
- 1Cesium介绍及3DTiles数据加载时添加光照效果对比_cesium光照
- 2RabbitMQ的死信队列详解及实现_获取死信队列中的信息
- 3PeLK:通过周边卷积的参数高效大型卷积神经网络
- 4react 暂存数据持久化_react store 数据持久化
- 5Map集合和Collections(集合工具类)_collections工具类中的binarysearch()方法中的key是map中的键吗
- 6如何解决Git合并分支造成的冲突_git合并出现冲突是如何解决的
- 7jmeter 性能测试结果分析_jmeter结果分析
- 8在Git上放一个静态页面并且可以访问_gitlab 怎么发布静态页面
- 9机械臂视觉抓取总结_机械臂目标定位与抓取
- 10Jupyter 进阶教程
【多模态LLM】(task1)Sora相关技术路径
赞
踩
note
注意:sora虽然未开源,但这个系列是学习常见text-to-video模型背后的原理。
Sora能力总结:
- Text-to-video: 文生视频
- Image-to-video: 图生视频
- Video-to-video: 改变源视频风格or场景
- Extending video in time: 视频拓展(前后双向),比如通过prompt针对某个视频增加对应的前置视频等
- Create seamless loops. Tiled videos that seem like they never end
- lmage generation: 图片生成(size最高达到 2048x2048)
- Generate video in any format: From 1920 x 1080 to 1080x 1920 视频输出比例自定义
- Simulate virtual worlds:链接虚拟世界,游戏视频场景生成
- Create avideo:长达60s的视频并保持人物、场景一致性
零、2023年AI视频生成时间线
2023年是AI生成视频技术爆炸性发展的一年。这些视频剪辑生成模型关注时间一致性、内容控制和视频长度。
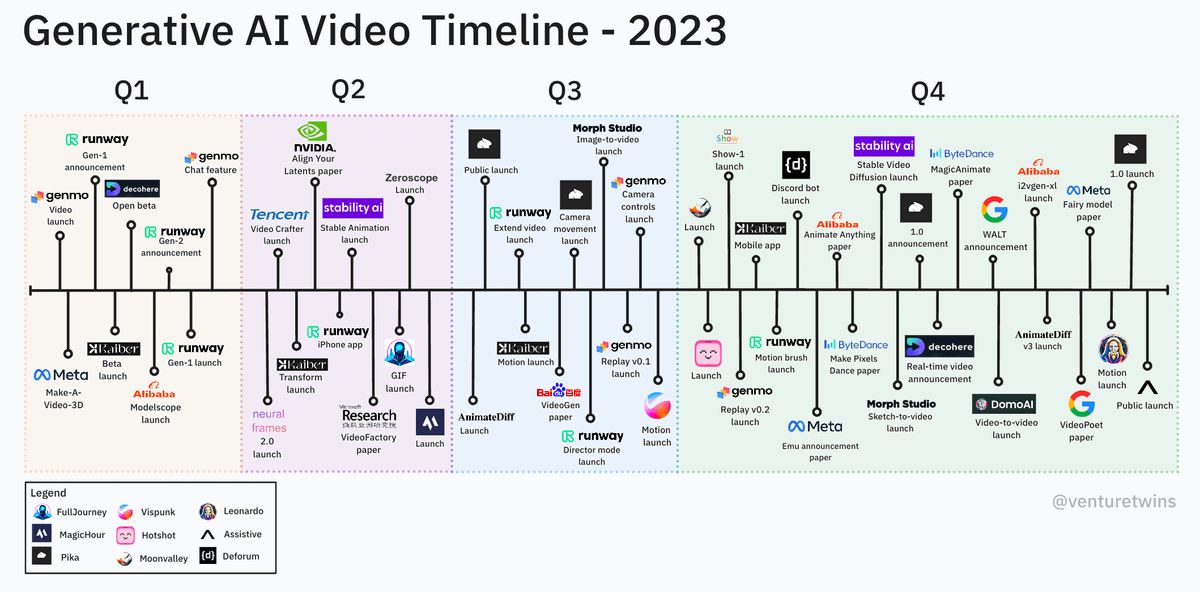
来源:https://briansolis.com/2024/01/generative-insights-in-ai-january-5-2024/
一、Sora模型
2024开年发布的Sora模型是OpenAI推出的首款AI视频模型,它代表了AI视频工具领域的一个重要进步。
Sora模型的一个重要特点是它能够生成长达一分钟的连贯视频,这是一个显著的进步。对于短视频来说已经是一个完整的时长,而对于其他AI视频工具来说,3秒的视频长度可能连视频素材的门槛都未达到。Sora的出现,使得从图文工作者无缝切换为视频工作者的目标更近了一步,因为它可以直接根据脚本生成成品视频。
总的来说,Sora模型的发布标志着AI视频生成领域的一次重大飞跃,它为视频内容的生产和创作提供了新的可能性
1. Sora的优缺点
