
- 1Cesium介绍及3DTiles数据加载时添加光照效果对比_cesium光照
- 2RabbitMQ的死信队列详解及实现_获取死信队列中的信息
- 3PeLK:通过周边卷积的参数高效大型卷积神经网络
- 4react 暂存数据持久化_react store 数据持久化
- 5Map集合和Collections(集合工具类)_collections工具类中的binarysearch()方法中的key是map中的键吗
- 6如何解决Git合并分支造成的冲突_git合并出现冲突是如何解决的
- 7jmeter 性能测试结果分析_jmeter结果分析
- 8在Git上放一个静态页面并且可以访问_gitlab 怎么发布静态页面
- 9机械臂视觉抓取总结_机械臂目标定位与抓取
- 10Jupyter 进阶教程
大数据分析与内存计算学习笔记
赞
踩
一、Scala编程初级实践
1.计算级数:
请用脚本的方式编程计算并输出下列级数的前n项之和Sn,直到Sn刚好大于或等于q为止,其中q为大于0的整数,其值通过键盘输入。(不使用脚本执行方式可写Java代码转换成Scala代码执行)
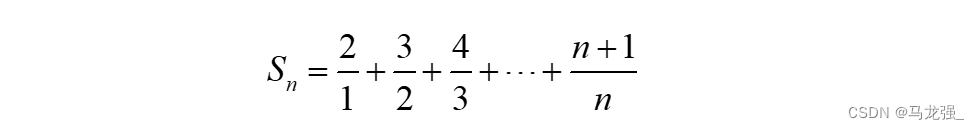
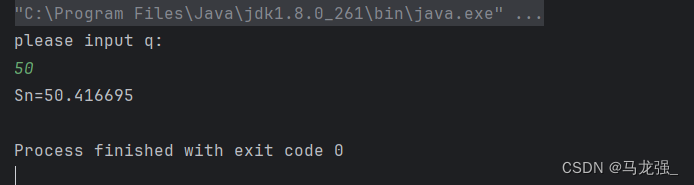
例如,若q的值为50.0,则输出应为:Sn=50.416695。
测试样例:
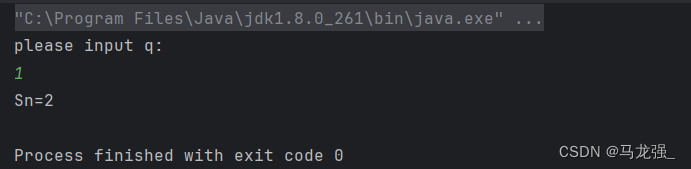
q=1时,Sn=2;
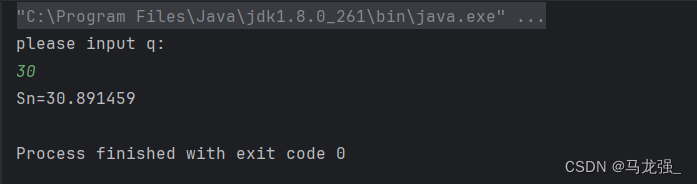
q=30时,Sn=30.891459;
q=50时,Sn=50.416695;
相关代码:
- import scala.io.StdIn.readInt
- object MedicalOne {
- def main(args: Array[String]): Unit = {
- var Sn: Float = 0
- var n: Float = 1
- println("please input q:")
- val q = readInt()
- while (Sn < q) {
- Sn += (n + 1) / n
- n += 1
- }
- if (Sn == Sn.toInt) {
- println(s"Sn=${Sn.toInt}")
- } else {
- println(s"Sn=$Sn")
- }
- }
- }

运行结果:
2 模拟图形绘制:
对于一个图形绘制程序,用下面的层次对各种实体进行抽象。定义一个Drawable的特质,其包括一个draw方法,默认实现为输出对象的字符串表示。定义一个Point类表示点,其混入了Drawable特质,并包含一个shift方法,用于移动点。所有图形实体的抽象类为Shape,其构造函数包括一个Point类型,表示图形的具体位置(具体意义对不同的具体图形不一样)。Shape类有一个具体方法moveTo和一个抽象方法zoom,其中moveTo将图形从当前位置移动到新的位置, 各种具体图形的moveTo可能会有不一样的地方。zoom方法实现对图形的放缩,接受一个浮点型的放缩倍数参数,不同具体图形放缩实现不一样。继承Shape类的具体图形类型包括直线类Line和圆类Circle。Line类的第一个参数表示其位置,第二个参数表示另一个端点,Line放缩的时候,其中点位置不变,长度按倍数放缩(注意,缩放时,其两个端点信息也改变了),另外,Line的move行为影响了另一个端点,需要对move方法进行重载。Circle类第一个参数表示其圆心,也是其位置,另一个参数表示其半径,Circle缩放的时候,位置参数不变,半径按倍数缩放。另外直线类Line和圆类Circle都混入了Drawable特质,要求对draw进行重载实现,其中类Line的draw输出的信息样式为“Line:第一个端点的坐标--第二个端点的坐标)”,类Circle的draw输出的信息样式为“Circle center:圆心坐标,R=半径”。如下的代码已经给出了Drawable和Point的定义,同时也给出了程序入口main函数的实现,请完成Shape类、Line类和Circle类的定义。
相关代码
代码目录:
主类GraphicPlotting:
- object GraphicPlotting {
- def main(args: Array[String]): Unit = {
- val p = Point(10, 30)
- p.draw()
