
- 1React + antd 中 的 CheckBox 实现限制复选框可选的个数_antd复选框只能选一个
- 2MPU6050传感器—姿态检测_姿态传感器的工作原理
- 3【Android】Room数据库的简单使用方法_android room数据库
- 414、切片之道:Go语言中的灵活数据处理艺术
- 5【机器学习】期望最大化(EM)算法
- 6STM32存储左右互搏 模拟U盘桥接SPI总线FATS读写FLASH W25QXX_stm32 u盘读取
- 7不存在UnityEngine.XR.ARFoundation命名空间的解决办法
- 82023-2024年最值得选的Java毕业设计选题大全:500个热门选题推荐✅_java 毕业设计
- 9快速排序之“挖坑法”_分治挖坑法
- 10测试DBLINK触发器事务_pg 触发器 dblink perform
2024最新java详细学习路线及路线图(超详细)_java 2024学习路线
赞
踩
printListRev(head.next);
System.out.println(head.item);
}
}
代码 单链表反转
//单链表反转 主要是逐一改变两个节点间的链接关系来完成
staticNode revList(Node head) {
if(head ==null) {
returnnull;
}
Node nodeResult =null;
Node nodePre =null;
Node current = head;
while(current !=null) {
Node nodeNext = current.next;
if(nodeNext ==null) {
nodeResult = current;
}
current.next = nodePre;
nodePre = current;
current = nodeNext;
}
returnnodeResult;
}
上面的几段代码主要展示了链表的几个基本操作,还有很多像获取指定元素,移除元素等操作大家可以自己完成,写这些代码的时候一定要理清节点之间关系,这样才不容易出错。
链表的实现还有其它的方式,常见的有循环单链表,双向链表,循环双向链表。 **循环单链表** 主要是链表的最后一个节点指向第一个节点,整体构成一个链环。 **双向链表** 主要是节点中包含两个指针部分,一个指向前驱元,一个指向后继元,JDK中LinkedList集合类的实现就是双向链表。** 循环双向链表** 是最后一个节点指向第一个节点。
[二、栈与队列]
栈和队列也是比较常见的数据结构,它们是比较特殊的线性表,因为对于栈来说,访问、插入和删除元素只能在栈顶进行,对于队列来说,元素只能从队列尾插入,从队列头访问和删除。
栈
栈是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫作栈顶,对栈的基本操作有push(进栈)和pop(出栈),前者相当于插入,后者相当于删除最后一个元素。栈有时又叫作LIFO(Last In First Out)表,即后进先出。
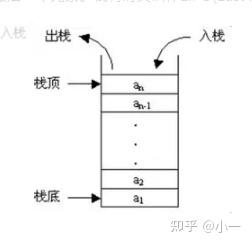
栈的模型
下面我们看一道经典题目,加深对栈的理解。

关于栈的一道经典题目
上图中的答案是C,其中的原理可以好好想一想。
因为栈也是一个表,所以任何实现表的方法都能实现栈。我们打开JDK中的类Stack的源码,可以看到它就是继承类Vector的。当然,Stack是Java2前的容器类,现在我们可以使用LinkedList来进行栈的所有操作。
队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。

队列示意图
我们可以使用链表来实现队列,下面代码简单展示了利用LinkedList来实现队列类。
代码9 简单实现队列类
publicclassMyQueue {
privateLinkedListlist=newLinkedList<>();
// 入队
publicvoidenqueue(E e){
list.addLast(e);
}
// 出队
publicEdequeue(){
returnlist.removeFirst();
}
}
普通的队列是一种先进先出的数据结构,而优先队列中,元素都被赋予优先级。当访问元素的时候,具有最高优先级的元素最先被删除。优先队列在生活中的应用还是比较多的,比如医院的急症室为病人赋予优先级,具有最高优先级的病人最先得到治疗。在Java集合框架中,类PriorityQueue就是优先队列的实现类,具体大家可以去阅读源码。
