
热门标签
热门文章
- 1我的春招实习+秋招总结【前端开发】_前端找不到实习秋招是不是完了
- 2解决:fatal:unable to access‘https://github.com/xx/xx.git/‘:OpenSSL SSL_read:Connection was reset errno_fatal: unable to access
- 3数据中心GPU集群高性能组网技术分析
- 4LIama3 五一超级课堂 前置知识VScode 远程连接开发机_liama3 使用指南
- 5备忘: 使用langchain结合千问大模型,用本地知识库辅助AI生成代码_langchain和本地大语言模型 摘要提取
- 6PTA 7-9 树层次遍历_我们已知二叉树与其自然对应的树相比,二叉树中结点的左孩子对应树中结点的左孩子,
- 7MySQL数据库之索引_mysql 索引文件
- 8AI探索测试未来:人工智能与自动化测试的结合实战,文末实用干货自行领取!_面向未来的ai自动化测试工具
- 94.0 树莓派做下位机播放视频、控制电机舵机、超声波检测、paj7620手势传感器控制,树莓派串口通信等程序分析_树莓派 播放视频
- 10AITM2-0007 比光密度测定_aitm 2.0007下载
当前位置: article > 正文
基于Amazon Bedrock_构建生成式 AI 应用_亞馬遜 bedrock workshop