- val line1 = new Line(Point(0, 0), Point(20, 20))
- line1.draw()
- line1.moveTo(Point(5, 5)) //移动到一个新的点
- line1.draw()
- line1.zoom(2) //放大两倍
- line1.draw()
- val cir = new Circle(Point(10, 10), 5)
- cir.draw()
- cir.moveTo(Point(30, 20))
- cir.draw()
- cir.zoom(0.5)
- cir.draw()
- }
- }
Drawable类
- trait Drawable {
- def draw() {
- println(this.toString)
- }
- }
Point类
- case class Point(var x: Double, var y: Double) extends Drawable {
- def shift(deltaX: Double, deltaY: Double) {
- x += deltaX;
- y += deltaY
- }
- }
Shape类
- abstract class Shape(var location: Point) {
- def moveTo(newLocation: Point) {
- location = newLocation
- }
-
- def zoom(scale: Double)
- }
Line类
- class Line(beginPoint: Point, var endPoint: Point) extends Shape(beginPoint) with Drawable {
- override def draw() {
- println(s"Line:(${location.x},${location.y})--(${endPoint.x},${endPoint.y})")
- } //按指定格式重载click
-
- override def moveTo(newLocation: Point) {
- endPoint.shift(newLocation.x - location.x, newLocation.y - location.y) //直线移动时,先移动另外一个端点
- location = newLocation //移动位置
- }
-
- override def zoom(scale: Double) {
- val midPoint = Point((endPoint.x + location.x) / 2, (endPoint.y + location.y) / 2) //求出中点,并按中点进行缩放
- location.x = midPoint.x + scale * (location.x - midPoint.x)
- location.y = midPoint.y + scale * (location.y - midPoint.y)
- endPoint.x = midPoint.x + scale * (endPoint.x - midPoint.x)
- endPoint.y = midPoint.y + scale * (endPoint.y - midPoint.y)
- }
- }
Circle类
- class Circle(center: Point, var radius: Double) extends Shape(center) with Drawable {
- override def draw() { //按指定格式重载click
- println(s"Circle center:(${location.x},${location.y}),R=$radius")
- }
-
- override def zoom(scale: Double) {
- radius = radius * scale //对圆的缩放只用修改半径
- }
- }
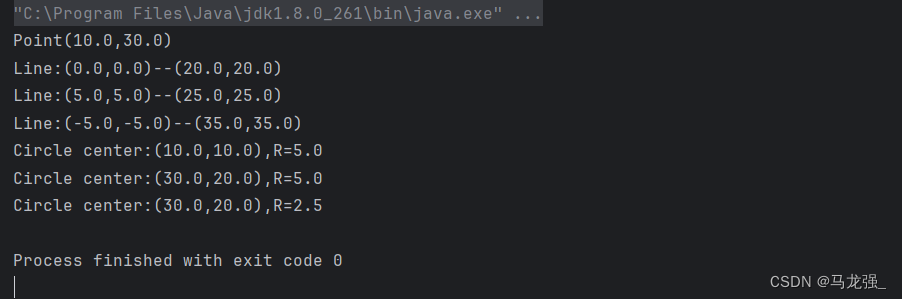
编译运行程序,期望的输出结果如下:
3 统计学生成绩:
学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为学号、性别、课程名1、课程名2等,后面每一行代表一个学生的信息,各字段之间用空白符隔开
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
...
