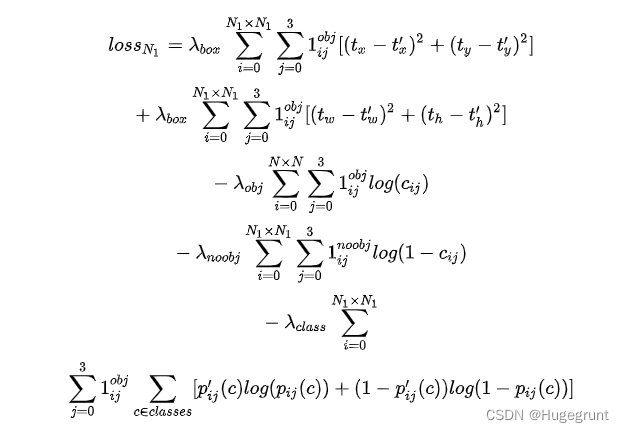- 1【第34天】SQL进阶-SQL高级技巧-Window Funtion(SQL 小虚竹)_sql window function
- 2【并发编程四】windows进程通信和Linux进程通信_windows linux消息队列,用于进程间消息同步
- 3C语言常用MySQL API函数_mysql 的 c api
- 4Vue项目开发目录结构和引用调用关系_vue app.vue拆分并引用
- 5大模型推理性能优化之KV Cache解读
- 6PyTorch深度学习实践——Logistic回归_pytorch之优化头歌
- 7如何借助 LLM 设计和实现任务型对话 Agent
- 8idea 项目 修改项目文件名 教程
- 92021浙江高考成绩查询平台,浙江省教育考试院:2021年浙江高考查分入口、查分系统...
- 10Java数组(如果想知道Java中有关数组的知识点,那么只看这一篇就足够了!)
YOLO 算法系列总结对比 —— v1 - v3_yolo系列算法比较
赞
踩
目录
2. 关于如何通过设计网络来实现YOLOv1预测bbox的思想
前言
YOLO系列是一种快速的目标检测算法,其目的是在满足一定的精度要求下尽量做到轻量快捷。这使得它非常适合部署在对检测速度要求比较高的场合。比如说视频中的目标实时检测,自动驾驶目标检测等。本文介绍了一下YOLO各个版本的特点对比。
YOLOv1
1. 技术路线
YOLOv1 提出了一种只用一个CNN网络就能实现端到端目标检测的方法。其技术路线的思路是首先将原图resize成448*448大小的图像,然后将这个图像切分成7*7个等份的cell。算法先验的假设了每个cell中只可能有某个一目标的bbox中心,算法的任务就是判定这个cell中是否是某一目标的中心,并且预测该目标的类别。因而如果有多个目标的bbox中心落到一个cell里,那么可能就会检测不出来或者检测的精度降低。实际上这个划分cell的操作并不是直接使用图形切分来实现的,而是通过设计网络和loss来实现的。
YOLOv1使用了一个有24层卷积,中间夹了4层池化的卷积网络来提取特征。并且用两个全连接层来输出7*7*30个预测值。

通过对这 7*7*30个预测值进行数据处理,就能得出我们想要的预测bbox框。
2. 关于如何通过设计网络来实现YOLOv1预测bbox的思想
首先我们注意到,模型的最后一层输出按理说虽然是个向量,但是实际上会被看做一个形状为7*7*30的参数图,其中7*7代表着cell的数目,30为每个cell需要预测出多少个参数。这些参数都是回归参数。我们可以看看在YOLOv1中是如何定义这30个参数的。首先对于每个cell,模型都要预测出两个不同的框框,不那么正确但是很直观的理解就是对于每个cell,模型都预测两遍bbox。每个bbox使用四个参数来定位,中心点坐标x,y和宽高w,h。最后为每个bbox添加一个参数C(confitence),代表着该bbox是前景的置信度。这样我们就为每个cell构造出了10个回归目标值。另外对于论文中当时使用的PASCAL VOC数据集,一共有20种目标类别,所以最后为每个gird预测一下这20个目标类别概率的预测值。这样如果预测出该cell包含一个目标bbox中心的话我们就可以进一步的对这个目标进行分类。
在介绍模型的loss之前,先要说明两个很重要也是最难理解的点,就是 1. 参数C(置信度)的意义。2. 如何定义背景前景的预测是“正确”的。我们知道,我们几乎不可能要求目标检测算法能够完美的100%预测出来一个与实际bbox一样的边框,我们其实在定义背景前景分类的正确与否的时候只需要要求预测的bbox和实际的bbox大致重合就行,并且我们可以把重合的程度作为我们的置信度。
1.关于参数C
作者将参数C赋予的意义是希望它能够尽量的去接近我们预测出的bbox与GT(ground truth)的IOU。请注意我这里使用的“尽量的去接近”这个表述,因为C毕竟也是个预测值,它也不可能完全的反映预测bbox与GT的IOU。只能说我们可以在训练阶段使用它与真实IOU的差值作为损失,来尽量让模型学习这一行为。实际在训练完成后使用这个模型的时候(习惯称为测试阶段),我们会利用参数C来评判预测的bbox是否为前景。
2. 关于如何定义预测的bbox是否为前景
由上面可以知道,在测试阶段我们可以根据预测的参数C来评判对应的bbox是否为前景。但是在训练阶段我们就要做的更精细一些,毕竟我们是有一个用来参考的GT的。我们可以提前计算一下IOU, 当IOU>阈值时认为该bbox为前景,反之认为为背景。 另外,YOLOv1还提到了另一个概念,我们把每一个预测出的bbox及其置信度的组合叫做一个“predictor”, 每个cell中有两个“predictor”。如果在该cell下的两个“predictor”都被判定为是前景,那么IOU更高的那个被称为“responsible” for the ground 的 “predictor”。
所以针对上面提到的几个目标值和几组不同的predictor,YOLOv1设计了如下的loss。

3. 一些值得强调的实现细节
因为CNN网络的输入可以是任意尺寸的,所以为了缩短训练时间,使用了224*224的图像对前20个卷积层进行了预训练。预训练时增加了一个平均池化层和一个全连接层作为预测值的回归器。预训练完成后,再用448*448的图像进行总体模型的训练,即添加最后4层卷积和2层全连接层。
在loss部分,宽高的回归使用的不是直接和真实值差的平方,而是将预测值和真实值都开根号后进行相减再平方。这样做的好处是尽量的能让大box和小box有比较相近的缩放权值。
因为实际上每张图中还是背景部分比较多,所以如果按照前面loss的设计思路,很有可能会使在训练时背景的权重过高,导致前景的分类训不出来。于是YOLOv1给非感兴趣predictor增加了一个<1的权值,这样可以减小背景样本的训练权重。同时给感兴趣区域的坐标预测loss加权。
实际的x,y,w,h的预测值都会被归一化,在训练时使用的GT就已经这么做了,其中x,y表示的是对于每个grid cell的相对位置,和在图像上的绝对位置无关。w,h是在整个图片的大小层面上被归一化的。
注:网络设计的精妙主要体现在loss的设计上!
YOLOv2
YOLOv2在YOLOv1的基础上主要解决的是定位精度差(bbox框画的不准)和召回率低(有好多目标没检测出来)的问题。
1. 在精度上的改进
1)在每个卷积层后面都增加了Batch Normalization (BN)层。
2)训练时采用更高分辨率图像进行10 epochs的预训练。然后进行微调。