[三、树与二叉树]
树型结构是一类非常重要的非线性数据结构,其中以树和二叉树最为常用。在介绍二叉树之前,我们先简单了解一下树的相关内容。
树
** 树 是由n(n>=1)个有限节点组成一个具有层次关系的集合。它具有以下特点:每个节点有零个或多个子节点;没有父节点的节点称为 根 节点;每一个非根节点有且只有一个 父节点 **;除了根节点外,每个子节点可以分为多个不相交的子树。
树的结构
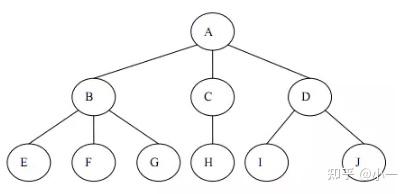
二叉树基本概念
定义
二叉树是每个节点最多有两棵子树的树结构。通常子树被称作“左子树”和“右子树”。二叉树常被用于实现二叉查找树和二叉堆。
相关性质
二叉树的每个结点至多只有2棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。
二叉树的第i层至多有2(i-1)个结点;深度为k的二叉树至多有2k-1个结点。
一棵深度为k,且有2^k-1个节点的二叉树称之为满二叉树 ;
深度为k,有n个节点的二叉树,当且仅当其每一个节点都与深度为k的满二叉树中,序号为1至n的节点对应时,称之为 完全二叉树 。
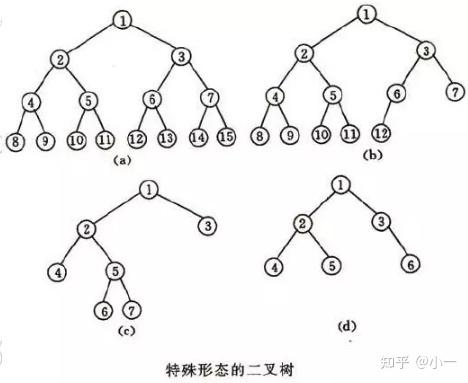
三种遍历方法
在二叉树的一些应用中,常常要求在树中查找具有某种特征的节点,或者对树中全部节点进行某种处理,这就涉及到二叉树的遍历。二叉树主要是由3个基本单元组成,根节点、左子树和右子树。如果限定先左后右,那么根据这三个部分遍历的顺序不同,可以分为先序遍历、中序遍历和后续遍历三种。
(1) 先序遍历 若二叉树为空,则空操作,否则先访问根节点,再先序遍历左子树,最后先序遍历右子树。 (2) 中序遍历 若二叉树为空,则空操作,否则先中序遍历左子树,再访问根节点,最后中序遍历右子树。(3) 后序遍历 若二叉树为空,则空操作,否则先后序遍历左子树访问根节点,再后序遍历右子树,最后访问根节点。
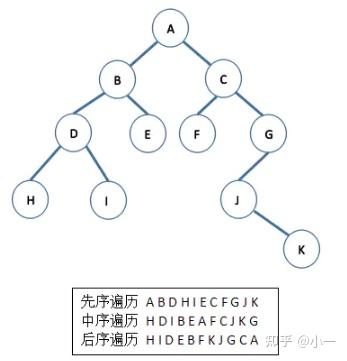
给定二叉树写出三种遍历结果
树和二叉树的区别
(1) 二叉树每个节点最多有2个子节点,树则无限制。 (2) 二叉树中节点的子树分为左子树和右子树,即使某节点只有一棵子树,也要指明该子树是左子树还是右子树,即二叉树是有序的。 (3) 树决不能为空,它至少有一个节点,而一棵二叉树可以是空的。
上面我们主要对二叉树的相关概念进行了介绍,下面我们将从二叉查找树开始,介绍二叉树的几种常见类型,同时将之前的理论部分用代码实现出来。
二叉查找树
定义
二叉查找树就是二叉排序树,也叫二叉搜索树。二叉查找树或者是一棵空树,或者是具有下列性质的二叉树: (1) 若左子树不空,则左子树上所有结点的值均小于它的根结点的值;(2) 若右子树不空,则右子树上所有结点的值均大于它的根结点的值;(3) 左、右子树也分别为二叉排序树;(4) 没有键值相等的结点。
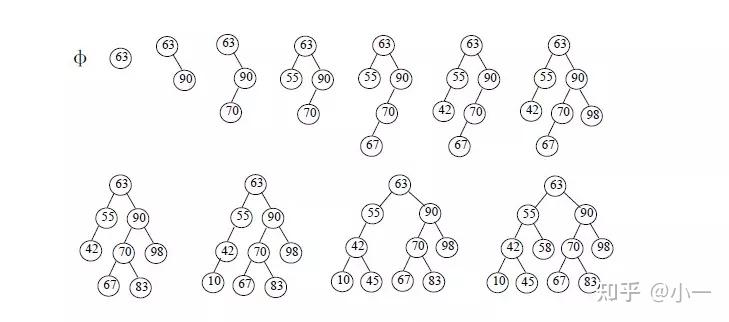
典型的二叉查找树的构建过程
性能分析
对于二叉查找树来说,当给定值相同但顺序不同时,所构建的二叉查找树形态是不同的,下面看一个例子。
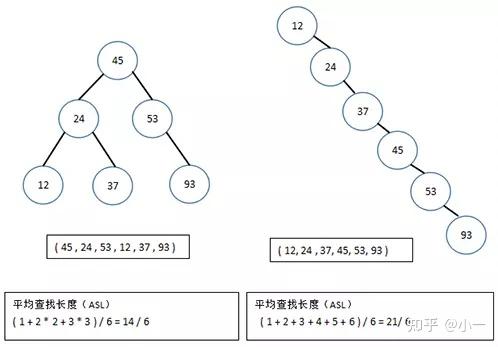
不同形态平衡二叉树的ASL不同
可以看到,含有n个节点的二叉查找树的平均查找长度和树的形态有关。最坏情况下,当先后插入的关键字有序时,构成的二叉查找树蜕变为单支树,树的深度为n,其平均查找长度(n+1)/2(和顺序查找相同),最好的情况是二叉查找树的形态和折半查找的判定树相同,其平均查找长度和log2(n)成正比。平均情况下,二叉查找树的平均查找长度和logn是等数量级的,所以为了获得更好的性能,通常在二叉查找树的构建过程需要进行“平衡化处理”,之后我们将介绍平衡二叉树和红黑树,这些均可以使查找树的高度为O(log(n))。
代码10 二叉树的节点
classTreeNode {
E element;
TreeNode left;
TreeNode right;
publicTreeNode(E e){
element = e;
}
}
二叉查找树的三种遍历都可以直接用递归的方法来实现:
代码12 先序遍历
protectedvoidpreorder(TreeNode root){
