
- 1算法-动态规划入门(C++实现)_c++动态规划
- 2Guitar Pro8软件激活码许可证如何获取?最新2024年免费教学步骤_guitarpro8许可证
- 3CNN中的卷积的作用及原理通俗理解_添加卷积cnn的作用是什么?
- 4HybridCLR热更新介绍
- 5用I/O流建立一个text.txt并写入字符。_用io流以文本方式建立一个文件txt,写入字符
- 6Redis集群原理和总结_redis的无主集群
- 7网络原理——TCP/IP--数据链路层,DNS
- 8Java安全--CC1的补充和CC6_yso cc6
- 9计划有变,国内应用厂商都在适配HarmonyOS?_haromony os next 适配情况_鸣潮适配鸿蒙吗
- 10基于OpenHarmony 系统通过S7协议读取西门子PLC数据_go plc s7
基于Python3的Django应用编写备忘录_python备忘录web应用
赞
踩
目录
cookies知识点详解
子类HttpResponseRedirect(注意namespace的配置)
前言
该备忘录是基于以下版本开发
- Mac OS High sierra 10.13.6
-
- mintoudeMacBook-Pro-2:~ mintou$ python3 -m django --version
- 2.2.1
- mintoudeMacBook-Pro-2:~ mintou$ ipython3
- Python 3.7.3 (default, Mar 27 2019, 09:23:39)
- [Clang 10.0.0 (clang-1000.11.45.5)] on darwin
-
-
安装
- pip3 install Django
-
- pip3 install ipython3
-
- FVFXGM44HV29:mysite mikejing191$ ipython3
- Python 3.7.3 (default, Mar 27 2019, 09:23:39)
- Type 'copyright', 'credits' or 'license' for more information
- IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.
-
- In [1]: import django
-
- In [2]: django.get_version()
- Out[2]: '2.2.1'
-
- In [3]:
-
-

创建项目(模型映射表)
cd到指定目录(例如桌面),mkdir一个文件夹放项目
然后执行
django-admin startproject test1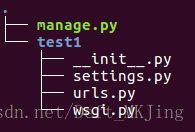
- manage.py:一个命令行工具,可以使你用多种方式对Django项目进行交互
- 内层的目录:项目的真正的Python包
- _init _.py:一个空文件,它告诉Python这个目录应该被看做一个Python包
- settings.py:项目的配置
- urls.py:项目的URL声明
- wsgi.py:项目与WSGI兼容的Web服务器入口
创建应用(默认方式)
1.cd到manage.py下的目录,然后执行创建一个booktest的应用
- mintoudeMacBook-Pro-2:DJangoProject mintou$ pwd
- /Users/mintou/Desktop/DJangoProject
- mintoudeMacBook-Pro-2:DJangoProject mintou$ ls
- test1
- mintoudeMacBook-Pro-2:DJangoProject mintou$ cd test1/
- mintoudeMacBook-Pro-2:test1 mintou$ ls -a
- . booktest manage.py
- .. db.sqlite3 test1
- mintoudeMacBook-Pro-2:test1 mintou$ python3 manage.py startapp booktest
从这也可以看到Django是默认用的sqlite3编写的
看下应用的目录

2.定义模型类
- 有一个数据表,就有一个模型类与之对应
- 打开models.py文件,定义模型类
- 引入包from django.db import models
- 模型类继承自models.Model类
- 说明:不需要定义主键列,在生成时会自动添加,并且值为自动增长
- 当输出对象时,会调用对象的str方法
- from django.db import models
-
-
- class BookInfo(models.Model):
- book_title = models.CharField(max_length=20)
- book_publish_date = models.DateTimeField()
-
- def __str__(self):
- # 2.1最新版本不需要encode
- return self.book_title
-
-
- class HeroInfo(models.Model):
- hero_name = models.CharField(max_length=20)
- hero_gender = models.BooleanField()
- hero_content = models.CharField(max_length=100)
- # 这里和1.x版本不同的是需要增加on_delete CASCADE代表级联操作。主表删除之后和这个关联的都会跟随删除
- hero_book = models.ForeignKey('BookInfo', on_delete=models.CASCADE)
-
- def __str__(self):
- return self.hero_name
3.生成数据表迁移
- 激活模型:编辑settings.py文件,将booktest应用加入到installed_apps中
- # Application definition
-
- INSTALLED_APPS = [
- 'django.contrib.admin',
- 'django.contrib.auth',
- 'django.contrib.contenttypes',
- 'django.contrib.sessions',
- 'django.contrib.messages',
- 'django.contrib.staticfiles',
- 'booktest',
- ]
- 生成迁移文件:根据模型类生成sql语句
python3 manage.py makemigrations- 迁移文件被生成到应用的migrations目录
- 执行迁移:执行sql语句生成数据表
python3 manage.py migrate这个 migrate 命令选中所有还没有执行过的迁移(Django 通过在数据库中创建一个特殊的表 django_migrations 来跟踪执行过哪些迁移)并应用在数据库上 - 也就是将你对模型的更改同步到数据库结构上。
迁移是非常强大的功能,它能让你在开发过程中持续的改变数据库结构而不需要重新删除和创建表 - 它专注于使数据库平滑升级而不会丢失数据。我们会在后面的教程中更加深入的学习这部分内容,现在,你只需要记住,改变模型需要这三步:
- 编辑
models.py文件,改变模型。 - 运行
python manage.py makemigrations为模型的改变生成迁移文件。 - 运行
python manage.py migrate来应用数据库迁移。
数据库迁移被分解成生成和应用两个命令是为了让你能够在代码控制系统上提交迁移数据并使其能在多个应用里使用;这不仅仅会让开发更加简单,也给别的开发者和生产环境中的使用带来方便。
4.测试数据操作
回到manage.py的目录进入shell,导入包然后执行代码查看所有BookInfo的信息
- mintoudeMacBook-Pro-2:test1 mintou$ pwd
- /Users/mintou/Desktop/DJangoProject/test1
- mintoudeMacBook-Pro-2:test1 mintou$ ls
- booktest db.sqlite3 manage.py test1
- mintoudeMacBook-Pro-2:test1 mintou$ python3 manage.py shell
- Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08)
- Type 'copyright', 'credits' or 'license' for more information
- IPython 6.3.1 -- An enhanced Interactive Python. Type '?' for help.
-
- In [1]: from booktest.models import BookInfo, HeroInfo
-
- In [2]: from django.utils import timezone
-
- In [3]: from datetime import *
-
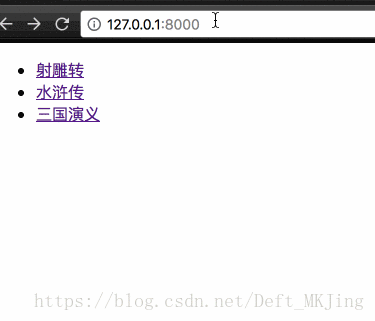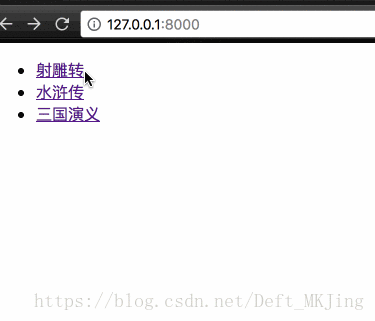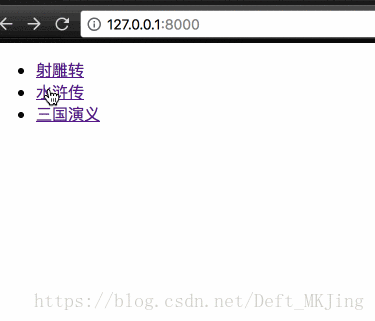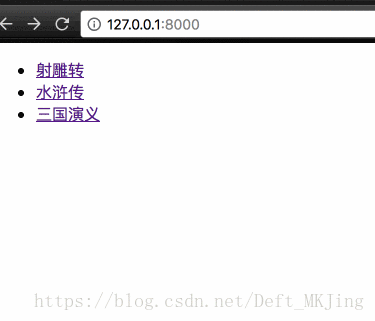
- In [4]: BookInfo.objects.all()
- Out[4]: <QuerySet [<BookInfo: 射雕银熊转>, <BookInfo: 水浒传>]>
- 新建图书信息:
- In [5]: book1 = BookInfo()
-
- In [6]: book1.book_title = "三国演义"
-
- In [8]: book1.book_publish_date = datetime(year=2018,month=1,day=30)
-
- In [9]: book1.save()
- /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/django/db/models/fields/__init__.py:1421: RuntimeWarning: DateTimeField BookInfo.book_publish_date received a naive datetime (2018-01-30 00:00:00) while time zone support is active.
- RuntimeWarning)
-
- In [10]: BookInfo.objects.all()
- Out[10]: <QuerySet [<BookInfo: 射雕银熊转>, <BookInfo: 水浒传>, <BookInfo: 三国演义>]>
- 查找图书信息:
- In [11]: BookInfo.objects.get(pk=3)
- Out[11]: <BookInfo: 三国演义>
- 修改图书信息:
- In [12]: book2 = BookInfo.objects.get(pk=1)
-
- In [13]: book2.book_title
- Out[13]: '射雕银熊转'
-
- In [14]: book2.book_title = "射雕转"
-
- In [15]: book2.save()
- 删除图书信息:
book2.delete()关联对象的操作
- 对于HeroInfo可以按照上面的操作方式进行
- 添加,注意添加关联对象
- In [18]: HeroInfo.objects.all()
- Out[18]: <QuerySet [<HeroInfo: 郭靖>, <HeroInfo: 黄蓉>, <HeroInfo: 浪里白条>, <HeroInfo: 小李广>, <HeroInfo: 花和尚>]>
-
- In [19]: h=HeroInfo()
-
- In [20]: h.hero_name = "霹雳火"
-
- In [21]: h.hero_gender = True
-
- In [22]: h.hero_content = "晴明"
-
- In [23]: BookInfo.objects.all()
- Out[23]: <QuerySet [<BookInfo: 射雕转>, <BookInfo: 水浒传>, <BookInfo: 三国演义>]>
-
- In [24]: b2=BookInfo.objects.get(pk=2)
-
- In [25]: h.hero_book=b2
-
- In [26]: h.save()
-
- In [27]: HeroInfo.objects.all()
- Out[27]: <QuerySet [<HeroInfo: 郭靖>, <HeroInfo: 黄蓉>, <HeroInfo: 浪里白条>, <HeroInfo: 小李广>, <HeroInfo: 花和尚>, <HeroInfo: 霹雳火>]>
- 获得关联集合:返回当前book对象的所有hero
- In [28]: b2.heroinfo_set.all()
- Out[28]: <QuerySet [<HeroInfo: 浪里白条>, <HeroInfo: 小李广>, <HeroInfo: 花和尚>, <HeroInfo: 霹雳火>]>
- 有一个HeroInfo存在,必须要有一个BookInfo对象,提供了创建关联的数据:
- In [29]: h = b2.heroinfo_set.create(hero_name='豹子头',hero_gender=True,hero_con
- ...: tent="灵宠")
-
- In [30]: HeroInfo.objects.all()
- Out[30]: <QuerySet [<HeroInfo: 郭靖>, <HeroInfo: 黄蓉>, <HeroInfo: 浪里白条>, <HeroInfo: 小李广>, <HeroInfo: 花和尚>, <HeroInfo: 霹雳火>, <HeroInfo: 豹子头>]>
Django后台管理系统
服务器
- 运行如下命令可以开启服务器
python3 manage.py runserver
- 可以不写ip,默认端口为8000
- 这是一个纯python编写的轻量级web服务器,仅在开发阶段使用
- 服务器成功启动后,提示如下信息
- mintoudeMacBook-Pro-2:test1 mintou$ python3 manage.py runserver
- Performing system checks...
-
- System check identified no issues (0 silenced).
- August 16, 2018 - 10:07:53
- Django version 2.1, using settings 'test1.settings'
- Starting development server at http://127.0.0.1:8000/
- Quit the server with CONTROL-C.
- 默认端口是8000,可以修改端口
python3 manage.py runserver 8080
- 打开浏览器,输入网址“127.0.0.1:8000”可以打开默认页面
- 如果修改文件不需要重启服务器,如果增删文件需要重启服务器
- 通过ctrl+c停止服务器
管理操作
-
站点分为“内容发布”和“公共访问”两部分
- “内容发布”的部分负责添加、修改、删除内容,开发这些重复的功能是一件单调乏味、缺乏创造力的工作。为此,Django会根据定义的模型类完全自动地生成管理模块
使用django的管理
- 创建一个管理员用户
- python3 manage.py createsuperuser
-
- 按提示输入用户名、邮箱、密码
- 启动服务器,通过“127.0.0.1:8000/admin”访问,输入上面创建的用户名、密码完成登录
- 进入管理站点,默认可以对groups、users进行管理
管理界面本地化
- 编辑settings.py文件,设置编码、时区
- LANGUAGE_CODE = 'zh-Hans'
- TIME_ZONE = 'Asia/Shanghai'
向admin注册模型
- 打开booktest/admin.py文件,注册模型
- from django.contrib import admin
- # 这里Python3编写就不能和2一样直接写models,需要在写一个.
- from .models import BookInfo, HeroInfo
-
- admin.site.register(BookInfo)
- admin.site.register(HeroInfo)
自定义管理页面
- Django提供了admin.ModelAdmin类
- 通过定义ModelAdmin的子类,来定义模型在Admin界面的显示方式
- class QuestionAdmin(admin.ModelAdmin):
- ...
- admin.site.register(Question, QuestionAdmin)
列表页属性
- list_display:显示字段,可以点击列头进行排序
list_display = ['pk', 'book_title', 'book_publish_date']- list_filter:过滤字段,过滤框会出现在右侧
list_filter = ['book_title']
- search_fields:搜索字段,搜索框会出现在上侧
search_fields = ['book_title']
- list_per_page:分页,分页框会出现在下侧
list_per_page = 10
添加、修改页属性
- fields:属性的先后顺序
fields = ['book_publish_date', 'book_title']
- fieldsets:属性分组
- fieldsets = [
- ('basic',{'fields': ['book_title']}),
- ('more', {'fields': ['book_publish_date']}),
- ]
关联对象
-
对于HeroInfo模型类,有两种注册方式
- 方式一:与BookInfo模型类相同
- 方式二:关联注册
-
按照BookInfor的注册方式完成HeroInfo的注册
- 接下来实现关联注册
- from django.contrib import admin
-
- # Register your models here.
