
热门标签
热门文章
- 12021-03-11 php 获取文件/上传文 是否是图片格式(与后缀无关,取文件实际内容)_--enable-exif
- 2如何把 Git 集成到 IntelliJ IDEA ?_已经安装好git,怎么绑定到idea上去
- 3Python笔记-Flask结合SQLAlchemy查询MySQL数据库_from flask_sqlalchemy import sqlalchemy
- 4自定义表单元素组件内容变化触发ElForm重新校验
- 5关于VScode切换、拉取、推送、合并分支,并解决冲突_vscode 切换分支
- 6Java面向对象程序设计_1. 创建一个ayyaylist,在其中加入三个职工。职工类employee属性为:姓名name,年
- 7详细讲解如何使用Java连接Kafka构建生产者和消费者(带测试样例)_java http 连接kafka
- 8AI芯片行业深度:发展现状、竞争格局、市场空间及相关公司深度梳理_人工智能芯片行业
- 9百度实习公司对考勤没有过多限制,稍微晚一点到也没有太大关系_太极股份 西安 加班
- 10【图像融合】融合算法综述(持续更新)_利用多通道的图像融合技术,实现图像的增强问题的设计方案
当前位置: article > 正文
(七)、基于 LangChain 实现大模型应用程序开发 | 基于知识库的个性化问答 (向量数据库与词向量 Vectorstores and Embeddings)_langchain 通义千问 +embedding实现本地知识库问答的python代码
作者:盐析白兔 | 2024-04-29 22:48:00
赞
踩
langchain 通义千问 +embedding实现本地知识库问答的python代码
检索增强生成(RAG)的整体工作流程如下:
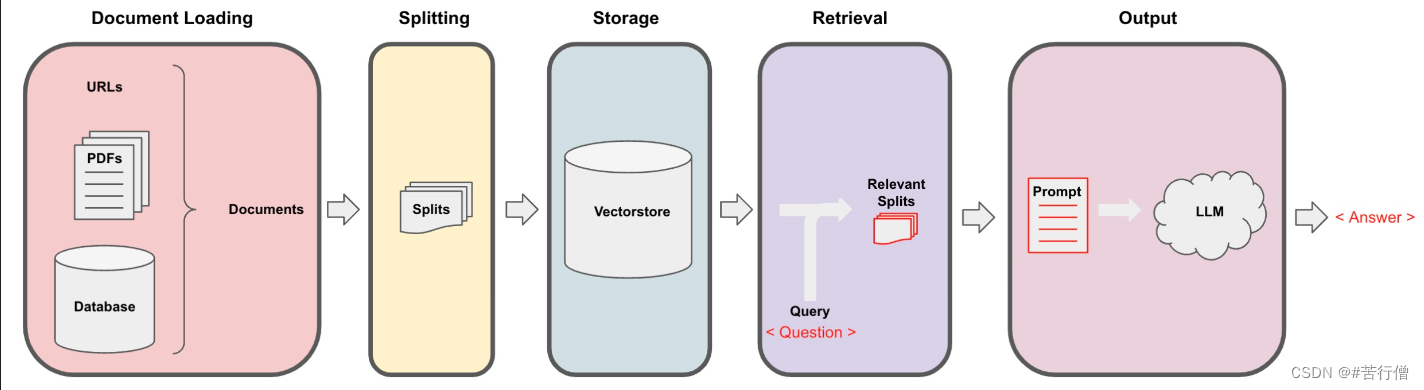
1、读取文档
from langchain.document_loaders import PyPDFLoader # 加载 PDF # MachineLearning-Lecture02.pdf其实是我多复制了一份MachineLearning-Lecture01.pdf,改了文件名 # 每份.pdf有22页 loaders = [ PyPDFLoader("./data/MachineLearning-Lecture01.pdf"), PyPDFLoader("./data/MachineLearning-Lecture02.pdf") ] docs = [] for loader in loaders: docs.extend(loader.load()) print(len(docs)) docs

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在文档加载后,我们可以使用RecursiveCharacterTextSplitter(递归字符文本拆分器)来创建块。
# 分割文本 from langchain.text_splitter import RecursiveCharacterTextSplitter # 默认separators=["\n\n", "\n", " ", ""] text_splitter = RecursiveCharacterTextSplitter( chunk_size = 2500, # 每个文本块的大小。这意味着每次切分文本时,会尽量使每个块包含 1500 个字符。 chunk_overlap = 150 # 每个文本块之间的重叠部分。 ) # .split_documents用来分割Document对象 # 我们之前学的是.split_text(text),因为text是字符串对象 # 而这里是由document对象构成的列表,即split是对整个列表进行的 splits = text_splitter.split_documents(docs) print(len(splits)) splits
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2、Embeddings
嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
# 初始化openai环境
from langchain.chat_models import ChatOpenAI
import os
import openai
# 运行此API配置,需要将目录中的.env中api_key替换为自己的
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
# 下面瞧瞧embedding的作用,测几个例子 from langchain.embeddings.openai import OpenAIEmbeddings embedding = OpenAIEmbeddings() sentence1_chinese = "我喜欢狗" sentence2_chinese = "我喜欢犬科动物" sentence3_chinese = "外面的天气很糟糕" embedding1_chinese = embedding.embed_query(sentence1_chinese) embedding2_chinese = embedding.embed_query(sentence2_chinese) embedding3_chinese = embedding.embed_query(sentence3_chinese) # 简单用点积来测测相似度,点积结果越大,说明越相似 import numpy as np s12 = np.dot(embedding1_chinese, embedding2_chinese) print('s12: ', s12) s13 = np.dot(embedding1_chinese, embedding3_chinese) print('s13: ', s13) s23 = np.dot(embedding2_chinese, embedding3_chinese) print('s13: ', s23)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
s12: 0.9441133587045968
s13: 0.7922614293489787
s13: 0.7805260643872631
- 1
- 2
- 3
3、Vectorstores
# 安装下依赖库
!pip install chromadb
- 1
- 2
3.1、初始化Chroma
Langchain集成了超过30个不同的向量存储库。我们选择Chroma是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
接下来我们来实际操作创建向量数据库的过程,并且将生成的向量数据库保存在本地。当我们在创建Chroma数据库时,我们需要传递如下参数:
- documents: 切割好的文档对象
- embedding: embedding对象
- persist_directory: 向量数据库存储路径
首先我们指定一个持久化路径:
from langchain.vectorstores import Chroma # !rm -rf './data/chroma/' # 删除旧的数据库文件(如果文件夹中有文件的话) persist_directory_chinese = './data/chroma/' # 如果该路径存在旧的数据库文件,可以通过以下命令删除: import shutil def clear_folder_shutil(path): shutil.rmtree(path) os.mkdir(path) clear_folder_shutil(persist_directory_chinese) # splits是我们前面切分好的存有document对象的列表,即知识库文档。 print(len(splits), splits) # 接着从已加载的文档中创建一个向量数据库: vectordb_chinese = Chroma.from_documents( documents=splits, embedding=embedding, persist_directory=persist_directory_chinese # 允许我们将persist_directory目录保存到磁盘上 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
