
- 1基于STM32的智能换气除湿杀菌鞋柜_基于stm32的智能鞋柜
- 2微信小程序之音乐播放器_微信小程序音乐播放器
- 3Kafka 保证消息的不丢失_怎么样确保kafka消息不丢失
- 4Mysql事务隔离MVCC机制_mvcc机制是如何保证事务的隔离性的?
- 5人脸识别方法的研究_gabor特征人脸识别国外研究现状
- 6修改hosts文件,提高访问github的速度(github外网的登录问题)_github hosts
- 7usage of algorithm
- 8stm32开发三、单片机关键字extern
- 9读入一个小于10 的整数n,输出它的阶乘n!_2.输入一个小于10的正整数n,输出n的阶乘。
- 10[网络安全自学篇] 十.论文之基于机器学习算法的主机恶意代码_恶意代码 顶级论文
windows系统pyspark安装、测试_pyspark windows安装
赞
踩
自动安装即可

1.下载winutils(替换hadoop的bin文件)
![]()
2.下载hadoop安装包(清华镜像)
![]()
3.解压(管理员权限)
![]()
4.在winutils中找到对应的hadoop版本
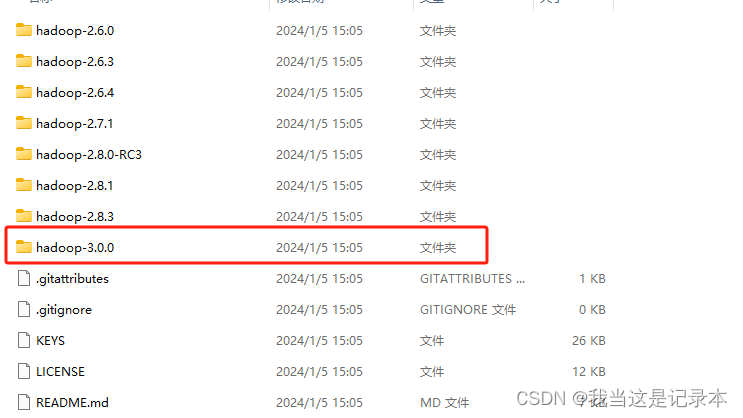
