
- 1chatgpt赋能python:用Python快速替换文本的技巧_python替换文本内容
- 2如何选择终端桌面管理软件?
- 3一、奇妙插件Tampermonkey的简单安装教程
- 4Faiss的基本使用_faiss 使用
- 5高标清4K音视频编码处理平台JR600系列
- 6SpringCloudGateway 3.1.4版本 Netty内存泄漏问题解决_netty-common-4.1.43.final.jar版本有内存泄漏吗
- 7【附源码】Java计算机毕业设计基于微信小程序的校园跑腿系统(程序+LW+部署)_计算机毕业设计 java校园跑腿平台设计与实现
- 8发胶行业调研报告 - 市场现状分析与发展前景预测(2021-2027年)_发胶 分析
- 9c——通讯录的模拟
- 10Android4.0 G-Sensor工作流程_gsensor reset
NLP算法岗面试知识点总结_nlp面经l1和l2正则
赞
踩
1.梯度下降做线性回归求解; 参数优化 ; 参数都初始化为0时有啥问题 ;逻辑回归和线性回归的本质区别
参数都初始化为0的问题
w初始化全为0,使得在反向传播的过程中所有参数结点可能变得相同,进而很可能直接导致模型失效,无法收敛。因此应该把参数初始化为随机值。
逻辑回归和线性回归的本质区别
- 逻辑回归引入了sigmoid函数,这是一个非线性函数,增加了模型的表达能力
- 逻辑回归输出有限离散值,可以用来解决概率问题、分类问题等。
- 两者使用的成本函数不同,线性回归使用的平方差,逻辑回归使用的是对数损失函数(更本质来讲,线性回归使用最小二乘方法、或梯度下降方法进行成本函数的求解,而逻辑回归使用最大似然方法进行求解)
2.损失函数有哪些;多分类下softmax的损失函数;softmax交叉熵反向推到公式
2.1 损失函数有哪些
- 平方损失(预测)
- 交叉熵(分类问题)
- hinge损失(SVM支持向量机)
- CART回归树的残差损失
2.2 多分类下的softmax损失函数
L = ∑ i N ∑ k = 1 C y ( i k ) l o g ( y ^ ( i k ) ) L = \sum{_{i}^{N}}\sum{_{k=1}^{C}}y^{(ik)}log(\hat{y}^{(ik)}) L=∑iN∑k=1Cy(ik)log(y^(ik))
2.3 softmax交叉熵反向推导公式
3.self-attention的公式;self-attention的作用;Attntion的作用;
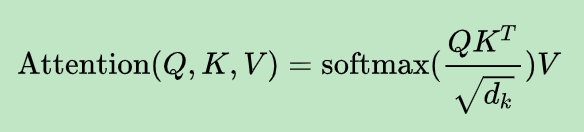
self-attention的作用
自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
4.梯度消失、梯度爆炸的原因和解决方案
4.1 梯度消失和梯度爆炸的原因
反向传播算法中要对激活函数进行求导,如果此部分大于1,那么神经网络层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着神经网络层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。梯度消失也和激活函数的选择有很大关系,如果激活函数选择不合适,在进行链式求导的时候其结果小于1,就非常容易发生梯度消失。
4.2 梯度消失和梯度爆炸的解决方案
-
预训练加微调
-
加入正则化
-
梯度修剪
-
选择合适的激活函数,relu、leakrelu、elu等激活函数
-
batchnorm
Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。
-
LSTM
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates),如下图,LSTM通过它内部的“门”可以接下来更新的时候“记住”前几次训练的”残留记忆“,因此,经常用于生成文本中。
5.Word2vec,BERT,ELMo详细介绍;BERT微调 ;BERT如何使用transformer的encoding模块;BERT的输入和transformer有什么不同;BERT有什么缺点;transformer中attention和self-attention机制;BERT为什么只用Transformer的Encoder而不用Decoder;
5.1 解读Transformer, 一篇文章解决

5.2 解读BERT
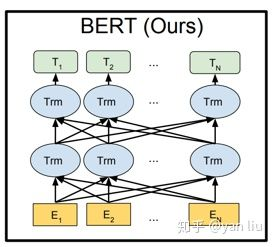
上图中的Trm就对应Transformer结构中左侧的Transformer Block。其中的
T
1
,
T
2
,
.
.
.
