
- 1Oracle物化视图(Materialized View)_oracle 物化视图
- 2基于FPGA的并行DDS设计
- 3python渗透工具编写学习笔记:9、web漏洞检测与利用脚本_python语言写网络渗透测试脚本
- 42024.5月更新大麦autojs代码,实现app端自动抢票_autojs 大麦
- 5AI辅写疑似度高风险?七招助你化险为夷!_论文ai风险高怎么解决
- 6Android Studio入门:Android应用界面详解(上)(View、布局管理器)_android studio的view
- 7腾讯后台开发一面(凉)_腾讯后端一面
- 8最新版IDEA(或Android Studio)Lombok的使用方法_android lombok
- 9Centos7防火墙与IPTABLES详解_centos7 iptables 和防火墙
- 10《动手学ROS2进阶篇》8.2RVIZ2可视化移动机器人模型_如何重装rviz2
NeurIPS 2022 | 视觉长尾学习模型为何无法较好地落地?
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
内容来自机器之心
近年来,长尾学习在计算机视觉领域得到了广泛关注,甚至在学术领域的常用设定中有了很好的解决方案,但是该类算法却一直无法很好地落地。
在这篇 NeurIPS 2022 论文中,来自新加坡国立、字节跳动和华为的学者表明:这个问题的本质在于实际应用中的测试集并不是单一的均匀分布的。因此,他们设计了 SADE 算法,即使是在一个固定的长尾分布数据集上训练的模型,也能够自适应地处理多个不同类别分布的测试场景。
2023年2月23日,AI TIME Youth PhD Talk NeurIPS 2022专场邀请到新加坡国立大学博士生张一帆同学带来本篇论文的讲解,点击“阅读原文”即可查看回放。
深度长尾学习是计算机视觉领域中最具挑战性的问题之一,旨在从遵循长尾类别分布的数据中训练出性能良好且类别无偏的深度神经网络。在传统视觉识别任务中,数据的类别分布往往受人为调整而变得均衡,即不同类别的样本量无明显差别。
但在实际应用中,数据的不同类别往往遵循长尾分布(如下图所示):一小部分类别拥有大量的样本(被称为多数类),而其余大部分类别只有较少的样本量(被称为少数类)。
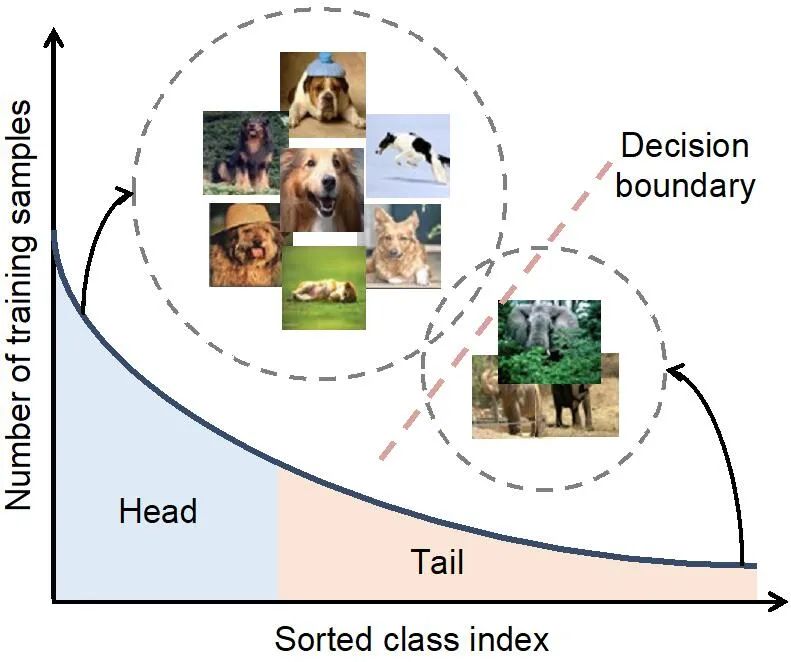
该长尾类别不平衡问题使得神经网络的训练变得非常困难。所得到的模型往往有偏于多数类,即倾向于分对更多多数类样本,导致了模型在样本量有限的少数类上表现不佳。
近年来,越来越多的研究开始探索长尾分类任务,并设计了各类方法来解决长尾类别不平衡问题,期望所得到的模型能在类别平衡的测试集上表现好。例如,Google 的 Logit Adjustment 从理论上提供了优雅的解法,能够较好地处理长尾分类任务中的类别不平衡。然而,学者们近期发现长尾学习问题到达了一个瓶颈,即传统的长尾分类问题似乎已经有了很好地解决方案,但却依然无法较好地落地。那么,问题到底出在哪里呢?