if(root ==null)
return;
System.out.println(root.element +" ");
preorder(root.left);
preorder(root.right);
}
代码13 中序遍历
protectedvoidinorder(TreeNode root){
if(root ==null)
return;
inorder(root.left);
System.out.println(root.element +" ");
inorder(root.right);
}
代码14 后序遍历
protectedvoidpostorder(TreeNode root){
if(root ==null)
return;
postorder(root.left);
postorder(root.right);
System.out.println(root.element +" ");
}
代码15 二叉查找树的简单实现
/**
- @author JackalTsc
*/
publicclassMyBinSearchTree<EextendsComparable>{
// 根
privateTreeNode root;
// 默认构造函数
publicMyBinSearchTree() {
}
// 二叉查找树的搜索
public boolean search(Ee) {
TreeNode current = root;
while(current !=null) {
if(e.compareTo(current.element) <0) {
current = current.left;
}elseif(e.compareTo(current.element) >0) {
current = current.right;
}else{
returntrue;
}
}
returnfalse;
}
// 二叉查找树的插入
public boolean insert(Ee) {
// 如果之前是空二叉树 插入的元素就作为根节点
if(root ==null) {
root = createNewNode(e);
}else{
// 否则就从根节点开始遍历 直到找到合适的父节点
TreeNode parent =null;
TreeNode current = root;
while(current !=null) {
if(e.compareTo(current.element) <0) {
parent = current;
current = current.left;
}elseif(e.compareTo(current.element) >0) {
parent = current;
current = current.right;
}else{
returnfalse;
}
}
// 插入
if(e.compareTo(parent.element) <0) {
parent.left = createNewNode(e);
}else{
parent.right = createNewNode(e);
}
}
returntrue;
}
// 创建新的节点
protectedTreeNode createNewNode(Ee) {
returnnewTreeNode(e);
}
}
// 二叉树的节点
classTreeNode<EextendsComparable>{
Eelement;
TreeNode left;
TreeNode right;
publicTreeNode(Ee) {
element = e;
}
}
上面的代码15主要展示了一个自己实现的简单的二叉查找树,其中包括了几个常见的操作,当然更多的操作还是需要大家自己去完成。因为在二叉查找树中删除节点的操作比较复杂,所以下面我详细介绍一下这里。
二叉查找树中删除节点分析
要在二叉查找树中删除一个元素,首先需要定位包含该元素的节点,以及它的父节点。假设current指向二叉查找树中包含该元素的节点,而parent指向current节点的父节点,current节点可能是parent节点的左孩子,也可能是右孩子。这里需要考虑两种情况:
current节点没有左孩子,那么只需要将patent节点和current节点的右孩子相连。