,
T
N
T_{1}, T_{2},..., T_{N}
T1,T2,...,TN对应的就是由BERT得到的词向量。
5.3 BERT的微调策略
-
预训练的长本文,因为Bert的最长文本序列是512
-
层数选择,每一层都会捕获不同的信息,因此我们需要选择最适合的层数
-
过拟合问题,因此需要考虑合适的学习率。Bert的底层会学习到更多的通用的信息,文中对Bert的不同层使用了不同的学习率。 每一层的参数迭代可以如下所示:
θ t l = θ t l − 1 − \theta_{t}^{l}=\theta_{t}^{l-1}- θtl=θtl−1−
5.4 BERT如何使用transformer的encoding模块
5.5 BERT的输入和transformer有什么不同
与Transformer本身的Encoder端相比,BERT的Transformer Encoder端输入的向量表示,多了Segment Embeddings。
5.5.1 BERT的输入是包括三部分

- wordpiece-token向量
- 位置向量:512个。训练
- 段向量:sentence A B两个向量。训练
- 一些符号:
- CLS:special classification embedding,用于分类的向量,会聚集所有的分类信息
- SEP:输入是QA或2个句子时,需添加SEP标记以示区别
- E A E_{A} EA 和 E B E_{B} EB:输入是QA或2个句子时,标记的sentence向量。如只有一个句子,则是sentence A向量
5.5.2 Transformer的输入
Transformer的输入涉及到两个部分既word embedding 和position embedding。没有段向量以CLS和SEP标识符。
5.6 BERT的缺点
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- BERT在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,然而有时候这些单词之间是有关系的。
- BERT的在预训练时会出现特殊的[MASK],但是它在下游的fine-tune中不会出现,这就出现了预训练阶段和fine-tune阶段不一致的问题。
- 另外还有一个缺点,是BERT在分词后做[MASK]会产生的一个问题,为了解决OOV的问题,我们通常会把一个词切分成更细粒度的WordPiece。
6.为什么使用交叉熵,不用平方差;手写交叉熵公式;手推Softmax交叉熵损失函数;
6.1 为什么使用交叉熵而不用平方差
在激活函数是sigmoid之类的函数的时候,用平方损失的话会导致误差比较小的时候梯度很小,这样就没法继续训练了,这时使用交叉熵损失就可以避免这种衰退
6.2 交叉熵公式(二分类)
单个样本的损失函数
y ^ = P ( y = 1 ∣ x ) \hat{y} = P(y=1|x) y^=P(y=1∣x)
1 − y ^ = P ( y = 0 ∣ x ) 1-\hat{y} = P(y=0|x) 1−y^=P(y=0∣x)
从极大似然情况组合以上两个公式
P ( y ∣ x ) = y ^ y ⋅ ( 1 − y ^ ) 1 − y P(y|x)=\hat{y}^y \cdot (1-\hat{y})^{1-y} P(y∣x)=y^y⋅(1−y^)1−y
l o g ( P ( y ∣ x ) ) = l o g ( y ^ y ⋅ ( 1 − y ^ ) 1 − y ) = y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) log(P(y|x)) = log(\hat{y}^y \cdot (1-\hat{y})^{1-y}) = y log\hat{y} + (1-y) log(1-\hat{y}) log(P(y∣x))=log(y^y⋅(1−y^)1−y)=ylogy^+(1−y)log(1−y^)
所有样本的损失函数
我们期望 l o g ( P ( y ∣ x ) ) log(P(y|x)) log(P(y∣x)) 越大越好,所以既有下列损失函数,使得 L L L 越小越好。
L = ∑ − [ y ( i ) l o g y ^ ( i ) + ( 1 − y ( i ) ) l o g ( 1 − y ^ ( i ) ) ] L=\sum{-[y^{(i)} log\hat{y}^{(i)} + (1-y^{(i)}) log(1-\hat{y}^{(i)})]} L=∑−[y(i)logy^(i)+(1−y(i))log(1−y^(i))](二分类的交叉熵损失函数)
L = − ∑ i N ∑ c = 1 M y ( i ) l o g ( y ^ ( i ) ) L = -\sum{_{i}^{N}\sum_{c=1}^{M}}y^{(i)}log(\hat{y}^{(i)}) L=−∑iNc=1∑My(i)log(y^(i)) (多分类的交叉熵损失函数)
其他文章对交叉熵函数的一些解释


6.3 手推Softmax交叉熵损失函数