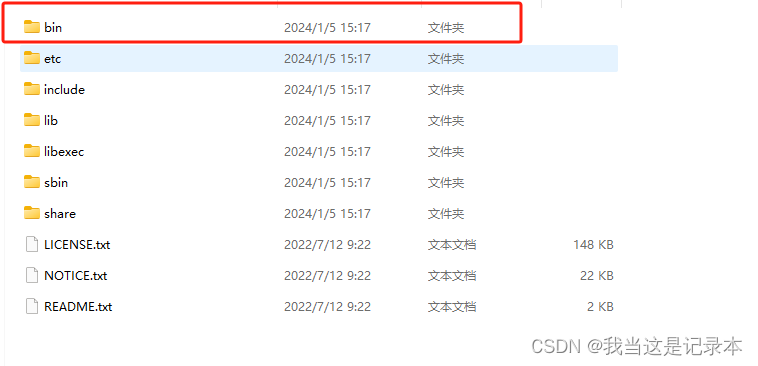
将winutils目录下的bin文件复制到hadoop中替换bin文件

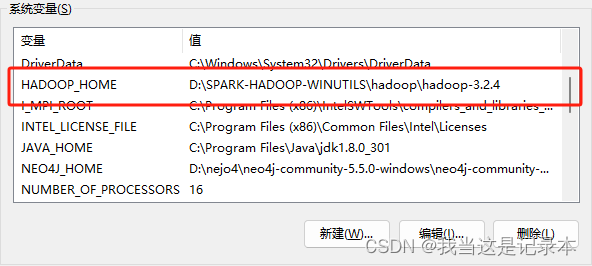
5.配置环境
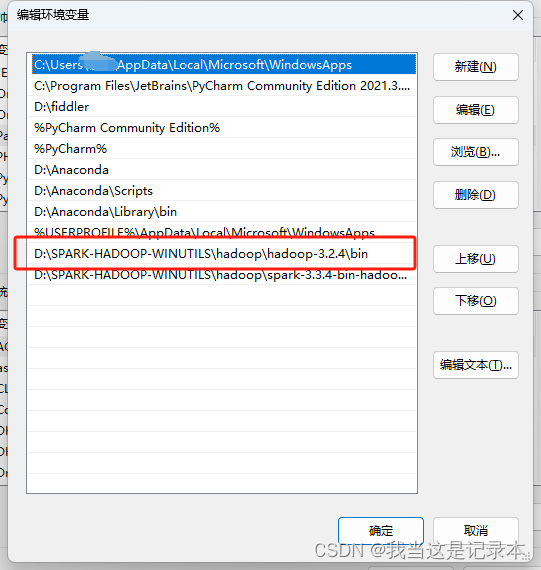
安装pyspaark
1.下载安装包(清华镜像)
![]()
2.解压(管理员打开)
![]()
3.配置环境
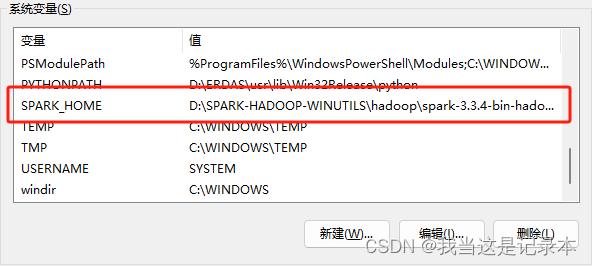
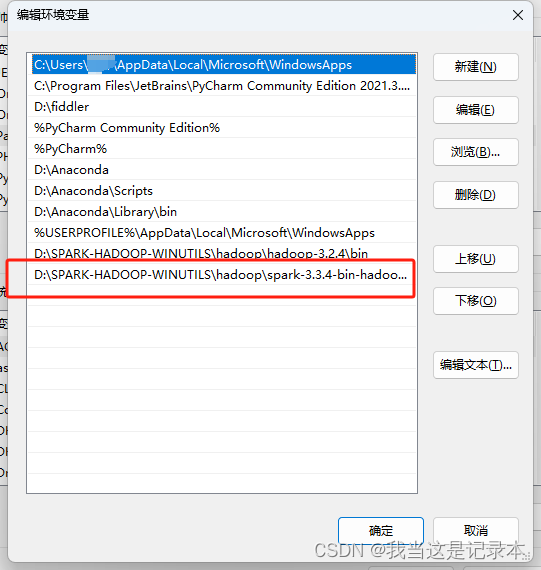
4.将spark文件夹下的pyspark文件复制(我的路径D:\SPARK-HADOOP-WINUTILS\hadoop\spark-3.3.4-bin-hadoop3\python\pyspark)
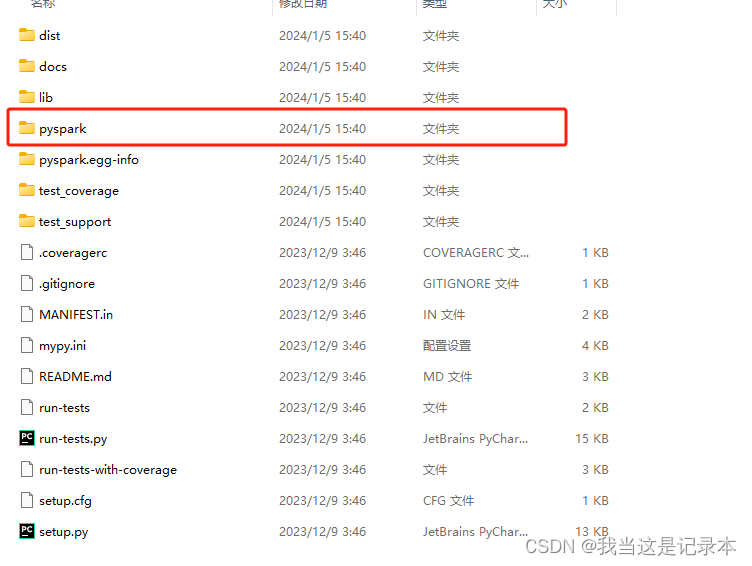
5.将pyspark文件粘贴到python项目路径下(我的路径 D:\pythonProject\venv\Lib\site-packages)这里各有不同,试一试总能试出来的。