作者:盐析白兔 | 2024-05-27 00:35:00
赞
踩
亞馬遜 bedrock workshop
前言
随着生成式人工智能(AIGC)技术的蓬勃发展,技术创作者们再次涌入一个充满挑战与机遇的新领域。Amazon Bedrock 是一个专为创新者设计的平台,它提供了构建生成式人工智能应用程序所需的一切工具和资源。无论您的技术背景如何,Amazon Bedrock 都能让您快速上手并体验到最新的生成式人工智能技术。对于AI新手和希望提升技能的专家来说,Amazon Bedrock 都是一个强大的助力。
今天我们就来一场酣畅淋漓的手把手教程, 让我们快速轻松的感受生成式人工智能的构建
登录Amazon Bedrock
点击链接 如下图所示点击开始实验

进入操作页面开启生成式ai 之旅吧!!
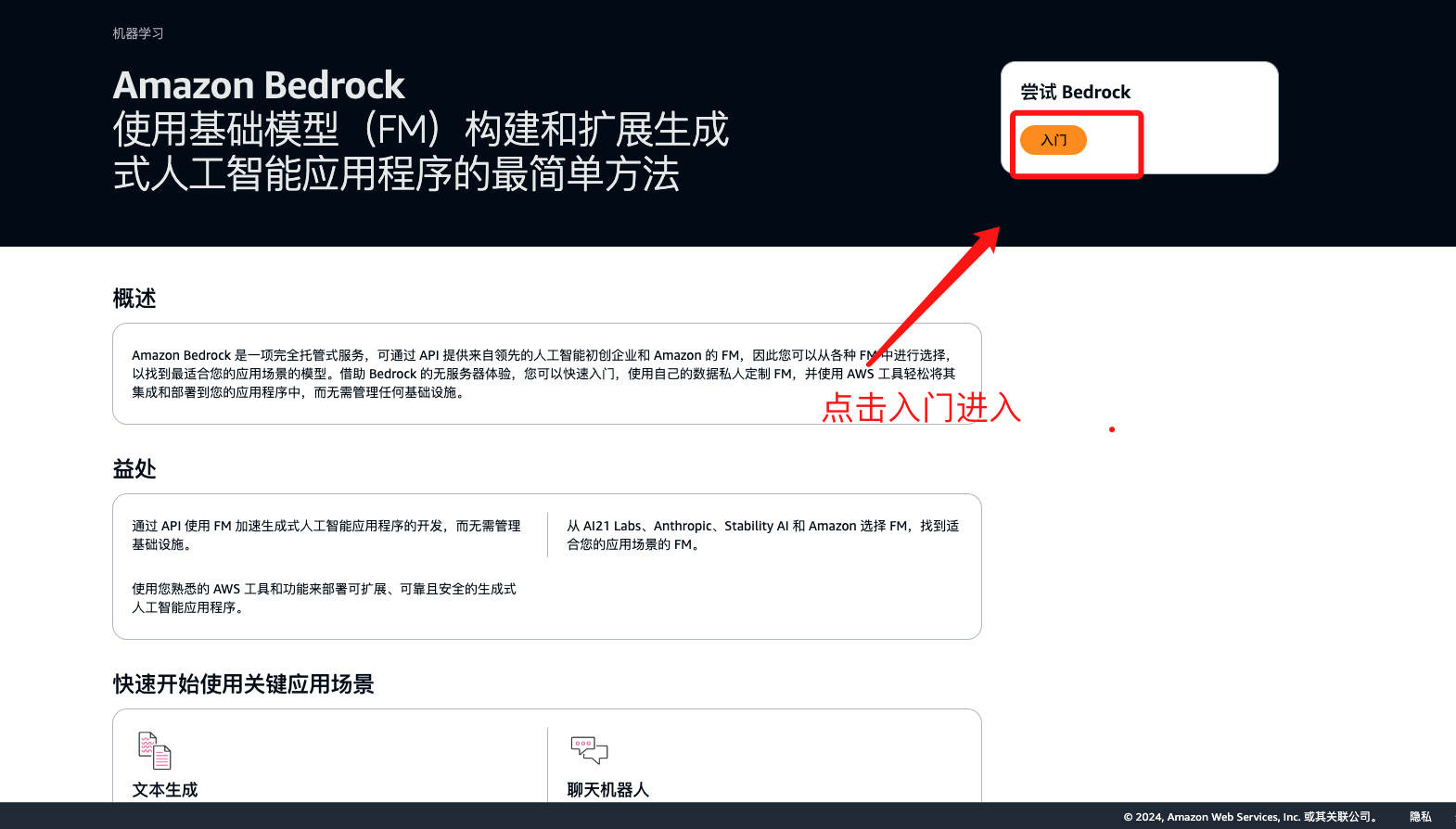
Meta Liama2 模型快速体验
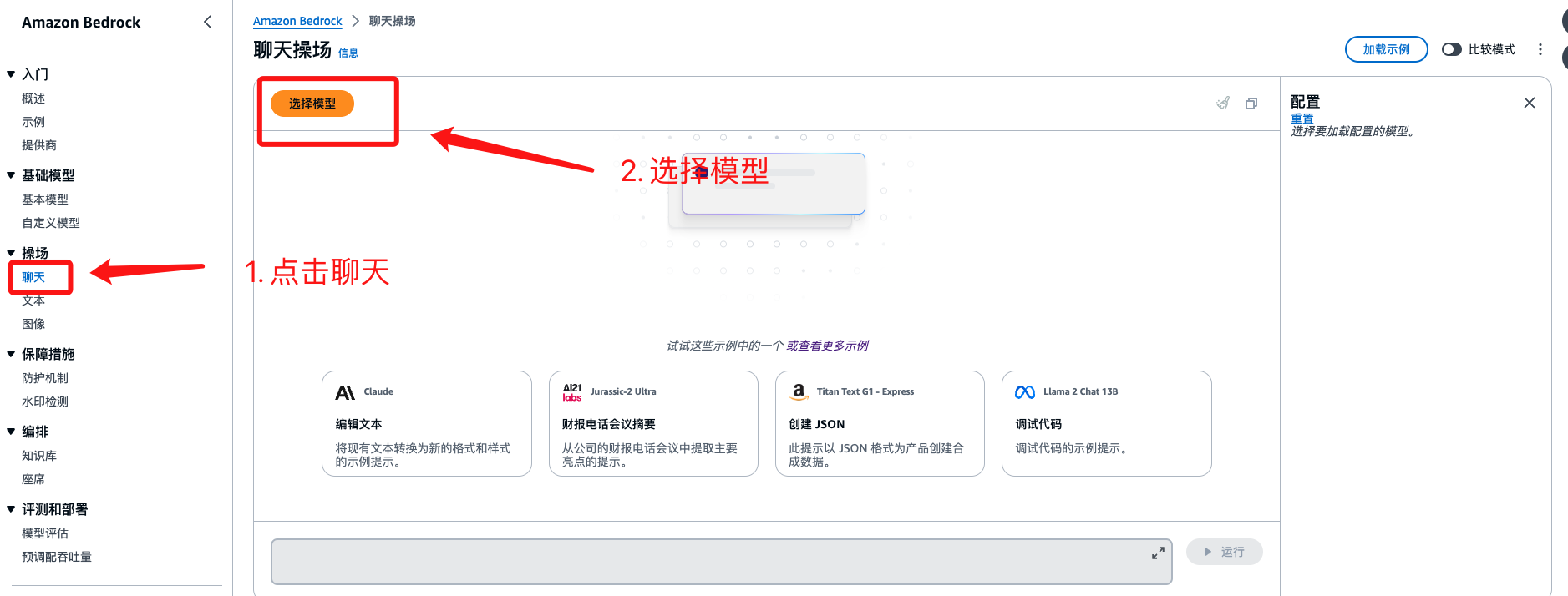
模型这里我们选择 Meta => LIama2 Chat 70B 吞吐量 按需即可
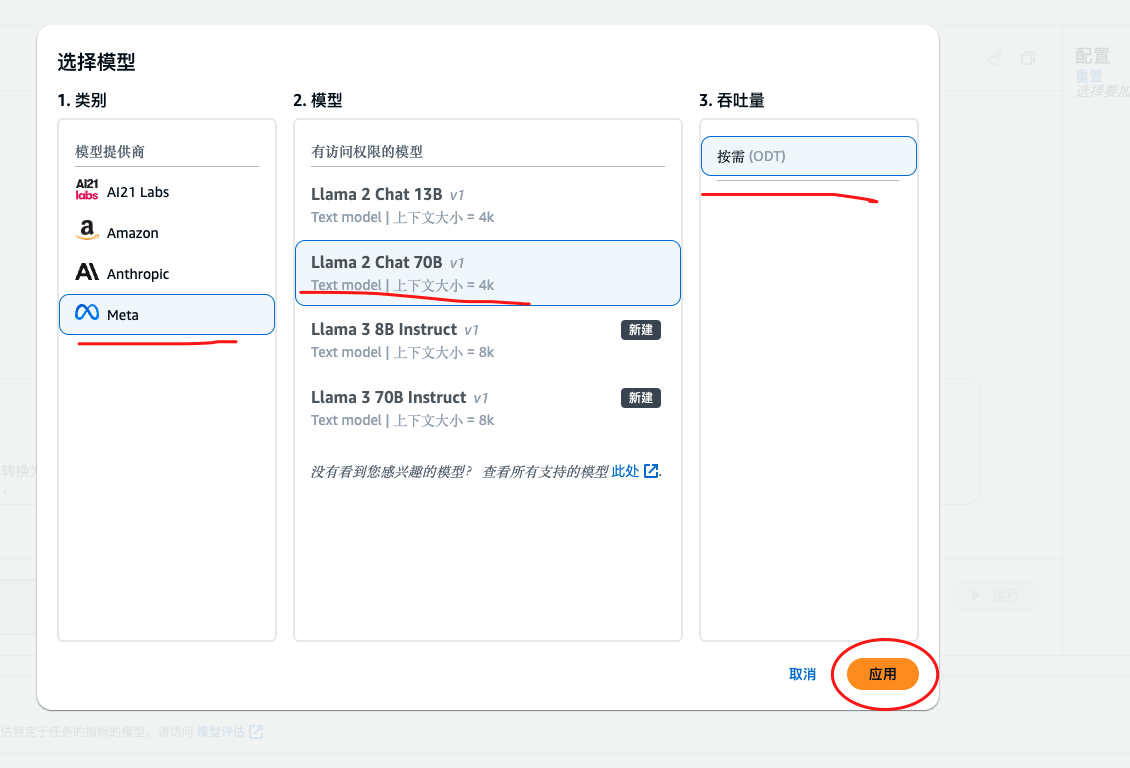
选择完成之后 点击应用
效果演示
当我们点击应用之后 效果如下
