
- 1[314]谷歌翻译_谷歌翻译镜像
- 2卷积神经网络参数量和计算量的计算_卷积参数量计算
- 3C# 调用支付宝API接口_c#支付宝支付api文档
- 4Spark开发实例(SequoiaDB)_spark开发例子
- 5Spring Cloud + Vue前后端分离-第17章 生产打包与发布_springcloud后端打包发布 j
- 6[华中杯]2024ABC题所有小问py代码+高质量完整思路20页重磅更新_太阳能路灯光伏板的朝向设计问题数学建模matlab
- 7python3读写excel文件_13-用 Python 读写 Excel 文件
- 8号称下一代监控系统,来看看它有多强!
- 9Spring boot 3 (3.1.5) Spring Security 设置一_spring boot 3.1.5
- 10Python爬虫怎么挣钱?解析Python爬虫赚钱方式,轻轻松松月入两万,再也不用为钱发愁啦_采集两千万英文数据做网站流量
Spark源码阅读(五) --- Spark的支持的join方式以及join策略_spark join
赞
踩
版本变动
2021-08-30
增加了对Broadcast Hash Join小表大小的评估内容
增加了对Sort Merge Join优于Shuffle Hash Join调用的解释
目录
小表Join大表--Broadcast Hash Join与Shuffle Hash Join
非等值连接--Broadcast Nested Loop Join与Cartesian Join
Join无论SparkCore中还是在SparkSql都占据着至关重要的地位,今天来阅读一下Join部分的源码
Spark支持的七种Join方式
直接看Join算子的源码,发现经过反复调用,最终会来到这个Join方法内部
- def join(right: Dataset[_], usingColumns: Seq[String], joinType: String): DataFrame = {
- // Analyze the self join. The assumption is that the analyzer will disambiguate left vs right
- // by creating a new instance for one of the branch.
- val joined = sparkSession.sessionState.executePlan(
- Join(logicalPlan, right.logicalPlan, joinType = JoinType(joinType), None))
- .analyzed.asInstanceOf[Join]
-
- withPlan {
- Join(
- joined.left,
- joined.right,
- UsingJoin(JoinType(joinType), usingColumns),
- None)
- }
- }
该方法默认为Inner Join,可以看到传入了String类型的名为joinType的param,被封装到了JoinType的Object对象内,其apply方法源码如下
- def apply(typ: String): JoinType = typ.toLowerCase(Locale.ROOT).replace("_", "") match {
- case "inner" => Inner
- case "outer" | "full" | "fullouter" => FullOuter
- case "leftouter" | "left" => LeftOuter
- case "rightouter" | "right" => RightOuter
- case "leftsemi" => LeftSemi
- case "leftanti" => LeftAnti
- case "cross" => Cross
- case _ =>
- val supported = Seq(
- "inner",
- "outer", "full", "fullouter", "full_outer",
- "leftouter", "left", "left_outer",
- "rightouter", "right", "right_outer",
- "leftsemi", "left_semi",
- "leftanti", "left_anti",
- "cross")
-
- throw new IllegalArgumentException(s"Unsupported join type '$typ'. " +
- "Supported join types include: " + supported.mkString("'", "', '", "'") + ".")
- }
- }

Inner Join
Inner Join又称为内连接,平日里书写时,用join或者Inner Join,它join的结果就是符合关联条件下的两张表数据的交集,例如有如下代码
Student表:
- sparkSession.sql(
- """
- |select 1 as id,'lili' as name
- |union all
- |select 2 as id,'hanhan' as name""".stripMargin)
- .createOrReplaceTempView("Student")
Score表:
- sparkSession.sql("select 1 as id,'math' as subject,99 as score")
- .createOrReplaceTempView("Score")
join sql:
- select t1.id,t1.name,t2.subject,t2.score
- from Student t1
- join Score t2
- on t1.id=t2.id
结果如下:


Cross Join
Cross Join,直译就是交叉Join,也就是所谓的笛卡尔积操作,笛卡尔积有很多实现的方法,比如非等值连接:
- select *
- from Student t1
- join Score t2
- on t1.id != t2.id
在from中同时from两张表
- select *
- from Student,Score
join不写条件
- select *
- from Student t1
- join Score t2
on条件中用上or
- select *
- from Student t1
- join Score t2
- on t1.id = t2.id or t1.name =t2.name
或者直接写cross Join
- select *
- from Student t1
- cross join Score t2
都可以触发笛卡尔积操作
它的结果或者执行过程中基本都会生成这样一张表