current节点有一个左孩子,假设rightMost指向包含current节点的左子树中最大元素的节点,而parentOfRightMost指向rightMost节点的父节点。那么先使用rightMost节点中的元素值替换current节点中的元素值,将parentOfRightMost节点和rightMost节点的左孩子相连,然后删除rightMost节点。
// 二叉搜索树删除节点
publicboolean delete(Ee) {
TreeNode parent = null;
TreeNode current = root;
// 找到要删除的节点的位置
while(current != null) {
if(e.compareTo(current.element) <0) {
parent = current;
current = current.left;
}elseif(e.compareTo(current.element) >0) {
parent = current;
current = current.right;
}else{
break;
}
}
// 没找到要删除的节点
if(current == null) {
returnfalse;
}
// 考虑第一种情况
if(current.left== null) {
if(parent == null) {
root = current.right;
}else{
if(e.compareTo(parent.element) <0) {
parent.left= current.right;
}else{
parent.right= current.right;
}
}
}else{// 考虑第二种情况
TreeNode parentOfRightMost = current;
TreeNode rightMost = current.left;
// 找到左子树中最大的元素节点
while(rightMost.right!= null) {
parentOfRightMost = rightMost;
rightMost = rightMost.right;
}
// 替换
current.element = rightMost.element;
// parentOfRightMost和rightMost左孩子相连
if(parentOfRightMost.right== rightMost) {
parentOfRightMost.right= rightMost.left;
}else{
parentOfRightMost.left= rightMost.left;
}
}
returntrue;
}
平衡二叉树
平衡二叉树又称AVL树,它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。
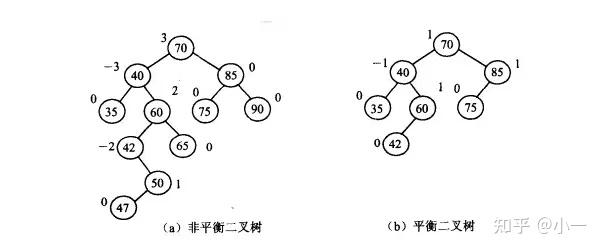
平衡二叉树
AVL树是最先发明的自平衡二叉查找树算法。在AVL中任何节点的两个儿子子树的高度最大差别为1,所以它也被称为高度平衡树,n个结点的AVL树最大深度约1.44log2n。查找、插入和删除在平均和最坏情况下都是O(log n)。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
红黑树
红黑树是平衡二叉树的一种,它保证在最坏情况下基本动态集合操作的事件复杂度为O(log n)。红黑树和平衡二叉树区别如下:(1) 红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。(2) 平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
[四、图]
简介
图是一种较线性表和树更为复杂的数据结构,在线性表中,数据元素之间仅有线性关系,在树形结构中,数据元素之间有着明显的层次关系,而在图形结构中,节点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。图的应用相当广泛,特别是近年来的迅速发展,已经渗入到诸如语言学、逻辑学、物理、化学、电讯工程、计算机科学以及数学的其他分支中。
相关阅读
因为图这部分的内容还是比较多的,这里就不详细介绍了,有需要的可以自己搜索相关资料。
(1) [《百度百科对图的介绍》]
(2) [《数据结构之图(存储结构、遍历)》]
这篇文章是常见数据结构与算法整理总结的下篇,上一篇主要是对常见的数据结构进行集中总结,这篇主要是总结一些常见的算法相关内容,文章中如有错误,欢迎指出。
一、概述
二、查找算法
三、排序算法
四、其它算法
五、常见算法题
六、总结
[一、概述]
以前看到这样一句话,语言只是工具,算法才是程序设计的灵魂。的确,算法在计算机科学中的地位真的很重要,在很多大公司的笔试面试中,算法掌握程度的考察都占据了很大一部分。不管是为了面试还是自身编程能力的提升,花时间去研究常见的算法还是很有必要的。下面是自己对于算法这部分的学习总结。
算法简介
算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。对于同一个问题的解决,可能会存在着不同的算法,为了衡量一个算法的优劣,提出了空间复杂度与时间复杂度这两个概念。
时间复杂度
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数f(n),算法的时间度量记为 ** T(n) = O(f(n)) **,它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐近时间复杂度,简称时间复杂度。这里需要重点理解这个增长率。
举个例子,看下面3个代码:
1、{++x;}
2、for(i =1; i <= n; i++) { ++x; }
3、for(j =1; j <= n; j++)
for(j =1; j <= n; j++)
{ ++x; }
上述含有 ++x操作的语句的频度分别为1、n、n^2,
假设问题的规模扩大了n倍,3个代码的增长率分别是1、n、n^2
它们的时间复杂度分别为O(1)、O(n )、O(n^2)
空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量。
[二、查找算法]
查找和排序是最基础也是最重要的两类算法,熟练地掌握这两类算法,并能对这些算法的性能进行分析很重要,这两类算法中主要包括二分查找、快速排序、归并排序等等。
顺序查找
顺序查找又称线性查找。它的过程为:从查找表的最后一个元素开始逐个与给定关键字比较,若某个记录的关键字和给定值比较相等,则查找成功,否则,若直至第一个记录,其关键字和给定值比较都不等,则表明表中没有所查记录查找不成功,它的缺点是效率低下。
二分查找
简介
二分查找又称折半查找,对于有序表来说,它的优点是比较次数少,查找速度快,平均性能好。
二分查找的基本思想是将n个元素分成大致相等的两部分,取a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止;如果x<a[n/2],则只要在数组a的左半部分继续搜索x,如果x>a[n/2],则只要在数组a的右半部搜索x。
二分查找的时间复杂度为O(logn)
实现
//给定有序查找表array 二分查找给定的值data
//查找成功返回下标 查找失败返回-1
staticintfunBinSearch(int[]array,intdata){
intlow =0;
inthigh =array.length -1;
while(low <= high) {
intmid = (low + high) /2;
if(data ==array[mid]) {
returnmid;
}elseif(data
high = mid -1;
}else{
low = mid +1;
}
}
return-1;
}
[三、排序算法]
排序是计算机程序设计中的一种重要操作,它的功能是将一个数据元素(或记录)的任意序列,重新排列成一个按关键字有序的序列。下面主要对一些常见的排序算法做介绍,并分析它们的时空复杂度。
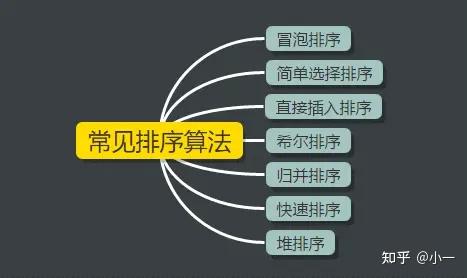
常见排序算法
常见排序算法性能比较:
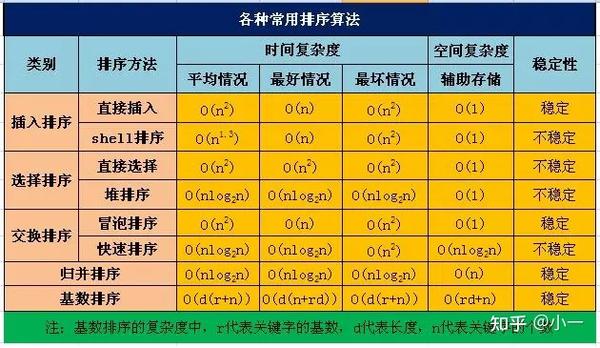
图片来自网络
上面这张表中有稳定性这一项,排序的稳定性是指如果在排序的序列中,存在前后相同的两个元素的话,排序前和排序后他们的相对位置不发生变化。
下面从冒泡排序开始逐一介绍。
冒泡排序
简介
冒泡排序的基本思想是:设排序序列的记录个数为n,进行n-1次遍历,每次遍历从开始位置依次往后比较前后相邻元素,这样较大的元素往后移,n-1次遍历结束后,序列有序。