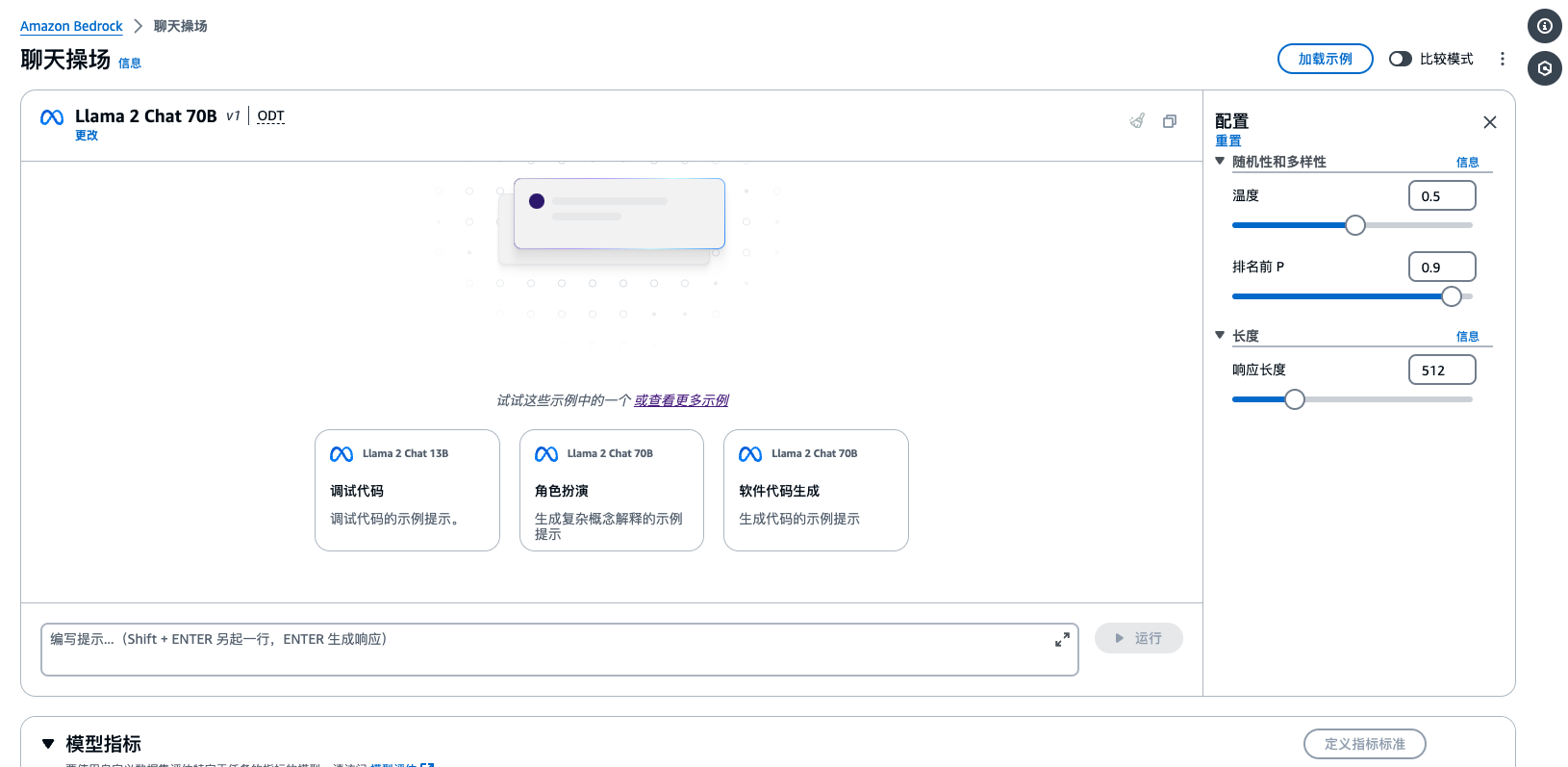
名词解释
| 名称 | 解释 |
|---|---|
| 随机性和多样性 | 通过将输出限制为更可能的结果或改变输出概率分布的形状来影响生成的响应的变化。 |
| 长度 | 通过指定结束响应生成的最大长度或字符序列来限制响应。 |
项目工程介绍
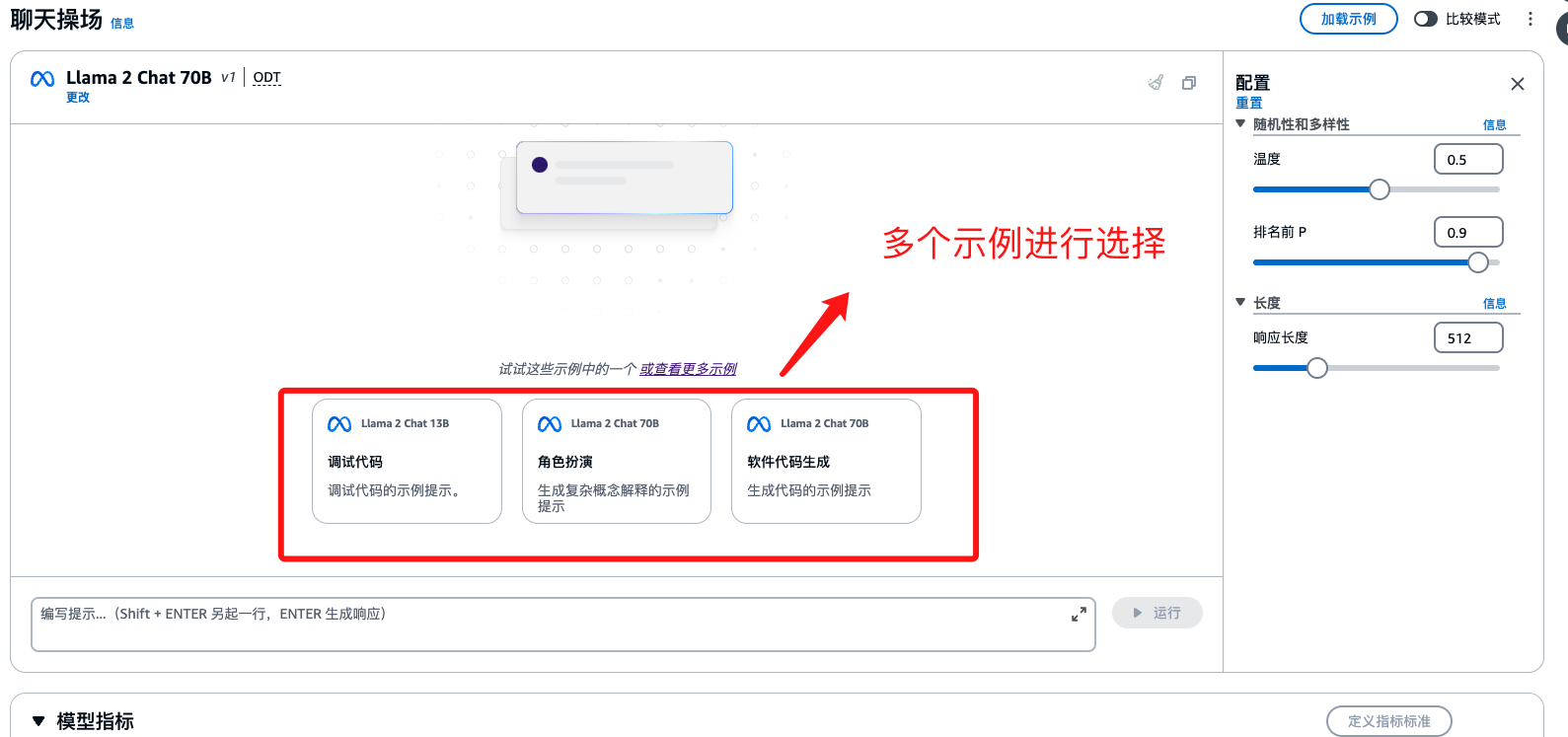
效果演示
我提出的问题是 : JavaScript 中如和理解闭包
回复如下:
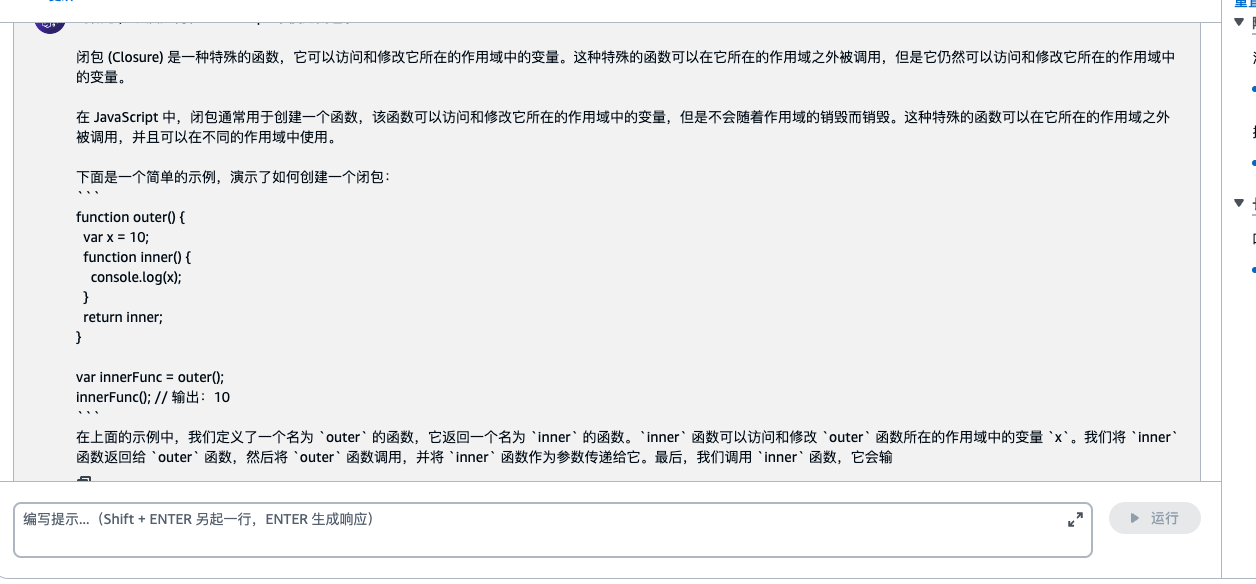
对于代码解释看起来还是有点东西的哦!!