这一问题的本质源于现存方法对传统长尾分类任务的设定:假设测试数据集的类别是均匀分布的,即不同的类别有相同的测试样本量。在这样的设定下,我们只需考虑如何优化模型在平衡数据集上的性能即可,因此最前沿的长尾学习方法往往都能在均匀分布测试集上表现良好。但问题在于,在实际应用场景中,测试集的类别分布是不可控的:它也许是均匀分布,但也可能是与训练集一样的长尾分布,甚至是反向长尾分布(即训练集中的少数类变成了测试集中的多数类)。
如下示意图所示,由现存长尾方法训练得到的模型虽能够较在服从均匀分布的测试集上表现良好,但却无法处理好遵循其他类别分布的测试集。这就导致那些在论文中看似表现良好的长尾学习模型无法较好地应用到实际场景中。
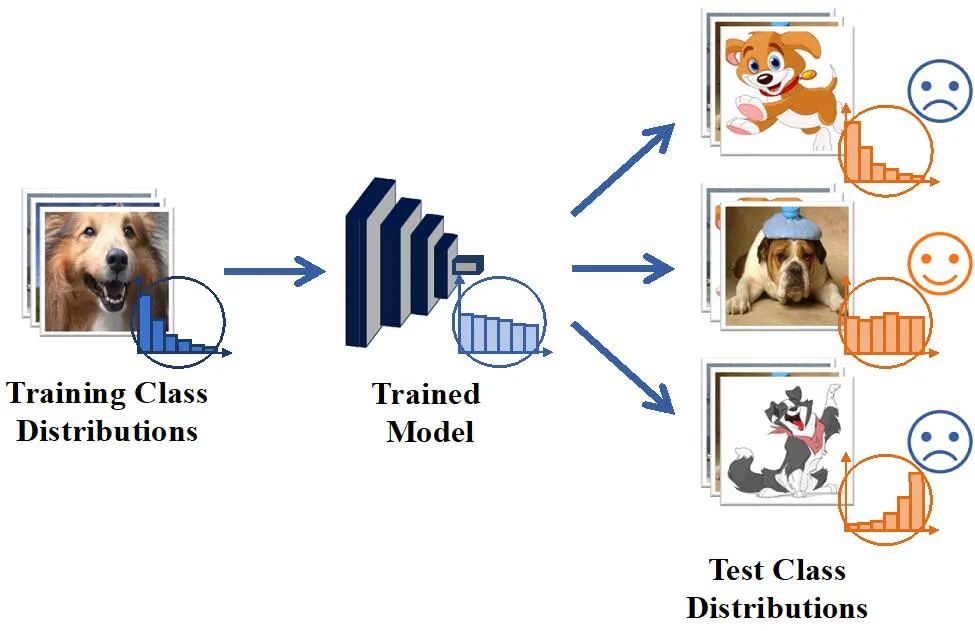
那么,这个问题可以被解决吗?让我们看看这篇 NeurIPS 2022 的新方法究竟能够为长尾学习的落地带来哪些改变吧。

论文链接:https://arxiv.org/pdf/2107.09249.pdf
该工作呼吁大家研究测试分布未知的长尾识别问题(Test-agnostic Long-tailed Recognition)。该任务旨在从一个固定的长尾分布训练集上训练一个神经网络模型,并期望它能在服从不同类别分布(包括均匀、长尾、反向长尾分布)的测试集上表现良好。为了解决该任务,该论文提出了 SADE(Self-supervised Aggregation of Diverse Experts)算法,在多个数据集的不同类别分布测试集上均取得了显著的性能提升。