-
- from .models import BookInfo, HeroInfo
-
-
- # 插入的Book的时候插入Hero 指定三条
- class HeroInfoInline(admin.StackedInline):
- model = HeroInfo
- extra = 3
-
-
- class BookAdmin(admin.ModelAdmin):
- # 展示方式 UI
- list_display = ['pk', 'book_title', 'book_publish_date']
- # 搜索UI
- search_fields = ['book_title']
- # 插入BookInfo的时候可以带上Hero子类插入,具体信息看HeroInfoInline的属性
- inlines = [HeroInfoInline]
-
-
- class HeroAdmin(admin.ModelAdmin):
- list_display = ['pk', 'hero_name', 'hero_gender', 'hero_content', 'hero_book']
- search_fields = ['hero_name']
-
-
- # 这里把需要的models注册进行 例如 BookInfo 和 HeroInfo 最基本的UI展示
- # 如果需要自定义UI就需要写一个继承于admin.ModelAdmin来指定字段编写展示
- admin.site.register(BookInfo, BookAdmin)
- admin.site.register(HeroInfo, HeroAdmin)
插入BookInfo的时候可以看到底部会附带三个HeroInfo让我们填写
布尔值的显示
- 发布性别的显示不是一个直观的结果,可以使用方法进行封装 在对应的Model里面编写
- class HeroInfo(models.Model):
- hero_name = models.CharField(max_length=20)
- hero_gender = models.BooleanField()
- hero_content = models.CharField(max_length=100)
- # 这里和1.x版本不同的是需要增加on_delete CASCADE代表级联操作。主表删除之后和这个关联的都会跟随删除
- hero_book = models.ForeignKey('BookInfo', on_delete=models.CASCADE)
-
- def __str__(self):
- return self.hero_name
-
- def gender(self):
- if self.hero_gender:
- return "男"
- else:
- return "女"
-
- gender.short_description = '性别'
- 在admin注册中使用gender代替hero_gender
- class HeroAdmin(admin.ModelAdmin):
- list_display = ['pk', 'hero_name', 'gender', 'hero_content', 'hero_book']
- search_fields = ['hero_name']
视图
- 在django中,视图对WEB请求进行回应
- 视图接收reqeust对象作为第一个参数,包含了请求的信息
- 视图就是一个Python函数,被定义在views.py中
- from django.shortcuts import render
- from django.http import HttpResponse
-
-
- def index(request):
- return HttpResponse('<h1>Hello Mikejing<h1>')
-
-
- def detail(request,id):
- return HttpResponse('detail page--->%s'%id)
URLconf(注意namespace的配置)
- 在Django中,定义URLconf包括正则表达式、视图两部分
- Django使用正则表达式匹配请求的URL,一旦匹配成功,则调用应用的视图
- 注意:只匹配路径部分,即除去域名、参数后的字符串
- 在test1/urls.py插入booktest,使主urlconf连接到booktest.urls模块
- from django.contrib import admin
- from django.urls import path, include, re_path
-
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^', include('booktest.urls'))
- ]
这里需要注意两点
1.这个是主入口,需要例如有个应用模块是booktest,我们需要另外再建一个urls,那么根部就需要把它include进来,需要把include包导入
2.2x版本之前是默认支持正则的,Django 2.x之后需要把path和re_path两个包都导入,后者对应正则匹配路径
- 在booktest中的urls.py中添加urlconf
- from django.urls import path, re_path
- from . import views
-
- urlpatterns = [
- re_path(r'^$', views.index, name='index'),
- re_path(r'^book/([0-9]+)$', views.detail, name='detail'),
- ]
模板
- 模板是html页面,可以根据视图中传递的数据填充值
- 创建模板的目录如下图:
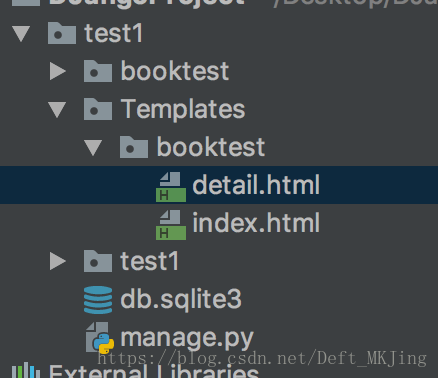
- 修改settings.py文件,设置TEMPLATES的DIRS值
'DIRS': [os.path.join(BASE_DIR, 'templates')],
- 在模板中访问视图传递的数据
- {{输出值,可以是变量,也可以是对象.属性}}
- {%执行代码段%}
index.html模板
- <body>
-
-
- <ul>
- {%for book in lists%}
- <li><a href="/book/{{book.id}}">{{book.book_title}}</a></li>
- {%endfor%}
- </ul>
-
- </body>
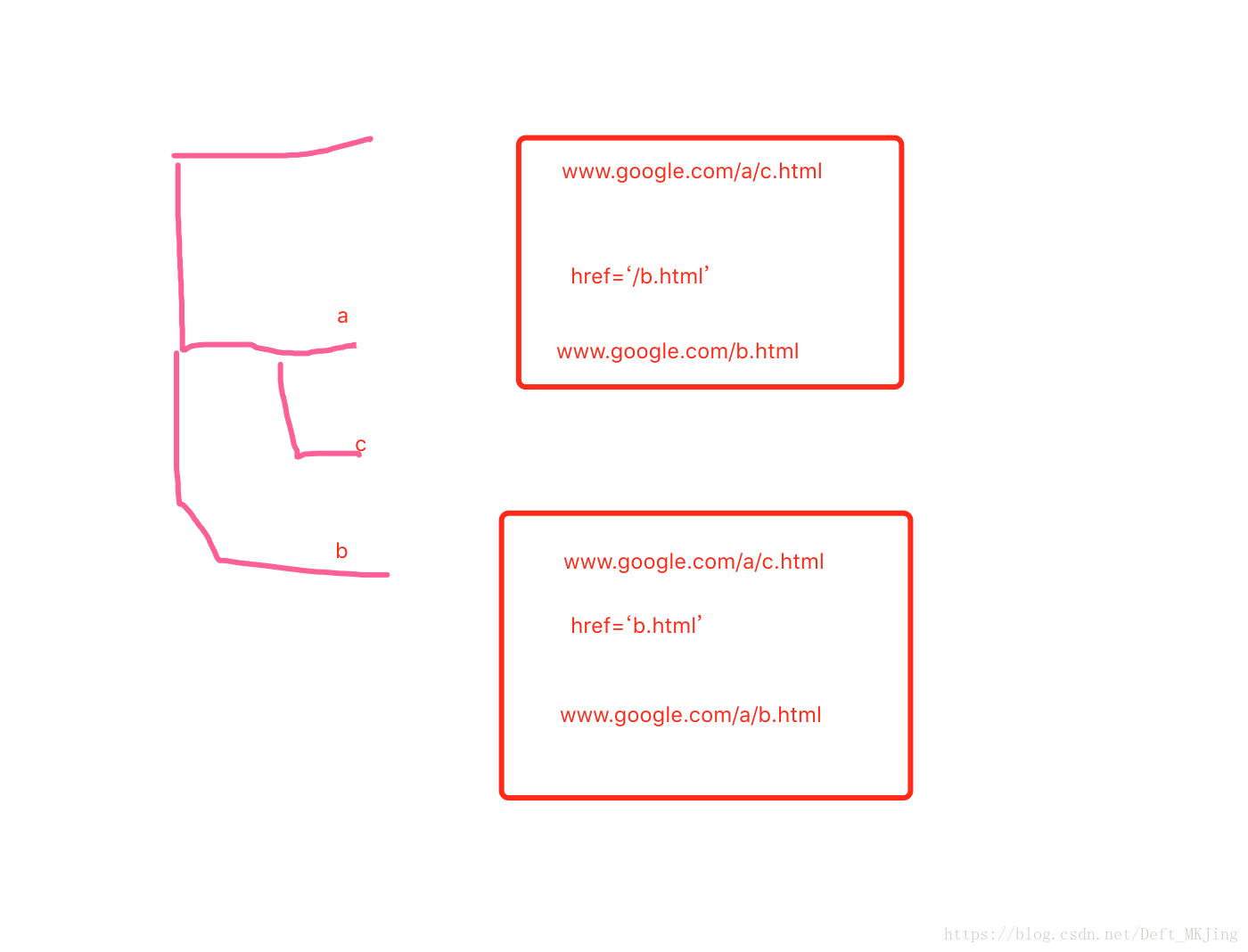
注意:
这里a标签里面的href中写的路径有两个区别如下图,首先明确一点,无论哪种都是从头根部urls开启重新匹配
带/和不带的区别,一般写全路径都需要带上/
detail.html模板
- <body>
-
- <ul>
- {%for hero in lists%}
- <li>{{hero.hero_name}} {{hero.hero_gender}} {{hero.hero_content}}</li>
- {%endfor%}
- </ul>
- </body>
应用urls
- from django.urls import path, re_path
- from . import views
-
- urlpatterns = [
- re_path(r'^$', views.index, name='index'),
- re_path(r'^book/([0-9]+)$', views.detail, name='detail'),
- ]
这里说的不是根目录下的urls,是每个创建的应用对应的urls,里面如果用了re_path正则来匹配,那么正则里面获取值的方式就是(),加了就能传递到views.detail方法里面作为第二个参数,没有默认还是一个
views里面的id就是正则()里面匹配到的id,根据id查找对应的heros进行模板渲染
- from django.shortcuts import render
- from django.http import HttpResponse
- from .models import *
-
-
- def index(request):
- books = BookInfo.objects.all()
- context = {'lists': books}
- return render(request, 'booktest/index.html', context)
-
-
- def detail(request, id):
- book = BookInfo.objects.get(pk=id)
- heros = book.heroinfo_set.all()
- return render(request, 'booktest/detail.html', {'lists': heros})
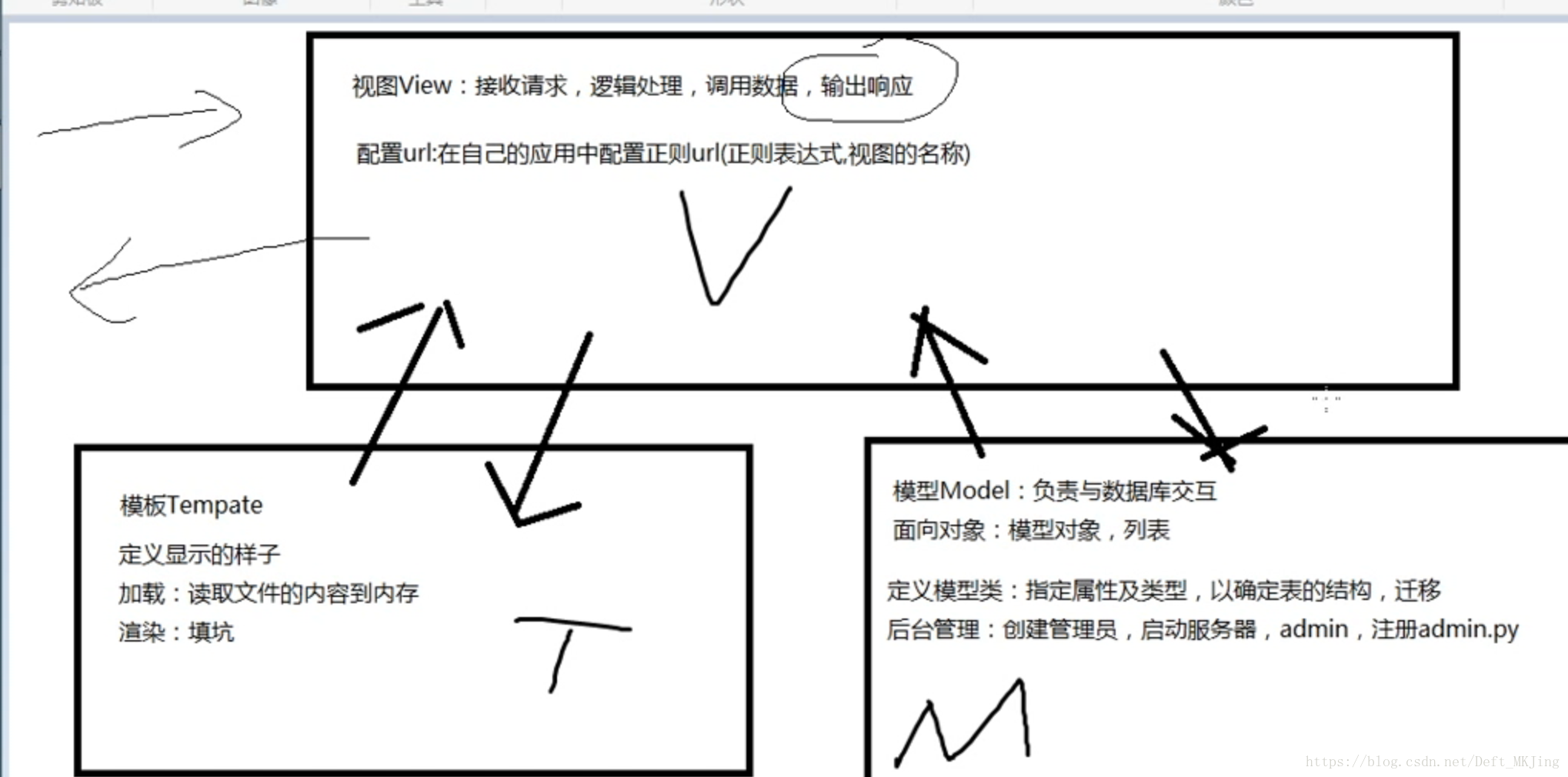
模型Model详细介绍
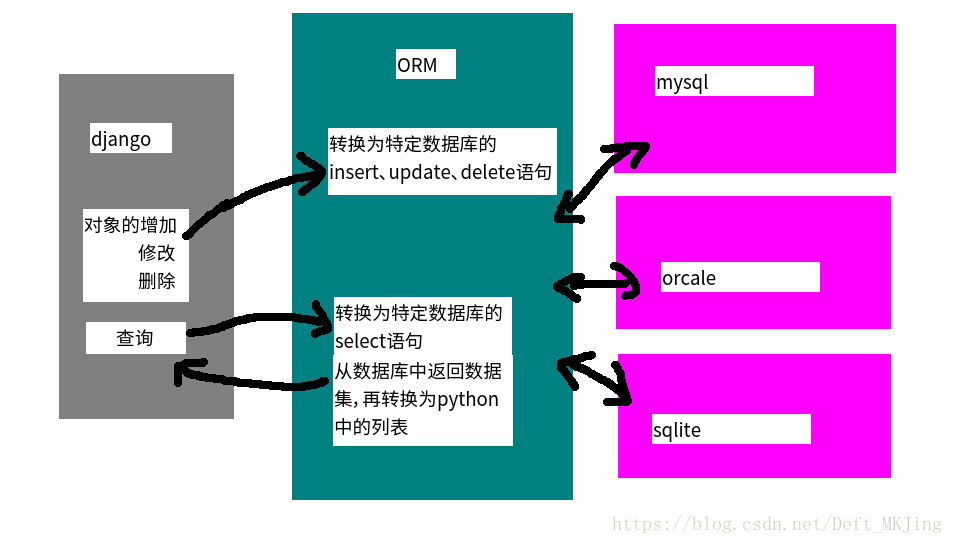
- MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库
- ORM是“对象-关系-映射”的简称,主要任务是:
- 根据对象的类型生成表结构
- 将对象、列表的操作,转换为sql语句
- 将sql查询到的结果转换为对象、列表
- 这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- Django中的模型包含存储数据的字段和约束,对应着数据库中唯一的表
- 在模型中定义属性,会生成表中的字段
- django根据属性的类型确定以下信息:
- 当前选择的数据库支持字段的类型
- 渲染管理表单时使用的默认html控件
- 在管理站点最低限度的验证
- django会为表增加自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后,则django不会再生成默认的主键列
- 属性命名限制
- 不能是python的保留关键字
- 由于django的查询方式,不允许使用连续的下划线
定义属性
- 定义属性时,需要字段类型
- 字段类型被定义在django.db.models.fields目录下,为了方便使用,被导入到django.db.models中
- 使用方式
- 导入from django.db import models
- 通过models.Field创建字段类型的对象,赋值给属性
- 对于重要数据都做逻辑删除,不做物理删除,实现方法是定义isDelete属性,类型为BooleanField,默认值为False
字段类型
- AutoField:一个根据实际ID自动增长的IntegerField,通常不指定
- 如果不指定,一个主键字段将自动添加到模型中
- BooleanField:true/false 字段,此字段的默认表单控制是CheckboxInput
- NullBooleanField:支持null、true、false三种值
- CharField(max_length=字符长度):字符串,默认的表单样式是 TextInput
- TextField:大文本字段,一般超过4000使用,默认的表单控件是Textarea
- IntegerField:整数
- DecimalField(max_digits=None, decimal_places=None):使用python的Decimal实例表示的十进制浮点数
- DecimalField.max_digits:位数总数
- DecimalField.decimal_places:小数点后的数字位数
- FloatField:用Python的float实例来表示的浮点数
- DateField[auto_now=False, auto_now_add=False]):使用Python的datetime.date实例表示的日期
- 参数DateField.auto_now:每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false
- 参数DateField.auto_now_add:当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false
- 该字段默认对应的表单控件是一个TextInput. 在管理员站点添加了一个JavaScript写的日历控件,和一个“Today"的快捷按钮,包含了一个额外的invalid_date错误消息键
- auto_now_add, auto_now, and default 这些设置是相互排斥的,他们之间的任何组合将会发生错误的结果
- TimeField:使用Python的datetime.time实例表示的时间,参数同DateField
- DateTimeField:使用Python的datetime.datetime实例表示的日期和时间,参数同DateField
- FileField:一个上传文件的字段
- ImageField:继承了FileField的所有属性和方法,但对上传的对象进行校验,确保它是个有效的image
字段选项
- 通过字段选项,可以实现对字段的约束
- 在字段对象时通过关键字参数指定
- null:如果为True,Django 将空值以NULL 存储到数据库中,默认值是 False
- blank:如果为True,则该字段允许为空白,默认值是 False
- 对比:null是数据库范畴的概念,blank是表单验证证范畴的
- db_column:字段的名称,如果未指定,则使用属性的名称
- db_index:若值为 True, 则在表中会为此字段创建索引
- default:默认值
- primary_key:若为 True, 则该字段会成为模型的主键字段
- unique:如果为 True, 这个字段在表中必须有唯一值
关系
- 关系的类型包括
- ForeignKey:一对多,将字段定义在多的端中
- ManyToManyField:多对多,将字段定义在两端中
- OneToOneField:一对一,将字段定义在任意一端中
- 可以维护递归的关联关系,使用'self'指定,详见“自关联”
- 用一访问多:对象.模型类小写_set
bookinfo.heroinfo_set
- 用一访问一:对象.模型类小写
heroinfo.bookinfo
- 访问id:对象.属性_id
heroinfo.book_id
元选项
- 在模型类中定义类Meta,用于设置元信息
- 元信息db_table:定义数据表名称,推荐使用小写字母,数据表的默认名称
<app_name>_<model_name>
- ordering:对象的默认排序字段,获取对象的列表时使用,接收属性构成的列表
- class BookInfo(models.Model):
- ...
- class Meta():
- ordering = ['id']
- 字符串前加-表示倒序,不加-表示正序
- class BookInfo(models.Model):
- ...