给定任何一个如上格式的清单(不同清单里课程数量可能不一样),要求尽可能采用函数式编程,统计出各门课程的平均成绩,最低成绩,和最高成绩;另外还需按男女同学分开,分别统计各门课程的平均成绩,最低成绩,和最高成绩。
测试样例1如下:
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
301612 female 44 71 77
301613 female 66 71 91
301614 female 70 71 100
301615 male 72 77 72
301616 female 73 81 75
301617 female 69 77 75
301618 male 73 61 65
301619 male 74 69 68
301620 male 76 62 76
301621 male 73 69 91
301622 male 55 69 61
301623 male 50 58 75
301624 female 63 83 93
301625 male 72 54 100
301626 male 76 66 73
301627 male 82 87 79
301628 female 62 80 54
301629 male 89 77 72
测试样例2如下:
Id gender Math English Physics Science
301610 male 72 39 74 93
301611 male 75 85 93 26
301612 female 85 79 91 57
301613 female 63 89 61 62
301614 male 72 63 58 64
301615 male 99 82 70 31
301616 female 100 81 63 72
301617 male 74 100 81 59
301618 female 68 72 63 100
301619 male 63 39 59 87
301620 female 84 88 48 48
301621 male 71 88 92 46
301622 male 82 49 66 78
301623 male 63 80 83 88
301624 female 86 80 56 69
301625 male 76 69 86 49
301626 male 91 59 93 51
301627 female 92 76 79 100
301628 male 79 89 78 57
301629 male 85 74 78 80
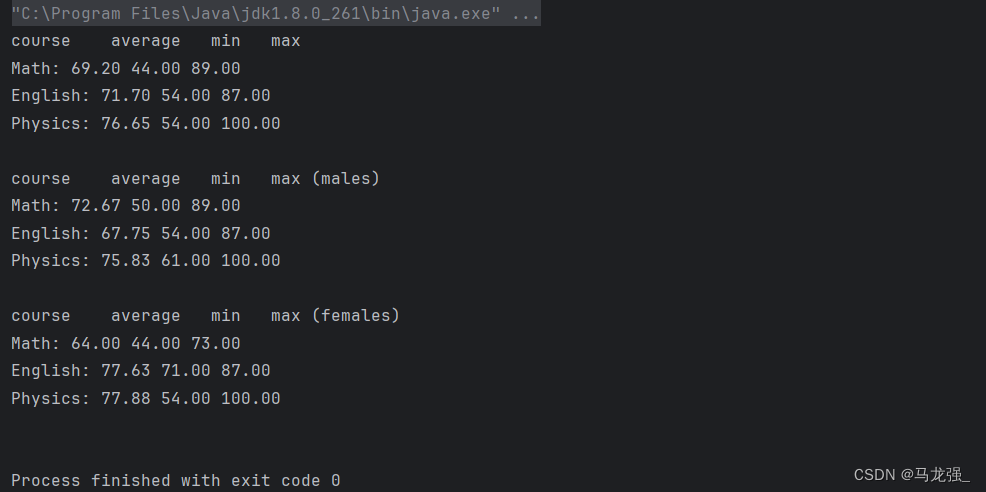
样例1的统计代码和结果输出
相关代码
- import scala.io.Source
-
- object Studentgrades_1 {
- def main(args: Array[String]): Unit = {
- val fileName = "D:\\IDEAProjects\\SecondScala\\src\\main\\scala\\grades1.txt"
- val lines = Source.fromFile(fileName).getLines().toList
- val header = lines.head.trim.split("\\s+").map(_.trim)
- val data = lines.tail.map(_.trim.split("\\s+"))
-
- val courseNames = header.drop(2)
- val statsTotal = calculateStatistics(data, courseNames)
- val statsMales = calculateStatistics(data.filter(_ (1) == "male"), courseNames)
- val statsFemales = calculateStatistics(data.filter(_ (1) == "female"), courseNames)
-
- printStatistics(statsTotal, "")
- printStatistics(statsMales, " (males)")
- printStatistics(statsFemales, " (females)")
- }
-
- def calculateStatistics(data: List[Array[String]], courses: Array[String]): List[(String, Double, Double, Double)] = {
- val courseScores = courses.indices.map { i =>
- val scores = data.filter(_(i + 2).matches("-?\\d+(\\.\\d+)?")).map(_(i + 2).toDouble) // Ensure we only have numbers
- if (scores.isEmpty) {
- (courses(i), 0.0, 0.0, 0.0) // Avoid division by zero if there are no scores for a course
- } else {
- val average = scores.sum / scores.length
- val min = scores.min
- val max = scores.max
- (courses(i), average, min, max)
- }
- }
- courseScores.toList
- }
-
- def printStatistics(stats: List[(String, Double, Double, Double)], title: String): Unit = {
- println(s"course average min max${title}")
- stats.foreach { case (course, average, min, max) =>
- println(f"$course: $average%.2f $min%.2f $max%.2f")
- }
- println()
- }
- }
结果输出
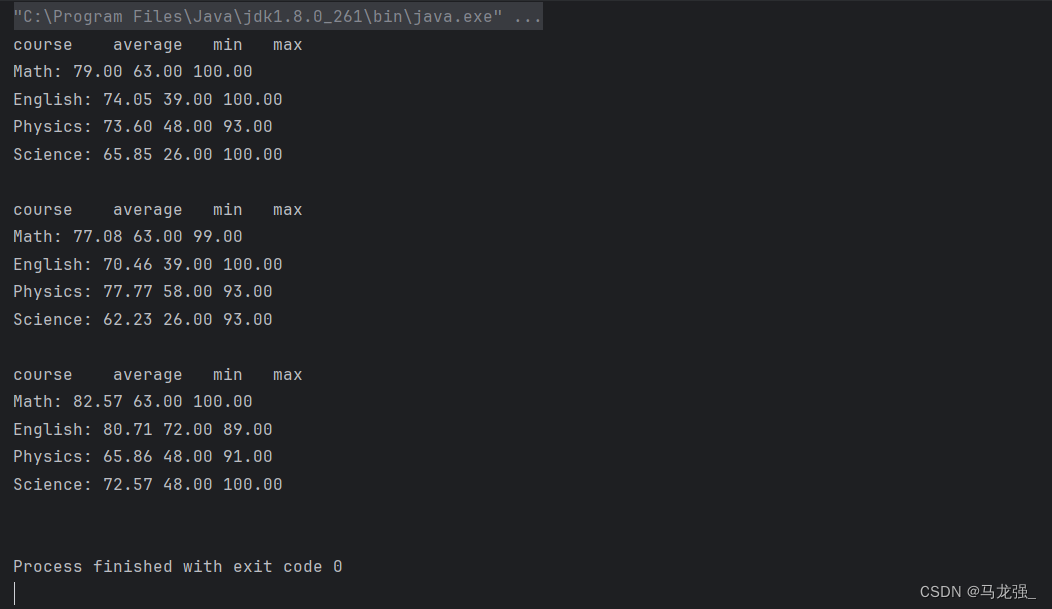
样例1的统计代码和结果输出
相关代码
- import scala.io.Source
-
- object Studentgrades_2 {
- def main(args: Array[String]): Unit = {
- val fileName = "D:\\IDEAProjects\\SecondScala\\src\\main\\scala\\grades2.txt"
- val lines = Source.fromFile(fileName).getLines().toList
- val header = lines.head.trim.split("\\s+").map(_.trim)
- val data = lines.tail.map(_.trim.split("\\s+"))
-
- val courseNames = header.drop(2)
- val statsTotal = calculateStatistics(data, courseNames)
- val statsMales = calculateStatistics(data.filter(_ (1) == "male"), courseNames)
- val statsFemales = calculateStatistics(data.filter(_ (1) == "female"), courseNames)
-
- printStatistics(statsTotal, "")
- printStatistics(statsMales, " (males)")
- printStatistics(statsFemales, " (females)")
- }
-
- def calculateStatistics(data: List[Array[String]], courses: Array[String]): List[(String, Double, Double, Double)] = {
- val courseScores = courses.indices.map { i =>
- val scores = data.filter(_(i + 2).matches("-?\\d+(\\.\\d+)?")).map(_(i + 2).toDouble) // Ensure we only have numbers
