
- 1Kotlin->Kotlin集合操作_kotlin 函数 removefirstornull
- 2Kafka学习之:mac 上安装 kafka_mac 安装kafka
- 3【Shiro】Apache Shiro 默认密钥致命令执行漏洞(CVE-2016-4437)的解决方案
- 4IT职场生存法则
- 5C语言创建二叉树(前序、中序、后续遍历)_编写c语言程序,对于给定的一棵二叉树,按先序次序编写函数 createbitree( bitr
- 6Java性能分析中常用命令和工具_java程序常用的性能分析命令
- 7大学生求职面试技巧_求职程序与面试技巧培训笔记
- 8HarmonyOS鸿蒙开发指南:基于ArkTS开发 窗口管理_let promise = windowclass.setfullscreen(isfullscre
- 9QT软件开发:基于QTAV开发跨平台音视频播放器_播放器编写软件
- 10C语言输出100到999之间构成三位数的乘积等于三位数字的和的数字_编写程序输出100~999之间所有对称三位数
RabbitMQ学习笔记(五)——RabbitMQ集群搭建&入门_mq的搭建和底层配置
赞
踩
RabbitMQ项目使用集群的好处
1. 扩展规模
◆ 般的基础架构中,单机扩容(Scale-Up)很难实现
◆ 需要扩容时尽量使用扩展数量实现(Scale-Out)
◆ RabbitMQ集群可以方便地通过Scale-Out扩展规模
2. 数据冗余
◆ 对于单节点RabbitMQ,如果节点宕机,内存数据丢失
◆ 对于单节点RabbitMQ,如果节点损坏,磁盘数据丢失
◆ RabbitMQ集群可以通过镜像队列,将数据冗余至多个节点.
3. 高可用
◆ 如果单节点RabbitMQ宕机,服务不可用
◆ RabbitMQ集群可以通过负载均衡,将请求转移至可用节点
RabbitMQ集群搭建
RabbitMQ集群原理
◆ 多个RabbitMQ单节点,经过配置组成RabbitMQ集群
◆ 集群节点之间共享元数据,不共享队列数据(默认)