优点:
- 最大支持60秒高清视频生成,以及基于已有短视频的前后扩展,同时保持人物/场景的高度一致性。
- 如奶茶般丝滑过渡的视频融合能力
- 同一场景的多角度/镜头的生成能力。
- 具有动态摄像机运动的视频。随着摄像机的移动和旋转,人和其他场景元素在三维空间中一致地移动。
- 支持任意分辨率,宽高比的视频输出。
缺点:Sora对物理规律的理解仍然十分有限
2. Sora目前的功能
图片生成
- Image generation(Text to Image文生图能力): 图片生成 (size最高达到 2048 x 2048)
基本功能
- Text-to-video: 文生视频
- Image-to-video: 图生视频
- Create a video: 长达60s的视频并保持人物、场景一致性
- Create seamless loops: Tiled视频像是他们没有结束一样
- Generate video in any format(生成任意格式视频): From 1920 x 1080 to 1080 x 1920 视频输出比例自定义
扩展
- Video-to-video: 改变源视频风格or场景
- Extending video in time: 视频拓展(前后双向)
- Simulate virtual worlds:链接虚拟世界,游戏视频场景生成,针对未来游戏开发
二、Sora模型的训练流程
Openai在Sora论文的摘要结尾指出:Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
openai希望Sora模型能够真正理解物理世界。
Sora发表文献:
https://openai.com/research/video-generation-models-as-world-simulators
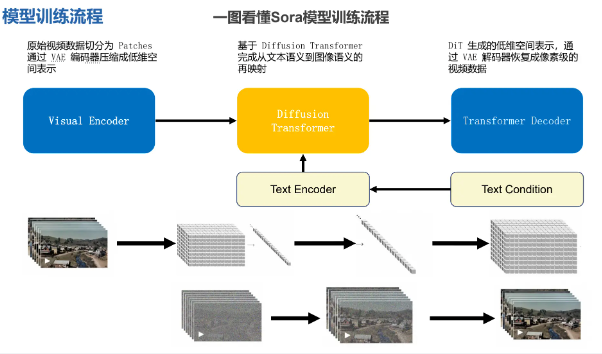
Sora模型训练流程一句话:就是将高维视频降维到低维数据加上文本编码,再还原回高维视频的过程。
但Sora的很多技术并非原创,而是整合了很多前人的研究成果。
- Patches:视频分割的最小的数据组
- 编码器:VAE,Visual Encoder
- Diffussion扩散模型:用于图片生成
- Transformer:文本编码与解码模型
- DiT:Diffussion+Transformer
视频分割为Patches
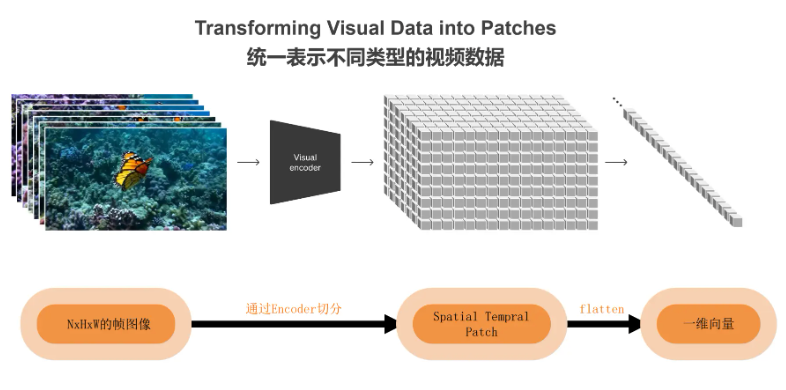
NxHxW是描述一个多维数组或张量(Tensor)维度大小的常见表示方式,特别是在计算机视觉和机器学习领域。这里的N、H和W分别代表不同的维度,具体含义如下:
- N:通常代表批处理大小(Batch Size),即一次处理的数据样本数量。
- H:代表高度(Height),通常用于表示图像或特征图的高度(以像素为单位)。
- W:代表宽度(Width),通常用于表示图像或特征图的宽度(以像素为单位)。