- if (scores.isEmpty) {
- (courses(i), 0.0, 0.0, 0.0) // Avoid division by zero if there are no scores for a course
- } else {
- val average = scores.sum / scores.length
- val min = scores.min
- val max = scores.max
- (courses(i), average, min, max)
- }
- }
- courseScores.toList
- }
-
- def printStatistics(stats: List[(String, Double, Double, Double)], title: String): Unit = {
- println(s"course average min max")
- stats.foreach { case (course, average, min, max) =>
- println(f"$course: $average%.2f $min%.2f $max%.2f")
- }
- println()
- }
- }
结果输出
二、RDD编程初级实践
1.spark-shell交互式编程
使用chapter5-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
| Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 …… |
请根据给定的实验数据,在spark-shell中通过编程来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设来多少门课程;
(3)Tom同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了DataBase这门课。
相关代码:
- (1)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val par = lines.map(row=>row.split(",")(0))
- val distinct_par = par.distinct() //去重操作
- distinct_par.count //取得总数
- (2)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val par = lines.map(row=>row.split(",")(1))
- val distinct_par = par.distinct()
- distinct_par.count
- (3)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val pare = lines.filter(row=>row.split(",")(0)=="Tom")
- pare.foreach(println)
- pare.map(row=>(row.split(",")(0),row.split(",")(2).toInt)).mapValues(x=>(x,1)).reduceByKey((x,y ) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1 / x._2)).collect()
- (4)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val pare = lines.map(row=>(row.split(",")(0),row.split(",")(1)))
- pare.mapValues(x => (x,1)).reduceByKey((x,y) => (" ",x._2 + y._2)).mapValues(x => x._2).foreach(println)
- (5)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val pare = lines.filter(row=>row.split(",")(1)=="DataBase")
- pare.count
- (6)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val pare = lines.map(row=>(row.split(",")(1),row.split(",")(2).toInt))
- pare.mapValues(x=>(x,1)).reduceByKey((x,y) => (x._1+y._1,x._2 + y._2)).mapValues(x => (x._1/ x._2)).collect().foreach(x => println(s"${x._1}: ${x._2}"))
- (7)
- val lines = sc.textFile("file:///home/qiangzi/chapter5-data1.txt")
- val pare = lines.filter(row=>row.split(",")(1)=="DataBase").map(row=>(row.split(",")(1),1))
- val accum = sc.longAccumulator("My Accumulator")
- pare.values.foreach(x => accum.add(x))
- accum.value
2.编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
实验代码:
- cd ~ # 进入用户主文件夹
- mkdir ./remdup
- mkdir -p ./remdup/src/main/scala
- vim ./remdup/src/main/scala/RemDup.scala
-
- /* RemDup.scala */
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- import org.apache.spark.HashPartitioner
-
- object RemDup {
- def main(args: Array[String]) {
- val conf = new SparkConf().setAppName("RemDup")
- val sc = new SparkContext(conf)
- val dataFileA = "file:///home/qiangzi/A.txt"
- val dataFileB = "file:///home/qiangzi/B.txt"
- val dataA = sc.textFile(dataFileA, 2)
- val dataB = sc.textFile(dataFileB, 2)
- val res = dataA.union(dataB).filter(_.trim().length > 0).map(line => (line.trim, "")).partitionBy(new HashPartitioner(1)).groupByKey().sortByKey().keys
- res.saveAsTextFile("file:///home/qiangzi/C.txt")
- }
- }
-
- cd ~/remdup
- vim simple.sbt
-
- /* simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- /usr/local/spark-3.5.1/bin/spark-submit --class "RemDup" --driver-java-options "-Dfile.encoding=UTF-8" ~/remdup/target/scala-2.12/simple-project_2.12-1.0.jar
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
实验代码:
- cd ~ # 进入用户主文件夹
- mkdir ./avgscore
- mkdir -p ./avgscore/src/main/scala
- vim ./avgscore/src/main/scala/AvgScore.scala
-
- /* AvgScore.scala */
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- import org.apache.spark.HashPartitioner