◆ RabbitMQ节点数据互相转发,客户端通过单一节点可以访问所有数据.

RabbitMQ集群搭建步骤
◆ 设置主机名或host,使得节点之间可以通过名称访问
◆ 安装RabbitMQ单节点
◆ 复制Erlang cookie
◆ 启动RabbitMQ并组成集群
单节点安装Rabbitmq
- 设置主机名称
hostnamectl set-hostname master.localdomain - 在hosts文件中,前两行里加入主机名称
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 master
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 master
- 1
- 2
- 安装epel
sudo yum install epel-release -y - 安装erlang
sudo yum install erlang -y - 安装socat
yum install socat -y - 安装wget
yum install wget -y - 下载rabbitmq安装包
mkdir -p /apps/rabbitMQ/
cd /apps/rabbitMQ/
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.8/rabbitmq-server-3.8.8-1.el8.noarch.rpm
- 1
- 2
- 3
-
导入rabbitmq密钥
rpm -import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc -
安装rabbitmq
rpm -ivh --nodeps rabbitmq-server-3.8.8-1.el8.noarch.rpm
rpm -ivh rabbitmq-server-3.8.8-1.el8.noarch.rpm -
管理rabbitmq服务
systemctl start rabbitmq-server
systemctl stop rabbitmq-server
systemctl status rabbitmq-server -
启用管控台插件
rabbitmq-plugins enable rabbitmq_management -
关闭系统防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service -
添加测试账户
rabbitmqctl add_user test test
rabbitmqctl set_user_tags test administrator
rabbitmqctl set_permissions -p / test ".*" ".*" ".*"
- 1
- 2
- 3
配置四台主机通过主机名访问:
vim /etc/hosts
192.168.166.134 master
192.168.166.135 salve1
192.168.166.136 salve2
192.168.166.137 salve3
- 1
- 2
- 3
- 4
- 5
- 6
复制Erlang cookie
-
需要停掉服务器的rabbitMQ的服务(如果没有停掉的话,Erlang的cookie是再被占用的)
systemctl stop rabbitmq-server -
修改.erlang.cookie权限
cat /var/lib/rabbitmq/.erlang.cookie
chmod 777 /var/lib/rabbitmq/.erlang.cookie -
将主节点的.erlang.cookie文件传输至集群所有节点
scp /var/lib/rabbitmq/.erlang.cookie root@salve1:/var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie root@salve2:/var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie root@salve3:/var/lib/rabbitmq/.erlang.cookie -
