- 1【算法】逃离大迷宫
- 2java 字符串转utc时间_JAVA 本地时间字符串转UTC时间字符串
- 3基于 wemos d1 智能感应开盖垃圾桶_垃圾桶舵机
- 4Centos 8 安装RabbitMQ 3.8.4 (亲测可用)_socat centos8
- 5【C++进阶】哈希表的实现_c++ 哈希实现
- 6浙江大学python程序设计(陈春晖、翁恺、季江民)习题答案_def selsort(nums): n = len(nums) for bottom in ran
- 7单点登录(SSO)详解——超详细_sso单点登录
- 8自然语言处理(NLP)-BERT 实战-模型微调-情感分析
- 9Python 生成器
- 10在win7系统上使用Python3.8.10进行开发使用_python3 win7
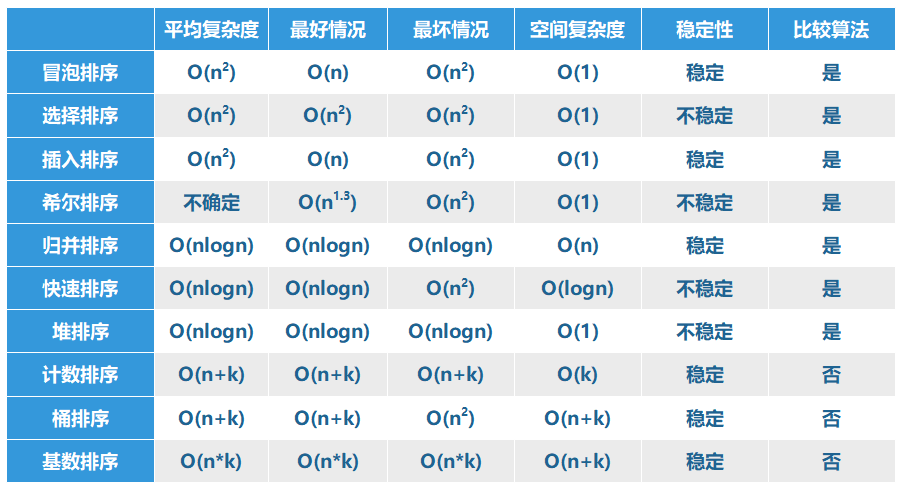
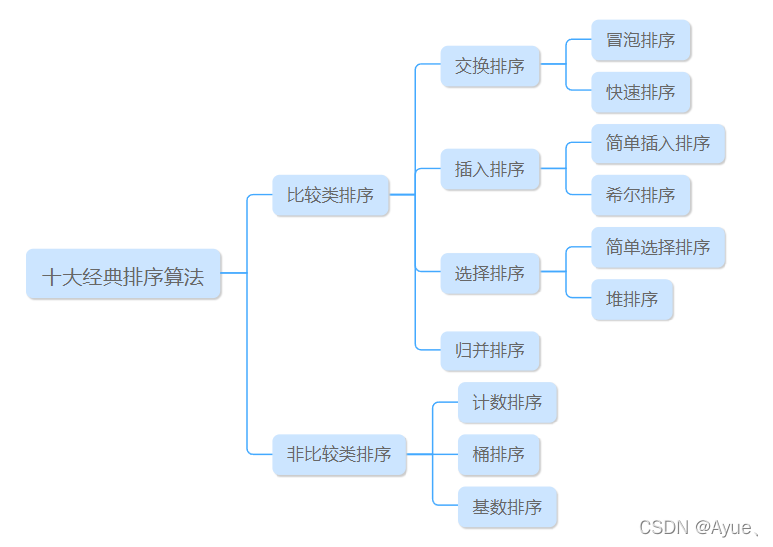
十大排序算法_假定在待排序的记录序列中
赞
踩
推荐几个动画演示的网站:
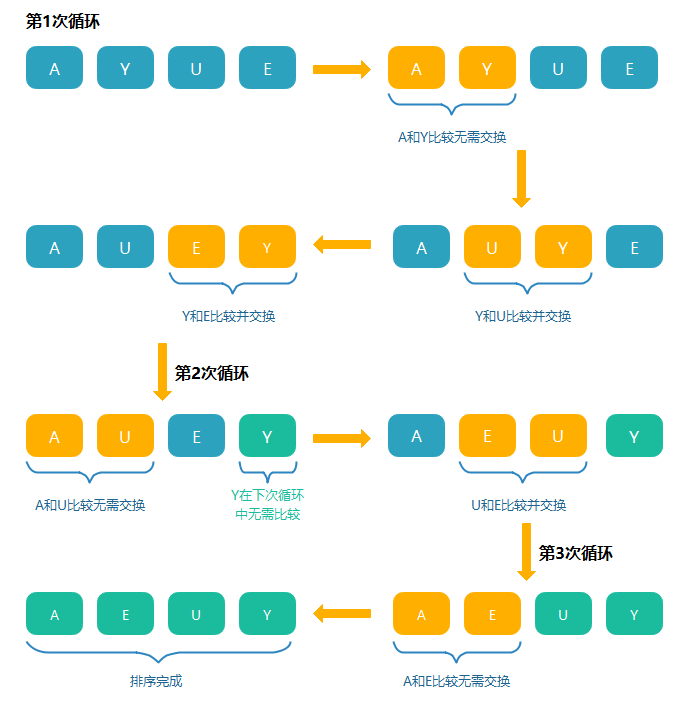
冒泡排序
- 从数组头开始,比较相邻的元素。如果第一个比第二个大(小),就交换它们两个
- 对每一对相邻元素作同样的工作,从开始第一对到尾部的最后一对,这样在最后的元素应该会是最大(小)的数
- 重复步骤1~2,重复次数等于数组的长度,直到排序完成
代码实现
对下面数组实现排序:{24, 7, 43, 78, 62, 98, 82, 18, 54, 37, 73, 9}
代码实现
public class BubbleSort { public static final int[] ARRAY = {24, 7, 43, 78, 62, 98, 82, 18, 54, 37, 73, 9}; public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } public static int[] sort(int[] array) { if (array.length == 0) { return array; } for (int i = 0; i < array.length; i++) { //array.length - 1 -i 已经冒泡到合适位置无需在进行排序,减少比较次数 for (int j = 0; j < array.length - 1 -i; j++) { //前面的数大于后面的数交换 if (array[j + 1] < array[j]) { int temp = array[j + 1]; array[j + 1] = array[j]; array[j] = temp; } } } return array; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
时间复杂度
对于上面12个数据项,从第一个元素开始,第一趟比较了11次,第二趟比较了10次,依次类推,一直到最后一趟,就是:
11 + 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 = 66次
- 1
若有n个元素,则第一趟比较为(n-1)次,第二趟比较为(n-2)次,依次类推:
(n-1) + (n-2) + (n-3) + ...+ 2 + 1 = n * (n-1)/2
- 1
在大O表示法中,去掉常数系数和低阶项,该排序方式的时间复杂度为:O(n2)
算法稳定性
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。——百度百科
在代码中可以看到,array[j + 1] = array[j]的时候,我们可以不移动array[i]和array[j],所以冒泡排序是稳定的。
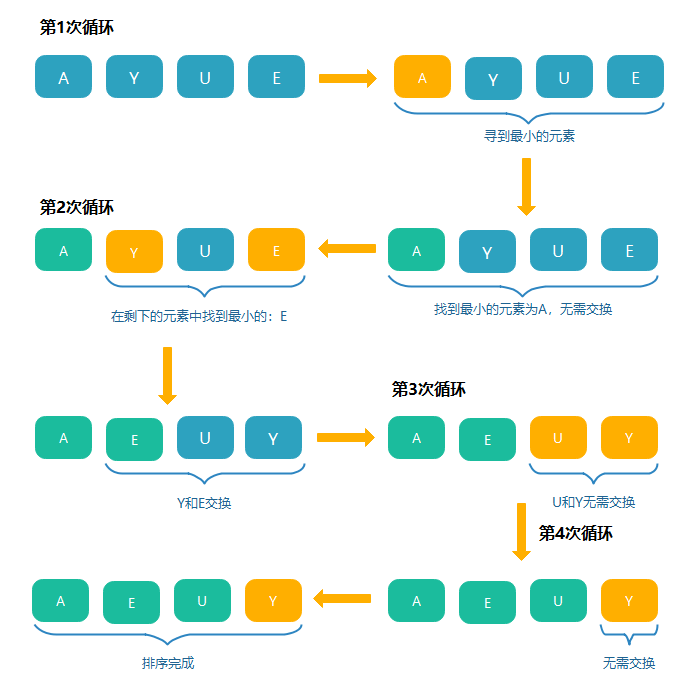
选择排序
- 找到数组中最大(或最小)的元素
- 将它和数组的第一个元素交换位置(如果第一个元素就是最大(小)元素那么它就和自己交换)
- 在剩下的元素中找到最大(小)的元素,将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。
代码实现
对下面数组实现排序:{87, 23, 7, 43, 78, 62, 98, 81, 18, 53, 73, 9}
动图演示

代码实现
public class SelectionSort { public static final int[] ARRAY = {87, 23, 7, 43, 78, 62, 98, 81, 18, 53, 73, 9}; public static int[] sort(int[] array) { if (array.length == 0) { return array; } for (int i = 0; i < array.length; i++) { //最小数的下标,每个循环开始总是假设第一个数最小 int minIndex = i; for (int j = i; j < array.length; j++) { //找到最小索引 if (array[j] < array[minIndex]) { //保存最小索引 minIndex = j; } } //最小索引的值 int temp = array[minIndex]; array[minIndex] = array[i]; array[i] = temp; } return array; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
时间复杂度
很明显,和冒泡排序相比,在查找最小(或最大)元素的索引,比较次数仍然保持为O(n2)
,但元素交换次数为O(n)。
算法稳定性
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果一个元素比当前元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么交换后稳定性就被破坏了。举个例子,数组5,8,5,2,9,我们知道第一遍选择第1个元素5会和2交换,那么原序列中两个5的相对前后顺序就被破坏了,所以选择排序是一个不稳定的排序算法。
