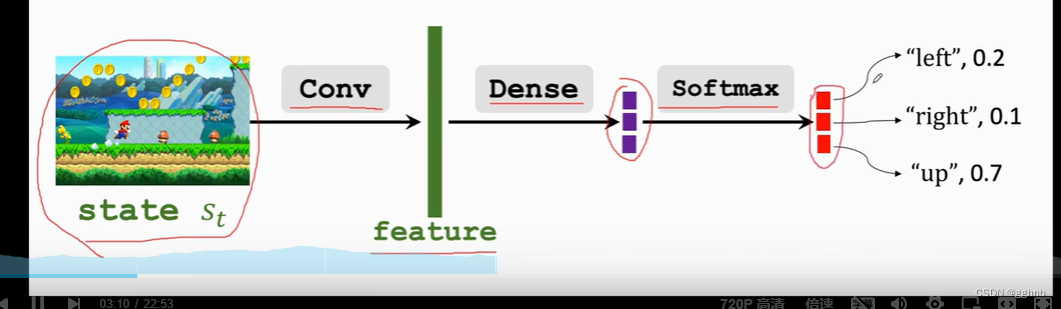
改进参数θ使得模型越变越好
改进θ使用Policy gradient ascent(策略梯度上升)
观察状态s
用以下公式更新θ:![]()
其中v(s;θ)表示状态价值函数,β表示学习率,而 叫做策略梯度。
叫做策略梯度。

可以通过下面两个公式计算策略梯度(第一种适合动作离散,第二种适合连续)

Actor-Critic Methods(策略学习+价值学习)

用以下步骤同时更新两个参数θ和w

算法总结

蒙特卡洛树搜索:
1.selection:玩家自己走一步action(假设走)
2.expansion:对手根据police network也走一步,更新状态(假设走)
3.evaluation:价值网络给当前状态打分为v,玩游戏到结束收到奖励r,把(v+r)/2当作动作a的打分
4.backup:用(v+r)/2更新动作价值函数
细说:1.selection
(1) 首先给每个动作a打一个分数
![]()
其中Q(a)为动作价值(初始默认为0,初始完全由策略网络决定)
Π为police network给动作a打的分
N(a)为动作a被探索的次数,随着a探索次数越来越多,分数主要有Q(a)决定
η为参数,手动调整
(2)选择分数最高的动作a
2.expansion
用策略函数Π来代替状态转移函数,并根据随机抽样选出对手的下一步a‘
3.evaluation
自博弈,玩完游戏最后得到奖励r,win:r=1,loss:r=-1
把s(t+1)给价值网络获得分数v(s(t+1);w)
上述两个值求平均记录为当前状态分数
4.backup
把一个动作后面的所有状态的得分求平均作为当前动作a的得分Q(a)