复原.erlang.cookie权限
chmod 400 /var/lib/rabbitmq/.erlang.cookie -
加入集群
# 所有节点启动rabbitmq
systemctl start rabbitmq-server
# 在非主节点上执行以下命令
rabbitmqctl stop_app
rabbitmqctl join_cluster --ram rabbit@master
rabbitmqctl start_app
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 打开master管控台
http://192.168.166.134:15672
可以看到所有节点的状态
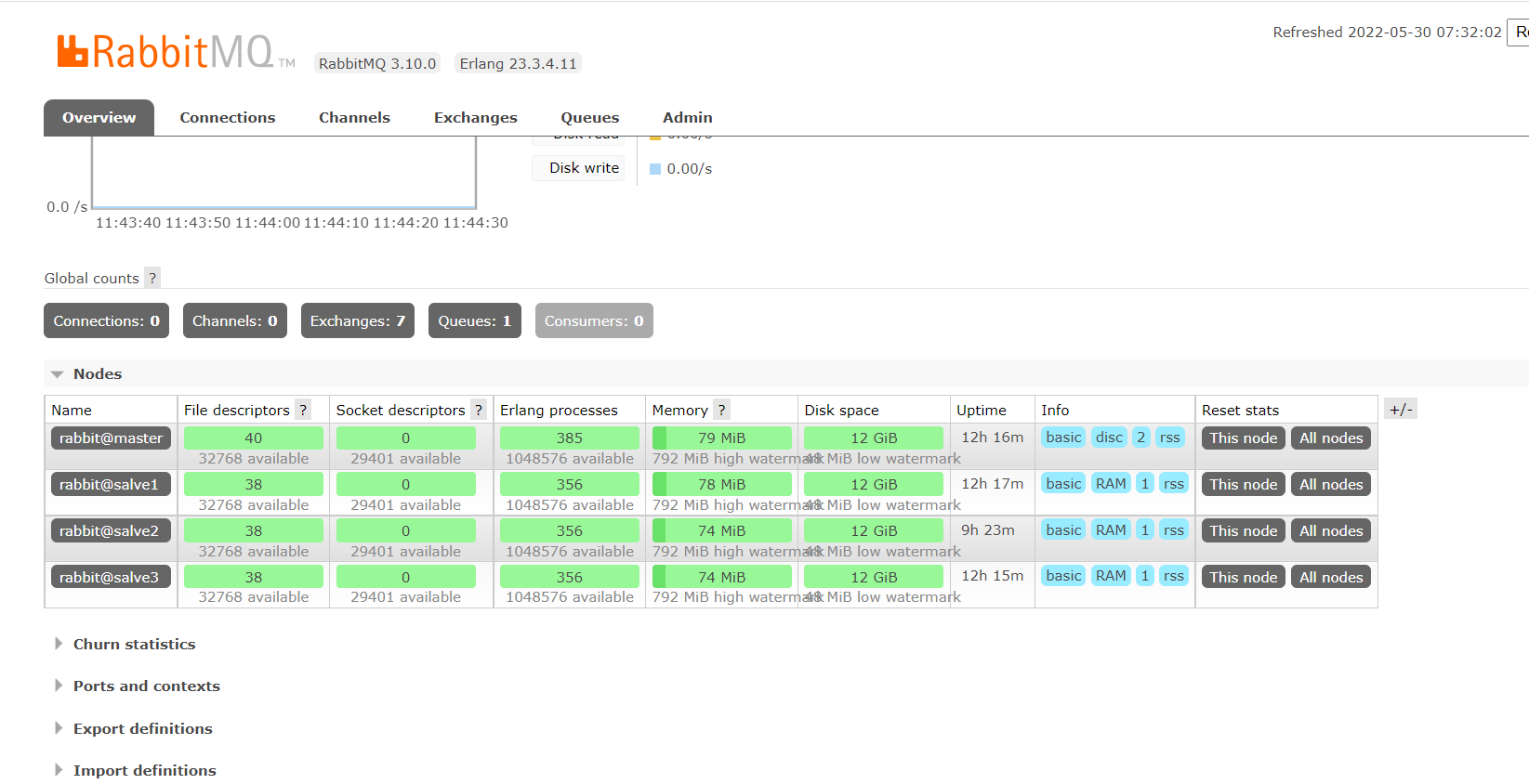
以上RabbitMQ集群解决了 高可用的 问题
集群镜像队列原理
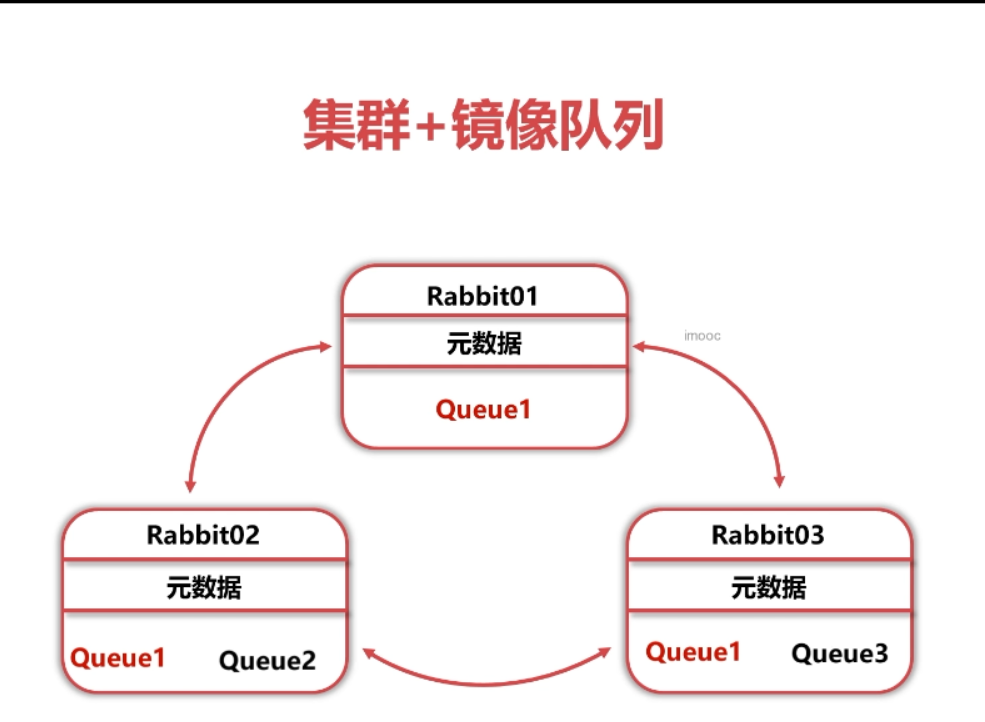
集群镜像队列设置方法
◆ 搭建集群
◆ 使用set_ policy 命令设置镜像队列策略
rabbitmqctl set_ policy [-p Vhost] Name Pattern Definition [Priority]
rabbitmqctl set_ policy Vhost 策咯名称 正则表达式 策略定义 优先级
Definition:策略定义
◆ ha-mode:指明镜像队列的模式
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
◆ ha-params: ha-mode模式需要用到的参数
◆ ha-svnc-mode:进行队列中消息的同步方式,有效值为automatic和manual
设置镜像队列策略案例:
◆ 匹配所有队列,并将镜像配置到集群中的所有节点