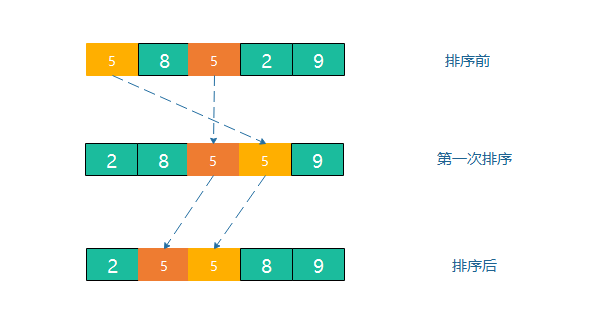
插入排序
当我们在玩扑克牌的时候,总是在牌堆里面抽取最顶部的一张然后按顺序在手中排列。
插入排序是指在待排序的元素中,假设前面n-1(其中n>=2)个数已经是排好顺序的,现将第n个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。
- 对于未排序数据(一般取数组的二个元素,把第一个元素当做有序数组),在已排序序列中从左往右扫描,找到相应位置并插入。
- 为了给要插入的元素腾出空间,需要将插入位置之后的已排序元素在都向后移动一位。
代码实现
对下面数组实现排序:{15, 51, 86, 70, 6, 42, 26, 61, 45, 81, 17, 1}
动图演示

代码实现
public class InsertionSort { public static final int[] ARRAY = {15, 51, 86, 70, 6, 42, 26, 61, 45, 81, 17, 1}; public static int[] sort(int[] array) { if (array.length == 0) { return array; } //待排序数据,改数据之前的已被排序 int current; for (int i = 0; i < array.length - 1; i++) { //已被排序数据的索引 int index = i; current = array[index + 1]; //将当前元素后移一位 while (index >= 0 && current < array[index]) { array[index + 1] = array[index]; index--; } //插入 array[index + 1] = current; } return array; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
时间复杂度
在上面图示中,第一趟循环比较一次,第二趟循环两次,依次类推,则最后一趟比较n-1次:
1 + 2 + 3 +… + n-1 = n*(n-1)/2
- 1
也就是说,在最坏的情况下(逆序),比较的时间复杂度为O(n2)
在最优的情况下,即while循坏总是假的,只需当前数跟前一个数比较一下就可以了,这时一共需要比较n-1次,时间复杂度为O(n)。
算法稳定性
在比较的时候,过两个数相等的话,不会进行移动,前后两个数的次序不会发生改变,所以插入排序是稳定的。
希尔排序
一种基于插入排序的快速的排序算法。简单插入排序对于大规模乱序数组很慢,因为元素只能一点一点地从数组的一端移动到另一端。例如,如果主键最小的元素正好在数组的尽头,要将它挪到正确的位置就需要n-1次移动。
希尔排序为了加快速度简单地改进了插入排序,也称为缩小增量排序。
希尔排序是把待排序数组按一定的数量分组,对每组使用直接插入排序算法排序;然后缩小数量继续分组排序,随着数量逐渐减少,每组包含的元素越来越多,当数量减至 1 时,整个数组恰被分成一组,排序便完成了。这个不断缩小的数量,就构成了一个增量序列,这里的数量称为增量。
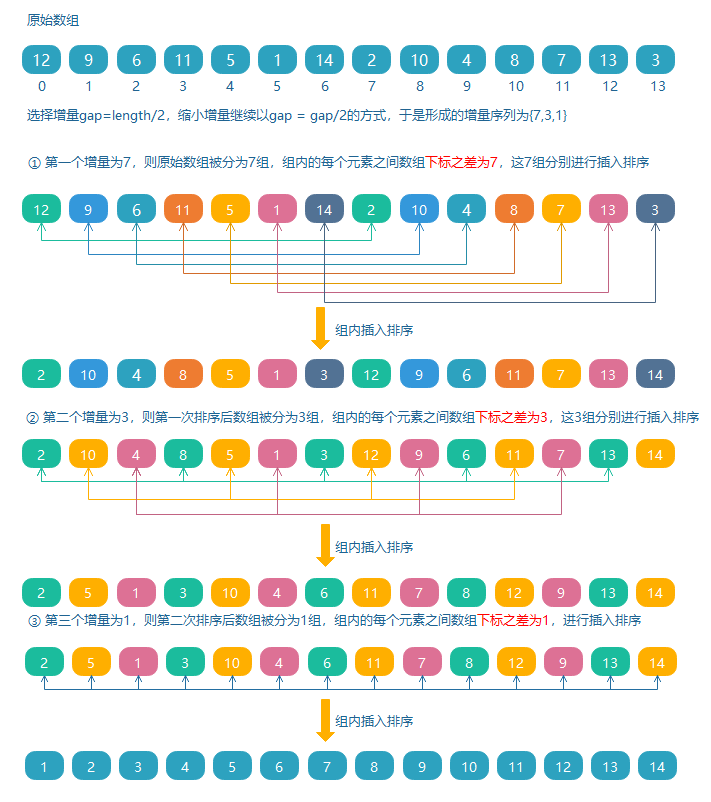
代码实现
public class ShellSort { public static final int[] ARRAY = {12, 9, 6, 11, 5, 1, 14, 2, 10, 4, 8, 7, 13, 3}; public static int[] sort(int[] array) { int len = array.length; if (len < 2) { return array; } //当前待排序数据,该数据之前的已被排序 int current; //增量 int gap = len / 2; while (gap > 0) { for (int i = gap; i < len; i++) { current = array[i]; //前面有序序列的索引 int index = i - gap; while (index >= 0 && current < array[index]) { array[index + gap] = array[index]; //有序序列的下一个 index -= gap; } //插入 array[index + gap] = current; } //int相除取整 gap = gap / 2; } return array; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
时间复杂度
希尔排序的复杂度和增量序列有关。
在先前较大的增量下每个子序列的规模都不大,用直接插入排序效率都较高,尽管在随后的增量递减分组中子序列越来越大,由于整个序列的有序性也越来越明显,则排序效率依然较高。
从理论上说,只要一个数组是递减的,并且最后一个值是1,都可以作为增量序列使用。有没有一个步长序列,使得排序过程中所需的比较和移动次数相对较少,并且无论待排序列记录数有多少,算法的时间复杂度都能渐近最佳呢?但是目前从数学上来说,无法证明某个序列是最好的。
常用的增量序列:
- 希尔增量序列 :{n/2, (n / 2)/2, …, 1},其中N为原始数组的长度,这是最常用的序列,但却不是最好的
- Hibbard序列:{2k-1, …, 3,1}
- Sedgewick序列:{… , 109 , 41 , 19 , 5,1} 表达式为9 * 4i- 9 * 2i + 1,i = 0,1,2,3,4…
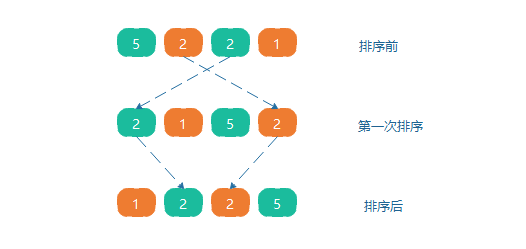
算法稳定性
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,如数组5,2,2,1,第一次排序第一个元素5会和第三个元素2交换,第二个元素2会和第四个元素1交换,原序列中两个2的相对前后顺序就被破坏了,所以希尔排序是一个不稳定的排序算法。
