
- 1Android_studio和java的完整安装_android studio java
- 2Sora AIGC 介绍
- 3一个开源的文档管理系统Paperless-ngx私有化部署教程_开源文档管理系统
- 4vscode 查看某个组件的引用和依赖关系_vscode查找文件引用
- 5[ai笔记13] 大模型架构对比盘点:Encoder-Only、Decoder-Only、Encoder-Decoder
- 6Hive的安装及配置详解(含图文)_hive配置文件
- 7数图可视化品类空间管理系统入编《零售门店数字化赋能专项报告(2024年)》
- 8如何在conda中降低Python版本_conda 虚拟环境降低python版本
- 9linux 编译 opencv遇到问题
- 10Quartus的2FSK调制解调verilog_verilog的2ask调制解调
中文分词常见方法_要实现中文分词可以使用
赞
踩
链接:https://www.zhihu.com/question/19578687/answer/190569700
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块。不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性、句法树等模块的效果。当然分词只是一个工具,场景不同,要求也不同。
在人机自然语言交互中,成熟的中文分词算法能够达到更好的自然语言处理效果,帮助计算机理解复杂的中文语言。竹间智能在构建中文自然语言对话系统时,结合语言学不断优化,训练出了一套具有较好分词效果的算法模型,为机器更好地理解中文自然语言奠定了基础。
在此,对于中文分词方案、当前分词器存在的问题,以及中文分词需要考虑的因素及相关资源,竹间智能 自然语言与深度学习小组 做了些整理和总结,希望能为大家提供一些参考。
中文分词根据实现原理和特点,主要分为以下2个类别:
1、基于词典分词算法
也称字符串匹配分词算法。该算法是按照一定的策略将待匹配的字符串和一个已建立好的“充分大的”词典中的词进行匹配,若找到某个词条,则说明匹配成功,识别了该词。常见的基于词典的分词算法分为以下几种:正向最大匹配法、逆向最大匹配法和双向匹配分词法等。
基于词典的分词算法是应用最广泛、分词速度最快的。很长一段时间内研究者都在对基于字符串匹配方法进行优化,比如最大长度设定、字符串存储和查找方式以及对于词表的组织结构,比如采用TRIE索引树、哈希索引等。
2、基于统计的机器学习算法
这类目前常用的是算法是HMM、CRF、SVM、深度学习等算法,比如stanford、Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
Nianwen Xue在其论文《Combining Classifiers for Chinese Word Segmentation》中首次提出对每个字符进行标注,通过机器学习算法训练分类器进行分词,在论文《Chinese word segmentation as character tagging》中较为详细地阐述了基于字标注的分词法。
常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。
随着深度学习的兴起,也出现了基于神经网络的分词器,例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。算法框架的思路与论文《Neural Architectures forNamed Entity Recognition》类似,利用该框架可以实现中文分词,如下图所示:
<img src="https://pic2.zhimg.com/v2-aad7ef8156b33c51efeb0f7f4b6f614d_b.jpg" data-rawwidth="633" data-rawheight="498" class="origin_image zh-lightbox-thumb" width="633" data-original="https://pic2.zhimg.com/v2-aad7ef8156b33c51efeb0f7f4b6f614d_r.jpg">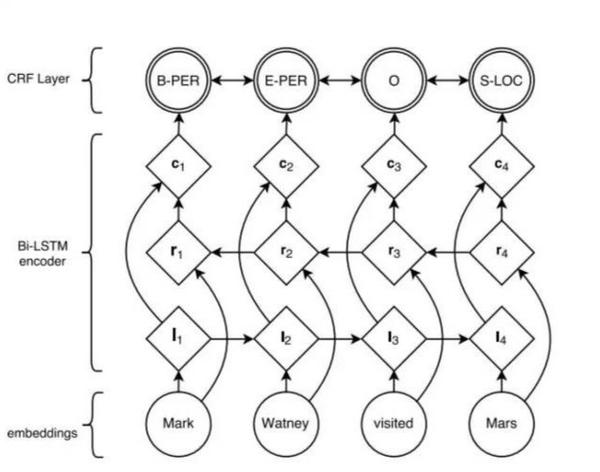