例如,对序列(3,2,1,5)进行排序的过程是:共进行3次遍历,第1次遍历时先比较3和2,交换,继续比较3和1,交换,再比较3和5,不交换,这样第1次遍历结束,最大值5在最后的位置,得到序列(2,1,3,5)。第2次遍历时先比较2和1,交换,继续比较2和3,不交换,第2次遍历结束时次大值3在倒数第2的位置,得到序列(1,2,3,5),第3次遍历时,先比较1和2,不交换,得到最终有序序列(1,2,3,5)。
需要注意的是,如果在某次遍历中没有发生交换,那么就不必进行下次遍历,因为序列已经有序。
** 实现**
// 冒泡排序 注意 flag 的作用
staticvoidfunBubbleSort(int[]array){
boolean flag =true;
for(inti =0; i
flag =false;
for(intj =0; j
if(array[j] >array[j +1]) {
inttemp =array[j];
array[j] =array[j +1];
array[j +1] = temp;
flag =true;
}
}
}
for(inti =0; i
System.out.println(array[i]);
}
}
分析
最佳情况下冒泡排序只需一次遍历就能确定数组已经排好序,不需要进行下一次遍历,所以最佳情况下,时间复杂度为** O(n) **。
最坏情况下冒泡排序需要n-1次遍历,第一次遍历需要比较n-1次,第二次遍历需要n-2次,…,最后一次需要比较1次,最差情况下时间复杂度为** O(n^2) **。
简单选择排序
简介
简单选择排序的思想是:设排序序列的记录个数为n,进行n-1次选择,每次在n-i+1(i = 1,2,…,n-1)个记录中选择关键字最小的记录作为有效序列中的第i个记录。
例如,排序序列(3,2,1,5)的过程是,进行3次选择,第1次选择在4个记录中选择最小的值为1,放在第1个位置,得到序列(1,3,2,5),第2次选择从位置1开始的3个元素中选择最小的值2放在第2个位置,得到有序序列(1,2,3,5),第3次选择因为最小的值3已经在第3个位置不需要操作,最后得到有序序列(1,2,3,5)。
实现
staticvoidfunSelectionSort(int[]array){
for(inti =0; i
intmink = i;
// 每次从未排序数组中找到最小值的坐标
for(intj = i +1; j
if(array[j]
mink = j;
}
}
// 将最小值放在最前面
if(mink != i) {
inttemp =array[mink];
array[mink] =array[i];
array[i] = temp;
}
}
for(inti =0; i
System.out.print(array[i] +" ");
}
}
分析
简单选择排序过程中需要进行的比较次数与初始状态下待排序的记录序列的排列情况** 无关**。当i=1时,需进行n-1次比较;当i=2时,需进行n-2次比较;依次类推,共需要进行的比较次数是(n-1)+(n-2)+…+2+1=n(n-1)/2,即进行比较操作的时间复杂度为** O(n^2) ,进行移动操作的时间复杂度为 O(n) 。总的时间复杂度为 O(n^2) **。
最好情况下,即待排序记录初始状态就已经是正序排列了,则不需要移动记录。最坏情况下,即待排序记录初始状态是按第一条记录最大,之后的记录从小到大顺序排列,则需要移动记录的次数最多为3(n-1)。
简单选择排序是不稳定排序。
直接插入排序
简介
直接插入的思想是:是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增1的有序表。
例如,排序序列(3,2,1,5)的过程是,初始时有序序列为(3),然后从位置1开始,先访问到2,将2插入到3前面,得到有序序列(2,3),之后访问1,找到合适的插入位置后得到有序序列(1,2,3),最后访问5,得到最终有序序列(1,2,3,5).
实现
staticvoidfunDInsertSort(int[]array){
intj;
for(inti =1; i
inttemp =array[i];
j = i -1;
while(j >-1&& temp
array[j +1] =array[j];
j–;
}
array[j +1] = temp;
}
for(inti =0; i
System.out.print(array[i] +" ");
}
}
分析