归并排序
归并,指合并,合在一起。归并排序(Merge Sort)是建立在归并操作上的一种排序算法。其主要思想是分而治之。什么是分而治之?分而治之就是将一个复杂的计算,按照设定的阈值进行分解成多个计算,然后将各个计算结果进行汇总。即“分”就是把一个大的通过递归拆成若干个小的,“治”就是将分后的结果在合在一起。
若将两个有序集合并成一个有序表,称为2-路归并,与之对应的还有多路归并。
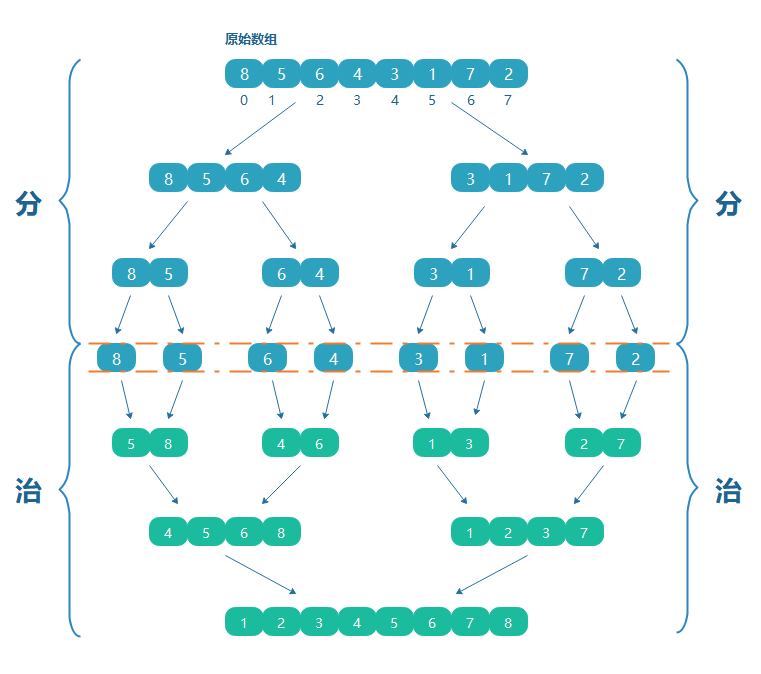
怎么分
- 对于排序最好的情况来讲,就是只有两个元素,这时候比较大小就很简单,但是还是需要比较
- 如果拆分为左右各一个,无需比较即是有序的。
怎么治
借助一个辅助空数组,把左右两边的数组按照大小比较,按顺序放入辅助数组中即可。
以下面两个有序数组为例:
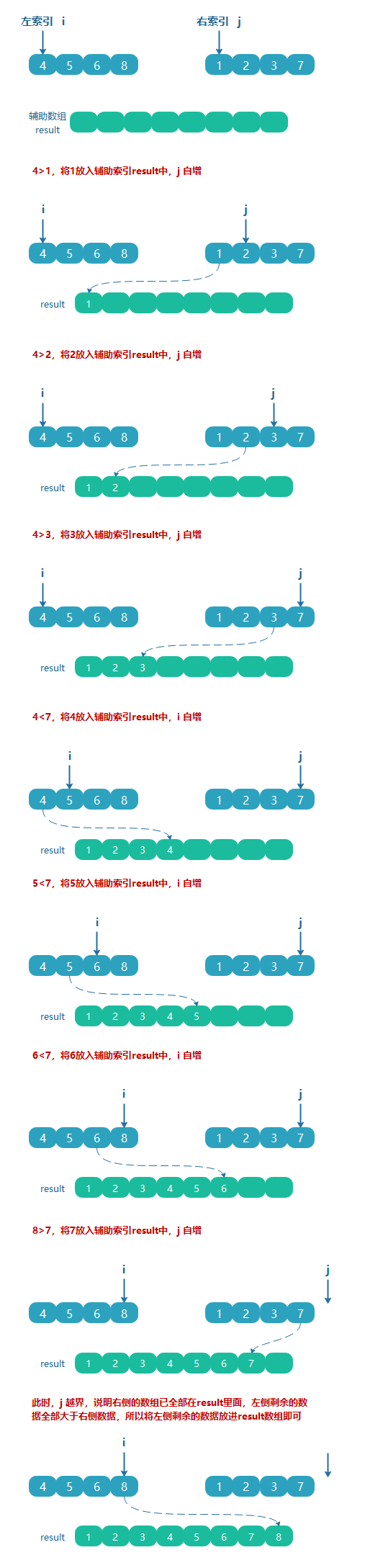
代码实现
public class MergeSort { public static final int[] ARRAY = {8, 5, 6, 4, 3, 1, 7, 2}; public static int[] sort(int[] array) { if (array.length < 2) return array; int mid = array.length / 2; //分成2组 int[] left = Arrays.copyOfRange(array, 0, mid); int[] right = Arrays.copyOfRange(array, mid, array.length); //递归拆分 return merge(sort(left), sort(right)); } //治---合并 public static int[] merge(int[] left, int[] right) { int[] result = new int[left.length + right.length]; //i代表左边数组的索引,j代表右边 for (int index = 0, i = 0, j = 0; index < result.length; index++) { if (i >= left.length) {//说明左侧的数据已经全部取完,取右边的数据 result[index] = right[j++]; } else if (j >= right.length) {//说明右侧的数据已经全部取完,取左边的数据 result[index] = left[i++]; } else if (left[i] > right[j]) {//左边大于右边,取右边的 int a = right[j++]; result[index] = a; } else {//右边大于左边,取左边的 result[index] = left[i++]; } } return result; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
时间复杂度
归并排序方法就是把一组n个数的序列,折半分为两个序列,然后再将这两个序列再分,一直分下去,直到分为n个长度为1的序列。然后两两按大小归并。如此反复,直到最后形成包含n个数的一个数组。
归并排序总时间 = 分解时间 + 子序列排好序时间 + 合并时间
- 1
无论每个序列有多少数都是折中分解,所以分解时间是个常数,可以忽略不计,则:
归并排序总时间 = 子序列排好序时间 + 合并时间
- 1
假设处理的数据规模大小为 n,运行时间设为:T(n),则T(n) = n,当 n = 1时,T(1) = 1
由于在合并时,两个子序列已经排好序,所以在合并的时候只需要 if 判断即可,所以n个数比较,合并的时间复杂度为 n。
- 将 n 个数的序列,分为两个 n/2 的序列,则:T(n) = 2T(n/2) + n
- 将 n/2 个数的序列,分为四个 n/4 的序列,则:T(n) = 4T(n/4) + 2n
- 将 n/4 个数的序列,分为八个 n/8 的序列,则:T(n) = 8T(n/8) + 3n
- …
- 将 n/2k 个数的序列,分为2k个 n/2k 的序列,则:T(n) = 2kT(n/2k) + kn
当 T(n/2k) = T(1)时, 即n/2k = 1(此时也是把n分解到只有1个数据的时候),转换为以2为底n的对数:k = log2n,把k带入到T(n)中,得:T(n) = n + nlog2n。
使用大O表示法,去掉常数项 n,省略底数 2,则归并排序的时间复杂度为:O(nlogn)
算法稳定性
从原理分析和代码可以看出,为在合并的时候,如果相等,选择前面的元素到辅助数组,所以归并排序是稳定的。
快速排序
快速排序是对冒泡排序的一种改进,也是采用分治法的一个典型的应用。JDK中Arrays的sort()方法,具体的排序细节就是使用快速排序实现的。
从数组中任意选取一个数据(比如数组的第一个数或最后一个数)作为关键数据,我们称为基准数(pivot,或中轴数),然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序,也称为分区(partition)操作。
问题
若给定一个无序数组 [8, 5, 6, 4, 3, 1, 7, 2],并指定一个数为基准,拆分数组使得左侧的数都小于等于它 ,右侧的数都大于它。
基准的选取最优的情况是基准值刚好取在无序区数值的中位数,这样能够最大效率地让两边排序,同时最大地减少递归划分的次数,但是一般很难做到最优。基准的选取一般有三种方式:
- 选取数组的第一个元素
- 选取数组的最后一个元素
- 以及选取第一个、最后一个以及中间的元素的中位数(如4 5 6 7, 第一个4, 最后一个7, 中间的为5, 这三个数的中位数为5, 所以选择5作为基准)。
思路
- 随机选择数组的一个元素,比如 6 为基准,拆分数组同时引入一个初始指针,也叫分区指示器,初始指针指向 -1
- 将数组中的元素和基准数遍历比较
- 若当前元素大于基准数,不做任何变化
- 若当前元素小于等于基准数时,分割指示器右移一位,同时