Meta Llama 2 API的调用
打开 Amazon Cloud9 实验环境
打开控制台,搜索Cloud9, 点击进入
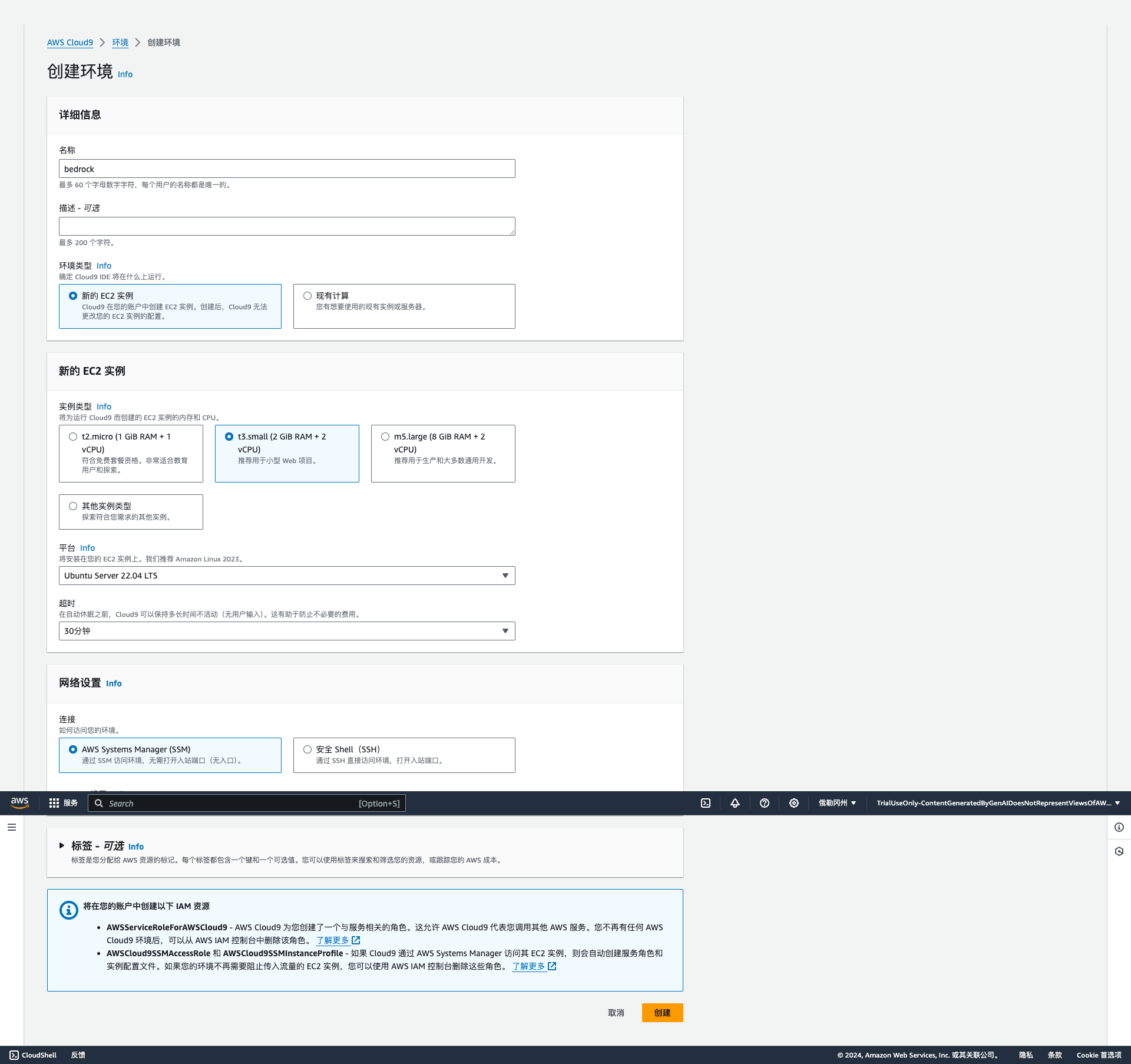
创建环境
设置环境详细信息
- 设置名称为 bedrock
- 设置实例类型 t3.small
- 平台 Ubuntu Server 22.04 LTS
- 超时 30 分钟
温馨提示:
- 实验环境中仅限选择Cloud9 EC2实例为 t3.small (2 GiB RAM + 2 vCPU)
- 基于不浪费的原则,创建Cloud9的时候,超时时间只能选择默认的30分钟的选项,且Cloud9实例数量也将自动审核,如果发现异常会关闭Cloud9实例,甚至封禁账号,务必注意文明实验
熟悉 Amazon Cloud9 实验环境
首次进入 Cloud9 实验环境中需要等待加载
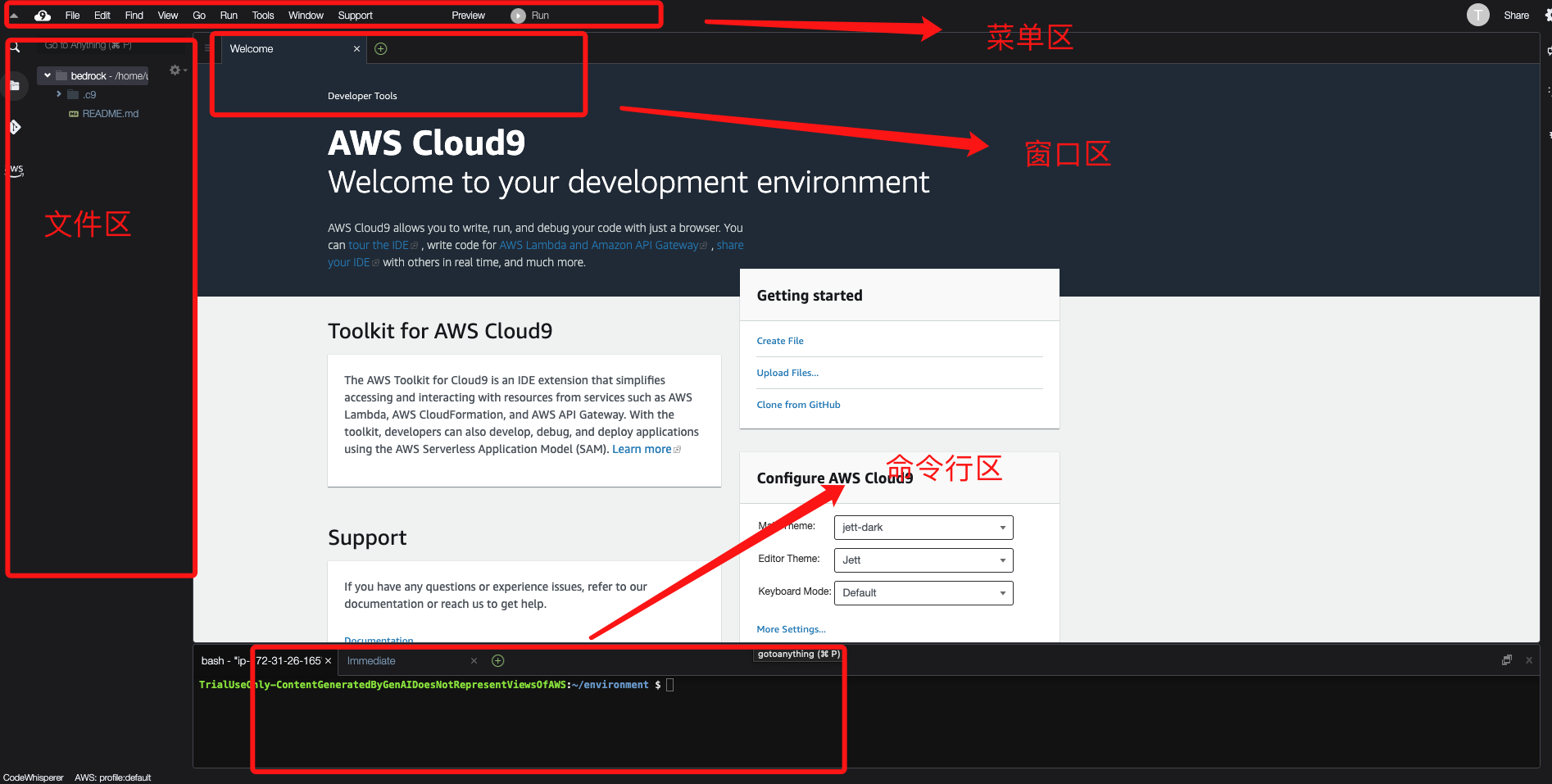
在Amazon Cloud9 IDE中,选择 终端
在终端中输入如下命令
cd ~/environment/
curl 'https://dev-media.amazoncloud.cn/doc/workshop.zip' --output workshop.zip
unzip workshop.zip
- 1
- 2
- 3
- 4
等待解压完成

查看对应的文件目录
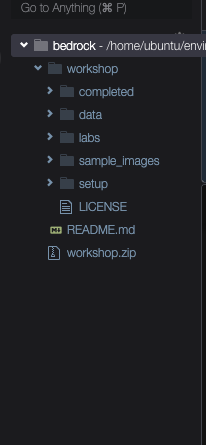
继续使用 终端,安装实验所需的环境依赖项
pip3 install -r ~/environment/workshop/setup/requirements.txt -U
- 1
- 2

编写调用 Meta Llama 2 API 应用
请求参数
| 参数 | 说明 |
|---|---|
| prompt复制 | 要传递给模型的提示,这是必填项。 |
| temperature复制 | 降低响应的随机性,默认值为0.5,取值范围是0到1。 |
| top_p复制 | 忽略可能性较小的选项,默认值为0.9,取值范围是0到1。 |
| max_gen_len复制 | 生成响应的最大令牌数,默认值为512,取值范围是1到2048。 |
返回参数
{
"generation": "\n\n<response>",
"prompt_token_count": int,