总体而言,这项研究阐明了:即使是在一个固定的长尾分布数据集上训练的模型,也能够自适应地处理不同类别分布的测试场景。目前该方法的代码已经开源,感兴趣的小伙伴可以在 Github 上查看。
GitHub:https://github.com/Vanint/SADE-AgnosticLT
方法
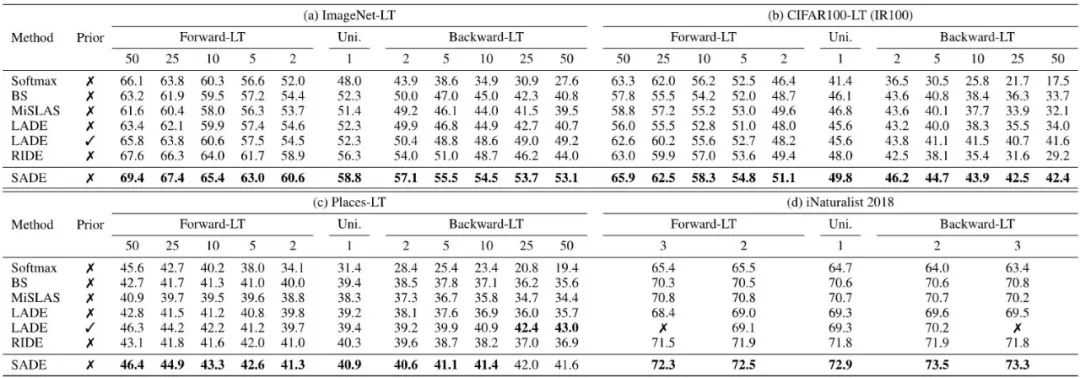
动机和方法框架 该工作发现:不同方法所得模型的性能分布是相对固定的,并不会随着测试分布的变化而变化。如下表所示,传统的 Softmax Cross-entropy 拟合原始长尾分布,因此它在多数类(Many-shot classes)上表现得比少数类(Few-shot classes)更好。这一特性在不同类别分布的测试集上表现一致。而由长尾学习方法(如 Balanced Softmax)所得到的模型则表现得更为均衡,且其性能分布在各测试分布上表现一致。
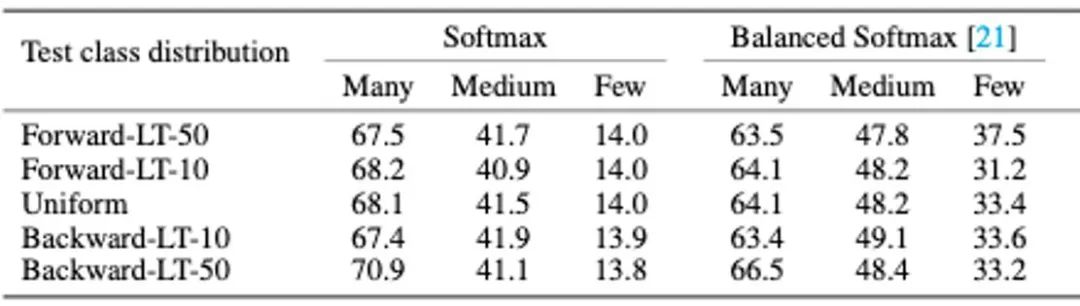
这一现象说明了通过不同方法得到的模型具有不同的技能特长,即擅长不同的类别分布。例如,Softmax 更擅长长尾分布,而 Balanced Softmax 更擅长均匀分布。基于这一发现,自然能联想到:如果能训练多个擅长不同类别分布的模型,并在测试场景下能够有效地组合它们,我们就能自适应地处理任何类别分布了!
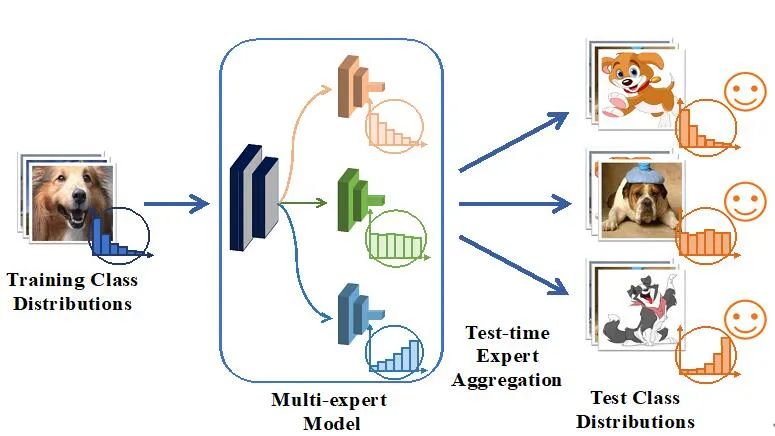
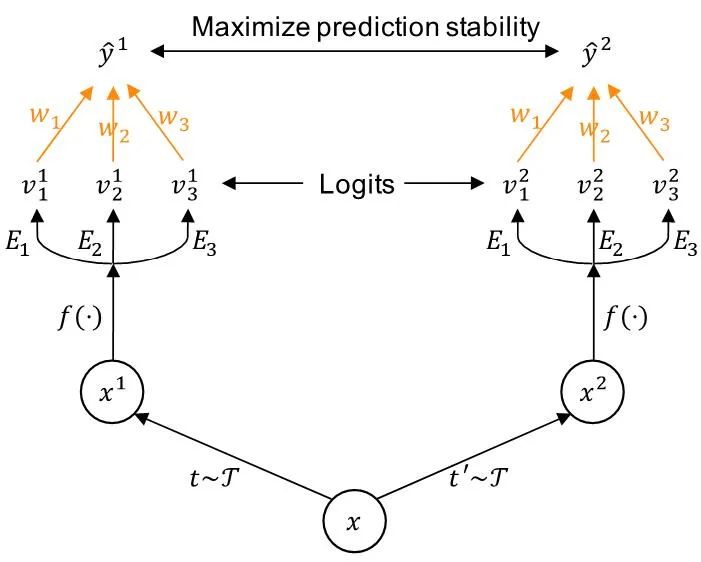