- 当前元素下标小于等于分区指示器时,当前元素保持不动
- 当前元素下标大于分区指示器时,当前元素和分区指示器所指元素交换
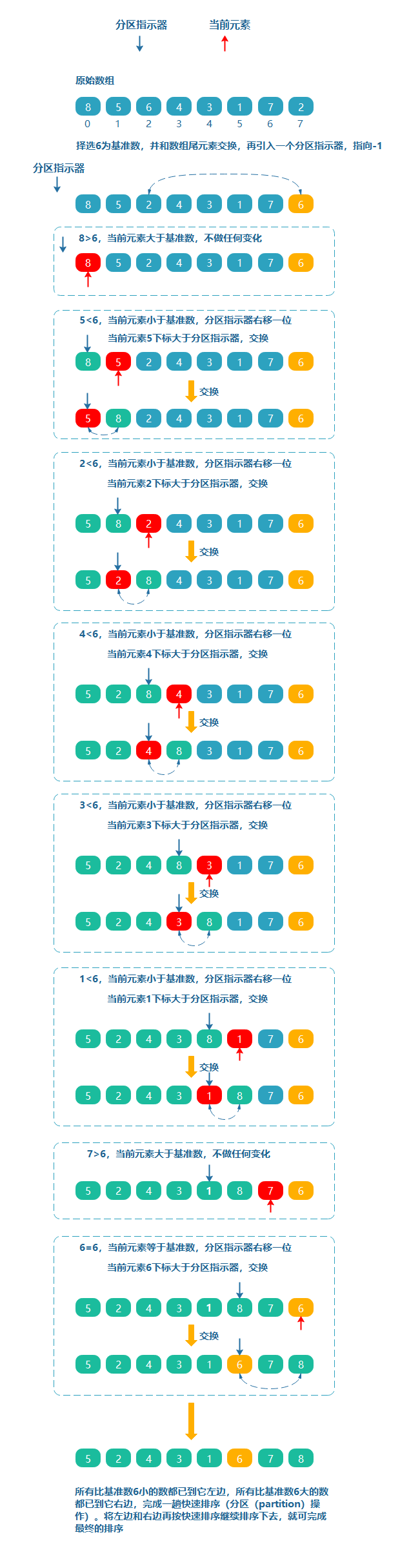
荷兰国旗问题
荷兰的国旗是由红白蓝三种颜色构成,如图:

若现在给一个随机的图形,如下:

把这些条纹按照颜色排好,红色的在上半部分,白色的在中间部分,蓝色的在下半部分,这类问题称作荷兰国旗问题。
对应leetcode:颜色分类
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
- 1
分析:
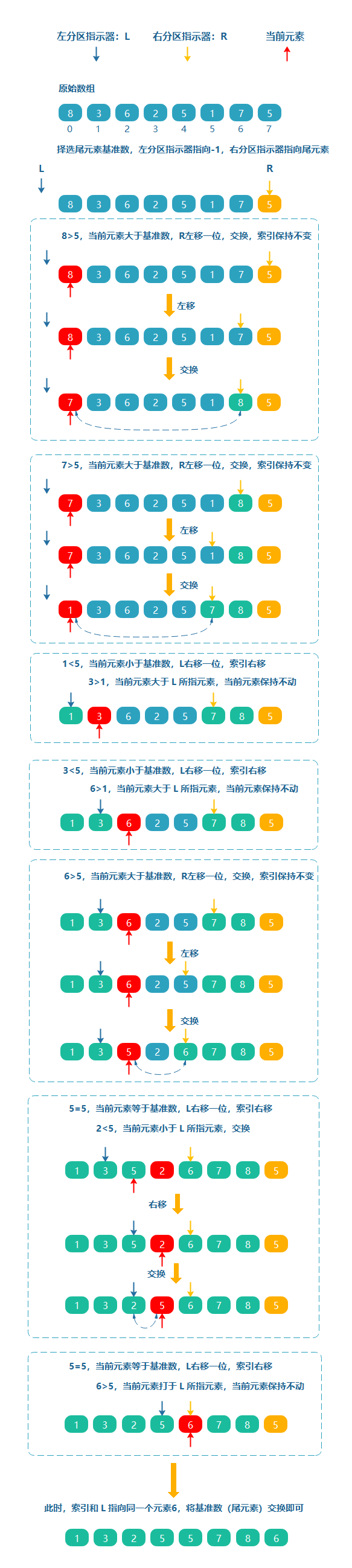
假如给定一个数组[8, 3, 6, 2, 5, 1, 7, 5],做如下操作:
-
随机选择数组的一个元素,比如 5 为基准,拆分数组同时引入一个左分区指示器,指向 -1,右分区指示器指向基准数(注:此时的基准数为尾元素)
-
若当前元素大于基准数,右分区指示器左移一位,当前元素和右分区指示器所指元素交换,
索引保持不变
-
若当前元素小于等于基准数时,左分区指示器右移一位,索引右移
- 当前元素大于等于左分区指示器所指元素,当前元素保持不动
- 当前元素小于左分区指示器所指元素,交换
简单来说就是,左分区指示器向右移动的过程中,如果遇到大于或等于基准数时,则停止移动,右分区指示器向左移动的过程中,如果遇到小于或等于主元的元素则停止移动。这种操作也叫双向快速排序。
代码实现
public class QuickSort { public static final int[] ARRAY = {8, 5, 6, 4, 3, 1, 7, 2}; public static final int[] ARRAY2 = {8, 3, 6, 2, 5, 1, 7, 5}; private static int[] sort(int[] array, int left, int right) { if (array.length < 1 || left > right) return null; //拆分 int partitionIndex = partition(array, left, right); //递归 if (partitionIndex > left) { sort(array, left, partitionIndex - 1); } if (partitionIndex < right) { sort(array, partitionIndex + 1, right); } return array; } /** * 分区快排操作 * * @param array 原数组 * @param left 左侧头索引 * @param right 右侧尾索引 * @return 分区指示器 最后指向基准数 */ public static int partition(int[] array, int left, int right) { //基准数下标---随机方式取值,也就是数组的长度随机1-8之间 int pivot = (int) (left + Math.random() * (right - left + 1)); //分区指示器索引 int partitionIndex = left - 1; //基准数和尾部元素交换 swap(array, pivot, right); //按照规定,如果当前元素大于基准数不做任何操作; //小于基准数,分区指示器右移,且当前元素的索引大于分区指示器,交换 for (int i = left; i <= right; i++) { if (array[i] <= array[right]) {//当前元素小于等于基准数 partitionIndex++; if (i > partitionIndex) {//当前元素的索引大于分区指示器 //交换 swap(array, i, partitionIndex); } } } return partitionIndex; } /** * 双向扫描排序 */ public static int partitionTwoWay(int[] array, int left, int right) { //基准数 int pivot = array[right]; //左分区指示器索引 int leftIndex = left - 1; //右分区指示器索引 int rightIndex = right; //索引 int index = left; while (index < rightIndex) { //若当前元素大于基准数,右分区指示器左移一位,当前元素和右分区指示器所指元素交换,索引保持不变 if (array[index] > pivot) { swap(array, index, --rightIndex); } else if (array[index] <= pivot) {//当前元素小于等于基准数时,左分割指示器右移一位,索引右移 leftIndex++; index++; //当前元素小于等于左分区指示器所指元素,交换 if (array[index] < array[leftIndex]) { swap(array, index, leftIndex); } } } //索引和 L 指向同一个元素 swap(array, right, rightIndex); return 1; } //交换 private static void swap(int[] array, int i, int j) { int temp = array[i]; array[i] = array[j]; array[j] = temp; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY, 0, ARRAY.length - 1)); System.out.println("====================双向排序=================="); print(ARRAY2); System.out.println("============================================"); print(sort(ARRAY2, 0, ARRAY2.length - 1)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