-
- object AvgScore {
- def main(args: Array[String]) {
- val conf = new SparkConf().setAppName("AvgScore")
- val sc = new SparkContext(conf)
- val dataFiles = Array(
- "file:///home/qiangzi/Sparkdata/algorithm.txt",
- "file:///home/qiangzi/Sparkdata/database.txt",
- "file:///home/qiangzi/Sparkdata/python.txt"
- )
- val data = dataFiles.foldLeft(sc.emptyRDD[String]) { (acc, file) =>
- acc.union(sc.textFile(file, 3))
- }
-
- val res = data.filter(_.trim().length > 0).map(line => {
- val fields = line.split(" ")
- (fields(0).trim(), fields(1).trim().toInt)
- }).partitionBy(new HashPartitioner(1)).groupByKey().mapValues(x => {
- var n = 0
- var sum = 0.0
- for (i <- x) {
- sum += i
- n += 1
- }
- val avg = sum / n
- f"$avg%1.2f"
- })
-
- res.saveAsTextFile("file:///home/qiangzi/Sparkdata/average.txt")
- }
- }
-
- cd ~/avgscore
- vim simple.sbt
-
- /* simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- /usr/local/spark-3.5.1/bin/spark-submit --class "AvgScore" --driver-java-options "-Dfile.encoding=UTF-8" ~/avgscore/target/scala-2.12/simple-project_2.12-1.0.jar
三、Spark SQL编程初级实践
1.Spark SQL基本操作
将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
| { "id":1 , "name":" Ella" , "age":36 } { "id":2, "name":"Bob","age":29 } { "id":3 , "name":"Jack","age":29 } { "id":4 , "name":"Jim","age":28 } { "id":4 , "name":"Jim","age":28 } { "id":5 , "name":"Damon" } { "id":5 , "name":"Damon" } |
为employee.json创建DataFrame,并写出Scala语句完成下列操作:
- 查询所有数据;
- 查询所有数据,并去除重复的数据;
- 查询所有数据,打印时去除id字段;
- 筛选出age>30的记录;
- 将数据按age分组;
- 将数据按name升序排列;
- 取出前3行数据;
- 查询所有记录的name列,并为其取别名为username;
- 查询年龄age的平均值;
- 查询年龄age的最小值。
实验代码:
- (1)
- import org.apache.spark.sql.SparkSession
- val spark=SparkSession.builder().getOrCreate()
- import spark.implicits._
- val df = spark.read.json("file:///home/qiangzi/employee.json")
- df.show()
- (2)
- df.distinct().show()
- (3)
- df.drop("id").show()
- (4)
- df.filter(df("age") > 30 ).show()
- (5)
- df.groupBy("age").count().show()
- (6)
- df.sort(df("name").asc).show()
- (7)
- df.take(3)
- (8)
- df.select(df("name").as("username")).show()
- (9)
- val avgAge = df.agg(avg("age")).first().getDouble(0)
- (10)
- val minAge = df.agg(min("age")).first().getLong(0).toInt
2.编程实现将RDD转换为DataFrame
源文件内容如下(包含id,name,age):
| 1,Ella,36 2,Bob,29 3,Jack,29 |
请将数据复制保存到Linux系统中,命名为employee.txt,实现从RDD转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出DataFrame的所有数据。请写出程序代码。
实验代码:
- cd ~ # 进入用户主文件夹
- mkdir ./rddtodf
- mkdir -p ./rddtodf/src/main/scala
- vim ./rddtodf/src/main/scala/RDDtoDF.scala
-
- /* RDDtoDF.scala */
- import org.apache.spark.sql.types._
- import org.apache.spark.sql.Encoder
- import org.apache.spark.sql.Row
- import org.apache.spark.sql.SparkSession
-
- object RDDtoDF {
- def main(args: Array[String]) {
- val spark = SparkSession.builder().appName("RDDtoDF").getOrCreate()
- import spark.implicits._
- val employeeRDD = spark.sparkContext.textFile("file:///home/qiangzi/employee.txt")
- val schemaString = "id name age"
- val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
- val schema = StructType(fields)
- val rowRDD = employeeRDD.map(_.split(",")).map(attributes => Row(attributes(0).trim, attributes(1), attributes(2).trim))
- val employeeDF = spark.createDataFrame(rowRDD, schema)
- employeeDF.createOrReplaceTempView("employee")
- val results = spark.sql("SELECT id,name,age FROM employee")
- results.map(t => "id:" + t(0) + "," + "name:" + t(1) + "," + "age:" + t(2)).show()
- spark.stop()
- }
- }
-
-
- cd ~/rddtodf
- vim simple.sbt
-
- /*simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies ++= Seq(
- "org.apache.spark" %% "spark-core" % "3.5.1",
- "org.apache.spark" %% "spark-sql" % "3.5.1"
- )
