
- 1微信小程序介绍
- 2【机器学习】机器学习:人工智能中实现自动化决策与精细优化的核心驱动力
- 3车载测试:CANoe中CDD数据库文件制作流程_怎么编辑cdd文件
- 4Facebook广告投放数据难以整理?你只需要这个「FB广告报表」插件!
- 5可解释AI如何帮助图片分类模型调试调优-可解释AI系列博文(二)_图像分类的调试结论
- 6基于树莓派4B设计的智能家居系统(华为云IOT)_基于树莓派的智能家居控制系统
- 7Pytorch学习-调整torchvision.models中模型输出类别数
- 8小程序业务域名配置如何将文件放置在域名根目录说明
- 9正确解决org.springframework.web.HttpRequestMethodNotSupportedException异常的有效解决方法
- 10记录element-ui select获取item对象以及解决回显问题_el-select选择对象回显
【大模型系列】大模型的上下文长度解释与拓展_大模型的文本向量长度
赞
踩
1 什么是大模型的上下文长度?
大模型的上下文长度(Context Length)是指在自然语言处理(NLP)的大型语言模型(Large Language Models,LLM)中,模型在处理输入信息时能够考虑的最大文本量(一次处理的最大tokens数量)。
超长上下文的优势:
- 可以处理更复杂的查询和更长的文档
- 更强的理解能力
超长上下文的挑战:
- 推理时间变长
- 推理显存空间变大
大模型在持续推理的过程中,需要缓存一个叫做 KV Cache 的数据快,KV Cache 的大小也与序列长度成正比。以 Llama 2 13B 大模型为例,一个 4K 长的序列大约需要 3G 的显存去缓存 KV Cache,16K 的序列则需要 12G,128K 的序列则需要 100G 显存。

Source: 如何扩展大模型的上下文长度
目前国内外大模型上下文长度支持情况如下:

Source: 大模型长上下文运行的关键问题
国内最近(2024)很火的Kimi Chat支持的上下文长度以及拓展到40万tokens。
2 拓展大模型上下文长度的方式
论文The What, Why, and How of Context Length Extension Techniques in Large Language Models – A Detailed Survey 对现有大模型上下文长度拓展方法做了详细的总结:
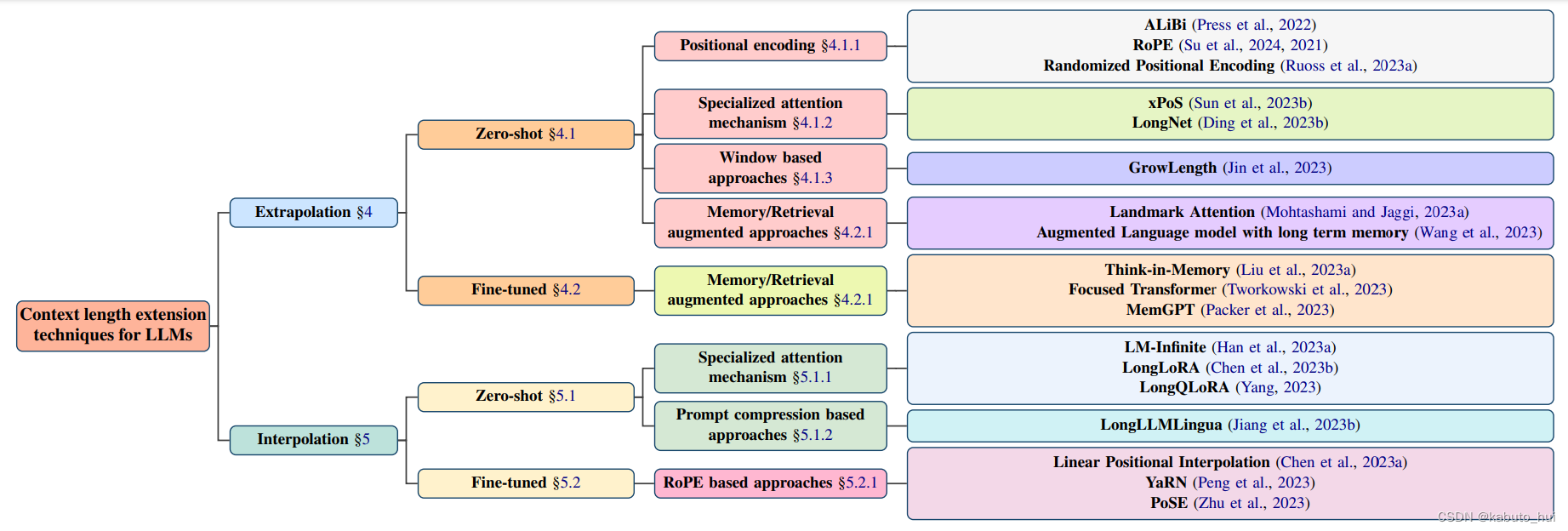
主要将其分为了Interpolation(插值)和Extrapolation(外推)技术:
- Interpolation: 融合不同来源或者不同上下文的信息,以提高预测的准确性;
- Extrapolation: 将模型的理解范围扩大到其训练的上下文长度之外。
其中:
- zero-shot: 表示先对模型进行改造,再重新训练,使模型自身具备长文本分析的能力;
- fine-tune: 表示对已经训练好的不支持长文本的模型进行改造,再进行微调;
大致可以简单分为以下几种主要的方式:

参考资料
[1] 如何扩展大模型的上下文长度
[2] 支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3
[3] 大模型长上下文运行的关键问题
[4] 卷完参数后,大模型公司又盯上了“长文本”?
[5] The What, Why, and How of Context Length Extension Techniques in Large Language Models – A Detailed Survey