例如,如果一个张量的维度表示为10x128x128,那么这意味着:
- 批处理大小为10,即一次处理10张图像。
- 每张图像的高度为128像素。
- 每张图像的宽度也为128像素。
这种表示方法有助于快速理解数据或模型输入的形状和大小,对于进行深度学习模型设计和调试非常重要。
将NxHxW的帧图像通过编码器切分,得到Patches,将patches展开(flatten)为一维向量。
"Spatial Temporal Patch"可能是指“Spatiotemporal Patch Shift (TPS)”方法,这是一种用于视频基础的动作识别的3D自我注意力建模方法。这个方法是为了解决在视频数据上直接应用时空变压器所带来的计算和内存负担。它通过在时间维度上以特定的马赛克模式移动部分补丁,将标准的空间自我注意力操作转换为时空操作,几乎不增加额外的成本。因此,可以以与2D自我注意力几乎相同的计算和内存成本来计算3D自我注意力。这个方法作为即插即用的模块,可以插入到现有的2D变压器模型中,以增强时空特征学习。它在Something-something V1 & V2、Diving-48和Kinetics400上的表现与最先进的方法相当,同时在计算和内存成本上更为高效。
Sora模型的训练
扩散模型 DDPM
目前所采用的扩散模型大都是来自于2020年的工作DDPM: Denoising Diffusion Probabilistic Models,DDPM对之前的扩散模型(具体见Deep Unsupervised Learning using Nonequilibrium Thermodynamics)进行了简化,并通过变分推断(variational inference)来进行建模,这主要是因为扩散模型也是一个隐变量模型(latent variable model),相比VAE这样的隐变量模型,扩散模型的隐变量是和原始数据是同维度的,而且推理过程(即扩散过程)往往是固定的。
来源:扩散模型之DDPM
对图片加噪点,让图片逐渐变成纯噪点图;再让 AI 学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。这个模型就是 AI 绘画中各种算法,如Disco Diffusion、Stable Diffusion中的常客扩散模型(Diffusion Model)。
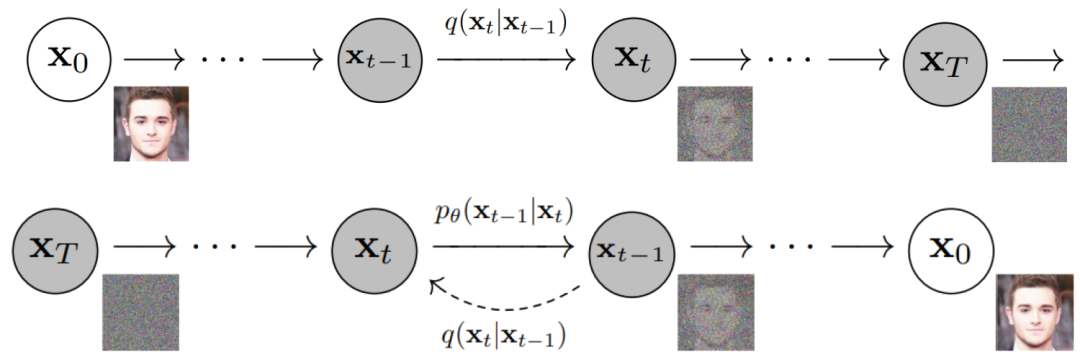
来源:Papers with Code - Denoising Diffusion Probabilistic Models

如下图,训练时使用真实的狗狗图片,经过扩散和反扩散生成AI版狗狗图片
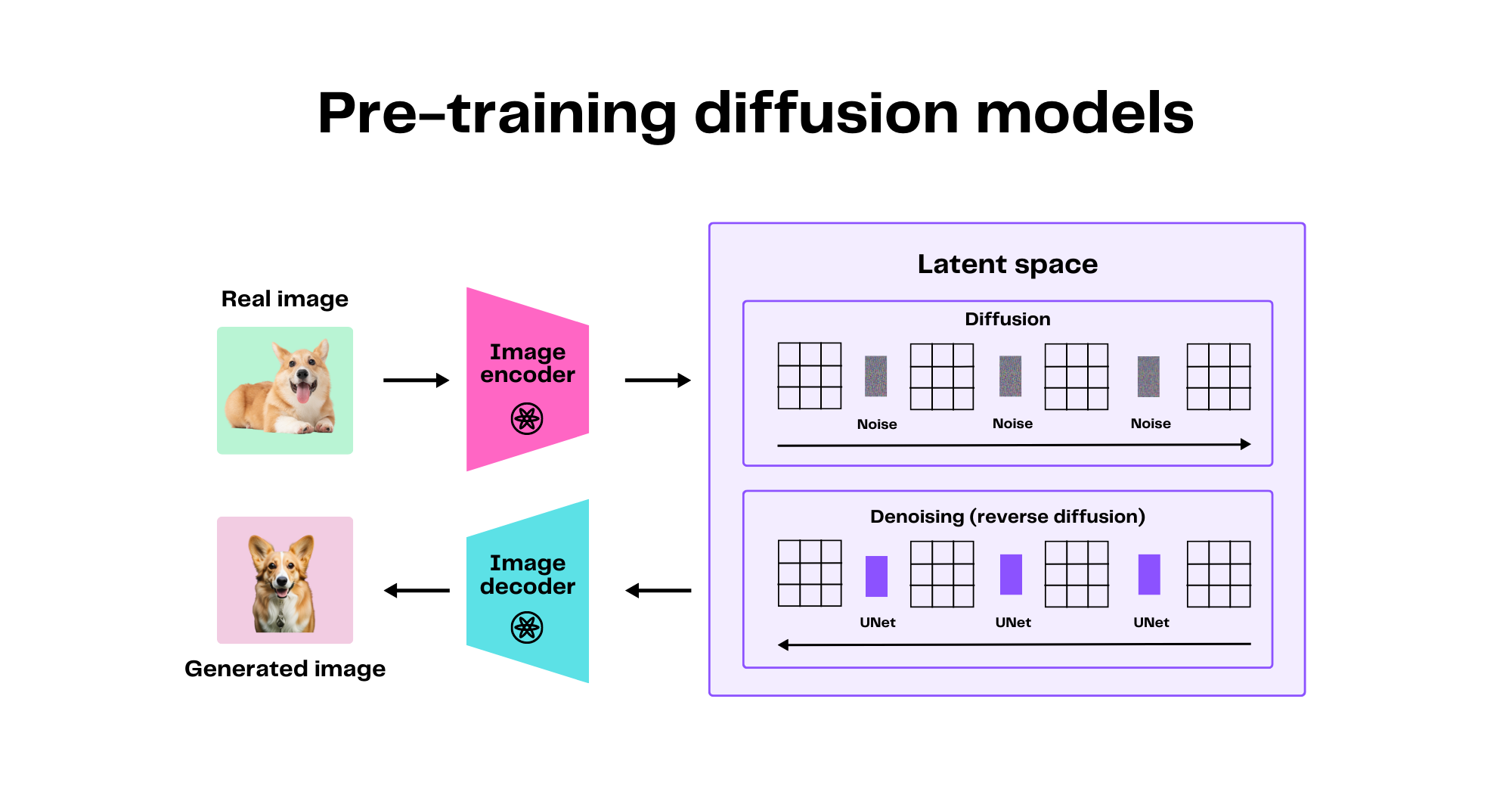
来源:The two models fueling generative AI products: Transformers and diffusion models
基于扩散模型的主干 U-Net
U-net是一种卷积神经网络(CNN),最初是为了医学图像分割而设计的。