3)引入了anchor机制
在YOLOv1中,每个grid cell里最多只能有一个“predictor”对最终的预测负责,另一个“predictor”将被舍弃。但YOLOv2不同,v2使用了anchor的概念来代替predictor。每个cell内先验的定义5个不同形状的anchor。对于每个anchor都分别进行前景背景的预测,并且分别预测目标的类别。这样每个cell里的每个anchor都可以是互相独立的。anchor的作用机制是,我们先验的假设所有目标的bbox都能用5种形状不同的anchor中的某一个来近似。当我们发现某个anchor内很可能含有目标时,可以对这个anchor进行微调修正,从而得出正确的bbox。对于每个cell,我们预设的5个anchor的中心点都在cell的相对原点处。
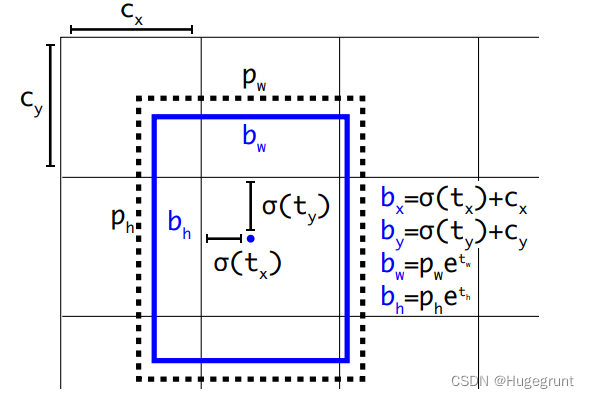
微调的参数我们可以通过预测得出。对于每个anchor,我们都用四个参数来进行修正(tx,ty,tw,th),分别代表bbox中心点x轴方向的位移,bbox中心点y轴方向的位移, bbox宽度方向的缩放的对数,bbox高度方向的缩放的对数。这几个参数的详细解析请参考目标检测中边框回归的直观理解。另外,虽然理论上来说对于bbox的“微调”的程度是不设限的,因为你可以对一个anchor通过缩放和平移生成任意形状大小位置的bbox。但显然这违背了我们的初衷,我们认为每个cell内预测出的bbox的中心只能在该cell以内,虽然网络会尽量的将anchor回归成存在目标的bbox,但如果对于这个cell是在找不到一个合适的bbox那也不强求,就交给其他合适的cell去做。所以在预测出tx,ty后,还需要过一个sigmoid函数进行归一化,0,0代表该cell的相对坐标原点,1,1代表该cell原点的对角。对于缩放比例,理论上是不设限的,实际上会以对应anchor的size进行归一化处理。下图中(bx,by,bw,bh)就是回归后bbox的绝对位置和绝对尺寸,下图展现了它们是如何根据(tx,ty,tw,th)被计算出来的。
YOLOv2使用K means聚类在COCO数据集和VOC数据集上面进行IOU形状相近的bbox的聚类。根据肘部法则,最后选择K=5聚类了五种bbox的形状类型。然后为每个cell都给出了五种先验的anchor。网络会为每个anchor预测25个参数,其中前5个参数包括4个bbox位置精修参数,1个前景背景预测参数,它们的意义如下
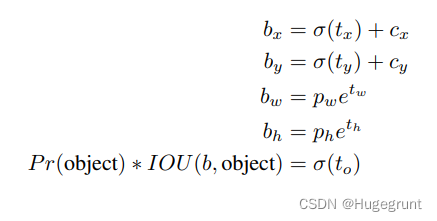
另外每个anchor还包括20个类别的分类参数。也就是每个cell预测5*25=125个参数
2. 在速度上的改进
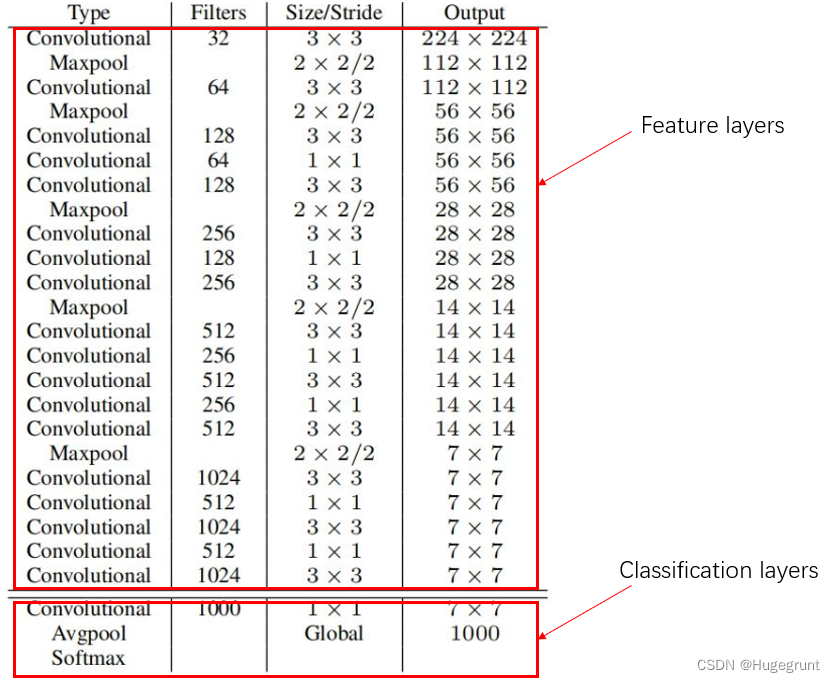