rabbitmqctl set_policy ha-all “^” ‘{“ha-mode”:“all”}’
◆ 名称以"two"开始的队列镜像到群集中的任意两个节点
rabbitmqctl set_policy ha-two “^two.” ‘{“ha-mode” :" exactly" ,“ha-params”:2,“ha-sync-mode”:" automatic}’
◆ 以" node"开头的队列镜像到集群中的特定节点
rabbitmqctl set_policy ha-nodes “^ nodes.” ‘{“ha-mode”:" nodes" ,“ha-params” :[“rabbit@nodeA”, “rabbit@nodeB”]}’
将镜像配置到集群中的所有节点
我们选择使用匹配所有队列
在主节点中:
rabbitmqctl set_policy ha-all “^” ‘{“ha-mode”:“all”}’
设置完后,会将队列数据保存在多个节点结果如下



以上RabbitMQ集群+镜像队列解决了 数据冗余的 问题
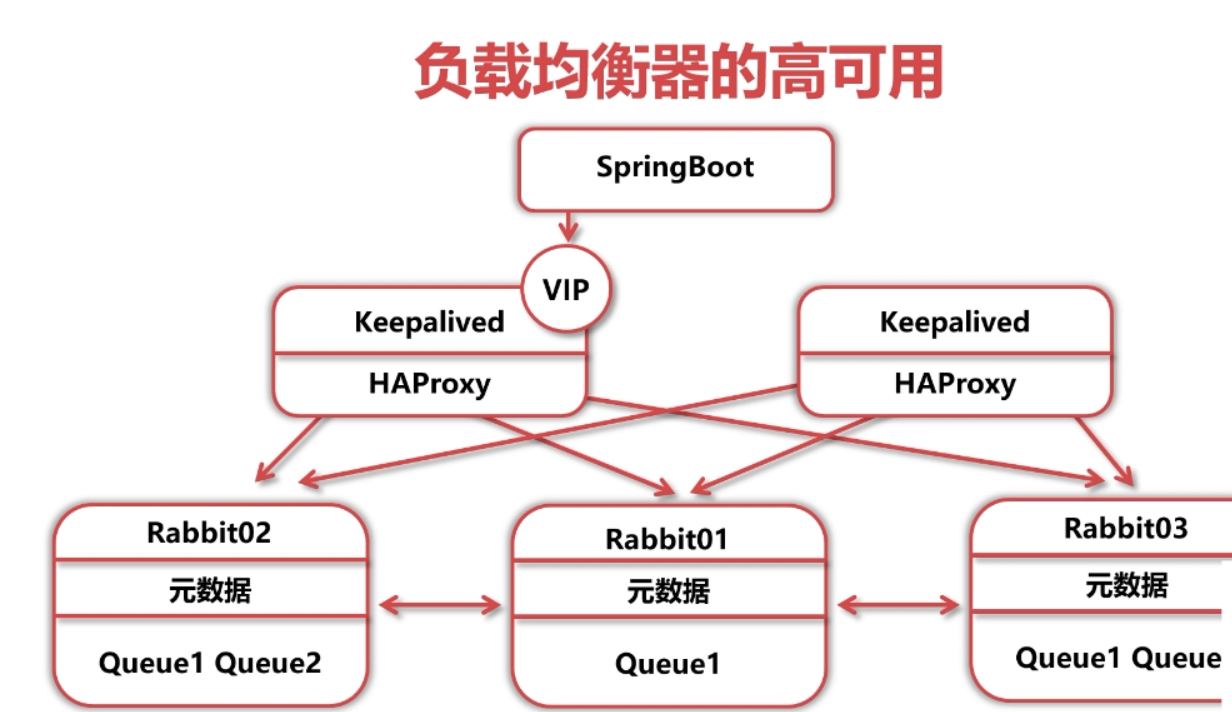
HAproxy+ Keepalived高可用集群搭建
HAproxy+ Keepalived直接在master和salve1结点上搭建
实现高可用的方式
◆ 客户端负载均衡
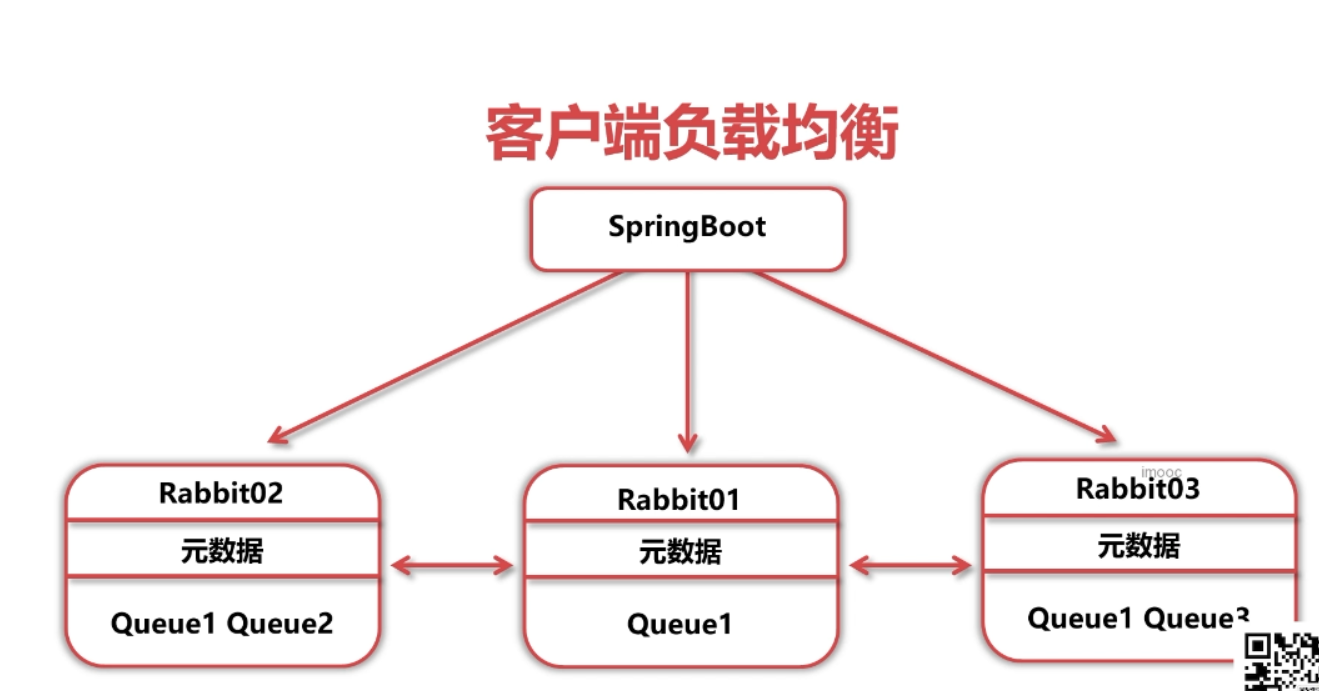
客户端负载均衡设置方法
直接在SpringBoot配置文件中设置多个地址
spring.rabbitmq.addresses= 127.0.0.1, 127.0.0.2, 127.0.0.3
◆ 服务端负载均衡
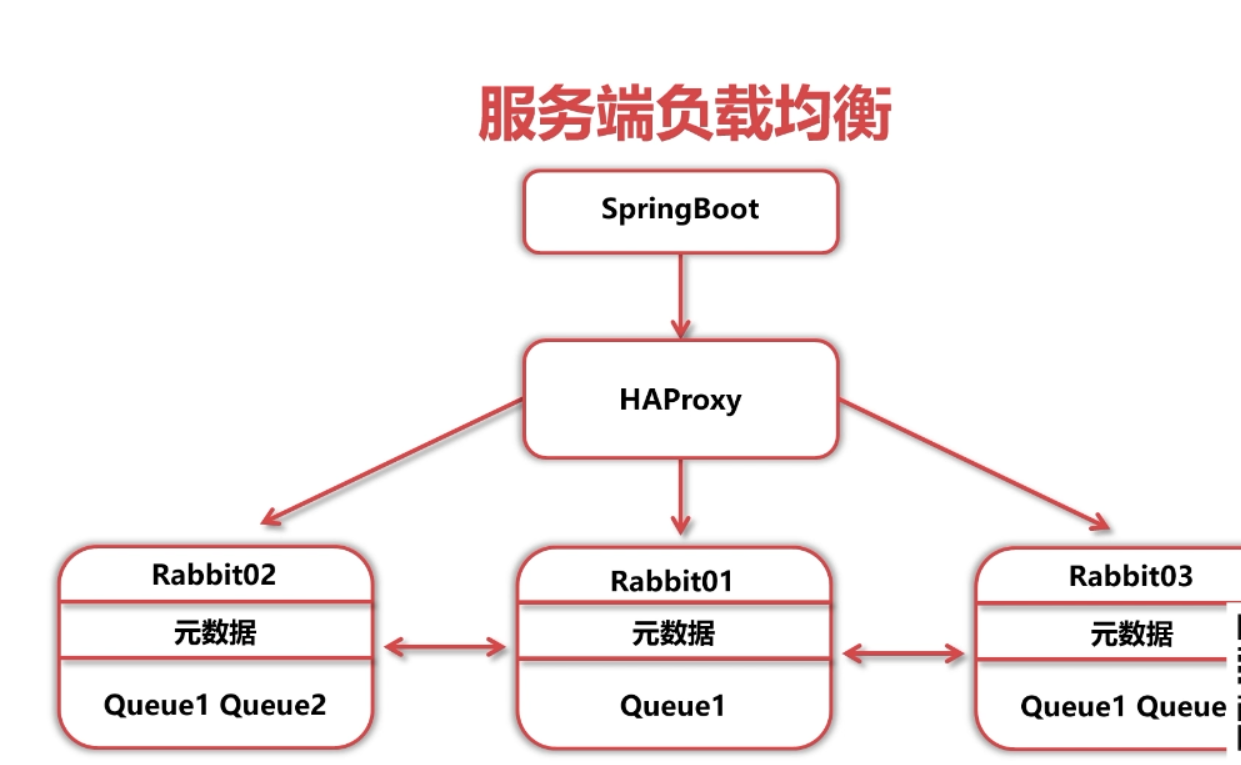
HAProxy简介
◆ HAProxy是一款提供高可用性、负载均衡以及基于TCP和HTTP应用的代理软件
◆ HAProxy适用于那些负载较大的web站点
◆ HAProxy可以支持数以万计的并发连接.