最好情况下,当待排序序列中记录已经有序时,则需要n-1次比较,不需要移动,时间复杂度为** O(n) 。最差情况下,当待排序序列中所有记录正好逆序时,则比较次数和移动次数都达到最大值,时间复杂度为 O(n^2) 。平均情况下,时间复杂度为 O(n^2) **。
希尔排序
希尔排序又称“缩小增量排序”,它是基于直接插入排序的以下两点性质而提出的一种改进:(1) 直接插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。(2) 直接插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
归并排序
简介
归并排序是分治法的一个典型应用,它的主要思想是:将待排序序列分为两部分,对每部分递归地应用归并排序,在两部分都排好序后进行合并。
例如,排序序列(3,2,8,6,7,9,1,5)的过程是,先将序列分为两部分,(3,2,8,6)和(7,9,1,5),然后对两部分分别应用归并排序,第1部分(3,2,8,6),第2部分(7,9,1,5),对两个部分分别进行归并排序,第1部分继续分为(3,2)和(8,6),(3,2)继续分为(3)和(2),(8,6)继续分为(8)和(6),之后进行合并得到(2,3),(6,8),再合并得到(2,3,6,8),第2部分进行归并排序得到(1,5,7,9),最后合并两部分得到(1,2,3,5,6,7,8,9)。
实现
//归并排序
staticvoidfunMergeSort(int[]array){
if(array.length >1) {
intlength1 =array.length /2;
int[] array1 =newint[length1];
System.arraycopy(array,0, array1,0, length1);
funMergeSort(array1);
intlength2 =array.length - length1;
int[] array2 =newint[length2];
System.arraycopy(array, length1, array2,0, length2);
funMergeSort(array2);
int[] datas = merge(array1, array2);
System.arraycopy(datas,0,array,0,array.length);
}
}
//合并两个数组
staticint[] merge(int[] list1,int[] list2) {
int[] list3 =newint[list1.length + list2.length];
intcount1 =0;
intcount2 =0;
intcount3 =0;
while(count1 < list1.length && count2 < list2.length) {
if(list1[count1] < list2[count2]) {
list3[count3++] = list1[count1++];
}else{
list3[count3++] = list2[count2++];
}
}
while(count1 < list1.length) {
list3[count3++] = list1[count1++];
}
while(count2 < list2.length) {
list3[count3++] = list2[count2++];
}
returnlist3;
}
分析
归并排序的时间复杂度为O(nlogn),它是一种稳定的排序,java.util.Arrays类中的sort方法就是使用归并排序的变体来实现的。
快速排序
简介
快速排序的主要思想是:在待排序的序列中选择一个称为主元的元素,将数组分为两部分,使得第一部分中的所有元素都小于或等于主元,而第二部分中的所有元素都大于主元,然后对两部分递归地应用快速排序算法。
实现
// 快速排序
staticvoidfunQuickSort(int[] mdata,intstart,intend){
if(end > start) {
intpivotIndex = quickSortPartition(mdata, start, end);
funQuickSort(mdata, start, pivotIndex -1);
funQuickSort(mdata, pivotIndex +1, end);
}
}
// 快速排序前的划分
staticintquickSortPartition(int[]list,intfirst,intlast){