它的特点是具有对称的“U”形结构,左侧是收缩路径(编码器),右侧是扩张路径(解码器)。
U-net在编码器和解码器之间使用了跳跃连接,使得模型能够保留更多的位置信息,这对于图像分割非常重要。
U-net可以作为Diffusion模型中的去噪网络。在Diffusion模型中,去噪过程涉及到逐步恢复数据的过程,U-net由于其特殊的结构和跳跃连接,能够有效地恢复图像的细节和结构信息,因此在某些Diffusion模型中,U-net被用作去噪网络。
U-net主要用于图像分割等像素级别的预测任务,而Diffusion模型是一种生成模型,用于生成新的图像或其他类型的数据。
U-net的结构是固定的,而Diffusion模型的结构更加灵活,可以使用不同的去噪网络。
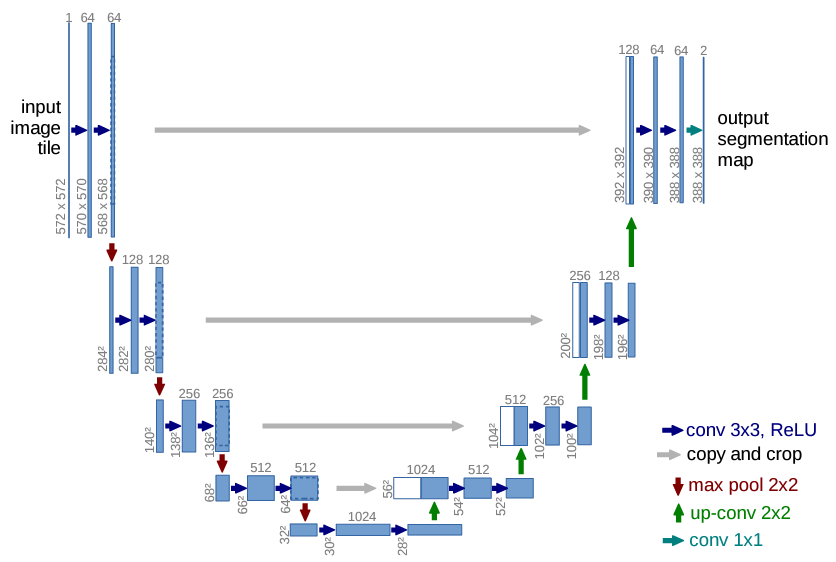
来源:Papers with Code - U-Net: Convolutional Networks for Biomedical Image Segmentation
- U-Net 网络模型结构把模型规模限定;
- SD/SDXL 作为经典网络只公布了推理和微调;(SD:Stable Diffussion)
- 国内主要基于 SD/SDXL 进行二次创作;
Latent Diffusion模型
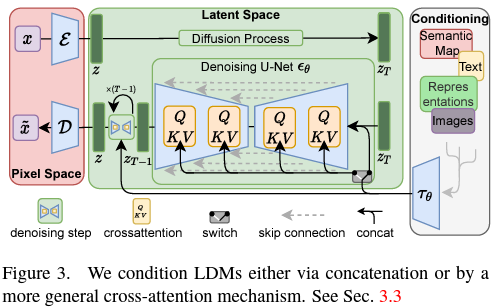
来源:Papers with Code - High-Resolution Image Synthesis with Latent Diffusion Models
Latent Diffusion Models (LDMs) 是一类特殊的Diffusion Models,它们在一个压缩的潜在空间内操作,而不是直接在数据的原始空间内。这种方法使得模型能够以更高的效率和较低的计算成本生成高质量的图像、文本或其他类型的数据。LDM通过学习潜在空间中的数据分布,然后应用扩散过程来生成或编辑数据。
- 主要特点:
- 在潜在空间中工作:与传统的Diffusion Models直接在数据的原始空间中工作不同,LDMs在一个经过压缩的潜在空间中进行操作,这有助于提高计算效率。
- 高效的数据生成:由于在压缩的潜在空间中操作,LDMs能够以更低的计算成本生成数据,同时保持高质量的输出。
- 广泛的应用范围:LDMs适用于多种类型的数据生成任务,包括图像、文本和音频生成。
- 创新点:
- 潜在空间的优化:LDMs的核心创新之一是在一个经过优化的潜在空间内进行扩散过程,这提高了生成效率和质量。
- 高效的学习过程:通过在潜在空间而不是原始数据空间内进行学习,LDMs能够更高效地处理大规模数据集和复杂的数据类型。
- 参考文献:
- Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models,” CVPR, 2022. https://paperswithcode.com/paper/high-resolution-image-synthesis-with-latent