80 [Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay. Good morning. ...
- 1
可以看到数据库长度也是80,这与我们之前的切分数量是一样的。现在让我们开始使用它。
print(vectordb_chinese._collection.count()) # 80
- 1
3.2、相似性搜索(Similarity Search)
# 首先我们定义一个需要检索答案的问题:
query = "machine learning是什么?"
# 接着调用已加载的向量数据库根据相似性检索答案topk:
docs_chinese = vectordb_chinese.similarity_search(query, k=3)
print(len(docs_chinese))
print(docs_chinese[0].page_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3
So in this class, we've tried to convey to you a broad set of principl es and tools that will
be useful for doing many, many things. And ev ery time I teach this class, I can actually
very confidently say that af ter December, no matter what yo u're going to do after this
December when you've sort of completed this class, you'll find the things you learn in
this class very useful, and these things will be useful pretty much no matter what you end
up doing later in your life.
So I have more logistics to go over later, but let's say a few more words about machine
learning. I feel that machine learning grew out of early work in AI, early work in artificial
intelligence. And over the last — I wanna say last 15 or last 20 years or so, it's been viewed as a sort of growing new capability for computers. And in particular, it turns out
that there are many programs or there are many applications that you can't program by
hand....
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 执行了persist()操作以后向量数据库才真正的被保存到了本地,下次在需要使用该向量数据库时我们只需要从本地加载数据库即可,
- 无需再根据原始文档来生成向量数据库了。
vectordb_chinese.persist()
- 1
已经存储了向量数据库(VectorDB),包含各文档的语义向量表示。可通过下面方式将向量数据库(VectorDB)加载进来:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory_chinese = './data/chroma/'
embedding = OpenAIEmbeddings()
vectordb_chinese = Chroma(
persist_directory=persist_directory_chinese,
embedding_function=embedding
)
print(vectordb_chinese._collection.count())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4、失败的情况(Failure modes)
这看起来很好,基本的相似性搜索很容易就能让你完成80%的工作。但是,可能会出现一些相似性搜索失败的情况。这里有一些可能出现的边缘情况,这一篇博客说一下这些失败的情况,下一篇博客再来讲如何有效地解答这两个问题。
4.1、重复块
语义搜索获取所有相似的文档,但不强制多样性。
从上面检索出来的3个结果可以看出,docs[0]和docs[1]是完全相同的。
docs_chinese
[Document(page_content="So in this class, we've tried to convey....", metadata={'page': 2, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content="So in this class, we've tried to convey....", metadata={'page': 2, 'source': './data/MachineLearning-Lecture02.pdf'}),
Document(page_content="joys of machine learning firs thand and really try", metadata={'page': 10, 'source': './data/MachineLearning-Lecture01.pdf'})]
- 1
- 2
- 3
- 4
4.2、检索错误答案
下面的问题询问了关于第二讲的问题,但也包括了来自其他讲的结果。
# 首先我们定义一个需要检索答案的问题:
query = "MachineLearning-Lecture02讲了什么内容?"
# 接着调用已加载的向量数据库根据相似性检索答案topk:
docs_chinese = vectordb_chinese.similarity_search(query, k=3)
print(len(docs_chinese))
docs_chinese
[Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay. Good morning...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture01.pdf'}),
Document(page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay. Good morning...', metadata={'page': 0, 'source': './data/MachineLearning-Lecture02.pdf'}),
Document(page_content=:'joys of machine learning firs thand and really try to think', metadata={'page': 10, 'source': './data/MachineLearning-Lecture02.pdf'})]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Reference
- [1] 吴恩达老师的教程
- [2] DataWhale组织
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/510185
推荐阅读

相关标签