7.降维(PCA)的原理以及涉及的公式;
8.Bagging和Boosting的区别;XGBoot,LGB 和 GBDT的区别;LSTM各类门结构;GBDT和RF (随机森林) 的区别;
8.1 Bagging 和 Boosting的区别
8.1.1 Bagging
Bagging 的核心思路是——民主。
Bagging 的思路是所有基础模型都一致对待,每个基础模型手里都只有一票。然后使用民主投票的方式得到最终的结果。
具体的过程:
- 从原始样本集中使用Bootstraping 方法随机抽取n个训练样本,共进行k轮抽取,得到k个训练集(k个训练集之间相互独立,元素可以有重复)。
- 对于k个训练集,我们训练k个模型,(这个模型可根据具体的情况而定,可以是决策树,knn等)
- 对于分类问题:由投票表决产生的分类结果;对于回归问题,由k个模型预测结果的均值作为最后预测的结果(所有模型的重要性相同)。

8.1.2 Boosting
Boosting 的核心思路是——挑选精英。
Boosting 和 bagging 最本质的差别在于他对基础模型不是一致对待的,而是经过不停的考验和筛选来挑选出「精英」,然后给精英更多的投票权,表现不好的基础模型则给较少的投票权,然后综合所有人的投票得到最终结果。
具体过程:
- 通过加法模型将基础模型进行线性的组合。
- 每一轮训练都提升那些错误率小的基础模型权重,同时减小错误率高的模型权重。
- 在每一轮改变训练数据的权值或概率分布,通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
8.1.3 Bagging 和 Boosting 的 4 点差别
样本选择上:
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
- Bagging:使用均匀取样,每个样例的权重相等
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
- Bagging:各个预测函数可以并行生成
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
8.2 XGBoot,LGB 和 GBDT的区别
9.SGD 和 min-SGD的区别
-
随机梯度下降 (SGD):相对于梯度下降,可以看到多了随机两个字,随机也就是说我每次用样本中的一个例子来近似我所有的样本,用这一个例子来计算梯度并用这个梯度来更新 θ \theta θ。因为每次只用了一个样本因而容易陷入到局部最优解中。
-
批量随机梯度下降 (mini-SGD):他用了一些小样本来近似全部的,其本质就是1个样本的近似不一定准,那就用更大的30个或50个样本来近似。将样本分成m个mini-batch,每个mini-batch包含n个样本;在每个mini-batch里计算每个样本的梯度,然后在这个mini-batch里求和取平均作为最终的梯度来更新参数;然后再用下一个mini-batch来计算梯度,如此循环下去直到m个mini-batch操作完就称为一个epoch结束。
10.CRF, HMM的细节
CRF和HMM并不是多么明白。
利用中文分词实例讲解HMM
http://yanyiwu.com/work/2014/04/07/hmm-segment-xiangjie.html
两者的区别
- HMM是生成模型,CRF是判别模型
- HMM是概率有向图,CRF是概率无向图
- HMM求解过程可能是局部最优,CRF可以全局最优
- CRF概率归一化较合理,HMM则会导致label bias 问题
11.优化器系统的讲一下
12.L1 L2正则化;
-
L1正则化指的是权值向量 w w w 中各个元素的绝对值之和,通常表示为 ∣ ∣ w ∣ ∣ 1 ||w||_{1} ∣∣w∣∣1
-
L2正则化指的是权值向量 w w w 中各个元素的平方和然后再求平方根,通常表示为 ∣ ∣ w ∣ ∣ 2 ||w||_{2} ∣∣w∣∣2
-
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
-
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
13.SVM了解吗?有什么优点?优化方法?
SVM的优点
- 解决小样本下机器学习问题。
- 解决非线性问题。
- 无局部极小值问题。(相对于神经网络等算法)
- 可以很好的处理高维数据集。
- 泛化能力比较强。
SVM缺点
- 对于核函数的高维映射解释力不强,尤其是径向基函数。
- 对缺失数据敏感。
14.什么是过拟合?产生的原因?如何解决?
定义: 过拟合就是模型在训练集上表现很好,能对训练数据充分拟合,误差也很小,但是在训练集上表现很差,泛化性不好。
产生原因:数据不够,模型太复杂
- L1和L2正则化
- dropout
- 提前停止
- 数据集扩增
- 简化网络结构
- 使用boosting或者bagging方法
15.精确率 § / 召回率 ® / F1值
16.反向传播算法的意义是什么?