首先对语料进行字符嵌入,将得到的特征输入给双向LSTM,然后加一个CRF就得到标注结果。
分词器当前存在问题:
目前中文分词难点主要有三个:
1、分词标准:比如人名,在哈工大的标准中姓和名是分开的,但在Hanlp中是合在一起的。这需要根据不同的需求制定不同的分词标准。
2、歧义:对同一个待切分字符串存在多个分词结果。
歧义又分为组合型歧义、交集型歧义和真歧义三种类型。
1) 组合型歧义:分词是有不同的粒度的,指某个词条中的一部分也可以切分为一个独立的词条。比如“中华人民共和国”,粗粒度的分词就是“中华人民共和国”,细粒度的分词可能是“中华/人民/共和国”
2) 交集型歧义:在“郑州天和服装厂”中,“天和”是厂名,是一个专有词,“和服”也是一个词,它们共用了“和”字。
3) 真歧义:本身的语法和语义都没有问题, 即便采用人工切分也会产生同样的歧义,只有通过上下文的语义环境才能给出正确的切分结果。例如:对于句子“美国会通过对台售武法案”,既可以切分成“美国/会/通过对台售武法案”,又可以切分成“美/国会/通过对台售武法案”。
一般在搜索引擎中,构建索引时和查询时会使用不同的分词算法。常用的方案是,在索引的时候使用细粒度的分词以保证召回,在查询的时候使用粗粒度的分词以保证精度。
3、新词:也称未被词典收录的词,该问题的解决依赖于人们对分词技术和汉语语言结构的进一步认识。
另外,我们收集了如下部分分词工具,供参考:
中科院计算所NLPIR http://ictclas.nlpir.org/nlpir/
ansj分词器 https://github.com/NLPchina/ansj_seg
哈工大的LTP https://github.com/HIT-SCIR/ltp
清华大学THULAC https://github.com/thunlp/THULAC
斯坦福分词器 https://nlp.stanford.edu/software/segmenter.shtml
Hanlp分词器 https://github.com/hankcs/HanLP
结巴分词 https://github.com/yanyiwu/cppjieba
KCWS分词器(字嵌入+Bi-LSTM+CRF) https://github.com/koth/kcws
ZPar https://github.com/frcchang/zpar/releases
IKAnalyzer https://github.com/wks/ik-analyzer
以及部分分词器的简单说明:
哈工大的分词器:主页上给过调用接口,每秒请求的次数有限制。
清华大学THULAC:目前已经有Java、Python和C++版本,并且代码开源。
斯坦福分词器:作为众多斯坦福自然语言处理中的一个包,目前最新版本3.7.0, Java实现的CRF算法。可以直接使用训练好的模型,也提供训练模型接口。
Hanlp分词:求解的是最短路径。优点:开源、有人维护、可以解答。原始模型用的训练语料是人民日报的语料,当然如果你有足够的语料也可以自己训练。
结巴分词工具:基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
字嵌入+Bi-LSTM+CRF分词器:本质上是序列标注,这个分词器用人民日报的80万语料,据说按照字符正确率评估标准能达到97.5%的准确率,各位感兴趣可以去看看。
ZPar分词器:新加坡科技设计大学开发的中文分词器,包括分词、词性标注和Parser,支持多语言,据说效果是公开的分词器中最好的,C++语言编写。
关于速度:
由于分词是基础组件,其性能也是关键的考量因素。通常,分词速度跟系统的软硬件环境有相关外,还与词典的结构设计和算法复杂度相关。比如我们之前跑过字嵌入+Bi-LSTM+CRF分词器,其速度相对较慢。另外,开源项目 https://github.com/ysc/cws_evaluation 曾对多款分词器速度和效果进行过对比,可供大家参考。
最后附上公开的分词数据集
测试数据集
1、SIGHAN Bakeoff 2005 MSR,560KB
http://sighan.cs.uchicago.edu/bakeoff2005/
2、SIGHAN Bakeoff 2005 PKU, 510KB
http://sighan.cs.uchicago.edu/bakeoff2005/
3、人民日报 2014, 65MB