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- /usr/local/spark-3.5.1/bin/spark-submit --class "RDDtoDF" --driver-java-options "-Dfile.encoding=UTF-8" ~/rddtodf/target/scala-2.12/simple-project_2.12-1.0.jar
3.编程实现利用DataFrame读写MySQL的数据
(1)在MySQL数据库中新建数据库sparktest,再创建表employee,包含如表6-2所示的两行数据。
表6-2 employee表原有数据
| id | name | gender | Age |
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
(2)配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入如表6-3所示的两行数据到MySQL中,最后打印出age的最大值和age的总和。
表6-3 employee表新增数据
| id | name | gender | age |
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
实验代码:
- mysql -u root -p
-
- create database sparktest;
- use sparktest;
- create table employee (id int(4), name char(20), gender char(4), age int(4));
- insert into employee values(1,'Alice','F',22);
- insert into employee values(2,'John','M',25);
-
- cd ~ # 进入用户主文件夹
- mkdir ./testmysql
- mkdir -p ./testmysql/src/main/scala
- vim ./testmysql/src/main/scala/TestMySQL.scala
-
- /* TestMySQL.scala */
- import java.util.Properties
- import org.apache.spark.sql.SparkSession
- import org.apache.spark.sql.functions._
- import org.apache.spark.sql.types._
- import org.apache.spark.sql.Row
-
- object TestMySQL {
-
- def main(args: Array[String]): Unit = {
-
- val spark = SparkSession.builder()
- .appName("TestMySQL")
- .getOrCreate()
- val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26", "4 Tom M 23"))
- .map(_.split(" "))
-
-
- val schema = StructType(List(
- StructField("id", IntegerType, true),
- StructField("name", StringType, true),
- StructField("gender", StringType, true),
- StructField("age", IntegerType, true)
- ))
- val rowRDD = employeeRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
- val employeeDF = spark.createDataFrame(rowRDD, schema)
-
-
- val prop = new Properties()
- prop.put("user", "root")
- prop.put("password", "789456MLq")
- prop.put("driver", "com.mysql.jdbc.Driver")
-
- employeeDF.write
- .mode("append")
- .jdbc("jdbc:mysql://slave1:3306/sparktest", "sparktest.employee", prop)
-
- val jdbcDF = spark.read
- .format("jdbc")
- .option("url", "jdbc:mysql://slave1:3306/sparktest")
- .option("driver", "com.mysql.jdbc.Driver")
- .option("dbtable", "employee")
- .option("user", "root")
- .option("password", "789456MLq")
- .load()
-
- val aggregatedDF = jdbcDF.agg(
- max("age").alias("max_age"),
- sum("age").alias("total_age")
- )
-
-
- aggregatedDF.show()
-
- spark.stop()
- }
- }
-
-
- cd ~/testmysql
- vim simple.sbt
-
- /*simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies ++= Seq(
- "org.apache.spark" %% "spark-core" % "3.5.1",
- "org.apache.spark" %% "spark-sql" % "3.5.1"
- )
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- sudo /usr/local/spark-3.5.1/bin/spark-submit --class "TestMySQL" --driver-java-options "-Dfile.encoding=UTF-8" --jars /usr/local/hive-3.1.2/lib/mysql-connector-java-5.1.49.jar ~/testmysql/target/scala-2.12/simple-project_2.12-1.0.jar
四、Spark Streaming编程初级实践
1.实验目的
- 通过实验学习使用Scala编程实现文件和数据的生成;
- 掌握使用文件作为Spark Streaming数据源的编程方法
2.实验内容
(1)、以随机时间间隔在一个目录下生成大量文件,文件名随机命名,文件中包含随机生成的一些英文语句,每个英语语句内部的单词之间用空格隔开。
(2)、实时统计每10秒新出现的单词数量。
(3)、实时统计最近1分钟内每个单词的出现次数(每10秒统计1次)。
(4)、实时统计每个单词累计出现次数,并将结果保存到本地文件(每10秒统计1次)。
3.注意:
本次实验中,实验(2)、(3)、(4)是在实验(1)的基础之上做的,因为要做流计算,所以实验(2)、(3)、(4)在打包完运行代码之前,一定要先执行(1)代码,具体步骤如下:
- 创建好所需目录后,打开两个终端(也可以安装idea,<1>在idea中运行,<2>,<3>,<4>在终端运行),一个执行实验(1)代码,一个执行实验(2)、(3)、(4)
- 在实验(2)、(3)、(4)打包完以后,先执行实验(1)代码,然后再执行(2)、(3)、(4)
3.实验代码
(1)
- /*===================================================*/
- 这一部分代码,我是在idea中运行的,你也可以开两个终端,在其中
- 一个打包运行,
- /*===================================================*/
-
-
-
- import java.io.{File, PrintWriter}
-
- object GenFile{
- def main(args: Array[String]) {
- val strList = List(
- "There are three famous bigdata softwares",
- "and they are widely used in real applications",
- "For in that sleep of death what dreams may come",