- 反向传播技术,使得训练深层神经网络成为可能
- 反向传播技术是先在前向传播中计算输入信号的乘积及其对应的权重,然后将激活函数作用于这些乘积的总和。这种将输入信号转换为输出信号的方式,是一种对复杂非线性函数进行建模的重要手段,并引入了非线性激活函数,使得模型能够学习到几乎任意形式的函数映射。然后,在网络的反向传播过程中回传相关误差,使用梯度下降更新权重值,通过计算误差函数E相对于权重参数W的梯度,在损失函数梯度的相反方向上更新权重参数。
17.各种优化算法
18. K-Means算法流程
从数据集中随机选择K个聚类样本作为初始的聚类中心,然后计算数据集中每个样本到这K个聚类中心的距离,并将此样本分到距离最小的聚类中心所对应的类中。将所有样本归类后,对于每个类别重新计算每个类别的聚类中心既每个类中所有样本的质心,重复以上操作直到聚类中心不变为止。
19. RNN;LSTM;GRU;结构以及计算公式
RNN
s
t
=
t
a
n
h
(
U
x
t
+
W
s
t
−
1
)
o
t
=
s
o
f
t
m
a
x
(
V
s
t
)
s_{t} = tanh(Ux_{t}+Ws_{t-1})\\ o_{t} = softmax(Vs_{t})
st=tanh(Uxt+Wst−1)ot=softmax(Vst)
LSTM
- 遗忘门
f t = s i g m o i d ( W f h t − 1 + U f x t + b f ) f^{t} = sigmoid(W_fh^{t-1}+U_{f}x^{t}+b_{f}) ft=sigmoid(Wfht−1+Ufxt+bf) - 输入门
i t = s i g m o i d ( W i h t − 1 + U i x t + b i ) a t = t a n h ( W a h t − 1 + U a x t + b a ) i^t = sigmoid(W_ih^{t-1}+U_{i}x^t+b_i)\\ a^t = tanh(W_ah^{t-1}+U_{a}x^t+b_a) it=sigmoid(Wiht−1+Uixt+bi)at=tanh(Waht−1+Uaxt+ba) - 输出门
o t = s i g m o i d ( W o h t − 1 + U o x t + b o ) h t = o t ⊙ t a n h ( c t ) o^t = sigmoid(W_{o}h^{t-1}+U_ox^t+b_o)\\ h^t=o^t \odot tanh(c^t) ot=sigmoid(Woht−1+Uoxt+bo)ht=ot⊙tanh(ct)
20. SVM相关
什么是支持向量机?
支持向量机是一个二分类模型,他的基本模型定义为特征空间上的间隔最大的线性分类器。而他的学习策略为最大化分类间隔,最终可以转化为凸二次规划问题求解。SVM的目标是寻找一个最优化超平面在空间中分割两类数据,这个最优的超平面需要满足的条件是:离其最近的点到其的距离最大化,这些点也称为支持向量
SVM什么时候用线性核什么时候用高斯核
- 线性核
在特征提取的较好,所包含的信息足够,很多问题是线性可分的。那么就采用线性核 - 高斯核
特征数较少,样本数量适中。对于时间问题不敏感,遇到的问题是线性不可分的时候使用高斯核。
SVM的优化目标函数

SVM的损失函数
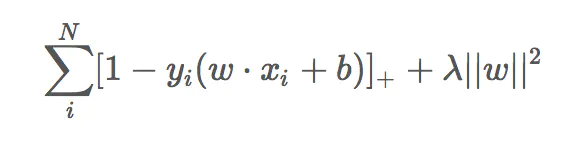
SVM引入对偶函数的目的
- 方便引入核函数
- 原问题的求解复杂度与特征的维数相关,而转成对偶问题后只与变量个数相关。由于SVM的变量个数为支持向量的个数,相较于特征数较少,因此转为对偶问题。
SVM和LR的区别
-
LR是参数模型,而SVM是非参数模型.