intpivot =list[first];
intlow = first +1;
inthigh = last;
while(high > low) {
while(low <= high &&list[low] <= pivot) {
low++;
}
while(low <= high &&list[high] > pivot) {
high–;
}
if(high > low) {
inttemp =list[high];
list[high] =list[low];
list[low] = temp;
}
}
while(high > first &&list[high] >= pivot) {
high–;
}
if(pivot >list[high]) {
list[first] =list[high];
list[high] = pivot;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
在面试前我整理归纳了一些面试学习资料,文中结合我的朋友同学面试美团滴滴这类大厂的资料及案例


由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
大家看完有什么不懂的可以在下方留言讨论也可以关注。
觉得文章对你有帮助的话记得关注我点个赞支持一下!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
列中选择一个称为主元的元素,将数组分为两部分,使得第一部分中的所有元素都小于或等于主元,而第二部分中的所有元素都大于主元,然后对两部分递归地应用快速排序算法。
实现
// 快速排序
staticvoidfunQuickSort(int[] mdata,intstart,intend){
if(end > start) {
intpivotIndex = quickSortPartition(mdata, start, end);
funQuickSort(mdata, start, pivotIndex -1);
funQuickSort(mdata, pivotIndex +1, end);
}
}
// 快速排序前的划分
staticintquickSortPartition(int[]list,intfirst,intlast){
intpivot =list[first];
intlow = first +1;
inthigh = last;
while(high > low) {
while(low <= high &&list[low] <= pivot) {
low++;
}
while(low <= high &&list[high] > pivot) {
high–;
}
if(high > low) {
inttemp =list[high];
list[high] =list[low];
list[low] = temp;
}
}
while(high > first &&list[high] >= pivot) {
high–;
}
if(pivot >list[high]) {
list[first] =list[high];
list[high] = pivot;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-VDir7SJy-1713292148553)]
[外链图片转存中…(img-IdCklCDB-1713292148554)]
[外链图片转存中…(img-cQJCkT5f-1713292148554)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
最后
在面试前我整理归纳了一些面试学习资料,文中结合我的朋友同学面试美团滴滴这类大厂的资料及案例
[外链图片转存中…(img-wP49Fl8o-1713292148554)]
[外链图片转存中…(img-e9fuvRk4-1713292148554)]
由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
大家看完有什么不懂的可以在下方留言讨论也可以关注。
觉得文章对你有帮助的话记得关注我点个赞支持一下!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!