- Jonathan Ho, Ajay Jain, Pieter Abbeel, “Denoising Diffusion Implicit Models,” ICLR, 2021. https://paperswithcode.com/paper/denoising-diffusion-implicit-models-1
Latent Diffusion Models的开发提供了一种新的视角来看待和解决生成模型中的效率和质量问题,特别是在处理高分辨率图像和复杂数据结构时。通过在潜在空间内操作,LDMs展现了在保持生成内容质量的同时减少计算资源需求的潜力。
Sora的技术架构图
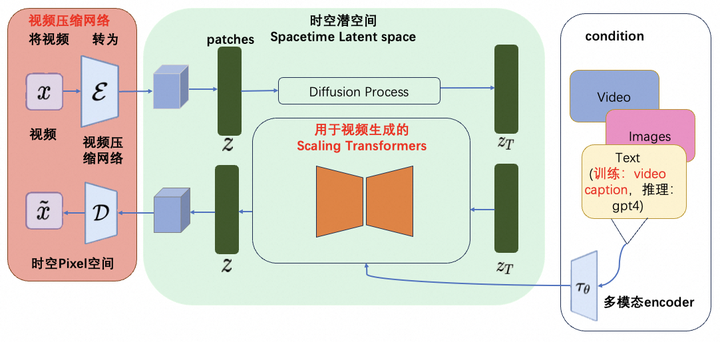
来源:复刻Sora有多难?一张图带你读懂Sora的技术路径-阿里云开发者社区
OpenAI发布的视频生成模型Sora,具备生成高保真视频的能力,是构建物理世界通用模拟器的一种可能路径。Sora的技术架构包括视频压缩网络、用于视频生成的Scaling Transformers、语言理解以及涌现的模拟能力。该模型的实现基于OpenAI的历史技术工作,如视觉理解、Transformers模型和大模型的涌现、Video Caption等。
三、Sora关键技术拆解
将图片/视频拆解为patches
einops是一个用于操作张量的库,它的出现可以替代我们平时使用的reshape、view、transpose和permute等操作einops支持numpy、pytorch、tensorfrflow等。

ViT:Vision Transformer编码器
- ViT 尝试将标准 Transformer 结构直接应用于图像;
- 图像被划分为多个 patch后,将二维 patch 转换为一维向量作为 Transformer 的输入;
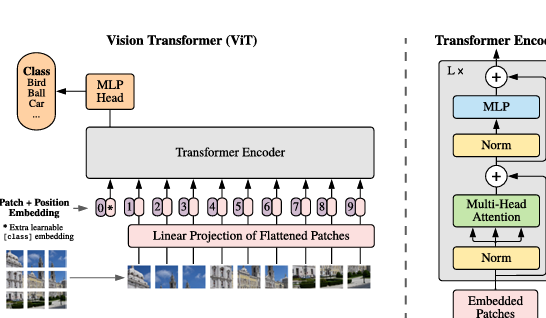
来源:Papers with Code - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
ViT的应用:Papers with Code - Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text
ViT在线运行示例:https://colab.research.google.com/github/SiYangming/sora-tutorial/blob/main/docs/chapter2/chapter2_3/ViT-BestPractice.ipynb
时空编码:Spacetime latent patches
Sora通过创新的时空patches和灵活的建模将静态图像转换为逼真的视频
- Sora 在视频生成方面的创新:Sora 对时空patches的创新使用为 AI 如何将静态图像转换为动态、逼真的视频提供了答案。Sora 的推出标志着一种范式转变,它结合了新的建模技术和处理各种持续时间、宽高比和分辨率的灵活性。
