
热门标签
热门文章
- 1从github下载项目并运行 / 廖雪峰Git教程_从github下载的ssm项目源码怎么运行
- 2CI/CD实践笔记_cicd项目经历
- 3【51单片机】SG90舵机控制_sg90舵机模块
- 4苹果专用解压缩软件BetterZip 5 for Mac v5.3.4中文免费注册版
- 5docker strace ptrace 报错 Operation not permitted 解决方法_strace operation not permitted
- 6git+linux+最新版本,linux源码安装git最新版本
- 7设计符合autosar架构的simulink模型框架
- 8Maven子项目启动报错_invalid packaging for parent pom com.yupi:dreaifea
- 9前端面试官的套路,你懂吗?_前端面试套路
- 10Python采集3000条北京二手房数据,看我都分析出了啥?_北京二手房交易数据分析
当前位置: article > 正文
结构化数据抽取成三元组_【NLP笔记】关系抽取,一步到位!
作者:盐析白兔 | 2024-04-22 10:48:48
赞
踩
结构化数据抽取三元组的方法
本本主要详细解读关系抽取SOTA论文Two are Better than One:Joint Entity and Relation Extraction with Table-Sequence Encoders, 顺带简要介绍关系抽取的背景方便完全不了解童鞋~
信息抽取
我们说的信息抽取一般是指从文本数据中抽取特定数据结构信息的一种手段。对于不同结构形式的数据如结构化文本,半结构化文本,自由文本,有各自对应的方案,其中从自由文本中抽取难度最大。总之,我们的目的是希望在海量文本中,快速抽出我们关注的事实。
关系抽取
三元组: 大部分情况下,我们喜欢用三元组的数据结构来描述抽取到的信息
- 三元组的表达能力非常丰富,几乎所有事情都可以自然或者强行的表达成三元组,比如随便一句”今天天气真冷“ 表达为 天气-状态-冷。
- 三元组与后续的知识图谱工作非常适配,如Neo4j等图数据库就是以三元组为存储单位,图谱的查询推断等工具使用三元组比普通的关系型数据库来的方便的多。
Schema:
当我们拿到一个信息抽取的任务,需要明确我们抽取的是什么,”今天天气真冷“,我们要抽的天气的状态天气-状态-冷,而非 今天-气候-冷(虽然也可以这样抽),因此一般会首先定义好我们要抽取的数据结构模式shcema, 会确定谓词以及主语并与的类型
- Subject_type: 主语类型
- Predicate: 谓词
- Object_type: 宾语类型
- 对应
- Subject_type: 人物
- Predicate: 出生地
- Object_type: 地点
常规RE方案
目前主流关系抽取一般两种解决方法
- pipline两步走: 将关系抽取分解为NER任务和分类任务,NER任务标注主语或宾语,分类主要针对定义的schema中的有限个谓词进行分类。根据具体任务不同,有些可能是两步走或者三步走,pipline任务的顺序先分类还是先标注也会有差异
- Pipline优势:每一步分别针对各个任务进行,表征是task-specific, 相对来说精度较高
- Pipline缺陷:
- 任务有顺序会有误差传递问题,即在预测时下一步任务可能受上一步误差隐形,而在训练阶段不会,训练和预测阶段有gap
- 分开的任务在一句话中多个实体关系时,比较难解决实体和关系的对应问题,
- joint learning: joint learing可以理解为采用多任务的方式,同时进行NER和关系分类任务, 在众多joint learning中最出众的是采用tabel filled 方式,即任务的输出是filled一张有text-sequence构成的表,在表中的位置表达除了词与词的连接,该位置的标注则标出了谓语(如下图)
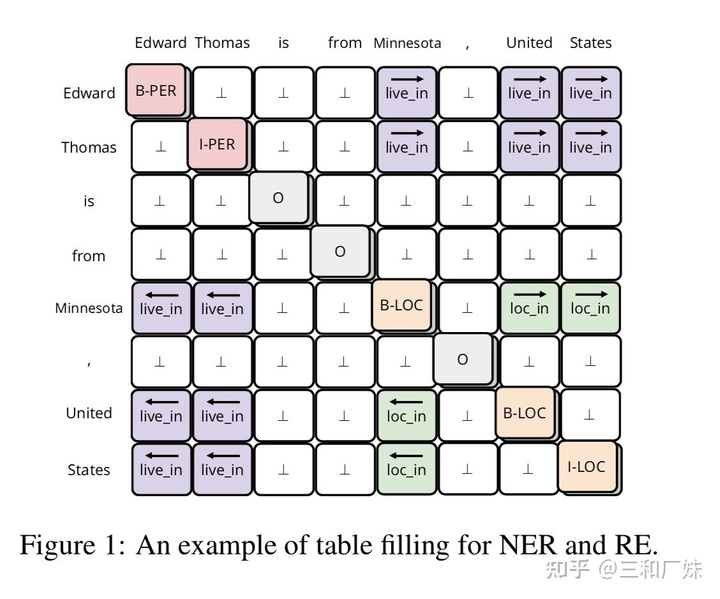
- 优势:
- 两个任务的表征有交互作用可能辅助任务的学习
- 不用训练多个模型,不存在训练与预测时的gap
- 缺陷:
- 两个任务的表征可能冲突,影响任务效果
- Fill table本质仍然是转成sequence来fill,未能充分利用table结构信息
RE with Table Sequence
终于来到本篇的主题啦,为了解决一般filled table的问题, 作者提出table-sequence encoder的方法,分别对table和sequence做表征,本文的最大贡献在于
- 分别对
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/468314
推荐阅读
相关标签