在统计学中,参数模型通常假设总体服从某个分布,这个分布可以由一些参数确定,如正态分布由均值和标准差确定,在此基础上构建的模型称为参数模型;非参数模型对于总体的分布不做任何假设或者说是数据分布假设自由,只知道其分布是存在的,所以就无法得到其分布的相关参数,只能通过非参数统计的方法进行推断。所以说,参数模型和非参数模型中的“参数”并不是模型中的参数,而是数据分布的参数。
-
LR采用的损失函数是logistical loss,而SVM采用的是合页损失
-
在学习分类器时,SVM只是考虑少量支持向量点,而LR是考虑所有的点
完整推导SVM
21. 强化学习相关
各种trick
- 引入了卷积层
- Experience Replay
- 用DQN网络辅助训练
- Double DQN
- Dueling DQN
22. K-means相关
算法流程:
- 从 n个数据对象任意选择 k 个对象作为初始聚类中心;
- 循环2到3直到每个聚类不再发生变化为止
- 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
- 重新计算每个(有变化)聚类的均值(中心对象)
缺点
- K-means是局部最优的,容易受到初始质心的影响;
- K的取值会影响最后的聚类结果,最优聚类的K值应与样本数据本身的结构信息相吻合,而这种结构很难去掌握,因此选取最优的K值也是非常困难的。
K值的确定
23. 集成学习相关
bagging和boosting的区别
1. 样本的选取
bagging采取有放回的采样方式得到训练弱分类器的训练集;boosting则会考虑所有的样本,但是每次训练样本的权重不一样,权重值会根据上一轮的分类结果做调整。
2. 样例权重
bagging是均匀取样,样本的权重一样;boosting会根据错误率调整权重,错误率越大权重值越大。
3. 预测函数
bagging的预测函数间是平等的权重相同,最后的预测结果通过类似于投票的方式得到;boosting的每个弱分类器都有对应的权重,对于分类误差小的分类器会有更大的权重。
4. 并行计算
bagging的各个分类器可以并行生成;boosting只能顺序生成,因为后一个模型参数需要前一轮模型的训练结果。
XGBoost特征并行化
xgboost的并行是在特征粒度上的。决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,这个block结构使得并行成为了可能。在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
XGBoost和GBDT的区别
- GBDT在优化过程中通过泰勒近似使用的是一阶导数信息,而XGBoost使用了一阶和二阶的信息。
- XGBoost在损失函数中加入了正则项。这个正则项是树叶子结点个数以及每个叶子结点上的输出值的L2平方和。
- XGBoost在处理每个特征列时可以做到并行。
- GBDT的结点分裂方式是使用gini系数,XGBoost通过优化推导出分裂结点前后的增益值来选择是否分裂当前结点。
- 对于缺失的样本,XGBoost可以自动学习出他的分裂方向。
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
AdaBoost和GBDT的区别
Adaboot是不断调整样本的权重和学得的弱分类器的权重来得到最后的分类模型;而GBDT是通过拟合负梯度来得到最后的模型,尤其是当GBDT中选择的损失函数是方差时,计算损失函数函数的负梯度值在当前模型的值就是残差。
Adaboost和RF的区别
- 数据集选取的不同。Adaboost改变了训练数据的权重,也就是样本的概率分布,减少上一轮被正确分类的样本的权重,提高被错误分类的样本的权重;而随机森林是挑选一部分数据训练每一个弱分类器
- 在对新数据预测的不同。Adaboost是所有树加权相加相加进行预测。而随机森林是所有树的预测结果按照少数服从多数的原则进行预测。
RF和GBDT的区别;执行原理的不同
执行原理的不同:
- GBDT的执行核心是通过分类器(CART\RF)拟合损失函数的负梯度,而损失函数的定义就决定了在子区域内的步长,其中就是期望输出与分类器预测输出的差值。
- RF的核心是自采样 (样本随机采样,有放回的随机抽取M个样本组成本弱分类器的训练集) 和随机属性(所有样本中随机选取K和属性/特征来划分)
两者的相同点:
- 都有多颗树组成
- 最后的结果也是由多棵树一起决定
两者的区别
- RF是bagging算法而GBDT是boosting算法;
- 组成随机森林的树可以是分类树,也可以是回归树。但是GBDT的只能是回归树;
- 组成RF的多个树可以并行生成;而GBDT的只能是串行生成;
- 对于最后的输出结果而言,随机森林采用多数投票;而GBDT则是将所有结果累加起来或者加权累加起来;
- RF对异常值不敏感,但是GBDT对异常值非常敏感。
