
- 1人脸表情识别相关研究_大学开展表情识别技术的相关研究工作
- 2当YOLOv5碰上PyQt5_yolov5加入pyqt5
- 3centos系列:【 全网最详细的安装配置Nginx,亲测可用,解决各种报错】_centos 安装nginx
- 4Python从入门到自闭(基础篇)
- 5EVO轨迹评估工具学习笔记_evo轨迹对准怎么从轨迹最开始对准
- 6学术英语视听说2听力原文_每天一套 | 高中英语听力专项训练(2)(录音+原文+答案)...
- 7深度解析:六个维度透视Claude3的潜能与局限_claude技术剖析
- 8git revert是个好东西_git revert 某个文件
- 9Jetson orin部署大模型示例教程_jetson部署
- 10YOLOv9:目标检测的新里程碑
【聚类】DBSCAN聚类(含代码实战)_dbscan案例加代码
赞
踩
写在前面:
首先感谢兄弟们的关注和订阅,让我有创作的动力,请一键三连,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。
往期聚类文章回归:
【聚类】K-Means聚类(优缺点、手肘法、轮廓系数法、检测异常点、图像压缩,含代码实战)
1、介绍
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的空间聚类算法,广泛应用于机器学习和数据挖掘领域。DBSCAN不需要预先指定簇的数量,而是基于数据点的密度来确定簇的形状和数量。
2、原理
只要任意两个样本点是密度直达或密度可达的关系,那么这两个样本点就被归为同一簇类。具体来说,算法从数据集D中随机选择一个核心点作为“种子”,然后找到这个核心点的所有密度可达对象,即一个簇。这些核心点以及它们ε邻域内的点被标记为同一个类。接着,算法再找一个未标记过的核心对象,重复上述步骤,直到所有核心对象都被标记为止。
在这个过程中,有两个重要的参数:Eps和MinPts。Eps决定了邻域的大小,即一个点的ε邻域。MinPts表示一个点要成为核心点,其ε邻域内必须包含的最少点数。如果Eps过大,可能导致所有数据对象都被划分到同一个簇中;如果Eps过小,则可能将相近但本应属于不同簇的数据对象划分到不同簇中。同样,MinPts参数过大会导致过度聚类,而过小则可能将随机噪声点误划分为簇。因此,对于给定的数据集,需要对这两个参数进行适当调整,以得到最优的聚类结果。
首先介绍几个关键词:
**核心点:**对于每个数据点,如果在其邻域内包含至少MinPts个样本点(包括该点自身),则该点被认为是核心点
**直接密度可达:**如果一个点是核心点,那么与其在同一个簇中的所有其他点都是直接密度可达的
**密度可达:**如果存在一个核心点序列(p1, p2, …, pn),其中p1是核心点,pn是目标点,而pi+1是pi的直接密度可达点,那么p1与pn是密度可达的
**密度相连:**如果存在一个核心点q,使得p和q都是密度可达的,那么p和q是密度相连的
基于以上的定义,DBSCAN将数据点分为三类:
**核心点:**具有足够密度的点,即其周围有足够数量的样本点
**边界点:**不是核心点,但位于核心点的邻域内
**噪声点:**既不是核心点,也不是边界点的点
3、优缺点
3.1优点
- 不需要预先指定簇的数量: DBSCAN不需要用户事先指定聚类的数量,这使得它对于不同形状和大小的簇都能有效地工作
- 对噪声点鲁棒: DBSCAN可以有效地处理噪声点,即那些不属于任何簇的点,因为它能够识别并排除它们
- 能够发现任意形状的簇: 由于DBSCAN基于密度可达性,而不是距离阈值,它可以识别出任意形状的簇,而不仅仅是球状或凸形状
- 适用于不同密度的簇: DBSCAN能够适应不同密度的簇,因为它使用局部密度来定义簇的概念
3.2缺点
- 对密度不均匀的数据敏感: DBSCAN对密度不均匀的数据集可能表现不佳,因为它使用相同的密度阈值来定义所有簇,而在密度变化较大的区域可能无法有效地分割簇
- 对参数敏感: DBSCAN的性能依赖于两个主要参数,即半径 ε(eps)和最小样本点数目
MinPts。选择合适的参数可能需要一些经验,且不同的数据集可能需要不同的参数 - 可能无法处理变化密度的簇: 当簇的密度变化较大时,DBSCAN可能无法正确地将它们分割为多个簇
- 样本量大收敛速度慢: 当样本量很大时,收敛速度慢,比较耗时
4、总结
综上所述,DBSCAN聚类算法通过基于密度的空间聚类方式,实现了对数据的有效划分,并能在处理复杂形状和异常点方面表现出色。但在应用时,需要根据数据集的特点选择合适的参数,以获取最佳的聚类效果。
5、代码实战
5.1生成模拟数据
生成实验需要的模拟数据代码:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_circles from sklearn.preprocessing import StandardScaler # 生成环形数据 X, y = make_circles(n_samples=850, noise=0.05, random_state=42, factor=0.5) # 在左上角生成更多的数据 extra_data = np.random.normal(loc=[-1.5, 1.5], scale=0.3, size=(80, 2)) X = np.vstack([X, extra_data]) # 缩放数据 X = StandardScaler().fit_transform(X) # 可视化数据 plt.scatter(X[:, 0], X[:, 1], c='blue', marker='o', s=35, edgecolor='k') plt.title("DBSCAN Demonstration Data") plt.xlabel("Feature 1") plt.ylabel("Feature 2") plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5.2DBSCAN代码
核心代码如下:
from sklearn.cluster import DBSCAN
# 使用DBSCAN进行聚类
dbscan = DBSCAN(eps=0.3, min_samples=5)
y_dbscan = dbscan.fit_predict(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_dbscan, cmap='viridis', marker='o', s=30, edgecolor='k')
plt.title("DBSCAN Clustering Result")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
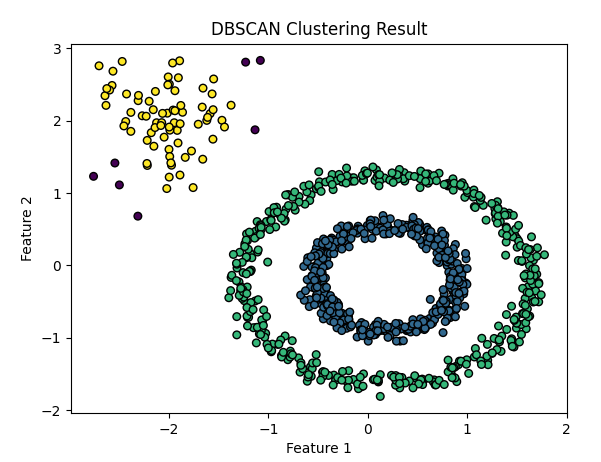
根据可视化可知数据集被聚类为4个簇其中一类为噪声点,这也是DBSACN的另外一个作用异常值检验,DBSCAN将那些不属于任何聚类簇的数据点视为噪声点。这些噪声点就是异常值,因为它们不符合在高密度区域中形成聚类的定义
5.3删除噪声点可视化

思考,主动一点。
主动一点,工作态度。
主动协调;主动提出想法。
参考资料
https://mp.weixin.qq.com/s/xDo9LYxQe54zUjKwq2Oznw


