
热门标签
热门文章
- 1【pytorch】从零开始用语义分割网络(deeplab3+)训练自己的数据集
- 2经典Java面试题汇总及答案解析_java问题解析思路面试题
- 3Telegram邀请码机器人源码 自动发码 数量统计 无码提醒
- 4建模之常见优化器(Keras)_tf.keras.optimizers.ftrl
- 5毫米波雷达-2D-CFAR算法_2dcfar
- 6井喷式爆发!2022年11月100篇 diffusion models 扩散模型 汇总!
- 7人形机器人进展:IEEE Robotics出版双臂通用协同机械手操作架构
- 8【技术分享】select下拉框option默认选中(php模板渲染)_select默认选中option
- 9无恒实验室联合GORM推出安全好用的ORM框架-GEN,赶紧收藏起来
- 10【开源免费】Vue+SpringBoot打造假日旅社管理系统,初学者入门实战项目
当前位置: article > 正文
Pytorch 学习笔记05 神经网络搭建小实战及Sequential的使用,Loss函数、反向传播、优化函数的使用,现有网络模型的使用及修改,保存及读取_nn.sequential 如何loss函数
作者:盐析白兔 | 2024-05-05 07:32:35
赞
踩
nn.sequential 如何loss函数
Pytorch 学习笔记05
nn.sequential的使用
使用sequential,可以让搭建网络的代码更简洁,使用起来更方便。
神经网络搭建实战
利用CIFAR10数据集的模型进行搭建。
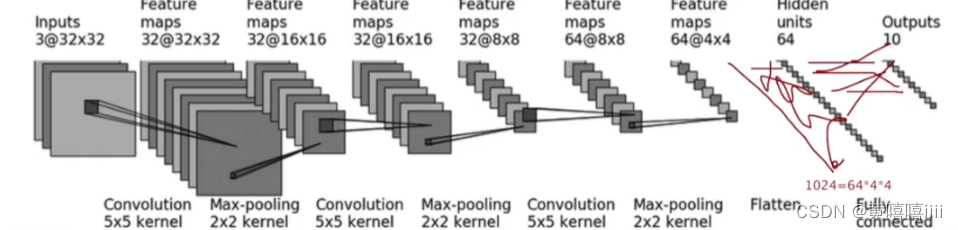
代码:
import torchvision
from torch import nn
from torch.utils.data import DataLoader
class Mynn(nn.Module):
def __init__(self):
super(Mynn, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, padding= 2), # stride使用默认值1,padding是根据官方文档里的公式计算得出
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64), # 1024 为 64 * 4 *4 得出
nn.Linear(64, 10)
)
def forward(self,x):
return self.model(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
卷积层中的padding是根据图中公式得出的。stride、dilation使用默认值。

Loss函数、反向传播、优化函数的使用
Loss函数用于计算训练结果与目标之间差距,Loss越小越好。
反向传播用来计算梯度,并通过optimization algorithms更新神经网络中的参数,进行优化。
代码:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
class Mynn(nn.Module):
def __init__(self):
super(Mynn, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, padding= 2), # stride使用默认值1,padding是根据官方文档里的公式计算得出
nn.MaxPool2d(2),
nn.Conv2d(32, 32, kernel_size=5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64), # 1024 为 64 * 4 *4 得出
nn.Linear(64, 10)
)
def forward(self,x):
return self.model(x)
dataset = torchvision.datasets.CIFAR10("./dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset,batch_size=1, drop_last=True)
mynn = Mynn()
# 定义loss函数
loss = nn.CrossEntropyLoss()
# 定义梯度优化函数
optim = torch.optim.SGD(mynn.parameters(), lr = 0.01)
for epoch in range(20): # 训练整个数据集20次
epoch_loss = 0.0 # 每次训练的总loss
for imgs, tars in dataloader:
outputs = mynn(imgs)
result_loss = loss(outputs,tars)
optim.zero_grad() # 每一批开始前,将梯度设为0,因为上一批的梯度对这一批没用
result_loss.backward() # 计算梯度
optim.step() # 优化
epoch_loss += result_loss # 计算总loss
print(f"第{epoch}轮训练的总loss为{epoch_loss}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
现有网络模型的使用及修改,保存及读取
以VGG16为例
使用及修改
主要参数:
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet # 如果为True,则返回在数据集ImageNet上训练后的模型;反之仅返回一个初始化的模型
progress (bool): If True, displays a progress bar of the download to stderr # 如果为 True,则显示下载到 stderr 的进度条
- 1
- 2
- 3
代码:
import torchvision
# 直接通过torchvision.models调用
from torch import nn
vgg16_False = torchvision.models.vgg16(pretrained=False)
vgg16_True = torchvision.models.vgg16(pretrained=True)
dataset = torchvision.datasets.CIFAR10("./dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True)
print(vgg16_True)
"""
查看该模型的层数,发现最后一层为Linear(in_features=4096, out_features=1000, bias=True)
out_features为1000,表示分类结果有1000个,
而CIFAR10模型的分类结果只有10个,所以要一层LInear,使得out_features=10
以两种方式来修改模型
"""
# 1.在模型后添加一层linear
vgg16_True.add_module("add_linear", nn.Linear(in_features=1000, out_features=10))
print(vgg16_True)
"""
这种方式是直接将该层加载VGG模型下,也可以加在 (classifier): 下面
"""
vgg16_True.classifier.add_module("add_linear", nn.Linear(in_features=1000, out_features=10))
print(vgg16_True)
# 2 直接修改(classifier):下的 (6): Linear(in_features=4096, out_features=1000, bias=True)
vgg16_False.classifier[6] = nn.Linear(in_features=4096, out_features=10, bias=True)
print(vgg16_False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
保存及读取
import torch
import torchvision
# 直接通过torchvision.models调用
from torch import nn
# 声明一个模型
vgg16_True = torchvision.models.vgg16(pretrained=True)
# 保存及读取
# 保存方式1, 既保存模型结构,也保存模型中的参数
torch.save(vgg16_True,"./vgg16_method1.pth") # 参数1:模型, 参数2:保存路径
# 保存方式1的加载模型
model1 = torch.load("./vgg16_method1.pth") # 模型的保存路径
# 保存方式2,以字典形式保存网络模型的参数,没有保存结构,(官方推荐)
torch.save(vgg16_True.state_dict(), "./vgg16_method2") # 参数1:模型里的参数,以字典形式保存; 参数2: 保存路径
# 保存方式2 加载模型
method2_model = torchvision.models.vgg16(pretrained=True) #创建一个新模型
method2_model_state = torch.load("./vgg16_method2") # 加载模型的参数
method2_model.load_state_dict(method2_model_state) # 将参数导入模型中
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/537859
推荐阅读
相关标签