XGBoost和lightGBM的区别和适用场景
- XGBoost使用的是预排序算法,能够更精确的找到数据分隔点;LightGBM使用的是直方图算法,占用的内存更低,数据分隔的复杂度更低。
- XGBoost采用的是level(depth)-wise生长策略,能够同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合;但不加区分的对待同一层的叶子,带来了很多没必要的开销。LightGBM采用leaf-wise生长策略,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环;但会生长出比较深的决策树,产生过拟合。
24. Tensorflow相关
tensorflow的工作原理
Tnesorflow是用数据流图来进行数值的计算的,而数据流图是描述有向图的数值计算过程。在有向图中,结点表述为数学运算,边表示为传输多维数据,节点也可以被分配到计算设备上并行的执行操作。
25. TF-IDF
其主要思想是:如果在一篇文章中一个词的出现频率高,并且语料库中其他文章包含这个词的概率小,那么这个词可以被选作关键词使用。
TF
T
F
=
n
i
∑
n
i
TF = \frac{n_i}{\sum{n_i}}
TF=∑nini
n
i
n_i
ni:一篇文章中一个词出现的次数
∑
n
i
\sum{n_i}
∑ni:这篇文章的总词数
可以看出一个词的TF值随着它在这篇文章中出现频率的增加而增加。
IDF
在其他文章出现的频率(Inverse Document Frequency)很少的词应该比出现频率高的词更有代表性
I
D
F
=
l
g
∣
D
∣
∣
j
:
t
i
∈
d
j
∣
+
1
IDF = lg\frac{|D|}{|j:t_i\in d_j|+1}
IDF=lg∣j:ti∈dj∣+1∣D∣
|D|: 语料库中的文件总数
∣
j
:
t
i
∈
d
j
∣
+
1
|j:t_i\in d_j|+1
∣j:ti∈dj∣+1: 包含这个词语的文章总数
注:+1的目的是防止这个词语在语料中没有出现导致分母为0的问题
TF-IDF
一个词的IDF值随着语料库中包含这个词的文章数目的减小而增大
T F − I D F = T F ∗ I D F TF-IDF = TF*IDF TF−IDF=TF∗IDF
#定义TF-IDF的计算过程
def D_con(word, count_list):
D_con = 0
for count in count_list:
if word in count:
D_con += 1
return D_con
def tf(word, count):
return count[word] / sum(count.values())
def idf(word, count_list):
return math.log(len(count_list)) / (1 + D_con(word, count_list))
def tfidf(word, count, count_list):
return tf(word, count) * idf(word, count_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
深度学习 (一)
这里主要对牛客网的面经中不熟悉的点再手敲一遍,加深记忆。
1.Batchnormallization的作用
由于神经网络层数的加深,在反向传播时底层的神经网络可能发生梯度消失的问题,BatchNormalization的作用就是规范化输入,把不规范的分布拉到正态分布,使得数据能够分布在激活函数的敏感区域。进而可以使得梯度变大,加快学习的收敛速度,避免梯度消失的问题。
2.梯度消失
由于激活函数选取不合适,在反向传播的过程中,梯度值趋于0,无法有效的反向传播,进而导致梯度消失。
3.循环神经网络,为什么好
RNN 利用内部的记忆机制来处理任意序列的输入序列,并且在处理单元之间既有内部的反馈链接又有前馈链接,这使得RNN可以更容易处理不分段的文本内容。
4.什么是Group Convolutional
若卷积神经网络的上一层有N个卷积核,则对应的通道数也为N。设群体数目为M,在进行卷积操作的时候,那么该群卷积层的操作就是,先将channel分成M份。每一个group对应N/M个channel,与之独立连接。然后各个group卷积完成后将输出叠在一起(concatenate),作为这一层的输出channel。
5.什么是RNN
一个序列中的当前输出不仅和当前的输入和前一个时间序列的输出有关,还可能和之前序列的隐藏层状态有关。RNN的机构中,当前隐藏层状态不仅包含当前的输入信息,还包括之前序列的隐藏层状态。网络会对之前的信息进行记忆并应用于当前的输入计算中。
6.训练过程中,如果一个模型不收敛,那么是否说明这个模型无效?导致模型不收敛的原因有哪些?
不能说明模型无效;导致不收敛的原因可能是数据分类的标注不准确,样本信息量太大导致模型不足以fit整个样本空间。学习率设置太大容易产生震荡,太小容易不收敛。数据没有进行归一化操作等
7.为什么用2个3*3的卷积核而不是5*5
因为两者有相同的感受野,但是前者的参数更少。
8.ReLU比Sigmoid好在哪里
Sigmoid只在0的附近时有比较好的激活性,而在正负饱和区的梯度趋近于0,从而产生梯度消失问题;而relu在大于0的部分梯度为常数,所以不会有梯度消失。ReLU的导数计算更快。ReLU在负半导数区为0,所以神经元激活值为负时,梯度为0,此神经元不参与训练,具有稀疏性。
9.权值共享问题
计算同一个深度切片的神经元时采用的滤波器是共享的
10.激活函数
relu,sigmoid,tanh
11.在深度学习中,通常会finetuning已有的成熟模型,再基于新数据,修改最后几层神经网络权值,为什么?
实践中的数据集质量参差不齐,可以使用训练好的网络来进行特征提取。把训练好的网络当作特征提取器。
12.Attention的作用
- 减小处理高维输入数据的计算负担,通过结构化的选取输入的子集,降低数据维度。
- “去伪存真”,让任务处理系统更专注于找到输入数据中显著的与当前输出相关的有用信息,从而提高输出的质量。
13.LSTM

14.LSTM和GRU的原理以及区别
- GRU和LSTM的性能在很多任务上不分伯仲。
- GRU 参数更少因此更容易收敛,但是数据集很大的情况下,LSTM表达性能更好。
- 从结构上来说,GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将hidden state 传给下一个单元,而LSTM则用memory cell 把hidden state 包装起来。
15.什么是dropout
在神经网络的计算过程中,对于神经单元按照一定的概率将其随机从网络中丢弃,从而达到对于每个mini-batch都是在训练不同的网络的效果,防止过拟合。
16. batch_size的大小的影响
batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
深度学习 (二)
16.优化器Adam
Adam算法和传统的SGD不同。SGD保持单一的学习率更新所有权重,学习率在训练过程中不会改变。而Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应学习率。
17.RNN梯度消失问题,为什么LSTM和GRU可以解决此问题
RNN由于网络比较深,后面层的输出误差很难影响到前面层的计算,RNN的某一单元主要受他附近单元的影响。而LSTM可以通过阀门记忆一些长期的信息,相应的保留了更多的梯度。而GRU也可以通过重置和更新两个阀门保留长期的记忆,进而相对解决梯度消失的问题。
18.1*1卷积的作用
- 实现跨通道的交互和信息整合
- 实现卷积核通道的降维和升维
- 可以实现多个feature map的线性组合而且可以实现与全连接等价的效果
19.如何提升模型泛化能力
- 数据:搜集更多数据;对数据做一些变化
- 算法:更好的权重初始化方式;调整学习率;调节batch和epoach的大小;添加正则;尝试其他优化器;使用early stopping。
20. RNN和LSTM的区别
21.如何防止过拟合
- 扩增数据集
- 加入dropout
- 加入正则
- batchnomaliztaion
- early stopping
22. 为什么需要神经元稀疏
更好的挖掘相关特征,拟合数据。而由于ReLU激活函数可以实现一半激活一半抑制,因而可以能够更好的实现神经元的稀疏。
深度学习 (三)
1. 神经网络为什么使用交叉熵
如果一个样本属于K,那么这个类别所对应的输出值应该是1,其他的为0,这是神经网络期望输出的结果。交叉熵就是用来判断实际输出和期望输出接近程度的。
2. Bi-LSTM的正向推导和反向推导过程
二面
1.手写svm,
2.手写LR,
3.手推前向传播。
4.xgb详细讲解。
5.knn,k-mean。
6.旋转数组:用额外内存和不用。
7.判断是不是后续遍历中序二叉树。
8.python内存管理,内存池最大?
9.python可变不可变数据结构。
10 python lamba与def 定义函数的区别
三面:
1.redis和mongodb与mysql。。真不会。
2.加快搜索速度方法。
3.计算相似度方法。
4.bert微调。
5.研究生最大收获。
6.研究生与本科生区别。
问面试官的问题:
7有啥问题:1.你们干啥的,2.你看起来为啥像95后,不应该是总监么。3.多久能收到反馈。