然而,这听起来很简单,但做起来却不太容易。这里有两个难题尚未解决:(1)如何在一个静态的、固定的长尾分布数据集上训练多个擅长不同类别分布的专家模型?(2)如何在完全无标注的测试数据上有效地组合多各专家模型?为了解决这些挑战,SADE 提出了两个解决策略:(a) 特长差异化的多专家模型学习策略,(b) 多专家模型测试场景自适应组合策略,如下图所示。
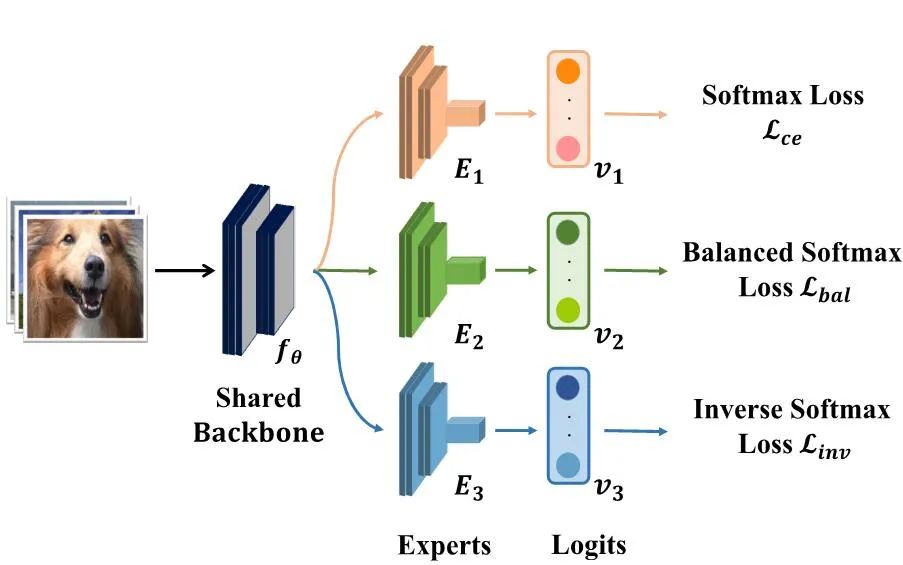
(a) 特长差异化的多专家模型学习策略 为了学习这样一个特长差异化的多专家模型,SADE 利用不同的损失函数训来练不同的专家模型。如下图所示,SADE 利用 Softmax loss 来学习擅长长尾分布的专家模型,用 Balanced Softmax loss 来学习擅长均匀分布的专家模型,并提出了一个新的 Inverse Softmax loss 来学习擅长反向长尾分布的专家模型。
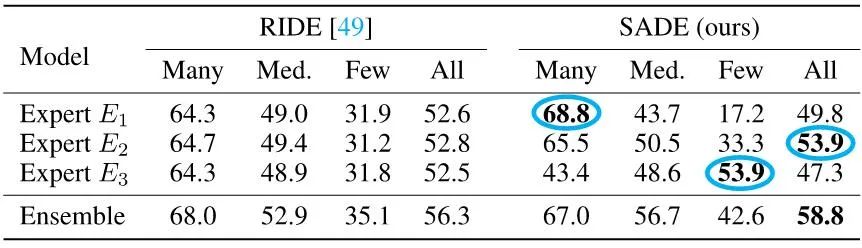
相较于之前致力于学习多个具有相同类别分布的多专家学习方法 RIDE,该策略能有效学习擅长不同类别分布的多专家模型,如下表所示。
(b) 多专家模型测试场景自适应策略 既然我们已经学到多个擅长不同类别分布的专家模型,那么接下就是如何自适应地组合它们。一个自然的想法就是适者生存,即更擅长目标测试集分布的专家应该被分配更高的组合权重。
那么问题来了:在无标签的测试数据上,如何去检测哪个专家更擅长测试集分布呢?为了解决这一问题,该研究观察到:给定一个测试分布,更强的专家模型往往能在预测其熟练类别样本时表现得更加稳定,即更强的专家对于其熟练类别样本的不同变体预测具有更高的预测相似性,如下表所示。
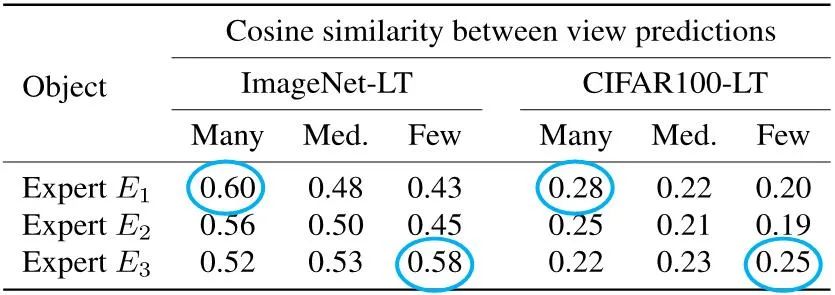