YOLOv2使用了一个新的网络结构,是作者自创的一种叫Darknet-19的网络结构。将这个网络先在ImageNet上面用224*224的图片训练150个epochs,然后再用448*448的图片训练10个epochs进行调整。因为该网络的输出只是一个简单的分类任务,所以实际应用到YOLO上时需要对网络进行修改。将训练好的网络进行剪裁,把最后的卷积层和最大池化层删除这样就得到一个用于特征提取的CNN网络。之后把这个特征提取器后面附上3层3*3*1024的卷积网络进行滤波和特征的进一步提取,最后增加一个1*1*125的卷积层进行回归任务,添加后再对网络进行160epochs的迁移训练。实际使用时,会将输入的图片resize成416*416大小,这和训练时采用的size都不一样。可以看到网络最后的输出将是一个13*13*125的特征图,这个特征图中每个像素代表着一个cell,每个cell预测125个特征。输出特征图为奇数的好处是,一般很多图像中的目标bbox都在图像中间附近,所以这样就存在一个中间的cell来对这些bbox进型更好的预测,这是一个小技巧。
但我们看到,13*13的特征图感受野太大了,很多细节的信息就可能会被忽略。这就使得很多小型目标没有被检测出来,YOLOv2认为,可以用26*26的特征图来提取细节特征用于检测小目标。26*26的特征图是在网络中间的层截取的,截取出来后被分为四个13*13的特征图,并且在通道维度上和13*13的特征图进行拼接。
YOLOv3
YOLOv3 主要是以牺牲了一定的速度FPS为代价,换取精度的大幅提升。
1. 网络结构的变化
v3应用了残差block来构建更深的Darknet-53网络。在目标检测时删除该网络最后的分类层使用该网络进行特征提取。利用该网络提取出来的特征进行bbox预测。
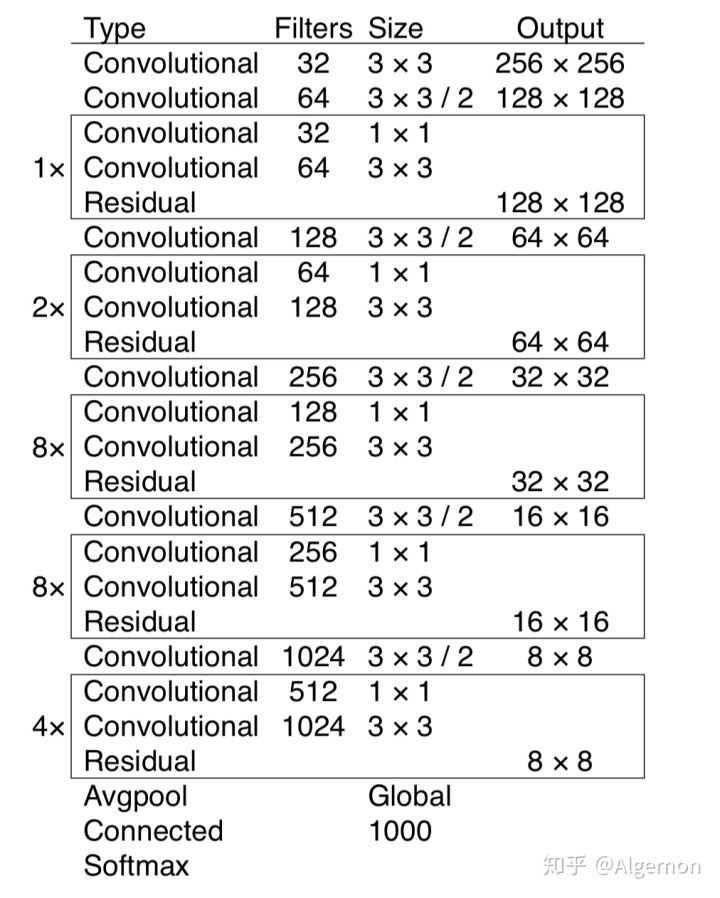
v3中最重要的改进是使用了9种size的anchor。9中anchor是根据k means聚类在数据集上运行得来的。9个anchor根据大小被分为三组,每组anchor使用不同的特征层进行预测。v2中的一个观点是因为浅层特征对于预测小尺寸bbox的表现更好,所以最终输出特征时要将深层特征和稍微浅一点的特征进行拼接。而v3采取了一个更加直接的办法,那就是在Darknet53中间和末尾截取三个不同尺寸的特征。因为浅层特征对于深度的语义特征提取的能力较弱,所以v3也将深层特征进行上采样后增加到浅层特征里。这种思想借鉴于特征金字塔的思想。
2. 其他改进
卷积层代替池化层
在网络中,V3删除了池化层,全部使用卷积层进行下采样。
置信度和分类变为分类任务
将背景前景置信度回归任务修改为分类任务,即训练时当某个输出框和GT的IOU大于所有输出框时,将该输出框的置信度真实标签值视为1。对于其他和GT的IOU大于阈值的预测框我们直接舍弃不让它们产生任何loss,因为我们对它们是否为前景这件事不确定,那就干脆即不让他们作为正例让网络学习,也不作为反例让网络学习,既然如此,那么产生bbox位置和具体分类相关的loss这件事也就没必要了。对于和GT的IOU小于阈值预测框,我们只将它们作为反例进行学习,同样也没必要对bbox的位置和具体的分类产生loss。
所以置信度的loss部分使用Binary cross entropy(BCE)loss.
另外目标的分类也改用sigmoid函数进行预测,这样每个分类都会得出一个独立的评分。在预测的时候可以设定阈值,对于高于阈值的所有分类将被赋予检测框。比如说一个检测框检测出来了目标,这个目标既可以同时是家居和沙发,也可以同时给出两个可能性,比如说一个目标既像狼又像狗那么可能yolov3可能会给出这个目标既可能是狼也可能是狗。
当然分类的loss也被改为BCE loss。
其中一个输出特征层的loss。