"generation_token_count": int,
"stop_reason" : string
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
参数说明说明
| 参数 | 解释意思 |
|---|---|
| 生成 | 指生成的文本。 |
| prompt_token_count复制 | 表示提示中的代币数量。 |
| generation_token_count复制 | 代表生成的文本中的标记数量。 |
| stop_reason复制 | 用于说明响应停止生成文本的原因。其可能的值为:1、stop 意味着模型已结束为输入提示生成文本。2、length表示生成的文本的词元长度超过了对 InvokeModel(如果需要对输出进行流式传输,则为 InvokeModelWithResponseStream)的调用中的 max_gen_len 值。此时响应会被截断为 max_gen_len 个词元。可考虑增大 max_gen_len 的值并重试。 |
操作流程讲解
- 打开workshop/labs/api文件夹,打开文件bedrock_api.py
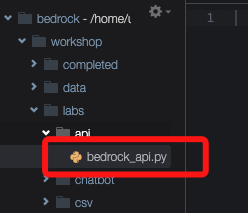
- 导入依赖语句允许我们使用Amazon boto3库来调用Amazon Bedrock
import json
import boto3
- 1
- 2
- 3
- 初始化Bedrock客户端库,创建一个Bedrock客户端
session = boto3.Session()
bedrock = session.client(service_name='bedrock-runtime') #初始化Bedrock客户端库
- 1
- 2
- 3
- 编写API调用代码
我们将确定要使用的模型、提示和指定模型的推理参数。
bedrock_model_id = "meta.llama2-70b-chat-v1" #设置模型
prompt = "说一下冒泡排序的原理?" #提示词
body = json.dumps({
"prompt": prompt,
"max_gen_len": 2048,
"temperature":0.5,
"top_p":0.9
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 使用Amazon Bedrock的invoke_model函数进行调用
