
热门标签
热门文章
- 1RT-1052-Cortex-M内核启动文件_main分析_rt1052启动过程
- 2力扣1793.好子数组的最大分数
- 3国家信息安全等级保护制度第三级要求
- 4AI_Chat_GPT,真的好用吗?_aichatos
- 5【windows】--- SQL Server 2008 超详细安装教程_sql server2008
- 6SAP 输出合并单元格样式的ALV 报表_sap合并单元格
- 7【软件开发规范篇】Git代码提交规范
- 8单链表(线性链表)数据元素插入和删除_链式线性表的插入与删除 描述:删除链式线性表指定位置的元素。 输入:第一行为自然
- 9Python李峋同款可写字版跳动的爱心(完整代码)_python绘制立体玫瑰花
- 10uniapp - 新建页面与tabBar配置_uniapp tabbar
当前位置: article > 正文
Apache Paimon系列之:认识Paimon
作者:盐析白兔 | 2024-07-03 09:54:31
赞
踩
apache paimon
一、认识Paimon
Apache Paimon的架构:
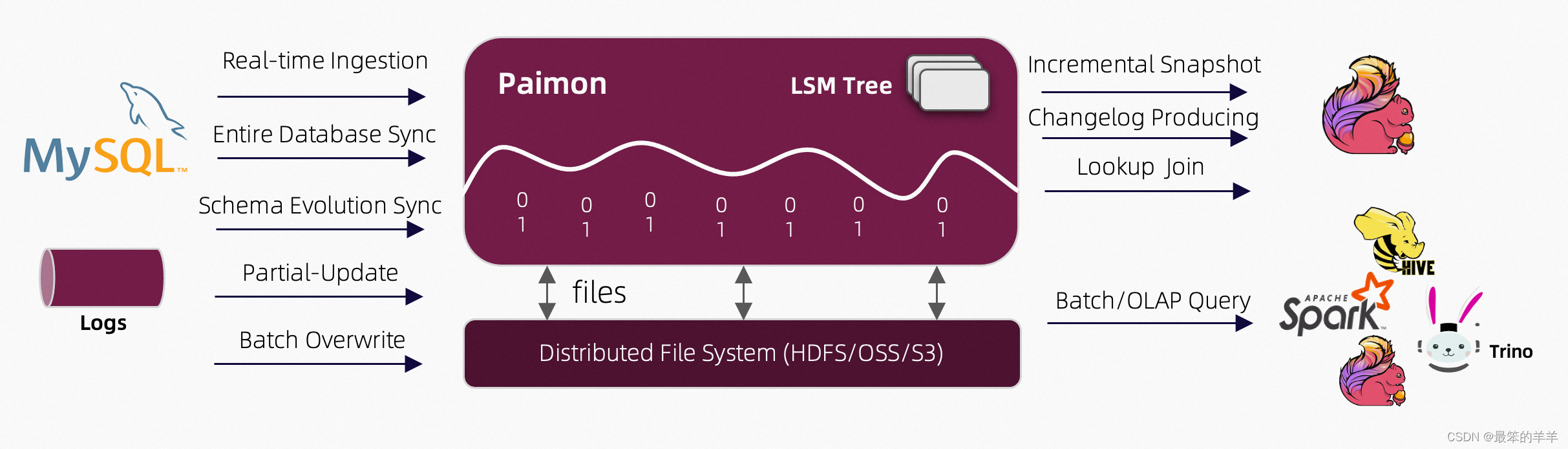
如上架构所示:
读/写:Paimon 支持多种读/写数据和执行 OLAP 查询的方式。
- 对于读取,它支持消费数据
- 从历史快照(批处理模式),
- 从最新的偏移量(在流模式下),或
- 以混合方式读取增量快照。
- 对于写入,它支持
- 来自数据库变更日志的流同步(CDC)
- 从离线数据批量插入/覆盖。
生态系统:除了Apache Flink之外,Paimon还支持Apache Hive、Apache Spark、Trino等其他计算引擎的读取。
内部的:
- 在底层,Paimon 将列式文件存储在文件系统/对象存储上
- 文件的元数据保存在manifest文件中,提供大规模存储和数据跳过。
- 对于主键表,采用LSM树结构,支持大数据量更新和高性能查询。
二、统一存储
对于 Apache Flink 这样的流引擎,通常有三种类型的连接器:
- 消息队列,例如 Apache Kafka,在该管道的源阶段和中间阶段都使用它,以保证延迟保持在秒级。
- OLAP系统,例如ClickHouse,它以流方式接收处理后的数据并服务用户的即席查询。