- 增强的视频生成功能:Sora 的扩散变压器模型结合了扩散和变压器架构,可实现文本到视频、图像到视频、视频风格转换、无缝循环等功能。Sora 能够创建各种格式的视频、模拟虚拟世界以及在一分钟内生成视频的能力进一步展示了其多功能性。
- Sora的烹饪比喻:传统的视频生成模型就像厨师严格遵循食谱一样,受到已知算法的限制并专注于特定类型的视频。相比之下,Sora被比喻为新型厨师,食材和技术灵活,可以创作出多样化的高品质视频。
- 通过时空patches提高效率:Sora 使用时空patches来提高视频生成的效率,与现有的建模架构相比,可以更有效地从大型数据集进行学习,并减少计算要求。该方法增强了模型生成高保真视频的能力,而无需调整或预处理输入视频数据。
- 掌握 3D 和连续性:Sora 的演示展示了其以令人印象深刻的精度建模 3D 空间和对象持久性的能力,即使在对象被遮挡或离开框架时也能实现逼真的运动和交互。该模型学会了准确地模拟物理世界,使数字对象和角色在三维空间中令人信服地移动。
参考:https://towardsdatascience.com/explaining-openai-soras-spacetime-patches-the-key-ingredient-e14e0703ec5b
摊大饼法:从输入视频剪辑中均匀采样 n_t 个帧,使用与ViT相同的方法独立地嵌入每个2D帧(embed each 2D frameindependently using the same method as ViT),并将所有这些token连接在一起
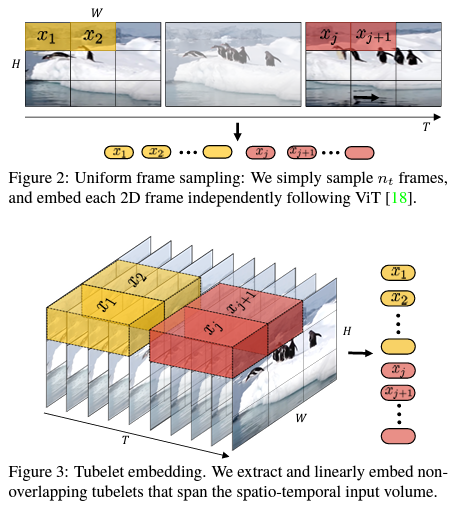
将输入的视频划分为若干tuplet,每个tuplet会变成一个token;
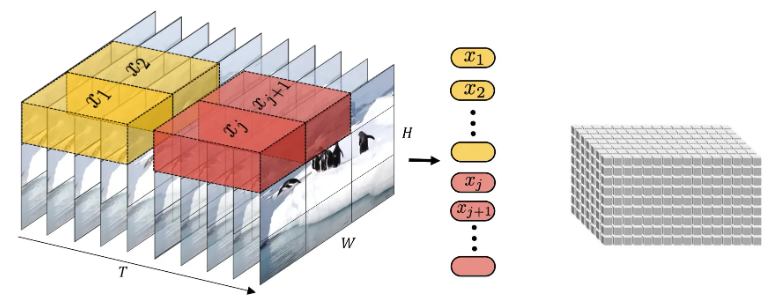
经过Spatial Temperal Attentioni进行空间/时间建模获得有效的视频表征token,即上图灰色block。
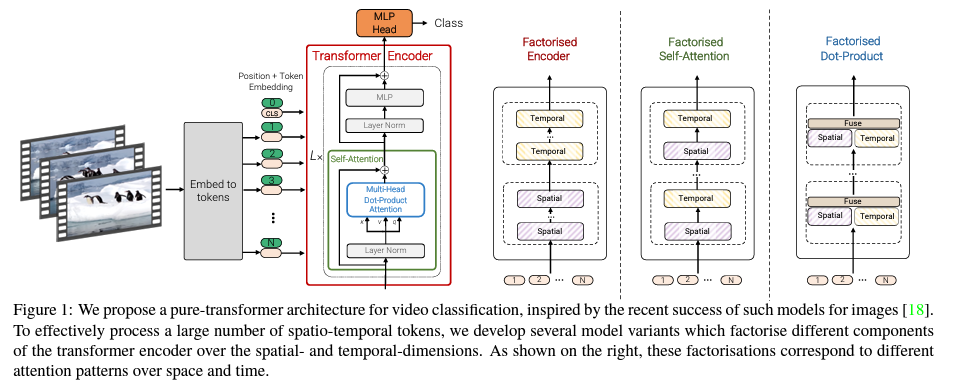
时空patches联合建模是 Sora 的核心创新,它建立在 Google DeepMind 对 NaViT 和 ViT 的早期研究之上,使模型能够灵活地有效处理视觉数据,而无需调整大小或填充。
ViViT:视频ViT
ViViT基于纯变压器的视频模型分类,借鉴了ViT图像分类中取得的成功。 ViViT从输入视频中提取时空标记,然后由一系列转换器层进行编码。
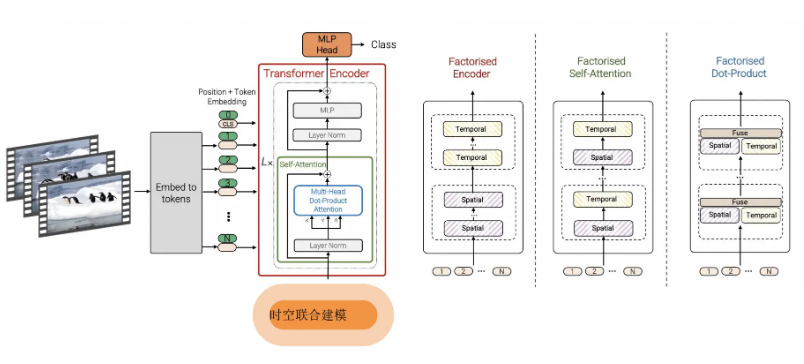
来源:Papers with Code - ViViT: A Video Vision Transformer
SORA 支持不同长度、不同分辨率的输入:NaViT多个patchesa打包成一个单一序列实现可变分辨率–》使用不同分辨率、不同时长的视频进行训练保证推理时在不同长度和分辨率上的效果–》带来大量的计算负载不均衡–》可能使用Googlef的NaVit相关技术降低计算量支持动态输入