HAProxy配置方法
可以新建一台虚拟机进行搭建,我就直接在master节点上配置HAProxy
◆ 安装HaProxy
yum install haproxy -y
◆ 编辑hosts,使得haproxy能够通过主机名访问集群节点
vi /etc/hosts
192.168.166.134 master
192.168.166.135 salve1
192.168.166.136 salve2
192.168.166.137 salve3
◆ 编辑haproxy配置文件
vi /etc/haproxy/haproxy.cfg
global
# 日志输出配置、所有日志都记录在本机,通过 local0 进行输出
log 127.0.0.1 local0 info
# 最大连接数
maxconn 4096
# 守护模式
daemon
# 默认配置
defaults
# 应用全局的日志配置
log global
# 使用4层代理模式,7层代理模式则为"http"
mode tcp
# 日志类别
option tcplog
# 不记录健康检查的日志信息
option dontlognull
# 3次失败则认为服务不可用
retries 3
# 每个进程可用的最大连接数
maxconn 2000
# 连接超时
timeout connect 5s
# 客户端超时
timeout client 120s
# 服务端超时
timeout server 120s
# 绑定配置
listen rabbitmq_cluster
# 绑定端口,需要不被占用的端口
bind :5671
# 配置TCP模式
mode tcp
# 采用加权轮询的机制进行负载均衡
balance roundrobin
# RabbitMQ 集群节点配置
server master master:5672 check inter 5000 rise 2 fall 3 weight 1
server salve1 salve1:5672 check inter 5000 rise 2 fall 3 weight 1
server salve2 salve2:5672 check inter 5000 rise 2 fall 3 weight 1
server salve3 salve3:5672 check inter 5000 rise 2 fall 3 weight 1
# 配置监控页面
listen monitor
bind *:8100
mode http
option httplog
stats enable
stats uri /rabbitmq
stats refresh 5s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
◆ 设置seLinux(需要开放Linux的一些限制)
sudo setsebool -P haproxy_connect_any=1
◆ 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
◆ 启动haproxy
systemctl start haproxy
◆ 进入web监控界面
ip:8100/rabbitmq
http://192.168.166.134:8100/rabbitmq
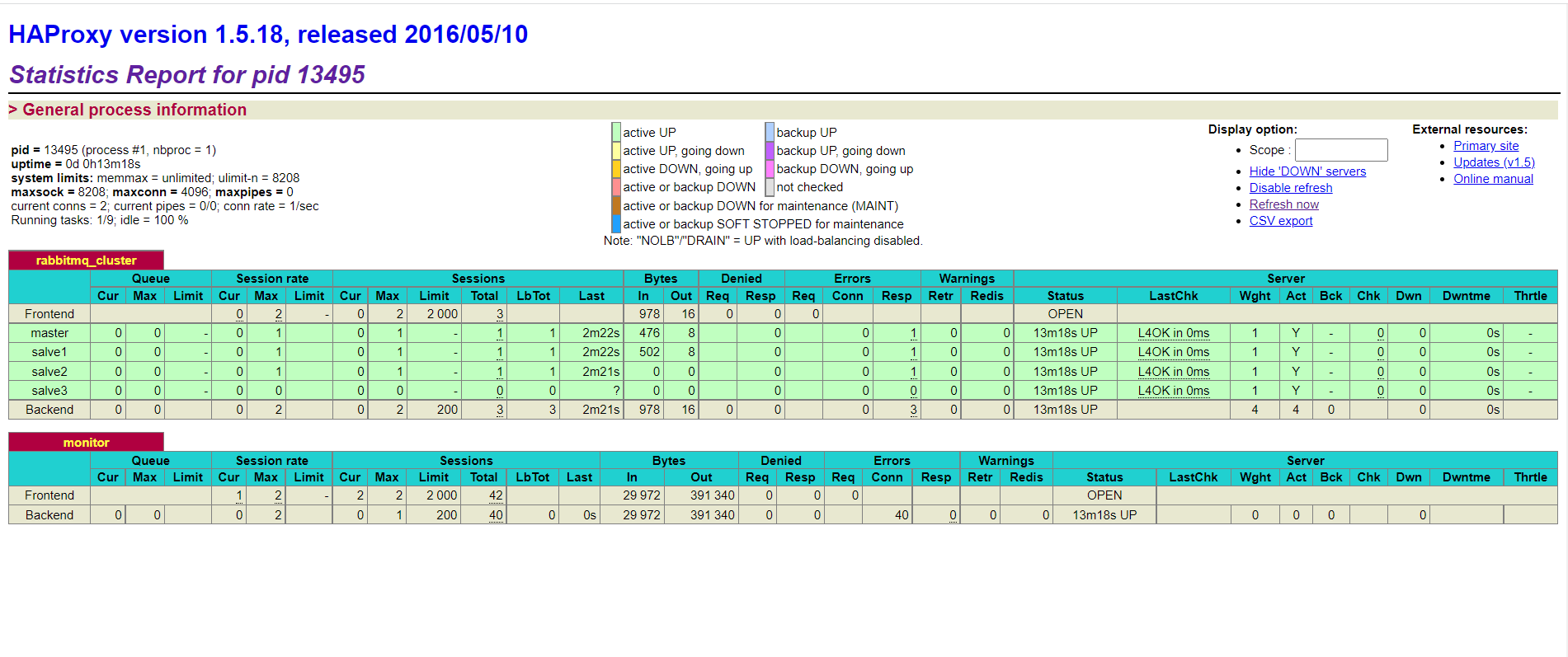
问题:HaProxy挂了怎么办?