- class Meta():
- ordering = ['-id']
- 排序会增加数据库的开销
1.创建项目(mysql服务)
cd 到指定目录
django-admin startproject test2打开配置文件默认用sqlite3引擎,name表示工程中sqlite3的路径
- # Database
- # https://docs.djangoproject.com/en/2.1/ref/settings/#databases
-
- DATABASES = {
- 'default': {
- 'ENGINE': 'django.db.backends.sqlite3',
- 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
- }
- }
这里可以看到默认的数据库引擎是sqlite3,我们现在用Mysql,打开backends路径下的查看如下
- /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6
- 这是我Python 3.6的安装路径
-
- 到该路径下有很多python文件,这些都是默认的包,我们安装的第三方包都在site-packages里面
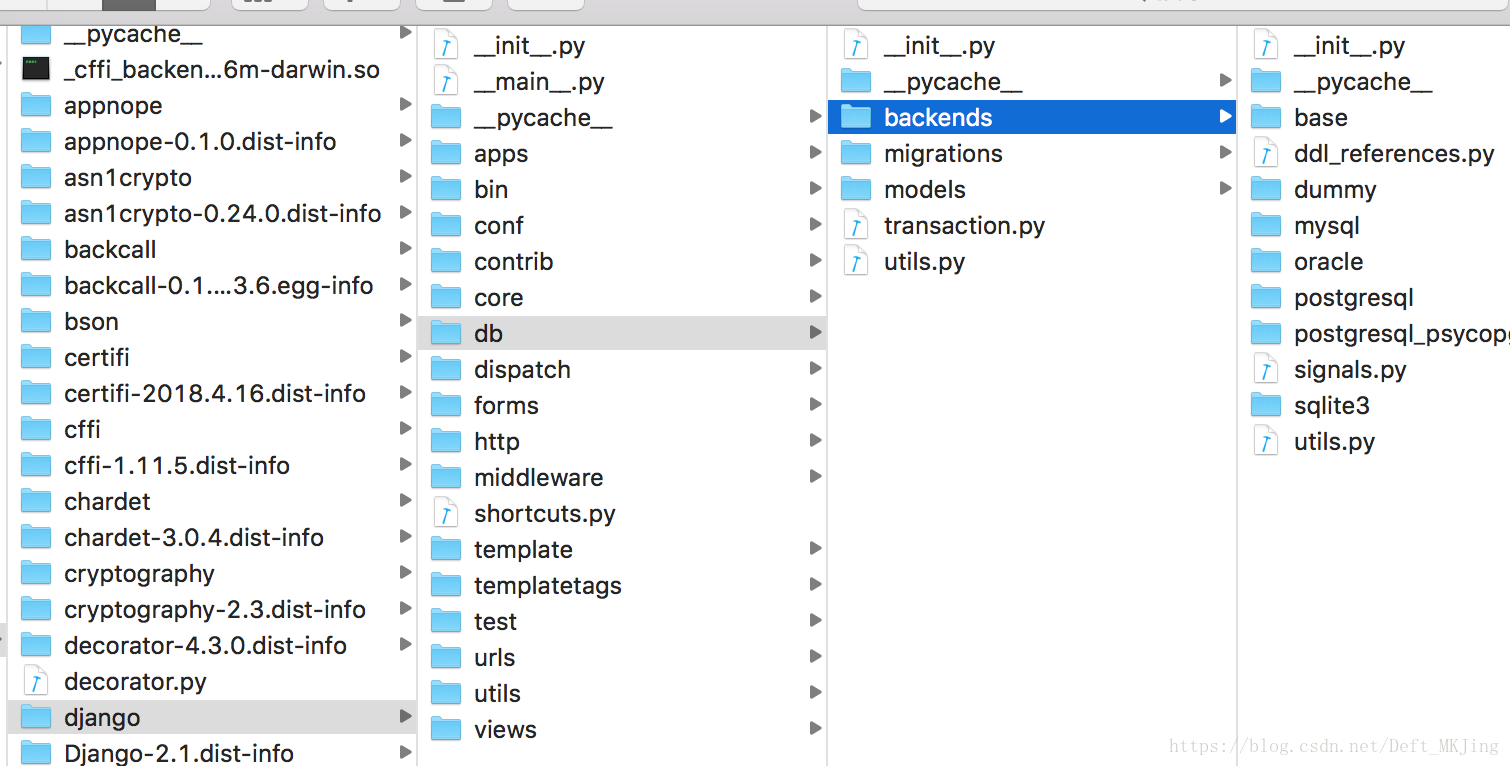
2.修改默认sqlite3为mysql
可以看到,除了sqlite3,还有mysql和oracle等,我们现在用mysql,因此就把上面的配置文件修改成mysql引擎
- # Database
- # https://docs.djangoproject.com/en/2.1/ref/settings/#databases
-
- DATABASES = {
- 'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'NAME': 'test2',
- 'USER': 'root',
- 'PASSWORD': 'mikejing',
- 'HOST': 'localhost',
- 'PORT': '3306'
- }
- }
这里的修改是要到mysql服务器上创建一个名字为test2的database ,mysql没有test2数据库,因此后续需要生成迁移,如果已经有了,就不需要进行迁移,直接跑服务就好
3.修改后在创建的项目中创建App
mintou$ python3 manage.py startapp booktest注意:当你修改成Mysql后之后,由于不在是2.7 python,我们用的是3.6 python针对Mysql的包名都不同,直接执行直接报错
Did you install mysqlclient or MySQL-python?我们在booktest--->test2---->__init__.py根目录下的__init__中添加如下
- import pymysql
- pymysql.install_as_MySQLdb()
4.编写好Model
- from django.db import models
-
- class BookInfo(models.Model):
- btitle = models.CharField(max_length=20)
- bpub_data = models.DateTimeField(db_column= 'book_publish_data')
- bread = models.IntegerField(default=0)
- bcommet = models.IntegerField(default=0)
- isDelete = models.BooleanField(default=False)
- # 用来修改数据库信息 比如表名
- class Meta():
- db_table = 'bookinfo'
-
-
- class HeroInfo(models.Model):
- hname = models.CharField(max_length=20)
- hgender = models.BooleanField(default=True)
- isDelete = models.BooleanField(default=False)
- hcontent = models.CharField(max_length=100)
- # 注意2.1一定要加上on_delete
- hbook = models.ForeignKey('BookInfo',on_delete=models.CASCADE)
把mode加入到setting文件中的INSTALLED_APPS选项中
5.生成迁移
python3 manage.py makemigrations再次执行makemigrations即可
- mintoudeMacBook-Pro-2:test2 mintou$ python3 manage.py makemigrations
- Migrations for 'booktest':
- booktest/migrations/0001_initial.py
- - Create model BookInfo
- - Create model HeroInfo
- mintoudeMacBook-Pro-2:test2 mintou$ python3 manage.py migrate
最后执行migrate执行迁移,把我们做的Model数据类型全部迁移到数据库上生成对应的表信息
6.查看Mysql数据
打开终端,链接数据库
- mysql -uroot -p
-
- 输入密码
-
- mysql> show databases;
- +--------------------+
- | Database |
- +--------------------+
- | information_schema |
- | mysql |
- | performance_schema |
- | sys |
- | test2 |
- +--------------------+
- 5 rows in set (0.00 sec)
-
- mysql> use test2
- Reading table information for completion of table and column names
- You can turn off this feature to get a quicker startup with -A
-
- Database changed
- mysql> show tables;
- +----------------------------+
- | Tables_in_test2 |
- +----------------------------+
- | auth_group |
- | auth_group_permissions |
- | auth_permission |
- | auth_user |
- | auth_user_groups |
- | auth_user_user_permissions |
- | bookinfo |
- | booktest_heroinfo |
- | django_admin_log |
- | django_content_type |
- | django_migrations |
- | django_session |
- +----------------------------+
- 12 rows in set (0.00 sec)
-
- mysql> desc bookinfo
- -> ;
- +-------------------+-------------+------+-----+---------+----------------+
- | Field | Type | Null | Key | Default | Extra |
- +-------------------+-------------+------+-----+---------+----------------+
- | id | int(11) | NO | PRI | NULL | auto_increment |
- | btitle | varchar(20) | NO | | NULL | |
- | book_publish_data | datetime(6) | NO | | NULL | |
- | bread | int(11) | NO | | NULL | |
- | bcommet | int(11) | NO | | NULL | |
- | isDelete | tinyint(1) | NO | | NULL | |
- +-------------------+-------------+------+-----+---------+----------------+
- 6 rows in set (0.00 sec)
-
- mysql> desc booktest_heroinfo;
- +----------+--------------+------+-----+---------+----------------+
- | Field | Type | Null | Key | Default | Extra |
- +----------+--------------+------+-----+---------+----------------+
- | id | int(11) | NO | PRI | NULL | auto_increment |
- | hname | varchar(20) | NO | | NULL | |
- | hgender | tinyint(1) | NO | | NULL | |
- | isDelete | tinyint(1) | NO | | NULL | |
- | hcontent | varchar(100) | NO | | NULL | |
- | hbook_id | int(11) | NO | MUL | NULL | |
- +----------+--------------+------+-----+---------+----------------+
- 6 rows in set (0.00 sec)
可以看到我们刚才的model信息变成了mysql表,Django帮我们生成了很多其他的标,主要看
booktest_heroinfo 和 bookinfo 前者是默认表名,后者是通过Meta元类修改自定义的表名
7.类的属性objects
- objects:是Manager类型的对象,用于与数据库进行交互
- 当定义模型类时没有指定管理器,则Django会为模型类提供一个名为objects的管理器
- 支持明确指定模型类的管理器
- class BookInfo(models.Model):
- ...
- books = models.Manager()
- 当为模型类指定管理器后,django不再为模型类生成名为objects的默认管理器
管理器Manager
- 管理器是Django的模型进行数据库的查询操作的接口,Django应用的每个模型都拥有至少一个管理器
- 自定义管理器类主要用于两种情况
- 情况一:向管理器类中添加额外的方法:见下面“创建对象”中的方式二
- 情况二:修改管理器返回的原始查询集:重写get_queryset()方法
- class BookInfoManager(models.Manager):
- def get_queryset(self):
- return super(BookInfoManager, self).get_queryset().filter(isDelete=False)
- class BookInfo(models.Model):
- ...
- books = BookInfoManager()
该类继承了models.Manager,重写的get_queryset的方法,当我们重新进入
- In [3]: BookInfo.objects.all()
- Out[3]: <QuerySet [<BookInfo: BookInfo object (1)>, <BookInfo: BookInfo object (2)>, <BookInfo: BookInfo object (3)>, <BookInfo: BookInfo object (4)>]>
-
- In [4]: exit
-
- 上半段,默认查出所有,没有重写之前
-
- 下半段是重写之后filter了,查出来只有三个了,而且不再是默认的objects,而是我们自己定义的类名books
-
-
- mintoudeMacBook-Pro-2:test2 mintou$ python3 manage.py shell
- Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08)
- Type 'copyright', 'credits' or 'license' for more information
- IPython 6.3.1 -- An enhanced Interactive Python. Type '?' for help.
-
- In [1]: from booktest.models import BookInfo, HeroInfo
-
- In [2]: BookInfo.objects.all()
- ---------------------------------------------------------------------------
- AttributeError Traceback (most recent call last)
- <ipython-input-2-182abd3174ec> in <module>()
- ----> 1 BookInfo.objects.all()
-
- AttributeError: type object 'BookInfo' has no attribute 'objects'
-
- In [3]: BookInfo.books.all()
- Out[3]: <QuerySet [<BookInfo: BookInfo object (1)>, <BookInfo: BookInfo object (2)>, <BookInfo: BookInfo object (3)>]>
8.创建对象
- 当创建对象时,django不会对数据库进行读写操作
- 调用save()方法才与数据库交互,将对象保存到数据库中
- 使用关键字参数构造模型对象很麻烦,推荐使用下面的两种之式
- 说明: _init _方法已经在基类models.Model中使用,在自定义模型中无法使用,
- 方式一:在模型类中增加一个类方法
- class BookInfo(models.Model):
- ...
- @classmethod
- def create(cls, title, pub_date):
- book = cls(btitle=title, bpub_date=pub_date)
- book.bread=0
- book.bcommet=0
- book.isDelete = False
- return book
- 引入时间包:from datetime import *
- 调用:book=BookInfo.create("hello",datetime(1980,10,11));
- 保存:book.save()
- 方式二:在自定义管理器中添加一个方法
- 在管理器的方法中,可以通过self.model来得到它所属的模型类
- class BookInfoManager(models.Manager):
- def create_book(self, title, pub_date):
- book = self.model()
- book.btitle = title
- book.bpub_date = pub_date
- book.bread=0
- book.bcommet=0
- book.isDelete = False
- return book
-
- class BookInfo(models.Model):
- ...
- books = BookInfoManager()
- 调用:book=BookInfo.books.create_book("abc",datetime(1980,1,1))
- 保存:book.save()
- 在方式二中,可以调用self.create()创建并保存对象,不需要再手动save()
- class BookInfoManager(models.Manager):
- def create_book(self, title, pub_date):
- book = self.create(btitle = title,bpub_date = pub_date,bread=0,bcommet=0,isDelete = False)
- return book
-
- class BookInfo(models.Model):
- ...
- books = BookInfoManager()
- 调用:book=Book.books.create_book("abc",datetime(1980,1,1))
- 查看:book.pk
实例的属性
- DoesNotExist:在进行单个查询时,模型的对象不存在时会引发此异常,结合try/except使用
实例的方法
- str (self):重写object方法,此方法在将对象转换成字符串时会被调用
- save():将模型对象保存到数据表中
- delete():将模型对象从数据表中删除
查询集
- 在管理器上调用过滤器方法会返回查询集
- 查询集经过过滤器筛选后返回新的查询集,因此可以写成链式过滤
- 惰性执行:创建查询集不会带来任何数据库的访问,直到调用数据时,才会访问数据库
- 何时对查询集求值:迭代,序列化,与if合用
- 返回查询集的方法,称为过滤器
- all()
- filter()
- exclude()
- order_by()
- values():一个对象构成一个字典,然后构成一个列表返回
- 写法:
- filter(键1=值1,键2=值2)
- 等价于
- filter(键1=值1).filter(键2=值2)
- 返回单个值的方法
- get():返回单个满足条件的对象
- 如果未找到会引发"模型类.DoesNotExist"异常
- 如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常
- count():返回当前查询的总条数
- first():返回第一个对象
- last():返回最后一个对象
- exists():判断查询集中是否有数据,如果有则返回True
- get():返回单个满足条件的对象
限制查询集
- 查询集返回列表,可以使用下标的方式进行限制,等同于sql中的limit和offset子句
- 注意:不支持负数索引
- 使用下标后返回一个新的查询集,不会立即执行查询
- 如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()引发DoesNotExist异常
查询集的缓存
- 每个查询集都包含一个缓存来最小化对数据库的访问
- 在新建的查询集中,缓存为空,首次对查询集求值时,会发生数据库查询,django会将查询的结果存在查询集的缓存中,并返回请求的结果,接下来对查询集求值将重用缓存的结果
- 情况一:这构成了两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载
- print([e.title for e in Entry.objects.all()])
- print([e.title for e in Entry.objects.all()])
- 情况二:两次循环使用同一个查询集,第二次使用缓存中的数据
- querylist=Entry.objects.all()
- print([e.title for e in querylist])
- print([e.title for e in querylist])
- 何时查询集不会被缓存:当只对查询集的部分进行求值时会检查缓存,但是如果这部分不在缓存中,那么接下来查询返回的记录将不会被缓存,这意味着使用索引来限制查询集将不会填充缓存,如果这部分数据已经被缓存,则直接使用缓存中的数据
字段查询
- 实现where子名,作为方法filter()、exclude()、get()的参数
- 语法:属性名称__比较运算符=值
- 表示两个下划线,左侧是属性名称,右侧是比较类型
- 对于外键,使用“属性名_id”表示外键的原始值
- 转义:like语句中使用了%与,匹配数据中的%与,在过滤器中直接写,例如:filter(title__contains="%")=>where title like '%\%%',表示查找标题中包含%的
比较运算符
- exact:表示判等,大小写敏感;如果没有写“ 比较运算符”,表示判等
filter(isDelete=False)
- contains:是否包含,大小写敏感
exclude(btitle__contains='传')
- startswith、endswith:以value开头或结尾,大小写敏感
exclude(btitle__endswith='传')
- isnull、isnotnull:是否为null 这个字段很有用,可以查询类下面所有子类,而不需要对象去查询
- In [13]: BookInfo.books.filter(heroinfo__isnull=False)
- Out[13]: <QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 笑傲江湖>, <BookInfo: 笑傲江湖>, <BookInfo: 笑傲江湖>]>
这里我们第四种书雪山飞狐由于isDelete字段是True,所以没出来,一般我们要查询一个book下面的所有hero,需要拿到book对象,也可以通过这方法来查询所有书的hero
filter(btitle__isnull=False)
- 在前面加个i表示不区分大小写,如iexact、icontains、istarswith、iendswith
- in:是否包含在范围内
filter(pk__in=[1, 2, 3, 4, 5])
- gt、gte、lt、lte:大于、大于等于、小于、小于等于
filter(id__gt=3)
- year、month、day、week_day、hour、minute、second:对日期间类型的属性进行运算
- filter(bpub_date__year=1980)
- filter(bpub_date__gt=date(1980, 12, 31))
- 跨关联关系的查询:处理join查询
- 语法:模型类名 <属性名> <比较>
- 注:可以没有__<比较>部分,表示等于,结果同inner join
- 可返向使用,即在关联的两个模型中都可以使用
filter(heroinfo_ _hcontent_ _contains='八')
- 查询的快捷方式:pk,pk表示primary key,默认的主键是id
filter(pk__lt=6)
聚合函数
- 使用aggregate()函数返回聚合函数的值
- 函数:Avg,Count,Max,Min,Sum
- from django.db.models import Max
- maxDate = list.aggregate(Max('bpub_date'))
- count的一般用法:
count = list.count()
F对象
-
可以使用模型的字段A与字段B进行比较,如果A写在了等号的左边,则B出现在等号的右边,需要通过F对象构造
list.filter(bread__gte=F('bcommet'))
- django支持对F()对象使用算数运算
list.filter(bread__gte=F('bcommet') * 2)
- F()对象中还可以写作“模型类__列名”进行关联查询
list.filter(isDelete=F('heroinfo__isDelete'))
- 对于date/time字段,可与timedelta()进行运算
list.filter(bpub_date__lt=F('bpub_date') + timedelta(days=1))
Q对象
- 过滤器的方法中关键字参数查询,会合并为And进行
- 需要进行or查询,使用Q()对象
- Q对象(django.db.models.Q)用于封装一组关键字参数,这些关键字参数与“比较运算符”中的相同
- from django.db.models import Q
- list.filter(Q(pk_ _lt=6))
- Q对象可以使用&(and)、|(or)操作符组合起来
- 当操作符应用在两个Q对象时,会产生一个新的Q对象
- list.filter(pk_ _lt=6).filter(bcommet_ _gt=10)
- list.filter(Q(pk_ _lt=6) | Q(bcommet_ _gt=10))
- 使用~(not)操作符在Q对象前表示取反
list.filter(~Q(pk__lt=6))
- 可以使用&|~结合括号进行分组,构造做生意复杂的Q对象
- 过滤器函数可以传递一个或多个Q对象作为位置参数,如果有多个Q对象,这些参数的逻辑为and
- 过滤器函数可以混合使用Q对象和关键字参数,所有参数都将and在一起,Q对象必须位于关键字参数的前面
视图详细介绍
- 视图接受Web请求并且返回Web响应
- 视图就是一个python函数,被定义在views.py中
- 响应可以是一张网页的HTML内容,一个重定向,一个404错误等等
- 响应处理过程如下图:
浏览器输入host+port+path---->DJango获取到地址除去host+port解析path---->匹配urls------>传递给views接收request返回response
urlconf
- 在settings.py文件中通过ROOT_URLCONF指定根级url的配置
- urlpatterns是一个url()实例的列表
- 一个url()对象包括:
- 正则表达式
- 视图函数
- 名称name
- 编写URLconf的注意:
- 若要从url中捕获一个值,需要在它周围设置一对圆括号
- 不需要添加一个前导的反斜杠,如应该写作'test/',而不应该写作'/test/'
- 每个正则表达式前面的r表示字符串不转义
- 请求的url被看做是一个普通的python字符串,进行匹配时不包括get或post请求的参数及域名
http://www.google.com/python/1/?i=1&p=new,只匹配“/python/1/”部分- 正则表达式非命名组,通过位置参数传递给视图
re_path(r'^([0-9]+)/$', views.detail, name='detail'),
- 正则表达式命名组,通过关键字参数传递给视图,本例中关键字参数为id