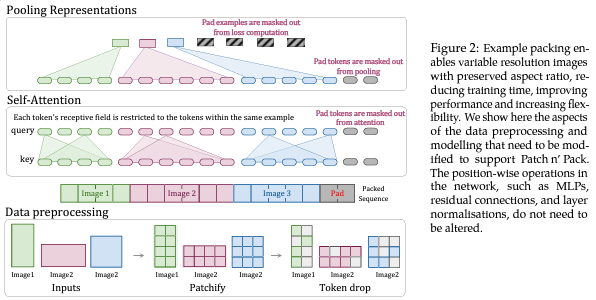
来源:Papers with Code - Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
质量训练数据的作用:Sora 利用庞大且多样化的训练数据集,其中包含不同长度、分辨率和长宽比的视频和图像,使其能够理解复杂的动态并生成多样化的高质量内容。
四、技术难点
技术难点1
视频压缩网络类比于Latent Diffusion Model中的VAE,但压缩率是多少,Encoder的复杂度、时空交互的range还需要进一步的探索和实验。
Peebles 在ICCV上发表了一篇 Dit 的工作该文章在 Technical Report的 Reference中给出:结合 Diffusion Model 和 Transformer,通过 Scale up Model 提升图像生成质量图像的scaling技术运用到视频场景非常直观,可以确定是 SORA 的技术之一,训练算力Scale up后视频生成质量有所提升。
Diffusion Transformer, DiT=VAE encoder + ViT + DDPM + VAE
DiT 利用 transformer 结构探索新的扩散模型,成功用 transformer 替换 U-Net 主干
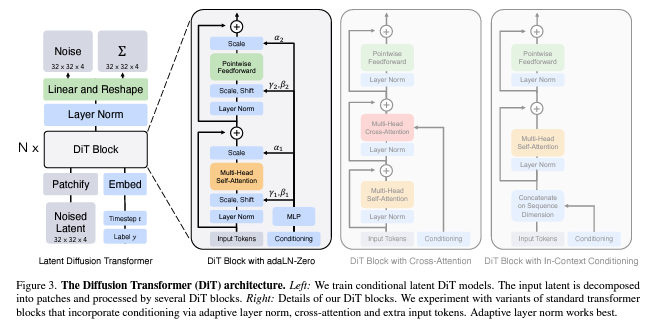
来源:Papers with Code - Scalable Diffusion Models with Transformers
- 例如输入一张256x256x3的图片,经过Encoder后得到对应的latent
- 推理时输入32x32x4的噪声,得到32x32x4的latent
- 结合当前的step t,输入label y,经过N个Dit Blocki通过MLP进行输出
- 得到输出的噪声以及对应的协方差矩阵
- 经过T个step采样,得到32x32x4的降噪后的latent
- 在训练时,需要使得去躁后的latent和第一步得到的latent尽可能一致
网络结构:Diffusion Transformer,DiT
- DiT 首先将将每个 patch 空间表示Latent 输入到第一层网络,以此将空间输入转换为 tokens 序列。
- 将标准基于 ViT 的 Patch 和Position Embedding 应用于所有输入token,最后将输入 token 由Transformer 处理。
- DiT 还会处理额外信息,e.g. 时间步长、类别标签、文本语义等。
技术难点2
- 训练数据很重要,具体怎么构建?
- Transformer Scale up到多大?
- 从头训练到收敛的trick?
- 如何实现Long Context(长达1分钟的视频)的支持->切断+性能优化
- 如何保证视频中实体的高质量和一致性?
技术分析报告
训练数据:OpenAI 使用类似 DALLE3 的Cationining 技术,训练了自己的 Video Captioner,用以给视频生成详尽的文本描述。
保证视频一致性:模型层不通过多个 Stage 方式来进行视频预测,而是整体预测视频的 Latent,在训练过程中引入 Auto Regressive的task,帮助模型更好地学习视频特征和帧间关系。
来源:Papers with Code - Photorealistic Video Generation with Diffusion Models
网络结构:DALLE 2
- 将文本提示输入文本编码器,该训练过的编码器便将文本提示映射到表示空间;
- 先验模型将文本编码映射到图像编码,图像编码捕获文本编码中的语义信息;
- 图像解码模型随机生成一幅从视觉上表现该语义信息的图像;
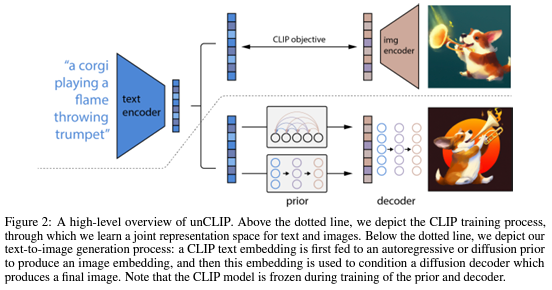
来源:Papers with Code - Hierarchical Text-Conditional Image Generation with CLIP Latents
五、多方讨论

杨知铮老师的思考:
- 算力:训练需要 200-400 张 A100,训练时间2-3个月
- Scaling Law:模型越大生成质量越高,解决视频一致性和连续性问题
- Data Engngine:数据工程很重要。如何设计视频的输入(e.g. 是否截断、长宽比、像素优化等)、patches 的输入方式、文本描述和文本图像对质量;
- AI Infrfrara:AI 系统(AI 框架、AI 编译器、AI 芯片、大模型)工程化能力是很大的技术壁垒,决定了 Scaling 的规模。
- LLM:LLM 大语言模型仍然是核心,多模态(文生图、图生文)都需要文本语义去牵引和约束生成的内容,CLIP/BLIP/GLIP 等关联模型会持续提升能力;
SORA的启发:
- 构建高密度优秀人才的小团队
- 不断试错,快速迭代,结果导向
- 真正的算法工程,需要懂算法、懂工程
- 坚定信念
扩展论文
- High-Resolution Image Synthesis with Latent Diffusion Models:https://paperswithcode.com/paper/high-resolution-image-synthesis-with-latent
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics:https://paperswithcode.com/paper/deep-unsupervised-learning-using
- Improved Denoising Diffusion Probabilistic Models:https://paperswithcode.com/paper/improved-denoising-diffusion-probabilistic-1
- Diffusion Models Beat GANs on Image Synthesis:https://paperswithcode.com/paper/diffusion-models-beat-gans-on-image-synthesis
- MAGVIT: Masked Generative Video Transformer:https://paperswithcode.com/paper/magvit-masked-generative-video-transformer
- U-ViT:All are Worth Words: A ViT Backbone for Diffusion Models:https://paperswithcode.com/paper/all-are-worth-words-a-vit-backbone-for-score
这篇论文介绍了一种名为U-ViT的新架构,它将扩散概率模型与Transformer结合。U-ViT的主要特点包括:- 图像生成领域的SOTA FID分数:U-ViT在图像生成领域展示了出色的性能,特别是在ImageNet256数据集上取得了SOTA的FID分数 2 。
- 多模态数据的融合:U-ViT展现了在多模态数据融合方面的强大能力,尤其是在没有额外数据的情况下,在MS-COCO数据集上的text-to-image generation任务中取得了SOTA FID 2 。
- 网络结构:U-ViT延续了ViT的方法,将带噪图片划分为多个patch,然后将时间t、条件c和图像patch视作token输入到Transformer block。同时,在网络浅层和深层之间引入了long skip connection 2 。
- long skip connection的重要性:long skip connection对于连接low-level feature提供了快捷方式,对图像生成的FID分数至关重要 2 。
- Patch size的影响:论文探讨了不同patch size对图像生成结果的影响,指出即使在不改变参数量的情况下,patch size的不同也会影响训练或推理所需的计算量 2 。
- 时间t的嵌入方法:研究了两种将时间t嵌入网络的方法,即将时间t视作token和类似于adaptive group normalization的方法 2 。
- 实验结果:U-ViT在CIFAT10、CelebA、ImageNet64、ImageNet256、ImageNet512和MSCOCO等数据集上进行了实验,并取得了与其他模型可比或更优的FID分数 2 2 。
- 与Latent Diffusion的比较:使用参数量和计算量相似的U-ViT替换掉Latent Diffusion中的U-Net,进一步证明了U-ViT的优越性 2 。
- U-ViT在线运行示例:https://colab.research.google.com/github/SiYangming/sora-tutorial/blob/main/docs/chapter2/chapter2_3/UViT_ImageNet_demo.ipynb
Reference
[1] 一文看Sora技术推演.阿里CV算法专家
[2] OpenAI王炸模型引爆科技圈,我们第一时间深读了官方技术报告.腾讯科技
[3] 魔搭社区基于ViT的扩散模型技术的开源教程: https://mp.weixin.qq.com/s/LQGwoU6xZJftmMtsQKde_w
[4] 复刻Sora有多难?一张图带你读懂Sora的技术路径.modelscope成晨
[5] https://datawhaler.feishu.cn/wiki/RKrCw5YY1iNXDHkeYA5cOF4qnkb?fromScene=spaceOverview#GWt8dCJcVodY0Nx6BdNcx2ohnif