- "The slings and arrows of outrageous fortune",
- "When we have shuffled off this mortal coil",
- "For who would bear the whips and scorns of time",
- "That patient merit of the unworthy takes",
- "When he himself might his quietus make",
- "To grunt and sweat under a weary life",
- "But that the dread of something after death",
- "And makes us rather bear those ills we have",
- "Than fly to others that we know not of",
- "Thus conscience does make cowards of us all",
- "And thus the native hue of resolution",
- "And enterprises of great pith and moment",
- "And lose the name of action"
- )
- var i = 0
- while (i < 10000){
- Thread.sleep(scala.util.Random.nextInt(5000))
- // 生成一个0到999之间的随机数,并转换为字符串
- var str = scala.util.Random.nextInt(1000).toString
- val filePath = "/home/qiangzi/data/out"+str+".txt"
- // 创建PrintWriter对象,用于写入文件
- val out = new PrintWriter(new File(filePath))
- // 随机选择列表中的句子并写入文件
- for (m <- 0 to 3) out.println(strList(scala.util.Random.nextInt(14)))
- out.close
- i = i + 1
- }
- }
- }
(2)
- cd
- mkdir ./wordcount
- mkdir -p ./wordcount/src/main/scala
- vim ./wordcount/src/main/scala/WordCount.scala
- /* WordCount.scala*/
- import org.apache.spark._
- import org.apache.spark.streaming._
- import org.apache.spark.SparkContext._
- object WordCount{
- def main(args: Array[String]) {
- val sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
- //设置为本地运行模式,两个线程,一个监听,另一个处理数据
- val sc = new SparkContext(sparkConf)
- sc.setLogLevel("ERROR")
- val ssc = new StreamingContext(sc, Seconds(10)) // 时间间隔为10秒
- val lines = ssc.textFileStream("file:///home/qiangzi/data") // 设置文件流监控的目录
- val words = lines.flatMap(_.split(" "))
- val wordCounts = words.count()
- wordCounts.print()
- ssc.start()
- ssc.awaitTermination()
- }
- }
-
- cd ~/wordcount
- vim simple.sbt
- /*simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies ++= Seq(
- "org.apache.spark" %% "spark-core" % "3.5.1",
- "org.apache.spark" %% "spark-sql" % "3.5.1",
- "org.apache.spark" %% "spark-streaming" % "3.5.1" // 添加spark-streaming依赖
- )
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- /usr/local/spark-3.5.1/bin/spark-submit --class "WordCount" --driver-java-options "-Dfile.encoding=UTF-8" ~/wordcount/target/scala-2.12/simple-project_2.12-1.0.jar
(3)
- cd
- mkdir ./wordcount1
- mkdir -p ./wordcount1/src/main/scala
- vim ./wordcount1/src/main/scala/WordCountOne.scala
- import org.apache.spark._
- import org.apache.spark.streaming._
- import org.apache.spark.SparkContext._
- import org.apache.spark.streaming.StreamingContext._
-
- object WordCount {
- def main(args: Array[String]) {
- // 设置Spark配置,应用程序名为"WordCountMinute",并设置本地模式运行,使用2个线程
- val sparkConf = new SparkConf().setAppName("WordCountMinute").setMaster("local[2]")
- val sc = new SparkContext(sparkConf)
- sc.setLogLevel("ERROR")
- // 创建StreamingContext对象,设置批处理间隔为10秒
- val ssc = new StreamingContext(sc, Seconds(10))
-
- // 设置数据源为文件流,监控指定目录下的文件变化
- val lines = ssc.textFileStream("file:///home/qiangzi/data")
-
- // 将每行文本分割成单词
- val words = lines.flatMap(_.split(" "))
-
- // 创建一个窗口化的DStream,窗口大小为60秒,滑动间隔为10秒
- val windowedWords = words.window(Seconds(60), Seconds(10))
- val wordCounts = windowedWords.flatMap(word => Array((word, 1)))
- .reduceByKey(_ + _)
- var outputCount = 0
-
- // 对每个RDD进行操作,打印每个单词的计数
- wordCounts.foreachRDD { rdd =>
- // 增加输出计数
- outputCount += 1
- // 获取当前系统时间的毫秒数
- val currentTime = System.currentTimeMillis()
- println(s"-------------------------------------------")
- println(s"Time: $currentTime ms")
- println(s"-------------------------------------------")
- // 遍历RDD中的每个元素,打印单词和对应的计数
- rdd.foreach { case (word, count) =>
- println(s"$word: $count")
- }
-
- // 如果输出次数达到6次,则停止SparkContext和StreamingContext
- if (outputCount == 6) {
- println("Finished printing word counts for the last time.")