re_path(r'^(?P<id>[0-9]+)/$', views.detail, name='detail'),- 参数匹配规则:优先使用命名参数,如果没有命名参数则使用位置参数
- 每个捕获的参数都作为一个普通的python字符串传递给视图
- 性能:urlpatterns中的每个正则表达式在第一次访问它们时被编译,这使得系统相当快
解析流程
新建的项目会有一个和项目同名的文件夹,下面有对应的urls文件,如下
- 根的urls
- """
- from django.contrib import admin
- from django.urls import path, re_path, include
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^booktest/', include('booktest.urls'))
- ]
- app urls
- from django.urls import path, re_path
- from . import views
- urlpatterns = [
- re_path(r'^$', views.index, name='index'),
- re_path(r'^book/([0-9]+)$', views.detail, name='detail'),
- ]
- 匹配过程:先与主URLconf匹配,成功后再用剩余的部分与应用中的URLconf匹配
- 请求http://www.google.com/booktest/1/
- 在sesstings.py中的配置:
- re_path(r'^booktest/', include('booktest.urls', namespace='booktest')),
- 在booktest应用urls.py中的配置
- re_path(r'^([0-9]+)/$', views.detail, name='detail'),
- 匹配部分是:/booktest/1/
- 匹配过程:在settings.py中与“booktest/”成功,再用“1/”与booktest应用的urls匹配
- 使用include可以去除urlconf的冗余
- 参数:视图会收到来自父URLconf、当前URLconf捕获的所有参数
- 在include中通过namespace定义命名空间,用于反解析 后面response部分会有讲到
- 注意使用namespace的操作,重定向需要指定
- 根部
- from django.contrib import admin
- from django.urls import path, re_path, include
-
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^booktest/', include('booktest.urls', namespace='booktest'))
- ]
-
-
- app
- from django.urls import path, re_path
- from . import views
-
- app_name = 'booktest'
-
- urlpatterns = [
-
- ]
-
- 这里和上面的配置区别就是需要加上namespace参数,然后在appurls加入app_name参数
错误页面
404 (page not found) 视图
- defaults.page_not_found(request, template_name='404.html')
- 默认的404视图将传递一个变量给模板:request_path,它是导致错误的URL
- 如果Django在检测URLconf中的每个正则表达式后没有找到匹配的内容也将调用404视图
- 如果在settings中DEBUG设置为True,那么将永远不会调用404视图,而是显示URLconf 并带有一些调试信息
- 在templates中创建404.html
- <!DOCTYPE html>
- <html>
- <head>
- <title></title>
- </head>
- <body>
- 找不到了
- <hr/>
- {{request_path}}
- </body>
- </html>
- 在settings.py中修改调试
- DEBUG = False
- ALLOWED_HOSTS = ['*', ]
- 请求一个不存在的地址
http://127.0.0.1:8000/test/
500 (server error) 视图
- defaults.server_error(request, template_name='500.html')
- 在视图代码中出现运行时错误
- 默认的500视图不会传递变量给500.html模板
- 如果在settings中DEBUG设置为True,那么将永远不会调用505视图,而是显示URLconf 并带有一些调试信息
400 (bad request) 视图
- defaults.bad_request(request, template_name='400.html')
- 错误来自客户端的操作
- 当用户进行的操作在安全方面可疑的时候,例如篡改会话cookie
Request对象
- 服务器接收到http协议的请求后,会根据报文创建HttpRequest对象
- 视图函数的第一个参数是HttpRequest对象
- 在django.http模块中定义了HttpRequest对象的API
属性
- 下面除非特别说明,属性都是只读的
- path:一个字符串,表示请求的页面的完整路径,不包含域名
- method:一个字符串,表示请求使用的HTTP方法,常用值包括:'GET'、'POST'
- encoding:一个字符串,表示提交的数据的编码方式
- 如果为None则表示使用浏览器的默认设置,一般为utf-8
- 这个属性是可写的,可以通过修改它来修改访问表单数据使用的编码,接下来对属性的任何访问将使用新的encoding值
- GET:一个类似于字典的对象,包含get请求方式的所有参数
- POST:一个类似于字典的对象,包含post请求方式的所有参数
- FILES:一个类似于字典的对象,包含所有的上传文件
- COOKIES:一个标准的Python字典,包含所有的cookie,键和值都为字符串
- session:一个既可读又可写的类似于字典的对象,表示当前的会话,只有当Django 启用会话的支持时才可用,详细内容见“状态保持”
方法
- is_ajax():如果请求是通过XMLHttpRequest发起的,则返回True
QueryDict对象
- 定义在django.http.QueryDict
- request对象的属性GET、POST都是QueryDict类型的对象
- 与python字典不同,QueryDict类型的对象用来处理同一个键带有多个值的情况
- 方法get():根据键获取值
- 只能获取键的一个值
- 如果一个键同时拥有多个值,获取最后一个值
- dict.get('键',default)
- 或简写为
- dict['键']
- 方法getlist():根据键获取值
- 将键的值以列表返回,可以获取一个键的多个值
dict.getlist('键',default)GET
- QueryDict类型的对象
- 包含get请求方式的所有参数
- 与url请求地址中的参数对应,位于?后面
- 参数的格式是键值对,如key1=value1
- 多个参数之间,使用&连接,如key1=value1&key2=value2
- 键是开发人员定下来的,值是可变的
- 示例如下
- 创建视图getTest1用于定义链接,getTest2用于接收一键一值,getTest3用于接收一键多值
- def getTest1(request):
- return render(request,'booktest/getTest1.html')
- def getTest2(request):
- return render(request,'booktest/getTest2.html')
- def getTest3(request):
- return render(request,'booktest/getTest3.html')
- 配置url
- url(r'^getTest1/$', views.getTest1),
- url(r'^getTest2/$', views.getTest2),
- url(r'^getTest3/$', views.getTest3),
- 创建getTest1.html,定义链接
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- 链接1:一个键传递一个值
- <a href="/getTest2/?a=1&b=2">gettest2</a><br>
- 链接2:一个键传递多个值
- <a href="/getTest3/?a=1&a=2&b=3">gettest3</a>
- </body>
- </html>
- 完善视图getTest2的代码
- def getTest2(request):
- a=request.GET['a']
- b=request.GET['b']
- context={'a':a,'b':b}
- return render(request,'booktest/getTest2.html',context)
- 创建getTest2.html,显示接收结果
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- a:{{ a }}<br>
- b:{{ b }}
- </body>
- </html>
- 完善视图getTest3的代码
- def getTest3(request):
- a=request.GET.getlist('a')
- b=request.GET['b']
- context={'a':a,'b':b}
- return render(request,'booktest/getTest3.html',context)
- 创建getTest3.html,显示接收结果
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- a:{% for item in a %}
- {{ item }}
- {% endfor %}
- <br>
- b:{{ b }}
- </body>
- </html>
POST
- QueryDict类型的对象
- 包含post请求方式的所有参数
- 与form表单中的控件对应
- 问:表单中哪些控件会被提交?
- 答:控件要有name属性,则name属性的值为键,value属性的值为键,构成键值对提交
- 对于checkbox控件,name属性一样为一组,当控件被选中后会被提交,存在一键多值的情况
- 键是开发人员定下来的,值是可变的
- 示例如下
- 定义视图postTest1
- def postTest1(request):
- return render(request,'booktest/postTest1.html')
- 配置url
url(r'^postTest1$',views.postTest1)
- 创建模板postTest1.html
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- <form method="post" action="/postTest2/">
- 姓名:<input type="text" name="uname"/><br>
- 密码:<input type="password" name="upwd"/><br>
- 性别:<input type="radio" name="ugender" value="1"/>男
- <input type="radio" name="ugender" value="0"/>女<br>
- 爱好:<input type="checkbox" name="uhobby" value="胸口碎大石"/>胸口碎大石
- <input type="checkbox" name="uhobby" value="跳楼"/>跳楼
- <input type="checkbox" name="uhobby" value="喝酒"/>喝酒
- <input type="checkbox" name="uhobby" value="爬山"/>爬山<br>
- <input type="submit" value="提交"/>
- </form>
- </body>
- </html>
- 创建视图postTest2接收请求的数据
- def postTest2(request):
- uname=request.POST['uname']
- upwd=request.POST['upwd']
- ugender=request.POST['ugender']
- uhobby=request.POST.getlist('uhobby')
- context={'uname':uname,'upwd':upwd,'ugender':ugender,'uhobby':uhobby}
- return render(request,'booktest/postTest2.html',context)
- 配置url
url(r'^postTest2$',views.postTest2)
- 创建模板postTest2.html
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- {{ uname }}<br>
- {{ upwd }}<br>
- {{ ugender }}<br>
- {{ uhobby }}
- </body>
- </html>
- 注意:使用表单提交,注释掉settings.py中的中间件crsf
Reponse对象
- 在django.http模块中定义了HttpResponse对象的API
- HttpRequest对象由Django自动创建,HttpResponse对象由程序员创建
- 不调用模板,直接返回数据
- #coding=utf-8
- from django.http import HttpResponse
-
- def index(request):
- return HttpResponse('你好')
- 调用模板
- from django.http import HttpResponse
- from django.template import RequestContext, loader
-
- def index(request):
- t1 = loader.get_template('polls/index.html')
- context = RequestContext(request, {'h1': 'hello'})
- return HttpResponse(t1.render(context))
属性
- content:表示返回的内容,字符串类型
- charset:表示response采用的编码字符集,字符串类型
- status_code:响应的HTTP响应状态码
- content-type:指定输出的MIME类型
cookies知识点详解
- init :使用页内容实例化HttpResponse对象
- write(content):以文件的方式写
- flush():以文件的方式输出缓存区
- set_cookie(key, value='', max_age=None, expires=None):设置Cookie
- key、value都是字符串类型
- max_age是一个整数,表示在指定秒数后过期
- expires是一个datetime或timedelta对象,会话将在这个指定的日期/时间过期,注意datetime和timedelta值只有在使用PickleSerializer时才可序列化
- max_age与expires二选一
- 如果不指定过期时间,则两个星期后过期
- def getCookies(request):
- # 后面再来的时候都会携带
- response = HttpResponse()
- if 'name' in request.COOKIES:
- response.write(request.COOKIES['name'])
- # 第一次的时候选择注入cookies
- # response.set_cookie('name', 'mikjeing')
- return response
- delete_cookie(key):删除指定的key的Cookie,如果key不存在则什么也不发生
分析:
http是无状态的,我们需要记录用户的信息,多次访问需要携带上一次的用户信息,有服务器发送cookies从resonse中给客户端保存在本地,但是服务器不存储这些信息,在有效时间内,同一域名下浏览器会默认带上cookies给服务器
简单的例子,当我们访问本地服务例如 127.0.0.7:8000/booktest/getCookies的时候是第一次,requestheader里面是找不到本地存储的cookies,因此不会有携带,但是服务器写了set_cookies,就会有respon里面带有cookies返回给客户端存储,刷新页面再次请求的时候,客户端带上cookies给服务端,就会在请求头带过去给服务器
上面的是最简单的设置例子,看下正常注册成功的时候把cookies的值回写
http://blog.51cto.com/suhaozhi/2063468
- def login(request):
-
- c_user = request.COOKIES.get('username')
-
- if not c_user:
-
- return redirect('/login/')
-
- #如果没有从浏览器响应头中得到username对应的value,那么直接跳转回登录页面。
-
- 2.cookie回写。
-
- if request.method == "GET":
-
- return render(request,'login.html')
-
- else:
-
- user = request.POST.get('username')
-
- pwd = request.POST.get('password')
-
- if user == 'admin' and pwd =='admin':
-
- obj = redirect('/admin/')
-
- obj.set_cookie('username','xxxx') ###为浏览器回写cookie!!key为username 对应的value为 xxx。
-
- return obj
-
- else:
-
- return render(request,'login.html')
- [28/Aug/2018 09:00:13] "GET /user/login/ HTTP/1.1" 200 6
- {'csrftoken': 'fy3O8YWLMnlQwi7GfOR55aFvyhKJvzOBviQD4Phe3eMitk4Dd6OP5OYpUKIMPDM7', 'username': 'tiantian'}
- [28/Aug/2018 09:00:22] "GET /user/login/ HTTP/1.1" 200 6
- [28/Aug/2018 09:00:25] "GET /user/register/ HTTP/1.1" 200 3262
- [28/Aug/2018 09:00:36] "GET /user/register/ HTTP/1.1" 200 3262
- [28/Aug/2018 09:00:49] "GET /user/register_exit/?uname=wuliao HTTP/1.1" 200 12
- [28/Aug/2018 09:00:56] "GET /user/register_exit/?uname=wuliao HTTP/1.1" 200 12
- [28/Aug/2018 09:00:56] "POST /user/register_handle/ HTTP/1.1" 302 0
- {'csrftoken': 'fy3O8YWLMnlQwi7GfOR55aFvyhKJvzOBviQD4Phe3eMitk4Dd6OP5OYpUKIMPDM7', 'username': 'wuliao'}
-
- 例如这两次注册的username的更改
1、设置cookie声明周期。
如果想在回写cookie时,可以给cookie加一个超时时间,就可以使用max_age参数。
例如:
obj.set_cookie('username','xxxx',max_age=10) ###为浏览器回写cookie!!key为username 对应的value为xxx,并且cookie的声明周期为10秒,10秒后自动消失。
2、设置cookie作用域。
如果需要设置cookie的作用域,可以通过response的set_cookie中的path参数去进行设置。
path='/' #代表对整个站点生效。
path='/p1' #代表对www.xxxx.com/p1/*站点生效。
还可以通过domain参数来设置,这个cookie对哪个域名生效。
默认为当前域名。
3、安全相关参数。
secure= False #默认值为False ,也就是关闭状态,当使用https时,需要开启。
httponly = False #默认值为False ,默认也是关闭状态,如果开启了httponly,那么这个cookie只能在http请求传输的时候可以被读取,
js是无法读取这个cookie的。
4、cookie的简单签名。
通过response回写cookie时。
obj.set_signed_cookie('kkk','vvv',salt='123456') #通过加盐的方式为cookie签名。
request.get_signed_cookie('kkk',salt='123456') #获取经过签名后的cookie值。
子类HttpResponseRedirect(注意namespace的配置)
- 重定向,服务器端跳转
- 构造函数的第一个参数用来指定重定向的地址
- def redTest1(request):
- return HttpResponseRedirect('/booktest/redTest2')
-
- def redTest2(request):
- return HttpResponse('我是转向后的页面资源')
-
-
- app
-
- from django.urls import path, re_path
- from . import views
-
- app_name = 'booktest'
-
- urlpatterns = [
-
- re_path(r'^redTest1$', views.redTest1, name='redTest1'),
- re_path(r'^redTest2$', views.redTest2, name='redTest2'),
- ]
-
- 根
- from django.contrib import admin
- from django.urls import path, re_path, include
-
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^booktest/', include('booktest.urls', namespace='booktest'))
- ]
当我们输入以下的时候,会重定向
- http://127.0.0.1:8000/booktest/redTest1
-
-
- 重定向
-
- http://127.0.0.1:8000/booktest/redTest2
重定向推荐使用反向解析(需要namespace配置)
- from django.urls import reverse
-
- def redTest1(request):
- # return HttpResponseRedirect('/booktest/redTest2')
-
- # 重定向的两个方法
- # return HttpResponseRedirect(reverse('booktest:redTest2'))
- return redirect(reverse('booktest:redTest2'))
-
- def redTest2(request):
- return HttpResponse('我是转向后的页面资源')
子类JsonResponse
- 返回json数据,一般用于异步请求
- _init _(data)
- 帮助用户创建JSON编码的响应
- 参数data是字典对象
- JsonResponse的默认Content-Type为application/json
- from django.http import JsonResponse
-
- def index2(requeset):
- return JsonResponse({'list': 'abc'})
简写函数render
render
- render(request, template_name[, context])
- 结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的HttpResponse对象
- request:该request用于生成response
- template_name:要使用的模板的完整名称
- context:添加到模板上下文的一个字典,视图将在渲染模板之前调用它
- from django.shortcuts import render
-
- def index(request):
- return render(request, 'booktest/index.html', {'h1': 'hello'})
重定向(这里可以写全路径)
- redirect(to)
- 为传递进来的参数返回HttpResponseRedirect
- to推荐使用反向解析
- from django.shortcuts import redirect
- from django.urls import reverse
-
- def index(request):
- return redirect(reverse('booktest:index2'))
-
-
- def redTest1(request):
- return redirect(reverse('booktest:redTest2'))
[21/Aug/2018 03:39:37] "GET /booktest/redTest1 HTTP/1.1" 302 0
[21/Aug/2018 03:39:37] "GET /booktest/redTest2 HTTP/1.1" 200 30
注:
任何简写的地方都可以写全路径例如 /booktest/redTest2
但是如果用reverse反向解析,需要用到命名空间namespace 两个都可以选择,后者更容易维护,不需要要在更改URL的情况下更改很多地方,直接自动反向解析url
经常看到网站有淘宝的商品cookies如何解释?
正常情况cookies是域名安全的,一开始我们用浏览器访问淘宝,打开很多商品,会被服务端包装到cookies传给客户端保存起来,那么如果继续访问淘宝,cookie会回传回去,就能知道对应的浏览记录然后进行分析和推荐,那为什么比如你访问博客网站的时候会有淘宝的广告,那其实是一个iframe,然后iframe里面嵌入了淘宝的域名下的链接,然后cookies就传过去了,拿出cookies信息解析展示推荐商品即可
Session
- http协议是无状态的:每次请求都是一次新的请求,不会记得之前通信的状态
- 客户端与服务器端的一次通信,就是一次会话
- 实现状态保持的方式:在客户端或服务器端存储与会话有关的数据
- 存储方式包括cookie、session,会话一般指session对象
- 使用cookie,所有数据存储在客户端,注意不要存储敏感信息
- 推荐使用sesison方式,所有数据存储在服务器端,在客户端cookie中存储session_id
- 状态保持的目的是在一段时间内跟踪请求者的状态,可以实现跨页面访问当前请求者的数据
- 注意:不同的请求者之间不会共享这个数据,与请求者一一对应
启用session
- 使用django-admin startproject创建的项目默认启用
- 在settings.py文件中
- 项INSTALLED_APPS列表中添加:
- 'django.contrib.sessions',
-
- 项MIDDLEWARE_CLASSES列表中添加:
- 'django.contrib.sessions.middleware.SessionMiddleware',
- 禁用会话:删除上面指定的两个值,禁用会话将节省一些性能消耗
使用session
- 启用会话后,每个HttpRequest对象将具有一个session属性,它是一个类字典对象
- get(key, default=None):根据键获取会话的值
- clear():清除所有会话
- flush():删除当前的会话数据并删除会话的Cookie
- del request.session['member_id']:删除会话
- urls.py
- re_path(r'^mainTest$', views.mainTest, name='mainTest'),
- re_path(r'^loginTest$', views.loginTest, name='login'),
- re_path(r'^login_handle/$', views.login_handle, name='login_handle'),
- re_path(r'^logoutTest/$', views.logoutTest, name='logoutTest'),
-
-
- views.py
-
- def mainTest(request):
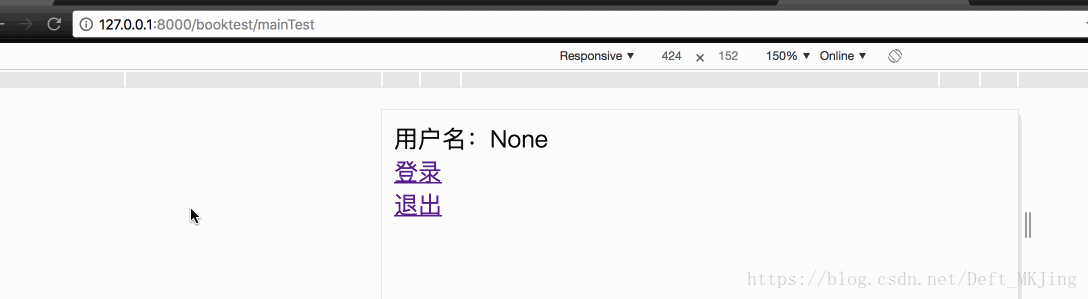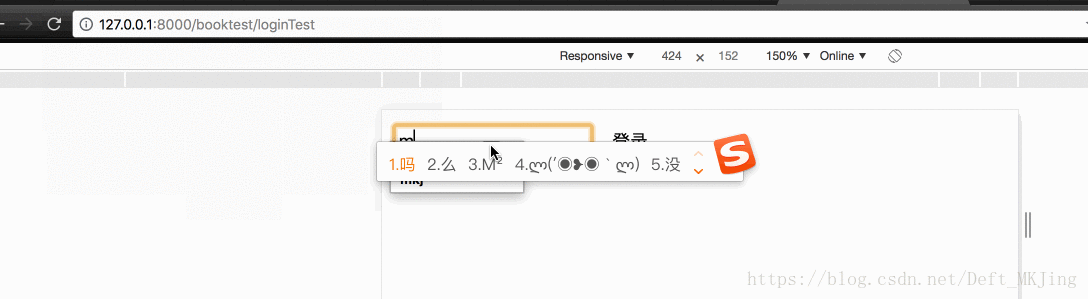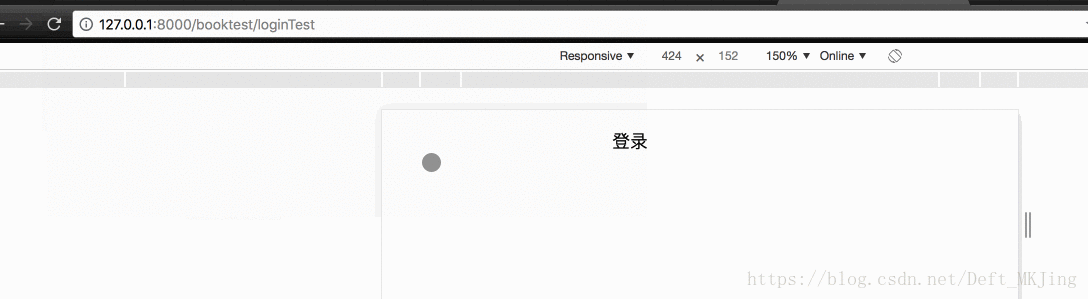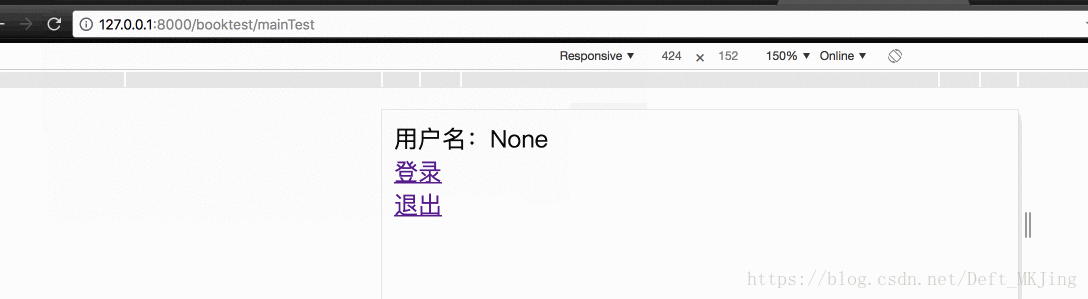
- username = request.session.get('name')
- return render(request, 'booktest/mainTest.html', {'uname':username})
-
-
- def loginTest(request):
- return render(request, 'booktest/loginTest.html')
-
-
- def login_handle(request):
- request.session['name'] = request.POST['username']
- request.session.set_expiry(0)
-
- return redirect(reverse('booktest:mainTest'))
-
-
- def logoutTest(request):
- request.session.flush()
- return redirect(reverse('booktest:mainTest'))
-
-
-
-
- 会话过期时间
- set_expiry(value):设置会话的超时时间
- 如果没有指定,则两个星期后过期
- 如果value是一个整数,会话将在values秒没有活动后过期
- 若果value是一个imedelta对象,会话将在当前时间加上这个指定的日期/时间过期
- 如果value为0,那么用户会话的Cookie将在用户的浏览器关闭时过期
- 如果value为None,那么会话永不过期
- 修改视图中login_handle函数,查看效果
首先来撸一下逻辑
1.当我们一个页面请求的时候,服务端会通过request对象获取对应的session,如果没有,就会创建一个session,有的话就读,这就很好解释为什么通过request来获取,因为有可能带过来了,就不需要创建了,内部逻辑会判断
2.登录成功的时候一样直接获取session,这个就是OC里面的懒加载,每次都直接读,没有创建新的,这里的内部逻辑DJango做了,获取到之后赋值,然后返回登录页面,这个时候已经能从session获取到信息,就渲染登录之后的信息
3.第一次创建session后,服务器通过cookies返回给客户端,然后客户端再次访问的时候会携带cookie,服务端就能从cookies拿到对应的sessionid,进行资源查找
4.服务器退出登录的时候例如执行flush,会清楚session,在返回的cookies里面不返回sessionid,下次访问就需要重新创建分配了
退出登录的时候报文截图

session在DJango默认存储在配置的数据库中,我们配置的Mysql,看下具体表中的存储
- mysql> show tables;
- +----------------------------+
- | Tables_in_test3 |
- +----------------------------+
- | auth_group |
- | auth_group_permissions |
- | auth_permission |
- | auth_user |
- | auth_user_groups |
- | auth_user_user_permissions |
- | bookinfo |
- | booktest_heroinfo |
- | django_admin_log |
- | django_content_type |
- | django_migrations |
- | django_session |
- +----------------------------+
- 12 rows in set (0.00 sec)
-
- mysql> select *from django_session;
- +----------------------------------+------------------------------------------------------------------------------------------------------+----------------------------+
- | session_key | session_data | expire_date |
- +----------------------------------+------------------------------------------------------------------------------------------------------+----------------------------+
- | 1tj570h8vwlm7yynu0z0hwe2kz0r9pil | Y2ZmMzJlNzUzYjI4MjNkNmEwZTM2NTNhMzM4MzQyODRhMDJkYzZlYTp7Im5hbWUiOiIzMzMiLCJfc2Vzc2lvbl9leHBpcnkiOjB9 | 2018-09-04 07:07:14.852882 |
- +----------------------------------+------------------------------------------------------------------------------------------------------+----------------------------+
- 1 row in set (0.00 sec)
配置Mysql情况下DJango是会把session数据存储到数据库里面,我们可以自己配置redis来提高性能
使用Redis缓存session
存储session
- 使用存储会话的方式,可以使用settings.py的SESSION_ENGINE项指定
- 基于数据库的会话:这是django默认的会话存储方式,需要添加django.contrib.sessions到的INSTALLED_APPS设置中,运行manage.py migrate在数据库中安装会话表,可显示指定为
SESSION_ENGINE='django.contrib.sessions.backends.db'
- 基于缓存的会话:只存在本地内在中,如果丢失则不能找回,比数据库的方式读写更快
SESSION_ENGINE='django.contrib.sessions.backends.cache'
- 可以将缓存和数据库同时使用:优先从本地缓存中获取,如果没有则从数据库中获取
SESSION_ENGINE='django.contrib.sessions.backends.cached_db'redis存储
- 会话还支持文件、纯cookie、Memcached、Redis等方式存储,下面演示使用redis存储
- 安装包
pip3 install django-redis-sessions
- 修改settings中的配置,增加如下项
- SESSION_ENGINE = 'redis_sessions.session'
- SESSION_REDIS_HOST = 'localhost'
- SESSION_REDIS_PORT = 6379
- SESSION_REDIS_DB = 0
- SESSION_REDIS_PASSWORD = ''
- SESSION_REDIS_PREFIX = 'session'
- 管理redis的命令
- Ubuntu
- 启动:sudo redis-server /etc/redis/redis.conf
- 停止:sudo redis-server stop
- 重启:sudo redis-server restart
-
-
- Mac
- 启动:
- brew services start redis
- redis-server /usr/local/etc/redis.conf
-
- 停止:brew services stop redis
-
- 重启:brew services restart redis
-
-
- redis-cli:使用客户端连接服务器
- keys *:查看所有的键
- get name:获取指定键的值
- del name:删除指定名称的键
- INFO keyspace 查看数据库
- select index 选择数据库
- CONFIG GET databases 查看数据库数量
配置好之后,我们还是执行上面的session登录操作,登录之后,报文中还是一样,可以下mysql和redis

可以看到session被存到的内存高性能redis里面去了,而Mysql不再存储。
模板详细介绍
模板配置
- 作为Web框架,Django提供了模板,可以很便利的动态生成HTML
- 模版系统致力于表达外观,而不是程序逻辑
- 模板的设计实现了业务逻辑(view)与显示内容(template)的分离,一个视图可以使用任意一个模板,一个模板可以供多个视图使用
- 模板包含
- HTML的静态部分
- 动态插入内容部分
- Django模板语言,简写DTL,定义在django.template包中
- 由startproject命令生成的settings.py定义关于模板的值:
- DIRS定义了一个目录列表,模板引擎按列表顺序搜索这些目录以查找模板源文件
- APP_DIRS告诉模板引擎是否应该在每个已安装的应用中查找模板
- 常用方式:在项目的根目录下创建templates目录,设置DIRS值
DIRS=[os.path.join(BASE_DIR,"templates")]
模板处理
- Django处理模板分为两个阶段
- Step1 加载:根据给定的标识找到模板然后预处理,通常会将它编译好放在内存中
loader.get_template(template_name),返回一个Template对象
- Step2 渲染:使用Context数据对模板插值并返回生成的字符串
Template对象的render(RequestContext)方法,使用context渲染模板
- 加载渲染完整代码:
- from django.template import loader, RequestContext
- from django.http import HttpResponse
-
- def index(request):
- tem = loader.get_template('temtest/index.html')
- context = RequestContext(request, {})
- return HttpResponse(tem.render(context))
快捷函数
- 为了减少加载模板、渲染模板的重复代码,django提供了快捷函数
- render_to_string("")
- render(request,'模板',context)
- from django.shortcuts import render
-
- def index(request):
- return render(request, 'temtest/index.html')
模板定义
- 模板语言包括
- 变量
- 标签 { % 代码块 % }
- 过滤器
- 注释{# 代码或html #}
变量
- 语法:
- {{ variable }}
- 当模版引擎遇到一个变量,将计算这个变量,然后将结果输出
- 变量名必须由字母、数字、下划线(不能以下划线开头)和点组成
- 当模版引擎遇到点("."),会按照下列顺序查询:
- 字典查询,例如:foo["bar"]
- 属性或方法查询,例如:foo.bar 如果是方法就不能带参
- 数字索引查询,例如:foo[bar]
- 如果变量不存在, 模版系统将插入'' (空字符串)
- 在模板中调用方法时不能传递参数
在模板中调用对象的方法
- 在models.py中定义类HeroInfo
- from django.db import models
-
- class HeroInfo(models.Model):
- ...
- def showName(self):
- return self.hname
- 在views.py中传递HeroInfo对象
- from django.shortcuts import render
- from models import *
-
- def index(request):
- hero = HeroInfo(hname='abc')
- context = {'hero': hero}
- return render(request, 'temtest/detail.html', context)
- 在模板detail.html中调用
- {{hero.showName}}
标签
- 语法:{ % tag % }
- 作用
- 在输出中创建文本
- 控制循环或逻辑
- 加载外部信息到模板中供以后的变量使用
- for标签
- { %for ... in ...%}
- 循环逻辑
- {{forloop.counter}}表示当前是第几次循环
- { %empty%}
- 给出的列表为或列表不存在时,执行此处
- { %endfor%}
- if标签
- { %if ...%}
- 逻辑1
- { %elif ...%}
- 逻辑2
- { %else%}
- 逻辑3
- { %endif%}
- comment标签
- { % comment % }
- 多行注释
- { % endcomment % }
- include:加载模板并以标签内的参数渲染
{ %include "foo/bar.html" % }
- url:反向解析
{ % url 'name' p1 p2 %}
- csrf_token:这个标签用于跨站请求伪造保护
{ % csrf_token %}
- 布尔标签:and、or,and比or的优先级高
- block、extends:详见“模板继承”
- autoescape:详见“HTML转义”
过滤器
https://blog.csdn.net/xyp84/article/details/7945094
一、形式:小写
{{ name | lower }}二、过滤器是可以嵌套的,字符串经过三个过滤器,第一个过滤器转换为小写,第二个过滤器输出首字母,第三个过滤器将首字母转换成大写
- 标签
-
- {{ str|lower|first|upper }}
-
- 显示前30个字
-
- {{ bio | truncatewords:"30" }}
-
- 格式化
-
- {{ pub_date | date:"F j, Y" }}
-
- 过滤器列表
-
- {{ 123|add:"5" }} 给value加上一个数值
-
- {{ "AB'CD"|addslashes }} 单引号加上转义号,一般用于输出到javascript中
-
- {{ "abcd"|capfirst }} 第一个字母大写
-
- {{ "abcd"|center:"50" }} 输出指定长度的字符串,并把值对中
-
- {{ "123spam456spam789"|cut:"spam" }} 查找删除指定字符串
-
- {{ value|date:"F j, Y" }} 格式化日期
-
- {{ value|default:"(N/A)" }} 值不存在,使用指定值
-
- {{ value|default_if_none:"(N/A)" }} 值是None,使用指定值
-
- {{ 列表变量|dictsort:"数字" }} 排序从小到大
-
- {{ 列表变量|dictsortreversed:"数字" }} 排序从大到小
-
- {% if 92|pisibleby:"2" %} 判断是否整除指定数字
-
- {{ string|escape }} 转换为html实体
-
- {{ 21984124|filesizeformat }} 以1024为基数,计算最大值,保留1位小数,增加可读性
-
- {{ list|first }} 返回列表第一个元素
-
- {{ "ik23hr&jqwh"|fix_ampersands }} &转为&
-
- {{ 13.414121241|floatformat }} 保留1位小数,可为负数,几种形式
-
- {{ 13.414121241|floatformat:"2" }} 保留2位小数
-
- {{ 23456 |get_digit:"1" }} 从个位数开始截取指定位置的1个数字
-
- {{ list|join:", " }} 用指定分隔符连接列表
-
- {{ list|length }} 返回列表个数
-
- {% if 列表|length_is:"3" %} 列表个数是否指定数值
-
- {{ "ABCD"|linebreaks }} 用新行用
-
- {% forloop.counter|divisibleby:"2" %} 表示是否被某个数整除
-
- 、
- 标记包裹
-
- {{ "ABCD"|linebreaksbr }} 用新行用
- 标记包裹
-
- {{ 变量|linenumbers }} 为变量中每一行加上行号
-
- {{ "abcd"|ljust:"50" }} 把字符串在指定宽度中对左,其它用空格填充
-
- {{ "ABCD"|lower }} 小写
-
- {% for i in "1abc1"|make_list %}ABCDE,{% endfor %} 把字符串或数字的字符个数作为一个列表
-
- {{ "abcdefghijklmnopqrstuvwxyz"|phone2numeric }} 把字符转为可以对应的数字??
-
- {{ 列表或数字|pluralize }} 单词的复数形式,如列表字符串个数大于1,返回s,否则返回空串
-
- {{ 列表或数字|pluralize:"es" }} 指定es
-
- {{ 列表或数字|pluralize:"y,ies" }} 指定ies替换为y
-
- {{ object|pprint }} 显示一个对象的值
-
- {{ 列表|random }} 返回列表的随机一项
-
- {{ string|removetags:"br p p" }} 删除字符串中指定html标记
-
- {{ string|rjust:"50" }} 把字符串在指定宽度中对右,其它用空格填充
-
- {{ 列表|slice:":2" }} 切片
-
- {{ string|slugify }} 字符串中留下减号和下划线,其它符号删除,空格用减号替换
-
- {{ 3|stringformat:"02i" }} 字符串格式,使用Python的字符串格式语法
-
- {{ "EABCD"|striptags }} 剥去[X]HTML语法标记
-
- {{ 时间变量|time:"P" }} 日期的时间部分格式
-
- {{ datetime|timesince }} 给定日期到现在过去了多少时间
-
- {{ datetime|timesince:"other_datetime" }} 两日期间过去了多少时间
-
- {{ datetime|timeuntil }} 给定日期到现在过去了多少时间,与上面的区别在于2日期的前后位置。
-
- {{ datetime|timeuntil:"other_datetime" }} 两日期间过去了多少时间
-
- {{ "abdsadf"|title }} 首字母大写
-
- {{ "A B C D E F"|truncatewords:"3" }} 截取指定个数的单词
-
- {{ "111221"|truncatewords_html:"2" }} 截取指定个数的html标记,并补完整
-
-
- {{ list|unordered_list }}
-
- 多重嵌套列表展现为html的无序列表
-
- {{ string|upper }} 全部大写
-
- linkageurl编码
-
- {{ string|urlize }} 将URLs由纯文本变为可点击的链接。
-
- {{ string|urlizetrunc:"30" }} 同上,多个截取字符数。
-
- {{ "B C D E F"|wordcount }} 单词数
-
- {{ "a b c d e f g h i j k"|wordwrap:"5" }} 每指定数量的字符就插入回车符
-
- {{ boolean|yesno:"Yes,No,Perhaps" }} 对三种值的返回字符串,对应是 非空,空,None。
三、过滤器的参数
- 语法:{ { 变量|过滤器 }},例如{ { name|lower }},表示将变量name的值变为小写输出
- 使用管道符号 (|)来应用过滤器
- 通过使用过滤器来改变变量的计算结果
- 可以在if标签中使用过滤器结合运算符
if list1|length > 1
- 过滤器能够被“串联”,构成过滤器链
name|lower|upper
- 过滤器可以传递参数,参数使用引号包起来
list|join:", "
- default:如果一个变量没有被提供,或者值为false或空,则使用默认值,否则使用变量的值
value|default:"什么也没有"
- date:根据给定格式对一个date变量格式化
value|date:'Y-m-d'
- escape:详见“HTML转义”
- 点击查看详细的过滤器
注释
- 单行注释
{#...#}
- 注释可以包含任何模版代码,有效的或者无效的都可以
{# { % if foo % }bar{ % else % } #}
- 使用comment标签注释模版中的多行内容
反向解析(动态生成跳转url)
DJango模板语言中
{ % url 'namespace:name' p1 p2 %}重定向中
- def login_handle(request):
- request.session['name'] = request.POST['username']
- request.session.set_expiry(0)
-
- return redirect(reverse('booktest:mainTest'))
为什么要反向解析?
首先看个简单的例子
- 根url匹配
-
- from django.contrib import admin
- from django.urls import path, re_path, include
-
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^booktest/', include('booktest.urls', namespace='booktest'))
- ]
-
-
-
- booktestapp里面url匹配
-
- from django.urls import path, re_path
- from . import views
-
- app_name = 'booktest'
-
- urlpatterns = [
-
- re_path(r'^$', views.index, name='index'),
- re_path(r'^(\d+)/$', views.show, name='show'),
-
- ]
-
-
-
-
- views.py
- index对应的文件
- <body>
- <h1>Index</h1>
-
- <a href="/booktest/123">展示</a>
- </body>
- </html>
这里面两个页面index页面展示一个跳转a标签,a标签写的路径是根路径,会替换url里面的路径,这么看来简单的跳转就没问题。但是如果咱们按下面改一下
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^', include('booktest.urls', namespace='booktest'))
- ]
当我们进入index页面的时候再点击a标签,路径还是带有booktest前缀,因此直接404了,外面改了,我们里面还是需要跟着改,这就非常的浪费时间了,而且维护起来很麻烦,因此就有了反向解析。
我们在根的urls下面都会有定义namespace,在app目录下的urls里面会给匹配的name,除此之外还需要在app的urls下面指定app_name
- 根部urls
-
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^booktest/', include('booktest.urls', namespace='booktest'))
- ]
-
- app里面urls
-
- app_name = 'booktest'
-
- urlpatterns = [
-
- re_path(r'^$', views.index, name='index'),
- re_path(r'^(\d+)/$', views.show, name='show'),
-
- ]
-
-
- views
- def index(request):
- return render(request, 'booktest/index.html')
- def show(request, p1):
- return render(request,'booktest/show.html', {'p1':p1})
-
- index页面信息
- <h1>Index</h1>
- # 这里的第一个参数是namespace 第二个参数是show正则里面()匹配的参数
- <a href="{% url 'booktest:show' '100000' %}">展示</a>
- </body>
- </html>
这里可以看到通过上面a标签的写法来指定反向解析,前提是booktest和show要先指定namespace和name,然后就可以通过语法进行反向url解析,不需要我们写死跳转路径了,views里面的重定向也是一样可以反向解析出路径,这样外部更改url,我们内部也无需再改
模板继承
- 模板继承可以减少页面内容的重复定义,实现页面内容的重用
- 典型应用:网站的头部、尾部是一样的,这些内容可以定义在父模板中,子模板不需要重复定义
- block标签:在父模板中预留区域,在子模板中填充
- extends继承:继承,写在模板文件的第一行
- 定义父模板base.html
- { %block block_name%}
- 这里可以定义默认值
- 如果不定义默认值,则表示空字符串
- { %endblock%}
- 定义子模板index.html
{ % extends "base.html" %}
- 在子模板中使用block填充预留区域
- { %block block_name%}
- 实际填充内容
- { %endblock%}
说明
- 如果在模版中使用extends标签,它必须是模版中的第一个标签
- 不能在一个模版中定义多个相同名字的block标签
- 子模版不必定义全部父模版中的blocks,如果子模版没有定义block,则使用了父模版中的默认值
- 如果发现在模板中大量的复制内容,那就应该把内容移动到父模板中
- 使用可以获取父模板中block的内容
- 为了更好的可读性,可以给endblock标签一个名字
- { % block block_name %}
- 区域内容
- { % endblock block_name %}
三层继承结构
- 三层继承结构使代码得到最大程度的复用,并且使得添加内容更加简单
- 如下图为常见的电商页面
1.创建根级模板
- 名称为“base.html”
- 存放整个站点共用的内容
- <!DOCTYPE html>
- <html>
- <head>
- <title>{%block title%}{%endblock%} 水果超市</title>
- </head>
- <body>
- top--{{logo}}
- <hr/>
- {%block left%}{%endblock%}
- {%block content%}{%endblock%}
- <hr/>
- bottom
- </body>
- </html>
2.创建分支模版
- 继承自base.html
- 名为“base_*.html”
- 定义特定分支共用的内容
- 定义base_goods.html
- {%extends 'temtest/base.html'%}
- {%block title%}商品{%endblock%}
- {%block left%}
- <h1>goods left</h1>
- {%endblock%}
- 定义base_user.html
- {%extends 'temtest/base.html'%}
- {%block title%}用户中心{%endblock%}
- {%block left%}
- <font color='blue'>user left</font>
- {%endblock%}
- 定义index.html,继承自base.html,不需要写left块
- {%extends 'temtest/base.html'%}
- {%block content%}
- 首页内容
- {%endblock content%}
3.为具体页面创建模板,继承自分支模板
- 定义商品列表页goodslist.html
- {%extends 'temtest/base_goods.html'%}
- {%block content%}
- 商品正文列表
- {%endblock content%}
- 定义用户密码页userpwd.html
- {%extends 'temtest/base_user.html'%}
- {%block content%}
- 用户密码修改
- {%endblock content%}
4.视图调用具体页面,并传递模板中需要的数据
- 首页视图index
- logo='welcome to itcast'
- def index(request):
- return render(request, 'temtest/index.html', {'logo': logo})
- 商品列表视图goodslist
- def goodslist(request):
- return render(request, 'temtest/goodslist.html', {'logo': logo})
- 用户密码视图userpwd
- def userpwd(request):
- return render(request, 'temtest/userpwd.html', {'logo': logo})
5.配置url
- from django.conf.urls import url
- from . import views
- urlpatterns = [
- url(r'^$', views.index, name='index'),
- url(r'^list/$', views.goodslist, name='list'),
- url(r'^pwd/$', views.userpwd, name='pwd'),
- ]
HTML转义
- Django对字符串进行自动HTML转义,如在模板中输出如下值:
- 视图代码:
- def index(request):
- return render(request, 'temtest/index2.html',
- {
- 't1': '<h1>hello</h1>'
- })
- 模板代码:
- {{t1}}
- 显示效果如下图:
会被自动转义的字符
- html转义,就是将包含的html标签输出,而不被解释执行,原因是当显示用户提交字符串时,可能包含一些攻击性的代码,如js脚本
- Django会将如下字符自动转义:
- < 会转换为<
-
- > 会转换为>
-
- ' (单引号) 会转换为'
-
- " (双引号)会转换为 "
-
- & 会转换为 &
- 当显示不被信任的变量时使用escape过滤器,一般省略,因为Django自动转义
- {{t1|escape}}
关闭转义
- 对于变量使用safe过滤器
- {{ data|safe }}
- 对于代码块使用autoescape标签
- {% autoescape off %}
- {{ body }}
- {% endautoescape %}
- 标签autoescape接受on或者off参数
- 自动转义标签在base模板中关闭,在child模板中也是关闭的
字符串字面值
- 手动转义
- {{ data|default:"<b>123</b>" }}
- 应写为
{{ data|default:"<b>123</b>" }}
CSRF(跨站请求伪造)
- 全称Cross Site Request Forgery,跨站请求伪造
- 某些恶意网站上包含链接、表单按钮或者JavaScript,它们会利用登录过的用户在浏览器中的认证信息试图在你的网站上完成某些操作,这就是跨站攻击
- 演示csrf如下
- 创建视图csrf1用于展示表单,csrf2用于接收post请求
- def csrf1(request):
- return render(request,'booktest/csrf1.html')
- def csrf2(request):
- uname=request.POST['uname']
- return render(request,'booktest/csrf2.html',{'uname':uname})
- 配置url
- url(r'^csrf1/$', views.csrf1),
- url(r'^csrf2/$', views.csrf2),
- 创建模板csrf1.html用于展示表单
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- <form method="post" action="/crsf2/">
- <input name="uname"><br>
- <input type="submit" value="提交"/>
- </form>
- </body>
- </html>
- 创建模板csrf2用于展示接收的结果
- <html>
- <head>
- <title>Title</title>
- </head>
- <body>
- {{ uname }}
- </body>
- </html>
- 在浏览器中访问,查看效果,报403
- 将settings.py中的中间件代码'django.middleware.csrf.CsrfViewMiddleware'注释
- 查看csrf1的源代码,复制,在自己的网站内建一个html文件,粘贴源码,访问查看效果
防csrf的使用
- 在django的模板中,提供了防止跨站攻击的方法,使用步骤如下:
- step1:在settings.py中启用'django.middleware.csrf.CsrfViewMiddleware'中间件,此项在创建项目时,默认被启用
- step2:在csrf1.html中添加标签
- <form>
- {% csrf_token %}
- ...
- </form>
- step3:测试刚才的两个请求,发现跨站的请求被拒绝了,效果如下图
取消保护
- 如果某些视图不需要保护,可以使用装饰器csrf_exempt,模板中也不需要写标签,修改csrf2的视图如下
- from django.views.decorators.csrf import csrf_exempt
-
- @csrf_exempt
- def csrf2(request):
- uname=request.POST['uname']
- return render(request,'booktest/csrf2.html',{'uname':uname})
- 运行上面的两个请求,发现都可以请求
保护原理
- 加入标签后,可以查看源代码,发现多了如下代码
<input type='hidden' name='csrfmiddlewaretoken' value='nGjAB3Md9ZSb4NmG1sXDolPmh3bR2g59' />
- 在浏览器的调试工具中,通过network标签可以查看cookie信息
- 本站中自动添加了cookie信息,如下图
- 查看跨站的信息,并没有cookie信息,即使加入上面的隐藏域代码,发现又可以访问了
- 结论:django的csrf不是完全的安全
- 当提交请求时,中间件'django.middleware.csrf.CsrfViewMiddleware'会对提交的cookie及隐藏域的内容进行验证,如果失败则返回403错误
自己的域名下自己访问加了{% csrf_token%}表单隐藏添加了cookies中的csrftoken信息,由于开启了middleware,服务器会做一个token让cookie带回来,如果表单没有开启token验证,表单不会携带csrftoken,那就会返回403,如果加了token验证,那么表单里面会把token带过去,服务器拿到表单和cookies进行token比较就可以了。但是有个问题,其他域名下访问的时候,也是伪造了表单,然后把cookies里面的token值抓下来带过去了,这个时候就能跨域访问了,感觉DJango没有判断cookies里面有没有值,直接拿服务器的和表单的比较了,这样cookies被扒下来就能伪造了,因此验证码模式就出来了,更完善的模式
验证码
- 在用户注册、登录页面,为了防止暴力请求,可以加入验证码功能,如果验证码错误,则不需要继续处理,可以减轻一些服务器的压力
- 使用验证码也是一种有效的防止crsf的方法
- 验证码效果如下图:

- 定义函数verify
- 此段代码用到了PIL中的Image、ImageDraw、ImageFont模块,pip3 install pillow
- Image表示画布对象
- ImageDraw表示画笔对象
-
ImageFont表示字体对象,Mac的字体路径为”/System/Library/Fonts/“
- from PIL import Image, ImageDraw, ImageFont
- from io import BytesIO
-
- def verify(request):
- # 引入绘图模块
- from PIL import Image, ImageDraw, ImageFont
- # 引入随机函数模块
- import random
- # 定义变量,用于画面的背景色、宽、高
- bgcolor = (random.randrange(20, 100), random.randrange(
- 20, 100), 255)
- width = 100
- height = 25
- # 创建画面对象
- im = Image.new('RGB', (width, height), bgcolor)
- # 创建画笔对象
- draw = ImageDraw.Draw(im)
- # 调用画笔的point()函数绘制噪点
- for i in range(0, 100):
- xy = (random.randrange(0, width), random.randrange(0, height))
- fill = (random.randrange(0, 255), 255, random.randrange(0, 255))
- draw.point(xy, fill=fill)
- # 定义验证码的备选值
- str1 = 'ABCD123EFGHIJK456LMNOPQRS789TUVWXYZ0'
- # 随机选取4个值作为验证码
- rand_str = ''
- for i in range(0, 4):
- rand_str += str1[random.randrange(0, len(str1))]
- # 构造字体对象 这里的路径是Mac的
- font = ImageFont.truetype('/System/Library/Fonts/AquaKana.ttc', 23)
- # 构造字体颜色
- fontcolor = (255, random.randrange(0, 255), random.randrange(0, 255))
- # 绘制4个字
- draw.text((5, 2), rand_str[0], font=font, fill=fontcolor)
- draw.text((25, 2), rand_str[1], font=font, fill=fontcolor)
- draw.text((50, 2), rand_str[2], font=font, fill=fontcolor)
- draw.text((75, 2), rand_str[3], font=font, fill=fontcolor)
- # 释放画笔
- del draw
- # 存入session,用于做进一步验证
- request.session['verifycode'] = rand_str
- # 内存文件操作 python2和3有很大区别,这里用的3
- buf = BytesIO()
- # 将图片保存在内存中,文件类型为png 二进制 所以用BytesIO
- im.save(buf, 'png')
- # 将内存中的图片数据返回给客户端,MIME类型为图片png
- return HttpResponse(buf.getvalue(), 'image/png')
1.注意Python3和2的区别,这里我们导入的BytesIO,而不在是StringsIO了
2.Mac的路径注意填写
配置url
- 在urls.py中定义请求验证码视图的url
- from django.urls import path, re_path
- from . import views
-
- app_name = 'booktest'
-
- urlpatterns = [
-
- re_path(r'^$', views.index, name='index'),
- re_path(r'^verify$', views.verify, name='verify'),
- re_path(r'^verifycode$', views.verifycode, name='verifycode'),
-
- ]
显示验证码
- 在模板中使用img标签,src指向验证码视图
- <h1>Index</h1>
- <a href="">{{random}}</a>
-
- <a href="{% url 'booktest:show' '100000' %}">展示</a>
- <br>
- <br>
- <br>
- <tr>
- <form action="{% url 'booktest:verifycode' %}" method="post">
- <input type="text" name="name">
- <img src="{% url 'booktest:verify' %}" alt="验证码" id="verify">
- <span id='verifycodeChange' onclick="changecode()">看不清,换一个</span>
- <input type="submit" value="提交">
- </form>
-
- </body>
-
- <script type="text/javascript">
-
- function changecode() {
- var i = Math.floor(Math.random() * (1000 - 1) + 1)
- document.getElementById("verify").src = "{% url 'booktest:verify' %}".concat('?a=', i)
- }
-
-
- </script>
-
- </html>
验证
- 接收请求的信息,与session中的内容对比
- def verifycode(request):
- poststr = request.POST['name']
- vcodestr = request.session.get('verifycode', '')
- if poststr.upper() == vcodestr:
- return HttpResponse('OK')
- else:
- return HttpResponse('NO')

高级特性
静态文件
- 项目中的CSS、图片、js都是静态文件
配置静态文件
- 在settings 文件中定义静态内容
- 这个值是可变的,例如给别人起一个外号,如果path里面路径由这个开头,就会从下面路径查找
-
- 127.0.0.1:8000/static/booktest/a1.jpg
-
- 匹配到static了,因此后面的/booktest/a1.jpg就会去STATICFILES_DIRS路径下查找
-
-
- STATIC_URL = '/static/'
- STATICFILES_DIRS = [
- os.path.join(BASE_DIR, 'static'),
- ]
-
-
- 如果改为
- STATIC_URL = '/mkj/'
- STATICFILES_DIRS = [
- os.path.join(BASE_DIR, 'static'),
- ]
-
- src=127.0.0.1:8000/static/booktest/a1.jpg这个时候,匹配不上mkj路径,因此显示不了
-
- 我们要写成src=127.0.0.1:8000/mkj/booktest/a1.jpg就好了,避免通过查看源代码知道物理结构,就弄了一个别名
- 在项目根目录下创建static目录,再创建当前应用名称的目录
test3(project名称)/static/booktest/
- 在模板中可以使用硬编码
- 结构
- /static/my_app/myexample.jpg
-
-
- src下面写相对路径,第一个路径标识STATIC_URL,和setting中匹配上,说明读的静态文件,然后再去
- STATICFILES_DIRS中查找后面路径的值/booktest/a1.jpg 找到就显示
- <img src="/static/booktest/a1.jpg" alt="美女" width="100" height="100">
- 在模板中可以使用static编码 和反向解析一样,可以和STATIC_URL一样同步
- 导入static标签
- { % load static from staticfiles %}
- <img src="{ % static "my_app/myexample.jpg" %}" alt="My image"/>
-
- 固定static写法,然后导入配置路径下的具体路径即可
- <img src="{ % static "booktest/a1.jpg" %}" alt="My image"/>
中间件
- 是一个轻量级、底层的插件系统,可以介入Django的请求和响应处理过程,修改Django的输入或输出
- 激活:添加到Django配置文件中的MIDDLEWARE_CLASSES元组中
- 每个中间件组件是一个独立的Python类,可以定义下面方法中的一个或多个
- _init _:无需任何参数,服务器响应第一个请求的时候调用一次,用于确定是否启用当前中间件
- process_request(request):执行视图之前被调用,在每个请求上调用,返回None或HttpResponse对象
- process_view(request, view_func, view_args, view_kwargs):调用视图之前被调用,在每个请求上调用,返回None或HttpResponse对象
- process_template_response(request, response):在视图刚好执行完毕之后被调用,在每个请求上调用,返回实现了render方法的响应对象
- process_response(request, response):所有响应返回浏览器之前被调用,在每个请求上调用,返回HttpResponse对象
- process_exception(request,response,exception):当视图抛出异常时调用,在每个请求上调用,返回一个HttpResponse对象
- 使用中间件,可以干扰整个处理过程,每次请求中都会执行中间件的这个方法
- 示例:自定义异常处理
- 与settings.py同级目录下创建myexception.py文件,定义类MyException,实现process_exception方法
- from django.http import HttpResponse
- class MyException():
- def process_exception(request,response, exception):
- return HttpResponse(exception.message)
- 将类MyException注册到settings.py中间件中
- MIDDLEWARE_CLASSES = (
- 'test1.myexception.MyException',
- ...
- )
- 定义视图,并发生一个异常信息,则会运行自定义的异常处理
上传图片
- 当Django在处理文件上传的时候,文件数据被保存在request.FILES
- FILES中的每个键为<input type="file" name="" />中的name
- 注意:FILES只有在请求的方法为POST 且提交的<form>带有enctype="multipart/form-data" 的情况下才会包含数据。否则,FILES 将为一个空的类似于字典的对象
- 使用模型处理上传文件:将属性定义成models.ImageField类型
pic=models.ImageField(upload_to='cars/')
- 注意:如果属性类型为ImageField需要安装包Pilow
pip3 install Pillow
- 图片存储路径
- 在项目根目录下创建media文件夹
- 图片上传后,会被保存到“/static/media/cars/图片文件”
- 打开settings.py文件,增加media_root项
MEDIA_ROOT=os.path.join(BASE_DIR,"static/media")
- 使用django后台管理,遇到ImageField类型的属性会出现一个file框,完成文件上传
- 手动上传的模板代码
- <body>
- <h1>呵呵</h1>
- <form action="{% url 'booktest:uploadfile2' %}" method="post" enctype="multipart/form-data">
- {% csrf_token %}
- <input type="file" name="icon">
- <input type="submit" value="提交">
- </form>
- </body>
- </html>
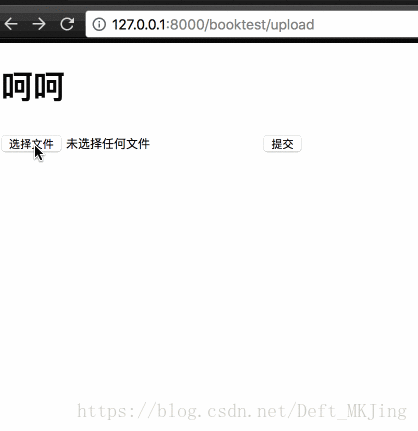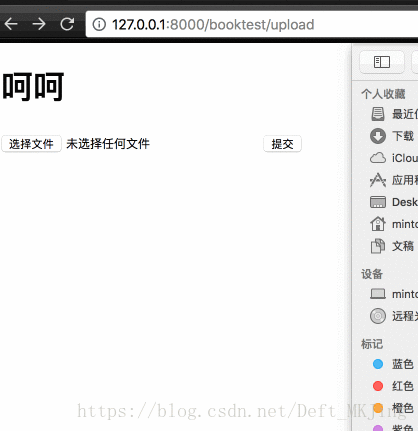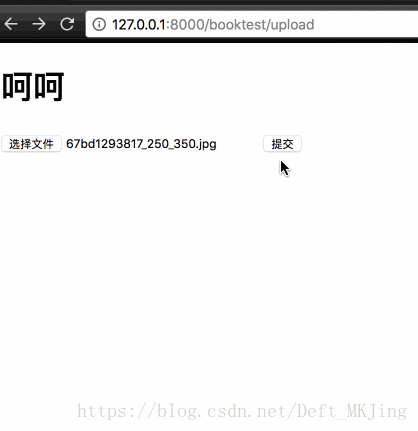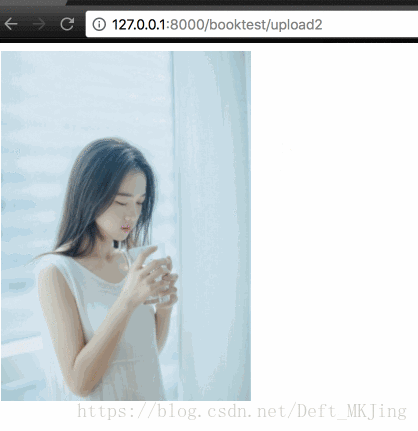
视图代码
- def uploadFile1(request):
- return render(request, 'booktest/upload.html')
-
-
- def uploadFile2(request):
- # 注意是FILES
- pic = request.FILES['icon']
- # 全路径
- storepath = os.path.join(settings.MEDIA_ROOT, pic.name)
- # with是不需要手动释放内存 ft指针
- with open(storepath, 'wb') as ft:
- # 内存中图片读取
- for ct in pic.chunks():
- # 写入
- ft.write(ct)
- # 这里的staitc是标识setting文件下的路径,会自动拼接那个路径,你然后后面跟media/xxx.jpg即可
- return HttpResponse('<img src="/static/media/%s" alt="">'%pic.name)
Admin站点
- 通过使用startproject创建的项目模版中,默认Admin被启用
- 1.创建管理员的用户名和密码
- python manage.py createsuperuser
- 然后按提示填写用户名、邮箱、密码
- 2.在应用内admin.py文件完成注册,就可以在后台管理中维护模型的数据
- from django.contrib import admin
- from models import *
-
- admin.site.register(HeroInfo)
- 查找admin文件:在INSTALLED_APPS项中加入django.contrib.admin,Django就会自动搜索每个应用的admin模块并将其导入
ModelAdmin对象
- ModelAdmin类是模型在Admin界面中的表示形式
- 定义:定义一个类,继承于admin.ModelAdmin,注册模型时使用这个类
- class HeroAdmin(admin.ModelAdmin):
- ...
- 通常定义在应用的admin.py文件里
- 使用方式一:注册参数
admin.site.register(HeroInfo,HeroAdmin)
- 使用方式二:注册装饰器
- @admin.register(HeroInfo)
- class HeroAdmin(admin.ModelAdmin):
- 通过重写admin.ModelAdmin的属性规定显示效果,属性主要分为列表页、增加修改页两部分
列表页选项
“操作选项”的位置
- actions_on_top、actions_on_bottom:默认显示在页面的顶部
- class HeroAdmin(admin.ModelAdmin):
- actions_on_top = True
- actions_on_bottom = True
list_display
- 出现列表中显示的字段
- 列表类型
- 在列表中,可以是字段名称,也可以是方法名称,但是方法名称默认不能排序
- 在方法中可以使用format_html()输出html内容
- 在models.py文件中
- from django.db import models
- from tinymce.models import HTMLField
- from django.utils.html import format_html
-
- class HeroInfo(models.Model):
- hname = models.CharField(max_length=10)
- hcontent = HTMLField()
- isDelete = models.BooleanField()
- def hContent(self):
- return format_html(self.hcontent)
-
- 在admin.py文件中
- class HeroAdmin(admin.ModelAdmin):
- list_display = ['hname', 'hContent']
- 让方法排序,为方法指定admin_order_field属性
- 在models.py中HeroInfo类的代码改为如下:
- def hContent(self):
- return format_html(self.hcontent)
- hContent.admin_order_field = 'hname'
- 标题栏名称:将字段封装成方法,为方法设置short_description属性
- 在models.py中为HeroInfo类增加方法hName:
- def hName(self):
- return self.hname
- hName.short_description = '姓名'
- hContent.short_description = '内容'
-
- 在admin.py页中注册
- class HeroAdmin(admin.ModelAdmin):
- list_display = ['hName', 'hContent']
list_filter
- 右侧栏过滤器,对哪些属性的值进行过滤
- 列表类型
- 只能接收字段
- class HeroAdmin(admin.ModelAdmin):
- ...
- list_filter = ['hname', 'hcontent']
list_per_page
- 每页中显示多少项,默认设置为100
- class HeroAdmin(admin.ModelAdmin):
- ...
- list_per_page = 10
search_fields
- 搜索框
- 列表类型,表示在这些字段上进行搜索
- 只能接收字段
- class HeroAdmin(admin.ModelAdmin):
- ...
- search_fields = ['hname']
增加与修改页选项
- fields:显示字段的顺序,如果使用元组表示显示到一行上
- class HeroAdmin(admin.ModelAdmin):
- ...
- fields = [('hname', 'hcontent')]
- fieldsets:分组显示
- class HeroAdmin(admin.ModelAdmin):
- ...
- fieldsets = (
- ('base', {'fields': ('hname')}),
- ('other', {'fields': ('hcontent')})
- )
- fields与fieldsets两者选一
InlineModelAdmin对象
- 类型InlineModelAdmin:表示在模型的添加或修改页面嵌入关联模型的添加或修改
- 子类TabularInline:以表格的形式嵌入
- 子类StackedInline:以块的形式嵌入
- class HeroInline(admin.TabularInline):
- model = HeroInfo
- class BookAdmin(admin.ModelAdmin):
- inlines = [
- HeroInline,
- ]
路径相关疑问
1、路径前面的/问题
首先我们看下/开头的路径,以一个 127.0.0.1:8000/booktest/path1路径为例,当我们进入前面这个路径的views后,点击a标签,这个时候a标签如果不开启命名空间,正常情况下如果用href='path2',那么这个路径会变成
127.0.0.1:8000/booktest/path1/path2如果href='/path2',路径会变成
127.0.0.1:8000/path2如果是img标签,路径是指定静态资源的,首先看下配置
- STATIC_URL = '/static/'
- STATICFILES_DIRS = [
- os.path.join(BASE_DIR, 'static'),
- ]
如果这个时候img标签里面的src是 /static/booktest/a1.jpg的意思是,第一个路径的参数是匹配上面的STATIC_URL的,如果匹配上了,就去STATICFILES_DIRS下查找,查找内容就是booktest/a1.jpg,这就是静态资源查找的规则
2、路径后面的/问题
Django中的处理方法是提供了一个设置项,APPEND_SLASH,这个设置的默认值是True。当APPEND_SLASH为True的时候,如果一个URL没有匹配成功,那么Django会在这个URL尾部加上一个'/'并重新redirect(301)回来。如果设置为False,那没有匹配成功的时候就什么都不会做。
需要注意的是,由于采用了redirect的方式,所以POST数据可能会丢失。
例如两个请求
- 127.0.0.1:8000/booktest/hello
-
- 127.0.0.1:8000/booktest/hello/
在APPEND_SLASH默认为True的情况下,如果
如果设置了'hello',那么只有'hello'会匹配,'hello/'不会匹配。
如果设置了'hello/',那么'hello'和'hello/'都会匹配。hello没匹配到,自动加上尾斜杠,然后301继续匹配,这也是DJango的推荐方式
在APPEND_SLASH默认为False的情况下,写了上面就匹配什么,匹配不到也不会继续301重定向,
可以看到如果按着DJango的写法,一般匹配都会写上尾斜杠来匹配用户输入写或者没写的url
https://www.bbsmax.com/A/kjdwABD6JN/
分页
- Django提供了一些类实现管理数据分页,这些类位于django/core/paginator.py中
Paginator对象
- Paginator(列表,int):返回分页对象,参数为列表数据,每面数据的条数
属性
- count:对象总数
- num_pages:页面总数
- page_range:页码列表,从1开始,例如[1, 2, 3, 4]
方法
- page(num):下标以1开始,如果提供的页码不存在,抛出InvalidPage异常
异常exception
- InvalidPage:当向page()传入一个无效的页码时抛出
- PageNotAnInteger:当向page()传入一个不是整数的值时抛出
- EmptyPage:当向page()提供一个有效值,但是那个页面上没有任何对象时抛出
Page对象
创建对象
- Paginator对象的page()方法返回Page对象,不需要手动构造
属性
- object_list:当前页上所有对象的列表
- number:当前页的序号,从1开始
- paginator:当前page对象相关的Paginator对象
方法
- has_next():如果有下一页返回True
- has_previous():如果有上一页返回True
- has_other_pages():如果有上一页或下一页返回True
- next_page_number():返回下一页的页码,如果下一页不存在,抛出InvalidPage异常
- previous_page_number():返回上一页的页码,如果上一页不存在,抛出InvalidPage异常
- len():返回当前页面对象的个数
- 迭代页面对象:访问当前页面中的每个对象
视图
- def herolist(request,index):
- if index == '':
- index = 1
- list1 = HeroInfo.objects.all()
- paginator = Paginator(list1, 5)
- page = paginator.page(index)
-
-
- return render(request, 'booktest/hero.html', {'page': page,'lists':list1})
url
- urlpatterns = [
- re_path(r'^$', views.index, name='index'),
- re_path(r'^hero/(\d*)$', views.herolist, name='hero'),
- ]
模板
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Title</title>
- </head>
- <body>
- <ul>
- {% for hero in page.object_list %}
- <li>{{hero.hname}}</li>
- {% endfor %}
- <br>
- {% for index in page.paginator.page_range %}
- {% if page.number == index%}
- {{index}}
- {% else %}
- <a href="/booktest/hero/{{index}}">{{index}}</a>
- {% endif %}
- {% endfor %}
- <!--总个数 {{page.count}}-->
- <br>
- <!--分了几页 {{page.num_pages}}-->
- <br>
- <!--页数数组 {{page.page_range}}-->
- </ul>
-
- </body>
- </html>
Ajax请求和JsonReponse数据
- 使用视图通过上下文向模板中传递数据,需要先加载完成模板的静态页面,再执行模型代码,生成最张的html,返回给浏览器,这个过程将页面与数据集成到了一起,扩展性差
- 改进方案:通过ajax的方式获取数据,通过dom操作将数据呈现到界面上
- 推荐使用框架的ajax相关方法,不要使用XMLHttpRequest对象,因为操作麻烦且不容易查错
- jquery框架中提供了$.ajax、$.get、$.post方法,用于进行异步交互
- 由于csrf的约束,推荐使用$.get
- 示例:实现省市区的选择

引入js文件
- js文件属于静态文件,创建目录结构如图:
修改settings.py关于静态文件的设置
- # Static files (CSS, JavaScript, Images)
- # https://docs.djangoproject.com/en/2.1/howto/static-files/
-
- STATIC_URL = '/static/'
- STATICFILES_DIRS = [
- os.path.join(BASE_DIR, 'static'),
- ]
在models.py中定义模型
- class AreaInfo(models.Model):
- title = models.CharField(max_length=20)
- parentid = models.ForeignKey('self', null=True, blank=True,on_delete=models.CASCADE)
生成迁移
- python manage.py makemigrations
- python manage.py migrate
网上找一个sql脚本,然后用Navicat连接,然后把脚本跑入对应的数据库即可
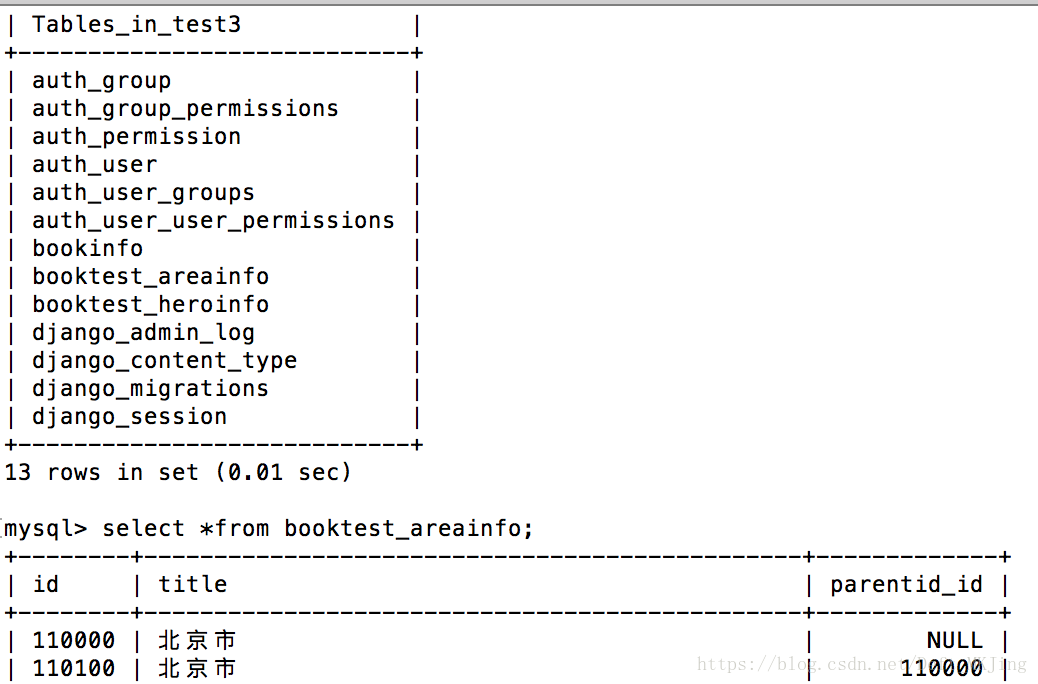
views.py中编写视图
- # 选择首页
- def area(request):
- return render(request,'booktest/area.html')
-
- # 省请求json信息
- def areainfo(request, pid):
- data = AreaInfo.objects.filter(parentid__isnull=True).values('id', 'title')
-
- return JsonResponse({'result': list(data)})
- # 市和区请求json信息
- def cityInfo(request, cid):
-
- data = AreaInfo.objects.filter(parentid=cid).values('id', 'title')
-
- return JsonResponse({'result': list(data)})
如果配置了mysql,就是mysql,配置了redis就从redis,获取到的fiter数据是QuerySet的,不能直接给JsonResponse转换,下面是StackoverFlow的答案
https://stackoverflow.com/questions/30243101/return-queryset-as-json
Simplest solution without any additional framework:
- results = PCT.objects.filter(code__startswith='a').values('id', 'name')
- return JsonResponse({'results': list(results)})
returns
{'results': [{'id': 1, 'name': 'foo'}, ...]}
or if you only need the values:
- results = PCT.objects.filter(code__startswith='a').values_list('id', 'name')
- return JsonResponse({'results': list(results)})
returns
{'results': [[1, 'foo'], ...]}
在urls.py中配置urlconf
- re_path(r'^area/$', views.area, name='area'),
- re_path(r'^area/(\d+)/$', views.areainfo, name='areainfo'),
- re_path(r'^city/(\d+)/$', views.cityInfo, name='cityinfo'),
主urls.py中包含此应用的url
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^booktest/', include('booktest.urls', namespace='booktest'))
- ]
定义模板index.html
- 在项目中的目录结构如图:
- 修改settings.py的TEMPLATES项,设置DIRS值
'DIRS': [os.path.join(BASE_DIR, 'templates')],
定义模板文件:包含三个select标签,分别存放省市区的信息
- <body>
- <!--选择器-->
- <select name="" id="pro">