◆ 再用一层负载均衡,不能解决问题,因为最后一层机器永远有风险
◆ 使用Virtual IP (VIP, 虚拟IP) 解决问题
Keepalived简介
◆ 高性能的服务器高可用或热备解决方案
◆ 主要来防止服务器单点故障的发生问题
◆ 以VRRP协议为实现基础,用VRRP协议来实现高可用性
keepalived配置(两个节点都需要)
-
安装keepalived
yum install keepalived -y -
编辑keepalived配置文件
vi /etc/keepalived/keepalived.conf
主机配置文件:(主节点)
! Configuration File for keepalived
global_defs {
router_id master
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh" ##执行脚本位置
interval 2 ##检测时间间隔
weight -20 ##如果条件成立则权重减20
}
vrrp_instance VI_1 {
# 配置需要绑定的VIP和本机的IP
state MASTER
interface ens33
virtual_router_id 28
# 本机IP
mcast_src_ip 192.168.166.134
priority 100
advert_int 1
# 通信之间设置的用户名和密码
authentication {
auth_type PASS
auth_pass 123456
}
# 虚拟IP
virtual_ipaddress {
192.168.166.238
}
# 健康检查
track_script {
chk_haproxy
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
热备机配置文件:(从节点)
global_defs {
router_id salve1
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh" ##执行脚本位置
interval 2 ##检测时间间隔
weight -20 ##如果条件成立则权重减20
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 28
mcast_src_ip 192.168.166.135
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.166.238
}
track_script {
chk_haproxy
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 健康检测脚本
vi /etc/keepalived/haproxy_check.sh
#!/bin/bash
COUNT=`ps -C haproxy --no-header |wc -l`
if [ $COUNT -eq 0 ];then
systemctl start haproxy
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
systemctl stop keepalived
fi