response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求
- 1
- 2
- 从模型的响应JSON中提取并打印返回的文本
response_body = json.loads(response.get('body').read())
response_text=response_body['generation'] #从 JSON 中返回相应数据
print(response_text)
- 1
- 2
- 3
- 4
- 保存文件,并准备运行脚本
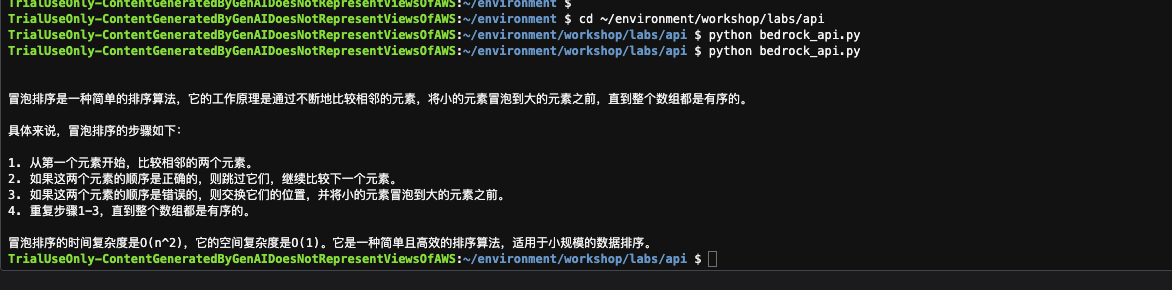
cd ~/environment/workshop/labs/api
python bedrock_api.py
- 1
- 2
- 3
8 运行结果如下
完整代码
import json import boto3 session = boto3.Session() bedrock = session.client(service_name='bedrock-runtime') #初始化Bedrock客户端库 bedrock_model_id = "meta.llama2-70b-chat-v1" #设置模型 prompt = "说一下冒泡排序的原理?" #提示词 body = json.dumps({ "prompt": prompt, "max_gen_len": 2048, "temperature":0.5, "top_p":0.9 }) response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求 response_body = json.loads(response.get('body').read()) response_text=response_body['generation'] #从 JSON 中返回相应数据 print(response_text)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
是不是很简单呢
总结
随着生成式人工智能的逐渐火爆, 期待小伙伴们也快快的加入进来体验一番吧!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/629070
推荐阅读
相关标签