时间复杂度
在拆分数组的时候可能会出现一种极端的情况,每次拆分的时候,基准数左边的元素个数都为0,而右边都为n-1个。这个时候,就需要拆分n次了。而每次拆分整理的时间复杂度为O(n),所以最坏的时间复杂度为O(n2)。什么意思?举个简单例子:
在不知道初始序列已经有序的情况下进行排序,第1趟排序经过n-1次比较后,将第1个元素仍然定在原来的位置上,并得到一个长度为n-1的子序列;第2趟排序经过n-2次比较后,将第2个元素确定在它原来的位置上,又得到一个长度为n-2的子序列;以此类推,最终总的比较次数:
C(n) = (n-1) + (n-2) + … + 1 = n(n-1)/2
所以最坏的情况下,快速排序的时间复杂度为O(n^2)
而最好的情况就是每次拆分都能够从数组的中间拆分,这样拆分logn次就行了,此时的时间复杂度为O(nlogn)。
而平均时间复杂度,则是假设每次基准数随机,最后算出来的时间复杂度为O(nlogn)
算法稳定性
通过上面的分析可以知道,在随机取基准数的时候,数据是可能会发生变化的,所以快速排序有不是稳定的情况。
堆排序
这里的堆并不是JVM中堆栈的堆,而是一种特殊的二叉树,通常也叫作二叉堆。它具有以下特点:
- 它是完全二叉树
- 堆中某个结点的值总是不大于或不小于其父结点的值
知识补充
二叉树
树中节点的子节点不超过2的有序树

满二叉树
二叉树中除了叶子节点,每个节点的子节点都为2,则此二叉树为满二叉树。
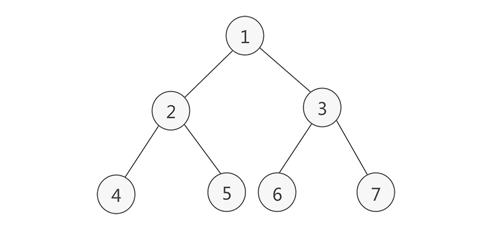
完全二叉树
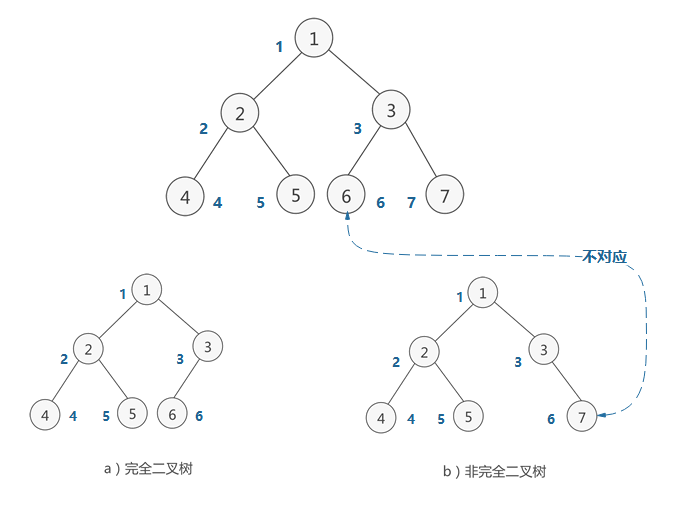
如果对满二叉树的结点进行编号,约定编号从根结点起,自上而下,自左而右。则深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树。
特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。需要注意的是,满二叉树肯定是完全二叉树,而完全二叉树不一定是满二叉树。
二叉堆
二叉堆是一种特殊的堆,可以被看做一棵完全二叉树的数组对象,而根据其性质又可以分为下面两种:
- 大根堆:每一个根节点都大于等于它的左右孩子节点,也叫最大堆
- 小根堆:每一个根节点都小于等于它的左右孩子节点,也叫最小堆
如果把一个数组通过大根堆的方式来表示(数组元素的值是可变的),如下:
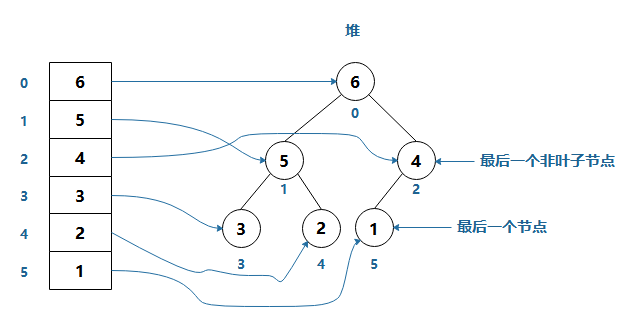
由此可以推出:
-
对于位置为 k 的节点,其子节点的位置分别为,左子节点 = 2k + 1,右子节点 = 2(k + 1)
如:对于 k = 1,其节点的对应数组为 5
左子节点的位置为 3,对应数组的值为 3
右子节点的位置为 4,对应数组的值为 2
-
最后一个非叶子节点的位置为 (n/2) - 1,n为数组长度
如:数组长度为6,则 (6/2) - 1 = 2,即位置 2 为最后一个非叶子节点
给定一个随机数组[35,63,48,9,86,24,53,11],将该数组视为一个完全二叉树:
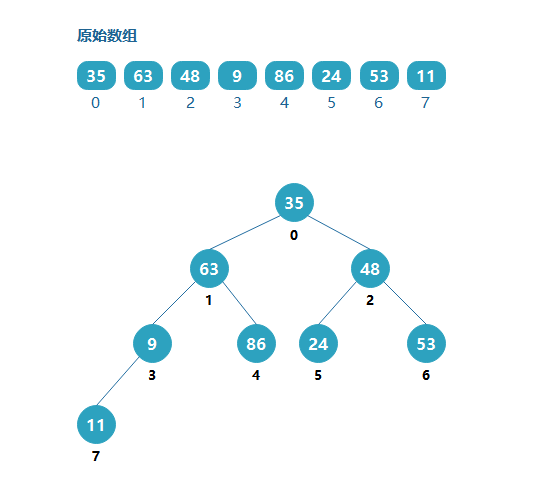
从上图很明显的可以看出,这个二叉树不符合大根堆的定义,但是可以通过调整,使它变为最大堆。如果从最后一个非叶子节点开始,从下到上,从右往左调整,则:

通过上面的调整,该二叉树为最大堆,这个时候开始排序,排序规则:
- 将堆顶元素和尾元素交换
- 交换后重新调整元素的位置,使之重新变成二叉堆

代码实现
public class HeapSort { public static final int[] ARRAY = {35, 63, 48, 9, 86, 24, 53, 11}; public static int[] sort(int[] array) { //数组的长度 int length = array.length; if (length < 2) return array; //首先构建一个最大堆 buildMaxHeap(array); //调整为最大堆之后,顶元素为最大元素并与微元素交换 while (length > 0) {//当lenth <= 0时,说明已经到堆顶 //交换 swap(array, 0, length - 1); length--;//交换之后相当于把树中的最大值弹出去了,所以要-- //交换之后从上往下调整使之成为最大堆 adjustHeap(array, 0, length); } return array; } //对元素组构建为一个对应数组的最大堆 private static void buildMaxHeap(int[] array) { //在之前的分析可知,最大堆的构建是从最后一个非叶子节点开始,从下往上,从右往左调整 //最后一个非叶子节点的位置为:array.length/2 - 1 for (int i = array.length / 2 - 1; i >= 0; i--) { //调整使之成为最大堆 adjustHeap(array, i, array.length); } } /** * 调整 * @param parent 最后一个非叶子节点 * @param length 数组的长度 */ private static void adjustHeap(int[] array, int parent, int length) { //定义最大值的索引 int maxIndex = parent; //parent为对应元素的位置(数组的索引) int left = 2 * parent + 1;//左子节点对应元素的位置 int right = 2 * (parent + 1);//右子节点对应元素的位置 //判断是否有子节点,再比较父节点和左右子节点的大小 //因为parent最后一个非叶子节点,所以如果有左右子节点则节点的位置都小于数组的长度 if (left < length && array[left] > array[maxIndex]) {//左子节点如果比父节点大 maxIndex = left; } if (right < length && array[right] > array[maxIndex]) {//右子节点如果比父节点大 maxIndex = right; } //maxIndex为父节点,若发生改变则说明不是最大节点,需要交换 if (maxIndex != parent) { swap(array, maxIndex, parent); //交换之后递归再次调整比较 adjustHeap(array, maxIndex, length); } } //交换 private static void swap(int[] array, int i, int j) { int temp = array[i]; array[i] = array[j]; array[j] = temp; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
时间复杂度
堆的时间复杂度是 O(nlogn)
参考:堆排序的时间复杂度分析
算法稳定性
堆的结构为,对于位置为 k 的节点,其子节点的位置分别为,左子节点 = 2k + 1,右子节点 = 2(k + 1),最大堆要求父节点大于等于其2个子节点,最小堆要求父节点小于等于其2个子节点。
在一个长为n的序列,堆排序的过程是从第n/2开始和其子节点共3个值选择最大(最大堆)或者最小(最大堆),这3个元素之间的选择当然不会破坏稳定性。但当为n/2-1,n/2-2,… 1 这些个父节点选择元素时,就会破坏稳定性。有可能第n/2个父节点交换把后面一个元素交换过去了,而第n/2-1个父节点把后面一个相同的元素没有交换,那么这2个相同的元素之间的稳定性就被破坏了。所以,堆排序不是稳定的排序算法。
参考:排序的稳定性
思考
对于快速排序来说,其平均复杂度为O(nlogn),堆排序也是O(nlogn),怎么选择?如下题:
leetcode:数组中的第K个最大元素
此题的意思是对于一个无序数组,经过排序后的第 k 个最大的元素。
我们知道快速排序是需要对整个数组进行排序,这样才能取出第 k 个最大的元素。
如果使用堆排序,且是最大堆的方式,则第k次循环即可找出第 k 个最大的元素,并不需要吧整个数组排序。
所以对于怎么选择的问题,要看具体的场景,或者是两者都可。
计数排序
一种非比较排序。计数排序对一定范围内的整数排序时候的速度非常快,一般快于其他排序算法。但计数排序局限性比较大,只限于对整数进行排序,而且待排序元素值分布较连续、跨度小的情况。
如果一个数组里所有元素都是整数,而且都在0-k以内。对于数组里每个元素来说,如果能知道数组里有多少项小于或等于该元素,就能准确地给出该元素在排序后的数组的位置。
如给定一个0~5范围内的数组[2,5,3,0,2,3,0,3],对于元素5为其中最大的元素,创建一个大小为(5-0+1 = 6)的计数数组,如果原数组中的值对应计数数组的下标,则下标对应计数数组的值加1。
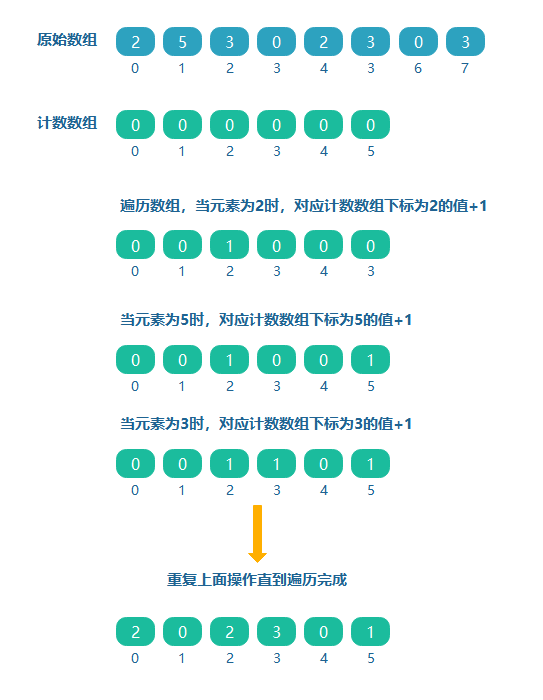
问题
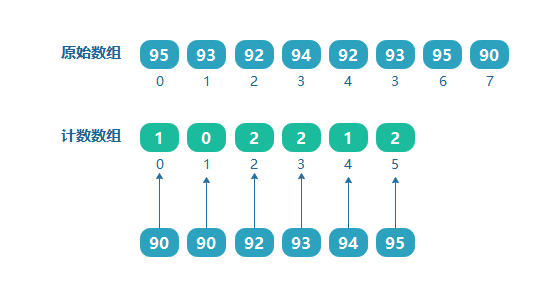
上面是通过数组的最大值来确定计数数组的长度的,但如果需要对学生的成绩进行排序,如学生成绩为:[95,93,92,94,92,93,95,90],如果按照上面的方法来处理,则需要一个大小为100的数组,但是可以看到其中的最小值为90,那也就是说前面 0~89 的位置都没有数据存放,造成了资源浪费。
如果我们知道了数组的最大值和最小值,则计数数组的大小为(最大值 - 最小值 + 1),如上面数组的最大值为99,最小值为90,则定义计数数组的大小为(95 - 90 + 1 = 6)。并且索引分别对应原数组9095的值。我们把090的范围用一个偏移量来表示,即最小值90就是这个偏移量。
代码实现
public class CountSort { public static final int[] ARRAY = {2, 5, 3, 0, 2, 3, 0, 3}; public static final int[] ARRAY2 = {95,93,92,94,92,93,95,90}; //优化前 private static int[] sort(int[] array) { if (array.length < 2) return array; //找出数组的最大值 int max = array[0]; for (int i : array) { if (i > max) { max = i; } } //初始化一个计数数组且值为0 int[] countArray = new int[max + 1]; for (int i = 0; i < countArray.length; i++) { countArray[i] = 0; } //填充计数数组 for (int temp : array) { countArray[temp]++; } int o_index = 0;//原数组下标 int n_index = 0;//计数数组下标 while (o_index < array.length) { //只要计数数组的下标不为0,就将计数数组的值从新写回原数组 if (countArray[n_index] != 0) { array[o_index] = n_index;//计数数组下标对应元素组的值 countArray[n_index]--;//计数数组的值要-1 o_index++; } else { n_index++;//上一个索引的值为0后开始下一个 } } return array; } //优化后 private static int[] sort2(int[] array) { if (array.length < 2) return array; //找出数组中的最大值和最小值 int min = array[0], max = array[0]; for (int i : array) { if (i > max) { max = i; } if (i < min) { min = i; } } //定义一个偏移量,即最小值前面0~min的范围,这里直接用一个负数来表示 int bias = 0 - min; //初始化一个计数数组且值为0 int[] countArray = new int[max - min + 1]; for (int i = 0; i < countArray.length; i++) { countArray[i] = 0; } for (int temp : array) { countArray[temp + bias]++; } //填充计数数组 int o_index = 0;//原数组下标 int n_index = 0;//计数数组下标 while (o_index < array.length) { if (countArray[n_index] != 0) { array[o_index] = n_index - bias; countArray[n_index]--; o_index++; } else { n_index++; } } return array; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); System.out.println("=================优化排序===================="); print(ARRAY2); System.out.println("============================================"); print(sort2(ARRAY2)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
时间复杂度
很明显,在排序过程中,我们至少遍历了三次原始数组,一次计数数组,所以它的复杂度为Ο(n+m)。因此,计数排序比任何排序都要块,这是一种牺牲空间换取时间的做法,因为排序过程中需要用一个计数数组来存元素组的出现次数。
算法稳定性
在新建的计数数组中记录原始数组中每个元素的数量,如果原始数组有相同的元素,则在输出时,无法保证元素原来的排序,是一种不稳定的排序算法。
桶排序
桶排序是计数排序的升级,计数排序可以看成每个桶只存储相同元素,而桶排序每个桶存储一定范围的元素,通过函数的某种映射关系,将待排序数组中的元素映射到各个对应的桶中,对每个桶中的元素进行排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序),最后将非空桶中的元素逐个放入原序列中。
桶排序需要尽量保证元素分散均匀,否则当所有数据集中在同一个桶中时,桶排序失效。

代码实现
-
找出数组中的最大值max和最小值min,可以确定出数组所在范围min~max
-
根据数据范围确定桶的数量
- 若桶的数量太少,则桶排序失效
- 若桶的数量太多,则有的桶可能,没有数据造成空间浪费
所以桶的数量由我们自己来确定,但尽量让元素平均分布到每一个桶里,这里提供一个方式
(最大值 - 最小值)/每个桶所能放置多少个不同数值+1 -
确定桶的区间,一般是按照
(最大值 - 最小值)/桶的数量来划分的,且左闭右开
public class BucketSort { public static final int[] ARRAY = {35, 23, 48, 9, 16, 24, 5, 11, 32, 17}; /** * @param bucketSize 作为每个桶所能放置多少个不同数值,即数值的类型 * 例如当BucketSize==5时,该桶可以存放{1,2,3,4,5}这几种数字, * 但是容量不限,即可以存放100个3 */ public static List<Integer> sort(List<Integer> array, int bucketSize) { if (array == null || array.size() < 2) return array; int max = array.get(0), min = array.get(0); // 找到最大值最小值 for (int i = 0; i < array.size(); i++) { if (array.get(i) > max) max = array.get(i); if (array.get(i) < min) min = array.get(i); } //获取桶的数量 int bucketCount = (max - min) / bucketSize + 1; //构建桶,初始化 List<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketCount); List<Integer> resultArr = new ArrayList<>(); for (int i = 0; i < bucketCount; i++) { bucketArr.add(new ArrayList<>()); } //将原数组的数据分配到桶中 for (int i = 0; i < array.size(); i++) { //区间范围 bucketArr.get((array.get(i) - min) / bucketSize).add(array.get(i)); } for (int i = 0; i < bucketCount; i++) { if (bucketSize == 1) { for (int j = 0; j < bucketArr.get(i).size(); j++) resultArr.add(bucketArr.get(i).get(j)); } else { if (bucketCount == 1) bucketSize--; //对桶中的数据再次用桶进行排序 List<Integer> temp = sort(bucketArr.get(i), bucketSize); for (int j = 0; j < temp.size(); j++) resultArr.add(temp.get(j)); } } return resultArr; } public static void print(List<Integer> array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(Arrays.stream(ARRAY).boxed().collect(Collectors.toList())); System.out.println("============================================"); print(sort(Arrays.stream(ARRAY).boxed().collect(Collectors.toList()), 2)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