fi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
修改健康检测脚本执行权限
chmod +x /etc/keepalived/haproxy_check.sh -
启动keepalived
systemctl start keepalived
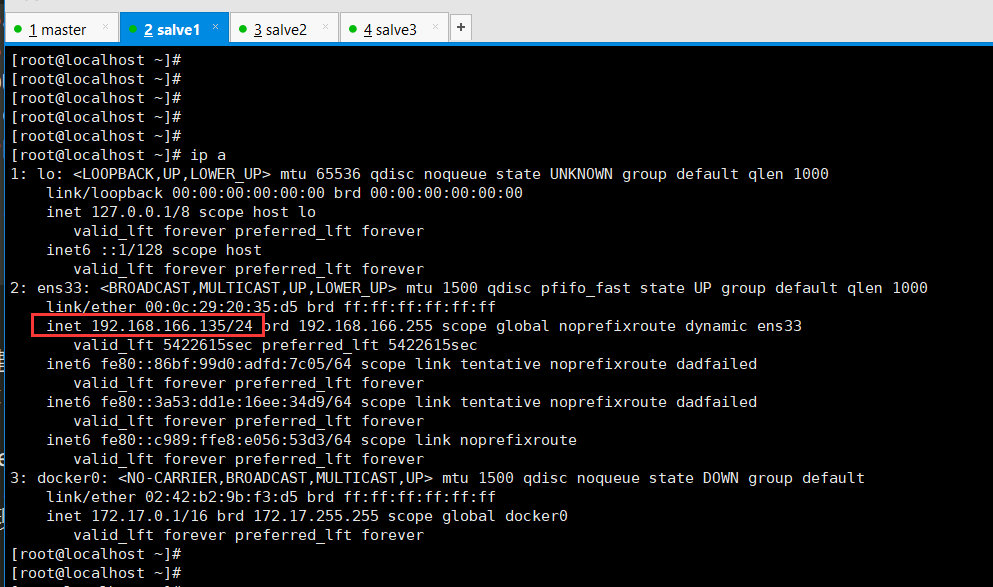
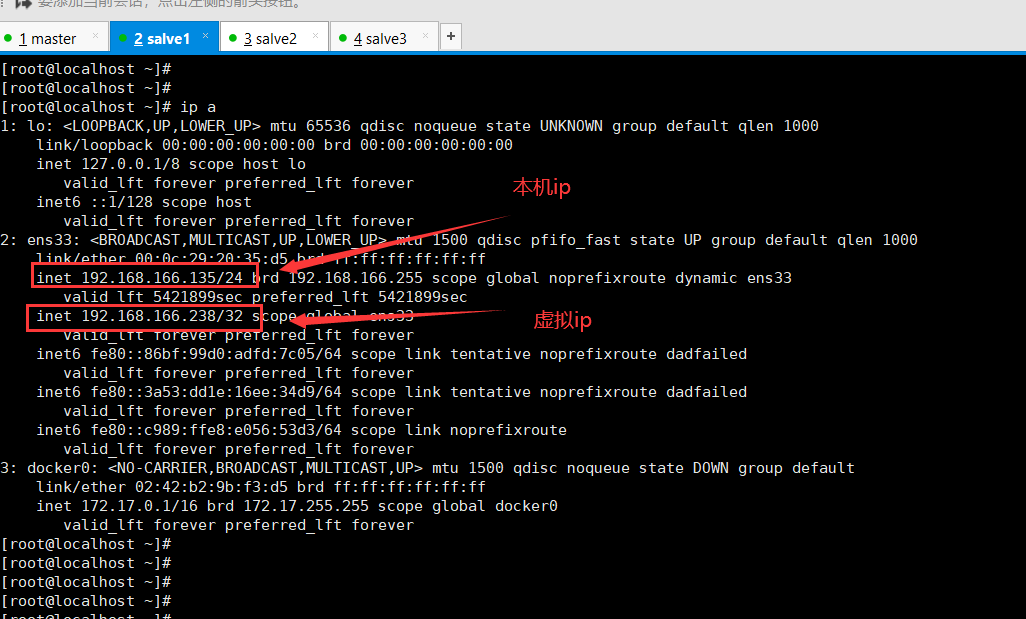
启动后发现主节点ip中多了一个虚拟ip,而从节点没有
主节点ip:
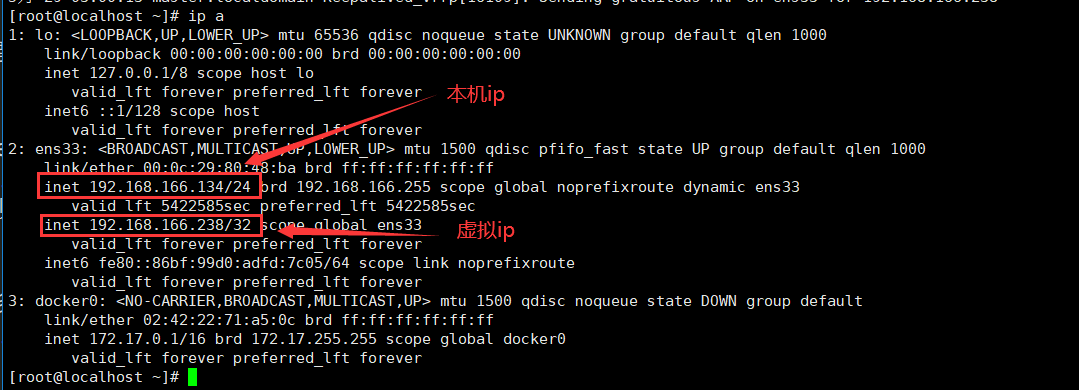
从节点ip:
- 做故障转移实验时,关闭keepalived即可
systemctl stop keepalived
关闭主节后发现从节点ip中多了一个虚拟ip,而主节点虚拟ip消失了
主节点ip:

从节点ip:
总结
◆ RabbitMQ集群 + 镜像队列 + HAproxy + Keepalived可以同时解决RabbitMQ的可扩展、数据冗余、高可用.
◆ 在使用客户端负载均衡时,可以省去HAproxy+ Keepalived
RabbitMQ集群间通信
问题:如果两个集群间处于异地,需要通讯会有以下问题
◆ 由于异地网络延时,异地RabbitMQ和业务应用之间很难建立网络连接
◆ 由于异地网络延时,异地RabbitMQ之间很难建立集群
◆ 此时如果异地RabbitMQ之间需要共享消息,需要使用集群间通信机制
RabbitMQ集群间通信方法
Federation(联邦)
Federation简介:
◆ 通过AMQP协议,使用一个内部交换机,让原本发送到一个集群的消息转发至另一个集群
◆ 消息可以从交换机转发至交换机,也可以由队列转发至队列
◆ 消息可以单向转发,也可以双向转发
Federation设置方法
◆ 启用Federation插件
rabbitmq-plugins enable rabbitmq_federation_management
◆ 使用管控台具体配置Federation
具体使用的时候再查文档
◆Shovel (铲子)
Federation简介:
◆ Shovel可以持续地从一 个broker拉取消息转发至另一个broker
◆ Shovel的使用较为灵活,可以配置从队列至交换机从队列至队列,从交换机至交换机
Shovel设置方法
◆ 启用插件
rabbitmq-plugins enable rabbitmq_ shovel_ management
◆ 使用管控台具体配置Shovel
具体使用的时候再查文档
总结
◆ Federation和Shovel都是在broker之间转发/共享消息的方法
◆ Federation只能在交换机之间或者队列之间转发消息
◆ Shovel更加灵活,可以在交换机和队列之间转发消息
经验和小结
实际开发经验
◆ 体系架构升级的根本原因是需求
◆ 不要盲目升级更高级的架构,更高级的架构意味着对运维有更高的要求
◆ 多思考架构拓扑,形成更好的架构思维
小结
◆ 为了追求规模的扩展性,搭建RabbitMQ集群
◆ 为了追求数据的冗余,使用RabbitMQ集群镜像队列
◆ 为了RabbitMQ服务高可用,使用了服务端的负载均衡技术
◆ 为了跨地域传送消息,学习了跨broker通信技术