- 批量存储,例如Apache Hive,它支持传统批处理的各种操作,包括INSERT OVERWRITE。
Paimon 提供表抽象。它的使用方式与传统数据库没有什么区别:
- 在批处理执行模式下,它就像一个Hive表,支持Batch SQL的各种操作。查询它以查看最新的快照。
- 在流执行模式下,它的作用就像一个消息队列。查询它的行为就像从历史数据永不过期的消息队列中查询流更改日志。
三、基本概念
1.文件布局
一张表的所有文件都存储在一个基本目录下。 Paimon 文件以分层方式组织。下图说明了文件布局。从快照文件开始,Paimon 读者可以递归地访问表中的所有记录。
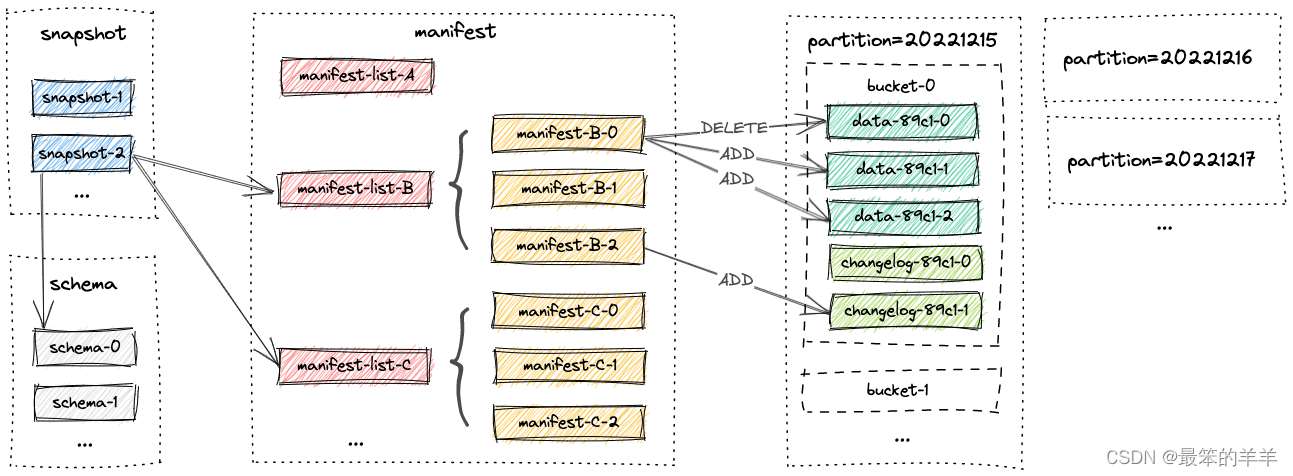
2.Snapshot
所有快照文件都存储在快照目录中。
快照文件是一个 JSON 文件,包含有关此快照的信息,包括
- 正在使用的模式文件
- 包含此快照的所有更改的清单列表
快照捕获表在某个时间点的状态。用户可以通过最新的快照来访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
3.清单文件
所有清单列表和清单文件都存储在清单目录中。
清单列表是清单文件名的列表。
清单文件是包含有关 LSM 数据文件和更改日志文件的更改的文件。例如对应快照中创建了哪个LSM数据文件、删除了哪个文件。
4.数据文件
数据文件按分区分组。目前,Paimon 支持使用 orc(默认)、parquet 和 avro 作为数据文件格式。
5.分区
- Paimon 采用与 Apache Hive 相同的分区概念来分离数据。
- 分区是一种可选方法,可根据日期、城市和部门等特定列的值将表划分为相关部分。每个表可以有一个或多个分区键来标识特定分区。
- 通过分区,用户可以高效地操作表中的一片记录。
6.一致性保证
Paimon 编写器使用两阶段提交协议以原子方式将一批记录提交到表中。每次提交在提交时最多生成两个快照。
对于任意两个同时修改表的写入者,只要他们不修改同一分区,他们的提交就可以并行发生。如果他们修改同一分区,则仅保证快照隔离。也就是说,最终表状态可能是两次提交的混合,但不会丢失任何更改。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/782693
推荐阅读
相关标签