基于该发现,SADE 提出通过最大化样本不同变体之间的预测稳定性来检测更强大的专家模型,并自适应地学习专家模型间的组合权重,如下图所示。
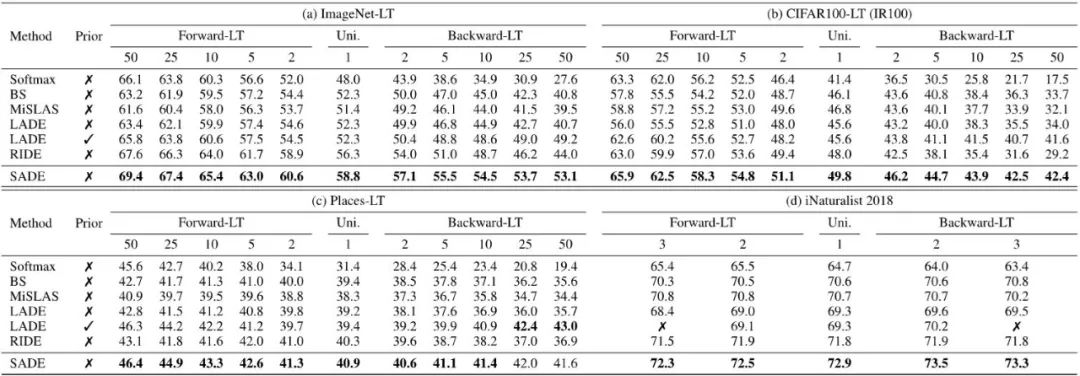
该策略能有效学到适用于未知测试类别分布的专家组合权重(如下表左),从而在不同类别分布(除均匀分布外)的测试集上都能获得显著的性能提升(如下表右)。

基于上述策略,SADE 能够在多个数据集的各种类别分布测试集(包括均匀分布、长尾分布、反向长尾分布)上取得最优的性能。
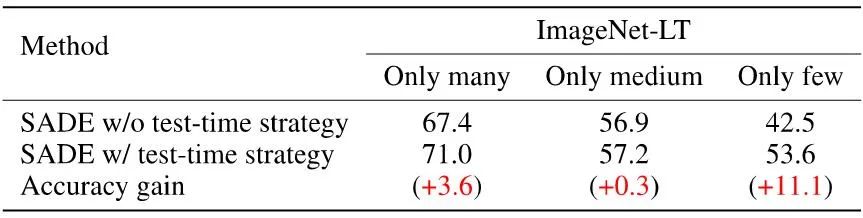
在实际应用场景中,测试数据也许遵循部分类别分布(partial class distribution),即只有部分类别存在。对于这种更加复杂的应用场景,SADE 也能表现良好,如下表所示。
总而言之,这篇 NeurIPS 2022 的研究表明:通过合理的方法设计,即使是一个在固定的长尾分布数据集上训练的模型,也能够自适应地处理不同类别分布的测试场景,而不只是单纯地对一个固定的测试分布不断地过拟合。
因此,该研究有效地推动了视觉长尾学习模型在实际场景中的落地。我们希望通过对这项研究的介绍,大家能重新思考深度长尾学习的落地问题,并设计出更有效和更实际的长尾学习新范式!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了900多位海内外讲者,举办了逾450场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!