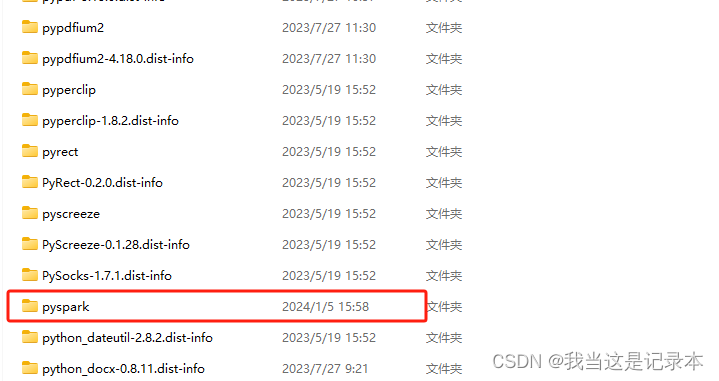
6.安装py4j(直接终端pip,我没有用conda,用conda的可以再找找)ps:如果上面第5步路径找不到,也可以先安装py4j然后找py4j的目录,然后复制过去也行。
检查是否安装成功
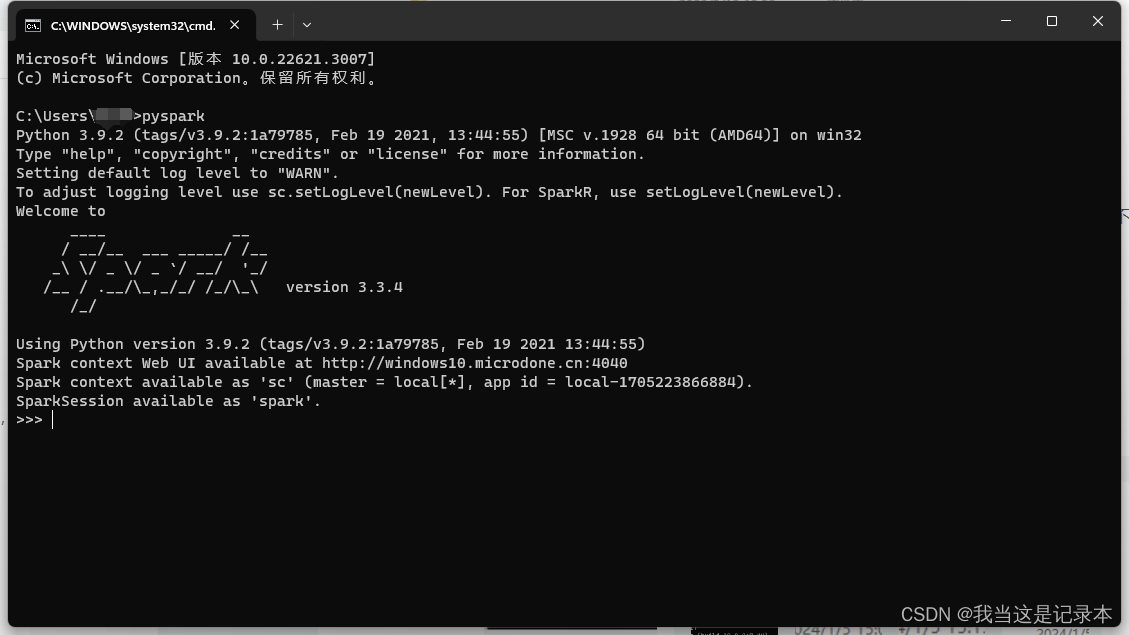
这样就是成功了!
注意!我个人在第一次使用的时候产生了一个报错信息24/01/05 16:10:42 ERROR Executor: Exception in task 4.0 in stage 0.0 (TID 4) java.io.IOException: Cannot run program "python3": CreateProcess error=2,我的解决办法是将python.exe复制一份并改名为python3.exe,成功运行。

我在本地写了一个简单的粒子群测试,开了三个线程。
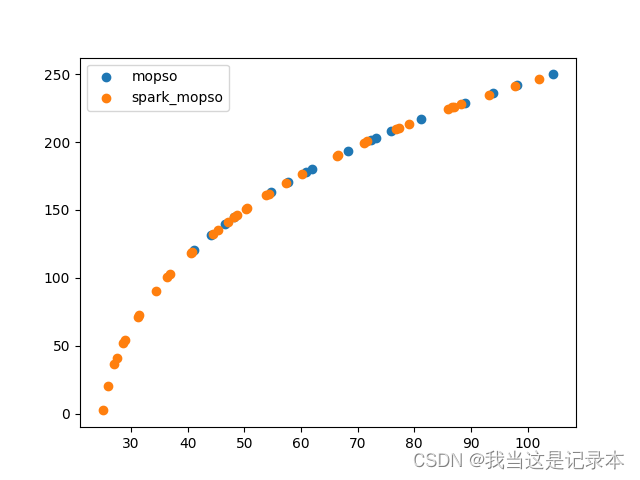
在相同的迭代次数下使用spark的粒子群计算耗时没有增加,但是求解结果分布更紧密,解集质量更高。
这是求解结果的目标空间分布情况
看到最后,如果对你有帮助的话,点个赞吧~