时间复杂度
桶排序算法遍历了2次原始数组,运算量为2N,最后,遍历桶输出排序结果的运算量为N,初始化桶的运算量为M。
对桶进行排序,不同的排序算法算法复杂度不同,冒泡排序算法复杂度为O(N^2),堆排序、归并排序算法复杂度为O(NlogN),我们以排序算法复杂度为O(NlogN)进行计算,运算量为N/M * log(N/M) * M
最终的运算量为3N+M+N/M * log(N/M) * M,即3N+M+N(logN-logM),去掉系数,时间复杂度为O(N+M+N(logN-logM))
参考:桶排序算法详解
算法稳定性
桶排序算法在对每个桶进行排序时,若选择稳定的排序算法,则排序后,相同元素的位置不会发生改变,所以桶排序算法是一种稳定的排序算法。
基数排序
常见的数据元素一般是由若干位组成的,比如字符串由若干字符组成,整数由若干位0~9数字组成。
基数排序按照从右往左的顺序,依次将每一位都当做一次关键字,然后按照该关键字对数组排序,同时每一轮排序都基于上轮排序后的结果;当我们将所有的位排序后,整个数组就达到有序状态。基数排序不是基于比较的算法。
基数是什么意思?对于十进制整数,每一位都只可能是0~9中的某一个,总共10种可能。那10就是它的基,同理二进制数字的基为2;对于字符串,如果它使用的是8位的扩展ASCII字符集,那么它的基就是256。
基数排序有两种方法:
- MSD 从高位开始进行排序
- LSD 从低位开始进行排序
对于大小范围为0~9的数的组合(若是两位数,就是个位数和十位数的组合),于是可以准备十个桶,然后放到对应的桶里,然后再把桶里的数按照0号桶到9号桶的顺序取出来即可。
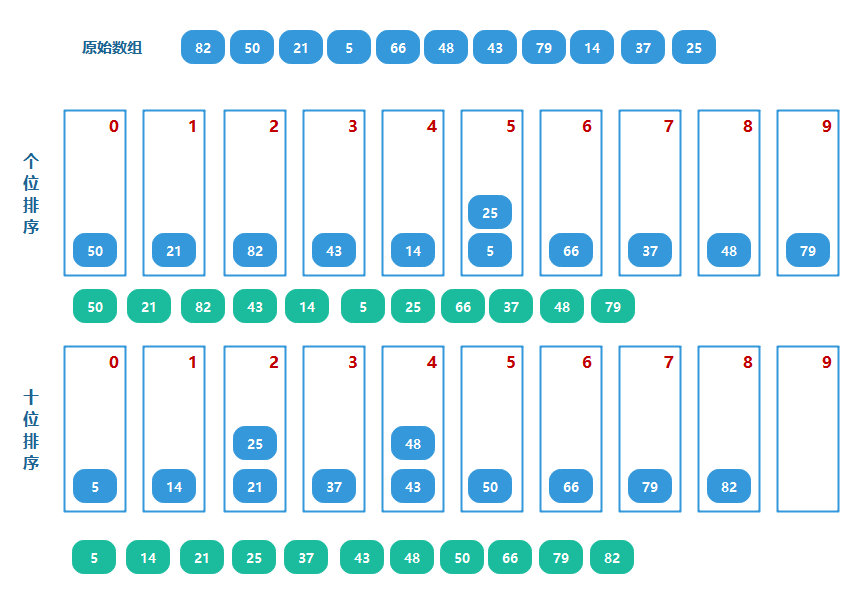
代码实现
public class RadixSort { public static final int[] ARRAY = {82, 50, 21, 5, 66, 48, 43, 79, 14, 37, 25}; public static int[] sort(int[] array) { if (array.length < 2) return array; //根据最大值算出位数 int max = array[0]; for (int temp : array) { if (temp > max) { max = temp; } } //算出位数digit int maxDigit = 0; while (max != 0) { max /= 10; maxDigit++; } //创建桶并初始化 ArrayList<ArrayList<Integer>> bucket = new ArrayList<>(); for (int i = 0; i < 10; i++) { bucket.add(new ArrayList<>()); } //按照从右往左的顺序,依次将每一位都当做一次关键字,然后按照该关键字对数组排序,每一轮排序都基于上轮排序后的结果 int mold = 10;//取模运算 int div = 1;//获取对应位数的值 for (int i = 0; i < maxDigit; i++, mold *= 10, div *= 10) { for (int j = 0; j < array.length; j++) { //获取个位/十位/百位...... int num = (array[j] % mold) / div; //把数据放入到对应的桶里 bucket.get(num).add(array[j]); } //把桶中的数据重新写回去,并把桶的元素清空,开始第二轮排序 int index = 0; for (int k = 0; k < bucket.size(); k++) { //桶中对应的数据 ArrayList<Integer> list = bucket.get(k); for (int m = 0; m < list.size(); m++) { array[index++] = list.get(m); } //清除桶 bucket.get(k).clear(); } } return array; } public static void print(int[] array) { for (int i : array) { System.out.print(i + " "); } System.out.println(""); } public static void main(String[] args) { print(ARRAY); System.out.println("============================================"); print(sort(ARRAY)); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
时间复杂度
计数排序算法的时间复杂度是O(N+M),基数排序算法执行了k次计数排序,所以基数排序算法的时间复杂度为O(K(N+M))。
算法稳定性
从上面的分析可以看出,相同元素会按照顺序放进固定的桶内,取出的时候也是按照顺序取出来的,所以基数排序算法是一种稳定的排序算法。
基数排序 vs 桶排序 vs 计数排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异
- 基数排序:根据每一位的关键字来分配桶
- 桶排序:存储一定范围的值
- 计数排序:每个桶只存储一个类型值,但是数量不限