
- 1Rust Web开发框架actix-web入门案例
- 2基于python机器学习算法的农作物产量可视化分析预测系统(完整系统源码+数据库+详细文档+论文+部署教程)_农作物产量预测系统
- 3HDFS文件系统与普通分布式文件系统的差别_比较hadoop的分布式文件系统hdfs与传统文件系统的区别。
- 4Spark:写入CSV文件
- 5SQL 游标使用实例
- 6鸿蒙HarmonyOS应用开发之Node-API常见问题(1),2024年最新HarmonyOS鸿蒙开发社招面试经验_libentry.so 改名
- 7Docker Desktop requires a newer WSL kernel version.
- 8微信小程序【网易云音乐实战】(第六篇 歌曲搜索、自定义模板、分包)_网易云搜索功能微信小程序
- 9堆的基本操作和堆排序
- 10在阿里巴巴做外包的那些日子...._阿里一个外包岗位会给外包公司多少钱
语言模型(一)—— 统计语言模型n-gram语言模型
赞
踩
作为NLP的基础知识,语言模型可能是我们最早接触的知识点之一了,那么语言模型到底是什么呢?在看过一些文章之后我最后形成了我自己的理解:语言模型就是计算词序列(可以是短语、句子、段落)概率分布的一种模型,它的输入是文本句子,输出是该句子的概率,这个概率表明了这句话的合理程度,即这句话符合人类语言规则的程度。
或者我们可以这么理解:传统的语言模型是基于词袋模型(Bag-of-Words)和one-hot编码展开工作的,即在传统的语言模型中要生成一个句子,其实是拿一堆词语进行拼凑,拼凑出一个句子后我们需要有一个评委来对这个机器生成的句子进行打分和评价,语言模型就是这么一位评委,它会给每个句子打出一个概率值,以表明他们与人类语言的接近程度。
比如,词袋中有这么几个词:
“小明”,‘’牛奶,”桌上”,“打翻”,“了“,”的”
如果是我们人类来造句,可能结果是:
“小明打翻了桌上的牛奶“
那么机器也造了两个句子:
“小明打翻了桌上的牛奶“
”小明牛奶打翻的桌上了“
那么语言模型就要出来了,它出来给机器造的两个句子进行打分,理想的状态是给第一个句子打一个高的分数(比如所得的概率值是0.8),给第二个句子打一个较低的分数(概率值0.2),这就是语言模型要做的事。即从数学上讲,语言模型是一个概率分布模型,目标是评估语言中任意一个字符串的生成概率p(S),其中S=(w1,w2,w3,…,wn),它可以表示一个短语、句子、段落或文档,wi取自词表集合W。利用条件概率及链式法则我们可以将p(S)表示为:
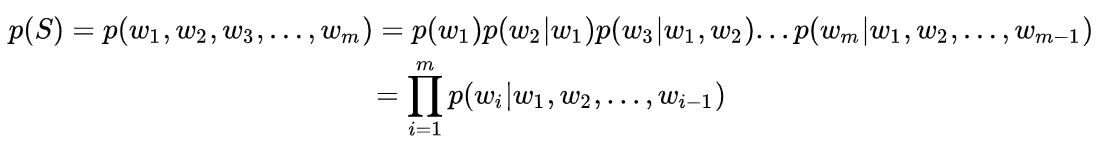
即一个句子生成可以理解为由m个单词共同出现组成,而这些单词又可以看成是词序列中的一员,第i个单词的出现依赖于它的前i-1个词出现的概率。
这样的方法看似已经可以了,但是会至少有以下两个问题:
1.参数量巨大,难以计算。
2.每一部分的概率怎么求得?
带着这两个问题我们来看由上面最原始的语言模型演化出来的统计语言模型——N-gram语言模型。
统计语言模型-N-gram语言模型
什么是N-gram
上面的公式中,某一个词出现的概率与它前面所有词出现的概率有关,数据稀疏问题会导致计算量可能会巨大,而N-gram模型引入了马尔科夫假设,这是一种独立性假设,在这里说的是某一个词语出现的概率只由其前面的n−1个词语所决定,这被称为n元语言模型 ,即n-gram,当n=2时,相应的语言模型就被称为是二元模型。
这样之前的统计语言模型在简化成N-gram语言模型之后就可以表示为:
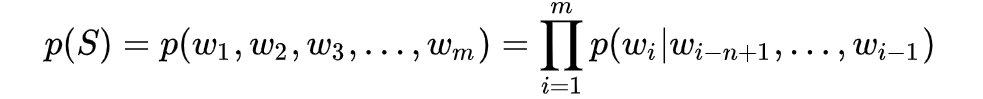
如Bi-gram(N =2):
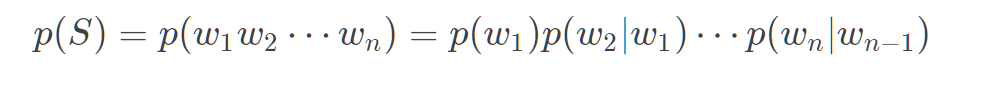
再如Tri-gram(N =3):
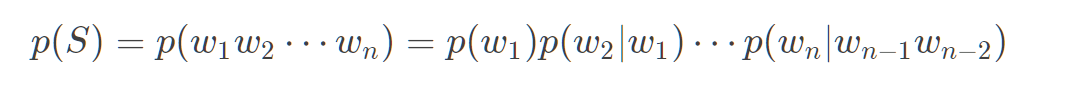
我们很少考虑N>3的N-gram。
举个例子:
我现在想预测出一个完整句子
“我要去吃冰激凌”,按照之前的统计模型,我们可以得出概率:
p(我要去吃冰激凌)=p(冰激凌|我要去吃)p(吃|我要去)p(要去|我)p(我)而若我们基于Bi-gram模型:
p(冰激凌|我要去吃)=p(冰激凌|吃)整个句子出现的概率:
p(我要去吃冰激凌)=p(冰激凌|吃)p(吃|要去)p(要去|我)p(我)
如何计算N-gram中的条件概率
那么,如何计算其中的每一项条件概率 p ( w n ∣ w n − 1 ⋯ w 2 w 1 ) p(w_{n}∣w_{n−1}⋯w_{2}w_{1}) p(wn∣wn−1⋯w2w1)呢?答案是极大似然估计(Maximum Likelihood Estimation,MLE),根据大数定理,当样本数量足够大时,我们可以近似地用频率来代替概率,在这里我们就是要求我们的语料库要比较大,然后概率用数频数的方法来计算:

下面我们通过一个N-gram Language Models文章中的小例子来说明上述公式的计算过程:
我们使用的一个三句话的微型语料库,且我们需要在这三句话的前后分别加上开始符
<s>和结束符</s>,接下来我们来看语料:<s> I am Sam </s> <s> Sam I am </s> <s> I do not like green eggs and ham </s>
- 1
- 2
- 3
利用Bi-gram计算各个概率值:
这样我们就完成了Bi-gram各个概率值的计算,整个句子的概率就是挑选出对应的概率相乘即可。这里需要说明一下为什么要在句子前后分别加上开始符
<s>和结束符</s>:目的是为了让以某一词为条件的所有概率加起来是1,从而保证这确实是一个合法的概率分布。
例如,对于上面的语料:
p(I|sam)+p(</s>|sam)=1/2+1/2=1
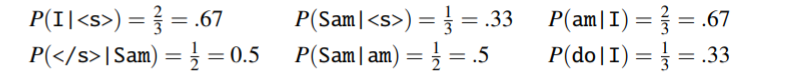
OOV与平滑/回退
在上面的计算过程过会有一个很严重的问题,那就是当我们的语料库有限,大概率会在实际预测的时候遇到我们没见过的词或短语,这就是未登录词(OOV),这样就会造成概率计算的公式中,分子或分母为0,毕竟它们都只是频率。分子为0的话,整个句子的概率是连乘出来的结果是0;分母是0的话,数学上就根本没法计算了,这样的问题我们该怎么解决呢?
方法有几种:
平滑(smoothing):为每个w对应的Count增加一个很小的值,目的是使所有的 N-gram 概率之和为 1、使所有的 N-gram 概率都不为 0。常见平滑方法:
Laplace Smoothing
Add-one:即强制让所有的n-gram至少出现一次,只需要在分子和分母上分别做加法即可。这个方法的弊端是,大部分n-gram都是没有出现过的,很容易为他们分配过多的概率空间。
Add-K:在Add-one的基础上做了一点小改动,原本是加1,现在加上一个小于1的常数K。但是缺点是这个常数仍然需要人工确定,对于不同的语料库K可能不同。
另外还有其他平滑方法:
- Good-Turing smoothing
- Jelinek-Mercer smoothing (interpolation)
- Catz smoothing
- Witten-Bell smoothing
- Absolute discounting
- Kneser-Ney smoothing
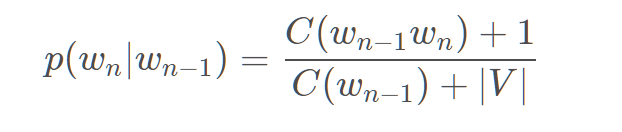
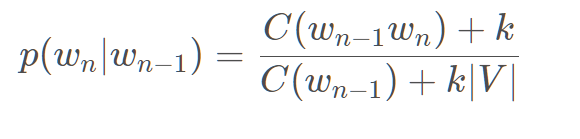
回退(Katz backoff):从N-gram回退到(N-1)-gram,例如Count(the,dog)~=Count(dog)。具体该方法也有公式计算,这里不再赘述,重点在掌握思想。
n-gram的优缺点
总结下基于统计的 n-gram 语言模型的优缺点:
优点:
- 采用极大似然估计,参数易训练;
- 完全包含了前 n-1 个词的全部信息;
- 可解释性强,直观易理解。
缺点:
- 缺乏长期依赖,只能建模到前 n-1 个词;
- 随着 n 的增大,参数空间呈指数增长;
- 数据稀疏,难免会出现OOV的问题;
- 单纯的基于统计频次,泛化能力差。
写在最后
基于n-gram的不足,人们开始尝试用神经网络来建立语言模型,下一篇笔记,我们一起回顾一下基本的前馈神经网络语言模型,以及对应延申出来的循环神经网络语言模型。
加油,不积跬步无以至千里!
参考文章:

