
梯度下降优化算法概述_j. duchi, e. hazan, and y. singer. adaptive subgra
赞
踩
最近学习cs231n的课程,其中到梯度下降这一块时发现好几种方法,都不太懂。故学习下这篇博文。同时,翻译出来,供大家学习参考。
Feel free to contact me or leave a comment.
错误与不足之处,望各位读者指正。
梯度下降优化算法概述
梯度下降是优化过程中最流行的方法之一并且并广泛运用在优化神经网络的过程中,同时,每一个state of art的深度学习库(如lasagne, caffe, kera)都包含了对多种梯度下降方法的实现。但是,这些算法常常像一个黑箱,很难在实际操作中对它们进行有点和不足的比较。
这篇博文的目的就是给大家提供不同梯度下降优化算法的直观理解,并帮助大家使用它们。我们首先了解梯度下降中的不同变体,然后简单的总结训练中的挑战。同时,我们将介绍最普遍的优化算法通过展示他们为解决这些挑战的动机,以及它们怎么引领update rule的导数。我们也将粗略的讨论并行和分布式的梯度下降优化算法和架构。最后,我们将探讨到对梯度下降优化算法有利的其它附加策略。
梯度下降是通过在目标函数ΔJ(θ)的梯度方向相反的方向更新参数最小化目标函数J(θ)的一种方法。而J(θ)是通过一个模型的参数θ参数化。而参数η即学习率决定我们迈向(局部)最小值时每一步的步长。换句话说,梯度下降就是我们沿着由目标函数生成的斜坡的斜率方向一路往下直到走到谷底。如果大家不熟悉梯度下降,可从这里http://cs231n.github.io/optimization-1/找到一个优化神经网络很好的入门材料。
梯度下降变体
有三种梯度下降的变体,每种只是用来计算目标函数梯度的数据量不同。依据数据量,我们在参数更新的准确率和执行更新所花的时间上做了权衡。
批梯度下降
Vanilla gradient descent又名批梯度下降。计算损失函数关于参数θ在整个数据集上的梯度。
正因为我们需要计算整个数据集的梯度来执行一次参数更新,批梯度下降将会非常缓慢,同时,对于大于内存容量的数据集是难以计算的(intractable)。
用代码表示为:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad- 1
- 2
- 3
对一个预定义的训练epoch数,我们首先计算整个数据集上对于我们参数向量params的损失函数的梯度向量params_grad。注意,那些个state of art 的深度学习库对有些参数提供了自动求导,可以很高效的计算梯度。如果自己实现梯度求导,那么进行梯度检查会是一个好主意(这里http://cs231n.github.io/neural-networks-3/对怎么检查梯度有一些好的建议)。
然后,我们用学习率决定一次更新的大小在梯度方向更新我们的参数。批梯度下降可以保证收敛到全局最小的凸误差曲面及局部最小的非凸误差曲面。
随机梯度下降
相比之下,随机梯度下降(SGD)进行一次参数更新对每一个训练样本xi及其类标yi.
批梯度下降对于大数据集是一个很冗余的计算,因为它在每次更新参数前对相似的数据集重新计算梯度。SGD通过一次进行一次更新丢弃了这种冗余(SGD does away with this redundancy by performing one update at a time.)。因此,SGD通常比BGD快得多,也能用在在线学习上(learn online)。
SGD在高方差内频繁的更新导致目标函数的波动严重,如图1所示。
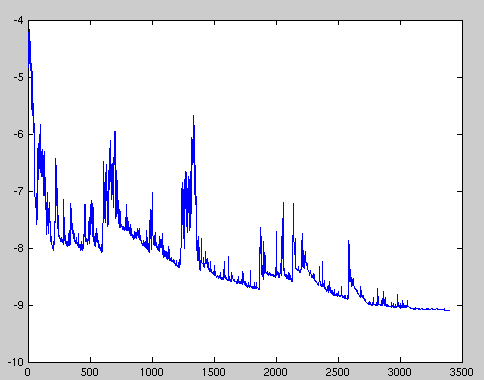
Image 1: SGD fluctuation (Source: Wikipedia)
然而,BGD收敛到参数化下的盆地最小值(converges to the minimum of the basin the parameters are placed in),SGB的波动,一方面,使得其能够跳到新的潜在的更好的局部最优处;另一方面,这最终也复杂化了到局部最优的收敛(this ultimately complicates convergence to the exact minimum)因为SGD会一直超调(overshooting)。然而,研究表明当我们逐步降低学习率时,SGD和BGD有着同样的收敛能力,几乎同样分别收敛到非凸和凸曲面的局部和全局最优。
其代码段简单在训练样本下的增加了一个循环,计算出对于每个样本下的梯度。注意我们之所以每次epoch都shuffle了训练集,其原因在这里。
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad- 1
- 2
- 3
- 4
- 5
Mini批梯度下降
MbGD最终吸取了两个方面的长处,它对每一个n个训练样本的mini-batch进行一次参数更新。
这样的话,它1)减少了参数更新了方差,引导向更稳定的收敛,2)可以使用和state of art深度学习库一样高度优化的矩阵操作来高效计算每一个mini-batch的梯度。常用的mini-batch在50-256之间,但是根据应用场景的不同而不同。MbGD是训练神经网络时的一个典型的选择,同时,SGD也常和MbGD一起使用。注意,在余下这篇博文的SGD方法的各种改进中,为了简便,我们省去了参数 。
在代码中,我们现在迭代mini-batch为50个样本,而不是整个样本集。
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad- 1
- 2
- 3
- 4
- 5
Challenges
然而,批梯度下降,并不保证好的收敛,同时,还产生了一些需要解决的挑战。
选择合适的学习率;学习率太小导致收敛极其缓慢,然而学习率太大又阻碍收敛,导致损失函数在最小值附近波动甚至发散。
Learning rate schedules [11] try to adjust the learning rate during training by e.g. annealing, i.e. reducing the learning rate according to a pre-defined schedule or when the change in objective between epochs falls below a threshold. These schedules and thresholds, however, have to be defined in advance and are thus unable to adapt to a dataset’s characteristics [10].
附加的,同一个学习率应用到所有的参数更新上,如果我们的数据是稀疏的,特征有着明显的频率差异,我们可能不会想着同样程度的更新这些特征的参数,而是对很少出现的特征进行一个更大的更新。
另一个在神经网络上最小化非凸误差函数的关键性的难点就是避免优化到无数个次优局部最小值(numerous suboptimal local numerous suboptimal local minima)。Dauphin et al. [19]争论到,真正的难点并不在局部最优而是在鞍点(saddle point)的地方,例如,这些点在一个维度最大,而在另一个维度最小。这些鞍点通常被一个同样错误的高原包围,这让SGB逃出来变得异常很难,因为梯度在所有的维度都接近于0.
Gradient descent optimization algorithms
接下来,我们将讲解来深度学习中常用的处理前面难点的算法。我们不会讨论像牛顿法这样在实践中在高维数据集上不可行的二阶导数方法。
Momentum
SGD很难navigate ravines, 比如那些一个维度比另外的维度弯曲的多的区域[1],恰恰,这些区域在局部最优的周围是很常见的。在这种情况下SGD只有像图2所示的那样,慢慢的从底部向局部最优前进才能跨过ravines。
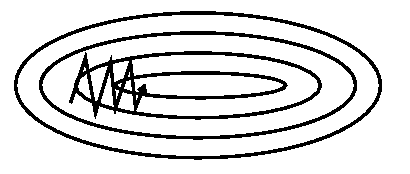
Image 2: SGD without momentum
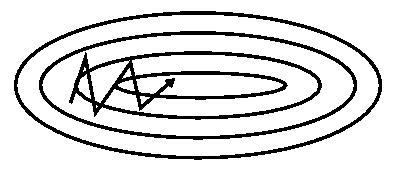
Image 3: SGD with momentum
Momentum [2]是一个加速在相关方向和阻尼震荡的SGD方法,如图3所示。它通过加上之前向量乘以系数γ来更新向量。
注意:一些编程实现中交换等式的符号。该系数常设置为0.9这样的值。
基本上,使用momentum时,我们把一个球推到山脚下,随着越往下滚球的动能越大,变得越来越快(直到它达到底端速度,如果有空气阻力的话,比如γ<1)。我们的参数更新也一样,动能项在那些梯度在同一个方向的维度上增加,并且在那些梯度改变的维度上的更新次数会减少,最终, 我们得到更快的收敛和减少震荡。
Nesterov accelerated gradient
然后,一个小球滚下小坡会盲目的沿着斜坡向下,这令人不怎么满意。我们希望球智能一点,一个有着知道要去哪里的标定的球,这样,它会在斜坡再次向上时缓慢下来。
Nesterov accelerated gradient (NAG) [7]是一个给我们的动能项这种预测能力的方法。我们知道我们将使用动能项 来移动参数θ。计算 给我下次梯度的近似(全部更新时梯度消失),粗略告诉我们参数将怎么更新。我们现在可以高效的看得更远通过计算近似位置的梯度而不是当前参数θ的梯度。
我们这里还将γ设置为0.9。动能项首先计算当前梯度(图4中小的蓝色向量)接着在updated accumulated gradient的方向上跳跃一大步(大的蓝色向量)。NAG首先在之前的梯度方向(previous accumulated gradient)跳一大步(棕色向量),计算梯度然后校正(绿色向量)。这种预先(anticipatory)更新预防止我们走的太快,作用在增加反应性(responsiveness)上,这也显著的增加了RNNs在大量任务上的performance.
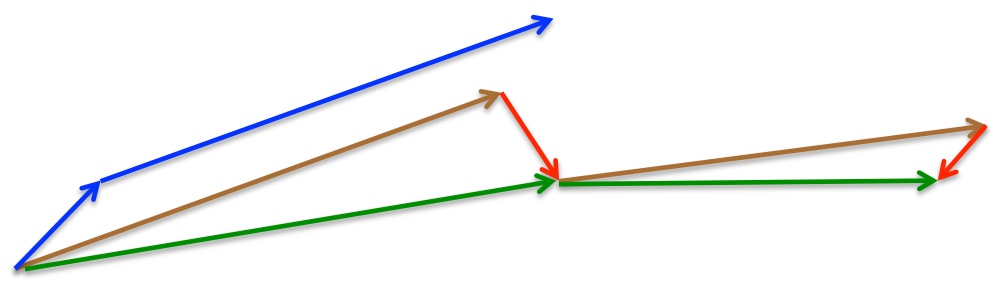
Image 4: Nesterov update (Source: G. Hinton’s lecture 6c)
Refer to here for another explanation about the intuitions behind NAG, while Ilya Sutskever gives a more detailed overview in his PhD thesis [9].
我们现在可以对误差函数的斜率适应我们的更新,反过来也加速了SGD。我们更希望对于每一个独立的参数,能够根据他们的重要性的大小更新他们,使他们变大或者变小。
Adagrad
Adadelta
RMSprop
Adam
Visualization of algorithms
Which optimizer to use?
Parallelizing and distributing SGD
Hogwild!
Downpour SGD
Delay-tolerant Algorithms for SGD
TensorFlow
Elastic Averaging SGD
Additional strategies for optimizing SGD
Shuffling and Curriculum Learning
Batch normalization
Early stopping
Gradient noise
Conclusion
Acknowledgements
Thanks to Denny Britz and Cesar Salgado for reading drafts of this post and providing suggestions.
References
- Sutton, R. S. (1986). Two problems with backpropagation and other steepest-descent learning procedures for networks. Proc. 8th Annual Conf. Cognitive Science Society.
- Qian, N. (1999). On the momentum term in gradient descent learning algorithms. Neural Networks : The Official Journal of the International Neural Network Society, 12(1), 145–151. http://doi.org/10.1016/S0893-6080(98)00116-6
- Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121–2159. Retrieved from http://jmlr.org/papers/v12/duchi11a.html
- Dean, J., Corrado, G. S., Monga, R., Chen, K., Devin, M., Le, Q. V, … Ng, A. Y. (2012). Large Scale Distributed Deep Networks. NIPS 2012: Neural Information Processing Systems, 1–11. http://doi.org/10.1109/ICDAR.2011.95
- Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543. http://doi.org/10.3115/v1/D14-1162
- Zeiler, M. D. (2012). ADADELTA: An Adaptive Learning Rate Method. Retrieved from http://arxiv.org/abs/1212.5701
- Nesterov, Y. (1983). A method for unconstrained convex minimization problem with the rate of convergence o(1/k2). Doklady ANSSSR (translated as Soviet.Math.Docl.), vol. 269, pp. 543– 547.
- Bengio, Y., Boulanger-Lewandowski, N., & Pascanu, R. (2012). Advances in Optimizing Recurrent Networks. Retrieved from http://arxiv.org/abs/1212.0901
- Sutskever, I. (2013). Training Recurrent neural Networks. PhD Thesis.
- Darken, C., Chang, J., & Moody, J. (1992). Learning rate schedules for faster stochastic gradient search. Neural Networks for Signal Processing II Proceedings of the 1992 IEEE Workshop, (September), 1–11. http://doi.org/10.1109/NNSP.1992.253713
- H. Robinds and S. Monro, “A stochastic approximation method,” Annals of Mathematical Statistics, vol. 22, pp. 400–407, 1951.
- Mcmahan, H. B., & Streeter, M. (2014). Delay-Tolerant Algorithms for Asynchronous Distributed Online Learning. Advances in Neural Information Processing Systems (Proceedings of NIPS), 1–9.
- Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., … Zheng, X. (2015). TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems.
- Zhang, S., Choromanska, A., & LeCun, Y. (2015). Deep learning with Elastic Averaging SGD. Neural Information Processing Systems Conference (NIPS 2015), 1–24. Retrieved from http://arxiv.org/abs/1412.6651
- Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13.
- Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (2009). Curriculum learning. Proceedings of the 26th Annual International Conference on Machine Learning, 41–48. http://doi.org/10.1145/1553374.1553380
- Zaremba, W., & Sutskever, I. (2014). Learning to Execute, 1–25. Retrieved from http://arxiv.org/abs/1410.4615
- Ioffe, S., & Szegedy, C. (2015). Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv Preprint arXiv:1502.03167v3.
- Dauphin, Y., Pascanu, R., Gulcehre, C., Cho, K., Ganguli, S., & Bengio, Y. (2014). Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. arXiv, 1–14. Retrieved from http://arxiv.org/abs/1406.2572
- Sutskever, I., & Martens, J. (2013). On the importance of initialization and momentum in deep learning. http://doi.org/10.1109/ICASSP.2013.6639346
- Neelakantan, A., Vilnis, L., Le, Q. V., Sutskever, I., Kaiser, L., Kurach, K., & Martens, J. (2015). Adding Gradient Noise Improves Learning for Very Deep Networks, 1–11. Retrieved from http://arxiv.org/abs/1511.06807
- LeCun, Y., Bottou, L., Orr, G. B., & Müller, K. R. (1998). Efficient BackProp. Neural Networks: Tricks of the Trade, 1524, 9–50. http://doi.org/10.1007/3-540-49430-8_2
- Niu, F., Recht, B., Christopher, R., & Wright, S. J. (2011). Hogwild ! : A Lock-Free Approach to Parallelizing Stochastic Gradient Descent, 1–22.


{kind=link}