- <option value="">请选择省</option>
- </select>
- <select name="" id="city">
- <option value="">请选择市</option>
- </select>
- <select name="" id="dis">
- <option value="">请选择区</option>
- </select>
-
- </body>
js代码
1.一进来请求省信息,get,直接执行
2.点击之后触发请求下一级
- <script src="/static/booktest/jquery-3.3.1.min.js"></script>
- <script>
- $(function () {
- //获取省
- pro = $('#pro')
-
- city = $('#city')
-
- dis = $('#dis')
- // get请求
- $.get('/booktest/area/0/', function (data) {
- $.each(data.result, function (index, item) {
- // console.log(index)
- pro.append('<option value="' + item.id + '">' + item.title + '</option>')
- })
- })
-
- // 获取市
- $('#pro').change(function () {
-
- // 选择当前城市的id
- console.log('/booktest/city/' + ($(this).val() || "0") + '/')
- $.get('/booktest/city/' + ($(this).val() || "0") + '/', function (data) {
- city.empty().append('<option value="">请选择市</option>')
- dis.empty().append('<option value="">请选择市</option>')
- $.each(data.result, function (index, item) {
- city.append('<option value="' + item.id + '">' + item.title + '</option>')
- })
- })
-
- })
-
- $('#city').change(function () {
- $.get('/booktest/city/' + ($(this).val() || "0") + '/', function (data) {
- dis.empty().append('<option value="">请选择区</option>')
- $.each(data.result, function (index, item) {
- dis.append('<option value="' + item.id + '">' + item.title + '</option>')
- })
- })
- })
-
-
- })
- </script>
创建正常项目简单流程梳理(mysql服务)
1.找个目录新建个文件夹放项目(例如桌面)

2.打开终端,cd到目录下,执行
- django-admin startproject taobao
-
-
- cd taobao/
-
- .
- ├── manage.py
- └── taobao
- ├── __init__.py
- ├── settings.py
- ├── urls.py
- └── wsgi.py
-
- 1 directory, 5 files
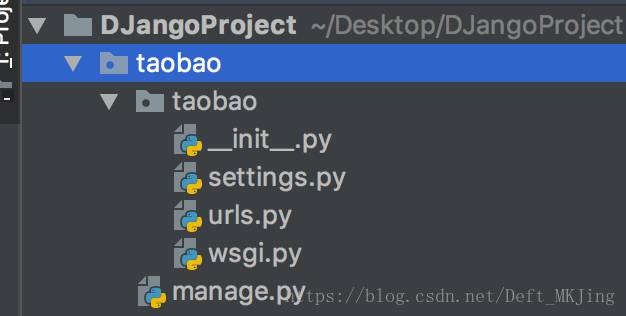
3.配置静态文件
先创建静态文件夹,static和templates,都在根级,和manage.py同级,在static中放静态文件

添加templates路径和static路径在根级的setting.py里面
- TEMPLATES = [
- {
- 'DIRS': [os.path.join(BASE_DIR,'templates')], // 添加路径
- ......
- },
- ]
-
- # Static files (CSS, JavaScript, Images)
- # https://docs.djangoproject.com/en/2.1/howto/static-files/
-
- STATIC_URL = '/static/'
-
- STATICFILES_DIRS=[
- os.path.join(BASE_DIR, 'static')
- ]
修改默认的sqllite为mysql
- # Database
- # https://docs.djangoproject.com/en/2.1/ref/settings/#databases
-
- DATABASES = {
- 'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'NAME': 'taobao',
- 'USER': 'root',
- 'PASSWORD': 'mikejing',
- 'HOST': 'localhost',
- 'PORT': '3306'
-
- }
- }
我们指定名字NAME为taobao的databases没有的话就需要自己先创建好,不然后面生成的models找不到数据库无法生成表
- mysql> show databases;
- +--------------------+
- | Database |
- +--------------------+
- | information_schema |
- | mysql |
- | performance_schema |
- | sys |
- | test2 |
- | test3 |
- +--------------------+
- 6 rows in set (0.00 sec)
-
- mysql> create database taobao charset=utf8;
- Query OK, 1 row affected, 1 warning (0.05 sec)
-
- mysql> show databases;
- +--------------------+
- | Database |
- +--------------------+
- | information_schema |
- | mysql |
- | performance_schema |
- | sys |
- | taobao |
- | test2 |
- | test3 |
- +--------------------+
- 7 rows in set (0.00 sec)
4.在taobao项目中创建app模块(用户模块为例)以及迁移
python3 manage.py startapp userinfo
在models.py里面创建模型类
- from django.db import models
-
-
- class UserInfo(models.Model):
- username = models.CharField(max_length=20)
- userpwd = models.CharField(max_length=40)
- useremail = models.CharField(max_length=30)
- usershow = models.CharField(max_length=20, default='')
- useraddress = models.CharField(max_length=100, default='')
- useryoubian = models.CharField(max_length=6, default='')
- userphone = models.CharField(max_length=11, default='')
在根级settings里面添加apps
- INSTALLED_APPS = [
- ......
- 'userinfo',
- ]
注意:当你修改成Mysql为数据库之后,由于不在是2.7 python,我们用的是3.6 python针对Mysql的包名都不同,直接执行直接报错,因此需要在根级taobao__init__文件中加入
- import pymysql
- pymysql.install_as_MySQLdb()
然后生成迁移脚本(sql语句而已 userinfo/migrations/0001_initial.py文件中),执行迁移 (执行)
- mintoudeMacBook-Pro-2:taobao mintou$ python3 manage.py makemigrations
- Migrations for 'userinfo':
- userinfo/migrations/0001_initial.py
- - Create model UserInfo
- mintoudeMacBook-Pro-2:taobao mintou$ python3 manage.py migrate
成功之后打开mysql查看即可
- mysql> desc userinfo_userinfo;
- +-------------+--------------+------+-----+---------+----------------+
- | Field | Type | Null | Key | Default | Extra |
- +-------------+--------------+------+-----+---------+----------------+
- | id | int(11) | NO | PRI | NULL | auto_increment |
- | username | varchar(20) | NO | | NULL | |
- | userpwd | varchar(40) | NO | | NULL | |
- | useremail | varchar(30) | NO | | NULL | |
- | usershow | varchar(20) | NO | | NULL | |
- | useraddress | varchar(100) | NO | | NULL | |
- | useryoubian | varchar(6) | NO | | NULL | |
- | userphone | varchar(11) | NO | | NULL | |
- +-------------+--------------+------+-----+---------+----------------+
- 8 rows in set (0.00 sec)
-
- mysql>
5.根据模块导入templates模板文件
首先根据模块在templates里面新建app对应的目录,然后html文件导入
6.编写views.py
- from django.shortcuts import render
-
-
- # Create your views here.
-
- def register(request):
- return render(request, 'userinfo/register.html')
7.配置urls即可访问
根级
- from django.contrib import admin
- from django.urls import path, re_path, include
-
- urlpatterns = [
- path('admin/', admin.site.urls),
- re_path(r'^user/', include('userinfo.urls', namespace='userinfo'))
- ]
模块级
- from django.urls import path, re_path
- from . import views
-
- app_name = 'userinfo'
-
-
- urlpatterns = [
- re_path(r'^register/', views.register, name='register')
- ]
Python服务器和Java服务器通信类比
Python的WSGI和Java的Servlet API
Python的WSGI
最近在学习使用Python进行WebServer的编程,发现WSGI(Web Server Gateway Interface)的概念。PythonWeb服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是Python应用程序或框架和Web服务器之间的一种接口,已经被广泛接受,它已基本达成它的可移植性方面的目标。WSGI 没有官方的实现,因为WSGI更像一个协议。只要遵照这些协议,WSGI应用(Application)都可以在任何服务器(Server)上运行,反之亦然。
如果没有WSGI,你选择的Python网络框架将会限制所能够使用的 Web 服务器。
这就意味着,你基本上只能使用能够正常运行的服务器与框架组合,而不能选择你希望使用的服务器或框架。
那么,你怎样确保可以在不修改 Web 服务器代码或网络框架代码的前提下,使用自己选择的服务器,并且匹配多个不同的网络框架呢?为了解决这个问题,就出现了PythonWeb 服务器网关接口(Web Server Gateway Interface,WSGI)。
WSGI的出现,让开发者可以将网络框架与 Web 服务器的选择分隔开来,不再相互限制。现在,你可以真正地将不同的 Web 服务器与网络开发框架进行混合搭配,选择满足自己需求的组合。例如,你可以使用Gunicorn或Nginx/uWSGI或Waitress服务器来运行Django、Flask或Pyramid应用。正是由于服务器和框架均支持WSGI,才真正得以实现二者之间的自由混合搭配。
Java的Servlet API
下面将类比Java来说明一下:
如果没有Java Servlet API,你选择的Java Web容器(Java Socket编程框架实现)将会限制所能够使用的Java Web框架(因为没有Java Servlet API,那么SpringMVC可能会实现一套SpringMVCHttpRequest和SpringMVCHttpResponse标准,Struts2可能会实现一套Struts2HttpRequest和Struts2HttpResponse标准,如果Tomcat只支持SpringMVC的API,那么选择Tomcat服务器就只能使用SpringMVC的Web框架来写服务端代码)。
这就意味着,你基本上只能使用能够正常运行的服务器(Tomcat)与框架(SpringMVC)组合,而不能选择你希望使用的服务器或框架(比如:我要换成Tomcat + Struts2的组合)。
注意:这里假设没有Java Servlet API,这样就相当于SpringMVC和Struts2可能都要自己实现一套Servlet封装HttpRequest和HttpResponse,这样从SpringMVC更换成Struts2就几乎需要重写服务器端的代码。为了解决这个问题,Java提出了Java Servlet API协议,让所有的Web服务框架都实现此Java Servlet API协议来和Java Web服务器(例如:Tomcat)交互,而复杂的网络连接控制等等都交由Java Web服务器来控制,Java Web服务器用Java Socket编程实现了复杂的网络连接管理。
详细说说Python的WSGI
Python Web 开发中,服务端程序可以分为两个部分,一是服务器程序,二是应用程序。前者负责把客户端请求接收,整理,后者负责具体的逻辑处理。为了方便应用程序的开发,我们把常用的功能封装起来,成为各种Web开发框架,例如 Django, Flask, Tornado。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。这样,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论对于服务器还是框架,都是不好的。对服务器来说,需要支持各种不同框架,对框架来说,只有支持它的服务器才能被开发出的应用使用。
这时候,标准化就变得尤为重要。我们可以设立一个标准,只要服务器程序支持这个标准,框架也支持这个标准,那么他们就可以配合使用。一旦标准确定,双方各自实现。这样,服务器可以支持更多支持标准的框架,框架也可以使用更多支持标准的服务器。
- 服务器端:
服务器必须将可迭代对象的内容传递给客户端,可迭代对象会产生bytestrings,必须完全完成每个bytestring后才能请求下一个。
- 应用程序:
服务器程序会在每次客户端的请求传来时,调用我们写好的应用程序,并将处理好的结果返回给客户端。
总结:
- Web Server Gateway Interface是Python编写Web业务统一接口。
- 无论多么复杂的Web应用程序,入口都是一个WSGI处理函数。
- Web应用程序就是写一个WSGI的处理函数,主要功能在于交互式地浏览和修改数据,生成动态Web内容,针对每个HTTP请求进行响应。
实现Python的Web应用程序能被访问的方式
要使 Python 写的程序能在 Web 上被访问,还需要搭建一个支持 Python 的 HTTP 服务器(也就是实现了WSGI server(WSGI协议)的Http服务器)。有如下几种方式:
- 可以自己使用Python Socket编程实现一个Http服务器
- 使用支持Python的开源的Http服务器(如:uWSGI,wsgiref,Mod_WSGI等等)。如果是使用Nginx,Apache,Lighttpd等Http服务器需要单独安装支持WSGI server的模块插件。
- 使用Python开源Web框架(如:Flask,Django等等)内置的Http服务器(Django自带的WSGI Server,一般测试使用)
Python标准库对WSGI的实现
wsgiref 是Python标准库给出的 WSGI 的参考实现。simple_server 这一模块实现了一个简单的 HTTP 服务器。
Python源码中的wsgiref的simple_server.py正好说明上面的分工情况,server的主要作用是接受client的请求,並把的收到的请求交給RequestHandlerClass处理,RequestHandlerClass处理完成后回传结果给client
uWSGI服务器
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。注意uwsgi是一种通信协议,而uWSGI是实现uwsgi协议和WSGI协议的Web服务器。
Django框架内置的WSGI Server服务器
Django的WSGIServer继承自wsgiref.simple_server.WSGIServer,而WSGIRequestHandler继承自wsgiref.simple_server.WSGIRequestHandler
之前说到的application,在Django中一般是django.core.handlers.wsgi.WSGIHandler对象,WSGIHandler继承自django.core.handlers.base.BaseHandler,这个是Django处理request的核心逻辑,它会创建一个WSGIRequest实例,而WSGIRequest是从http.HttpRequest继承而来
Python和Java的类比
Python和Java的服务器结构
- 独立WSGI server(实现了Http服务器功能) + Python Web应用程序
- 例如:Gunicorn,uWSGI + Django,Flask
- 独立Servlet引擎(Java应用服务器)(实现了Http服务器功能) + Java Web应用程序
- 例如:Jetty,Tomcat + SpringMVC,Struts2
Python和Java服务器共同点
WSGI server(例如Gunicorn和uWSGI)
- WSGI server服务器内部都有组建来实现Socket连接的创建和管理。
- WSGI server服务器都实现了Http服务器功能,能接受Http请求,并且通过Python Web应用程序处理之后返回动态Web内容。
Java应用服务器(Jetty和Tomcat)
- Java应用服务器内部都有Connector组件来实现Socket连接的创建和管理。
- Java应用服务器都实现了Http服务器功能,能接受Http请求,并且通过Java Web应用程序处理之后返回动态Web内容。
以上这段参考链接
DJango部署到阿里云
另外写了一篇部署到阿里云