- ssc.stop(stopSparkContext = true, stopGracefully = true)
- }
- }
- ssc.start()
- ssc.awaitTermination()
- }
- }
-
- cd ~/wordcount1
-
- vim simple.sbt
-
- /*simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies ++= Seq(
- "org.apache.spark" %% "spark-core" % "3.5.1",
- "org.apache.spark" %% "spark-sql" % "3.5.1",
- "org.apache.spark" %% "spark-streaming" % "3.5.1" // 添加spark-streaming依赖
- )
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- /usr/local/spark-3.5.1/bin/spark-submit --class "WordCountOne" --driver-java-options "-Dfile.encoding=UTF-8" ~/wordcount1/target/scala-2.12/simple-project_2.12-1.0.jar
(4)
- cd
- mkdir ./wordcount2
- mkdir -p ./wordcount2/src/main/scala
- vim ./wordcount2/src/main/scala/WordCountTwo.scala
-
- import org.apache.spark._
- import org.apache.spark.streaming._
- import org.apache.spark.SparkContext._
- import org.apache.spark.streaming.StreamingContext._
- import java.text.SimpleDateFormat
- import java.util.Date
-
- object WordCountWithFileOutput {
- def main(args: Array[String]) {
- val sparkConf = new SparkConf().setAppName("WordCountWithFileOutput") .setMaster("local[2]") // 设置本地模式,使用2个线程
- val sc = new SparkContext(sparkConf) // 创建Spark上下文
- sc.setLogLevel("ERROR")
-
- val ssc = new StreamingContext(sc, Seconds(10)) // 创建Streaming上下文,设置批处理时间为10秒
-
- val lines = ssc.textFileStream("file:///home/qiangzi/data") // 监听目录,读取新增文件作为数据流
-
- val words = lines.flatMap(_.split(" ")) // 每行数据按空格切分,展平为单词流
-
- // 设置滑动窗口为6000秒长度,每10秒滑动一次(此处长度设置可能过大,实际使用中请根据需求调整)
- val windowedWords = words.window(Seconds(6000), Seconds(10))
- val wordCounts = windowedWords.flatMap(word => Array((word, 1))) .reduceByKey(_ + _) // 按单词聚合计数
-
- var outputCount = 0
- wordCounts.foreachRDD { rdd =>
- outputCount += 1
-
- val sdf = new SimpleDateFormat("yyyyMMdd_HHmmss") // 创建日期格式化对象
- val currentTimeStr = sdf.format(new Date(System.currentTimeMillis()))
- // 遍历RDD,将每个单词及其计数写入文件
- rdd.foreach { case (word, count) =>
- val outputFile = s"/home/qiangzi/dataout/${currentTimeStr}_wordcount.txt" // 构造输出文件路径
- val content = s"$word: $count\n"
- val bw = new java.io.BufferedWriter(new java.io.FileWriter(outputFile, true)) // 创建写入文件的对象
- bw.write(content)
- bw.close()
- }
-
- // 当输出计数达到600次时,停止SparkContext和StreamingContext
- if (outputCount == 600) {
- println("Finished writing word counts to files for the last time.")
- ssc.stop(stopSparkContext = true, stopGracefully = true)
- }
- }
- ssc.start()
- ssc.awaitTermination()
- }
- }
-
- cd ./wordcount2
-
- vim simple.sbt
-
- /*simple.sbt*/
- name := "Simple Project"
- version := "1.0"
- scalaVersion := "2.12.18"
- libraryDependencies ++= Seq(
- "org.apache.spark" %% "spark-core" % "3.5.1",
- "org.apache.spark" %% "spark-sql" % "3.5.1",
- "org.apache.spark" %% "spark-streaming" % "3.5.1" // 添加spark-streaming依赖
- )
-
- /usr/local/sbt-1.9.0/sbt/sbt package
-
- /usr/local/spark-3.5.1/bin/spark-submit --class "WordCountWithFileOutput" --driver-java-options "-Dfile.encoding=UTF-8" ~/wordcount2/target/scala-2.12/simple-project_2.12-1.0.jar