就是所谓的交叉乘积,Student表中的每一条数据和Score表中的每一条数据都做了排列组合式聚合并最终输出。
但是有个要注意的地方是,有时候并不会真的在底层做了笛卡尔积操作,因为sparkSql内部存有优化器,并且在非等值连接且条件允许的情况下,一般是对Broadcast Nested Loop Join进行调用,所以如何判断是否真的产生了笛卡尔积?我们查询执行计划的时候如果看到
CartesianProduct那就是底层真正采用了笛卡尔积操作。
关于sparkSql的Join策略将会在本文后半部分讲述。
Left Outer Join
Left Outer Join,又称左外连接,平常使用的时候写left outer join或者left join都行,其作用是显示全左表的数据,即便这部分数据不满足Join条件
join sql:
- select *
- from Student t1
- left join Score t2
- on t1.id = t2.id
结果如下:

可以看到左表没匹配到的字段全部置为null
Right Outer Join
Right Outer Join,又称右外连接,平常使用的时候写right outer join或者right join都行,与left outer join类似,其作用是显示全右表的数据,即便这部分数据不满足Join条件
join sql:
- select *
- from Student t1
- right join Score t2
- on t1.id = t2.id
结果如下:

这里我将Student换到右表去,结果与预期一致
Full Outer Join
Full Outer Join,又称全外连接,平常使用的时候写full outer join或者full join都行,其作用是显示全右左表的全部数据,即便这部分数据不满足Join条件
join sql:
- select *
- from Score t1
- full join Student t2
- on t1.id = t2.name
结果如下:
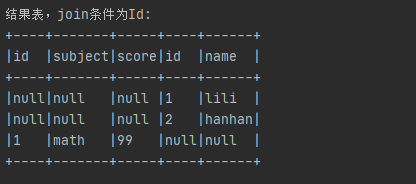
我特意让两张表的join条件的字段不一致,结果如预期一般全部显示
Left Semi Join
Left Semi Join,又名左半连接,算是一种优化策略式的join方式,sparkSql的底层通常会将in操作优化为Left Semi Join,我们重点讲解一下这个Join
首先注意它有几个特点
1、右表的key仅仅只传递到map阶段,所以它将不会在结果中出现
2、他的输出结果与join类似,都是只输出符合join条件的数据,但是它更快而且left semi join天生就是去重,可以看成一个更快的,去重的join
3、因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,比如左表中有一个time字段中有2020-11-05这样一条数据,右表有两个字段start_time和end_time组成一个时间段,这之中有两条数据,分别是2020-10-12至2020-12-06和2020-9-17至2020-12-07,join的条件是time between start_time and end_time。那么join他会将这两个条件都匹配上,致使数据发散,而left semi join只会匹配到一条满足条件的数据,其他就会被跳过,这也是为什么left semi join本身自带去重,因为没有数据发散,又十分快,因为仅满足条件就行。
下面举几个例子来说说它的特点
首先我们来两张表
订单表:

活动表:
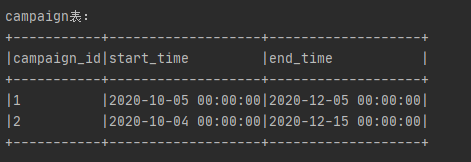
join sql:
- -- join
- select *
- from order t1
- join campaign t2
- on t1.order_dt between start_time and end_time
- --left semi join
- select *
- from order t1
- left semi join campaign t2
- on t1.order_dt between start_time and end_time
结果如下:
join结果

left semi join结果
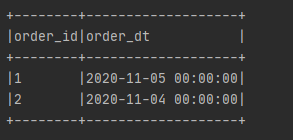
可以很明显的看到join的结果数据发散了,而left semi join并没有,这个结果符合了我们刚刚提到几个特点
Left Anti Join
Left Anti Join,名为反左连接,其作用是显示没匹配的数据,其实就类似于not in,这也是一个经典的优化策略式的join方式,与left semi join相同,右表的数据也仅仅传到map阶段,并不会输出到最终的结果,其底层的优化与left semi join类似
join sql:
- select *
- from Student t1
- left anti join Score t2
- on t1.id=t2.id
这里给个预期的结果,我就不多做赘述了
Spakr支持的五种Join策略
上述提到了spark的七种join方式,那么下面来说说spark的五种Join策略,它们分别是
1、Broadcast Hash Join
2、Shuffle Hash Join
3、Sort Merge Join
4、Cartesian Join
5、Broadcast Nested Loop Join
小表Join大表--Broadcast Hash Join与Shuffle Hash Join
我们知道spark是一个分布式计算引擎,其Join的核心其实仍是传统数据库中常见的各类Join策略,这边先说说Broadcast Hash Join与Shuffle Hash Join用到的Hash Join是什么
举例上文提到的Student表和Score表,假如有这么一个sql:select * from Student t1 join Score t2 on t1.id=t2.id.
那么Hash Join会做这么几件事情,如下图

1、首先Score表会作为一张Build Table,Student表会作为一张Probe Table,区分这两者的因素是表的大小,为何选取小表做Build Table进而去生成Hash Table呢?因为小表体量小,可以完全加载到内存中,并且能够比较轻松地被作为BroadCast分发出去。
2、扫描Score表全表,Score表会根据join条件的key做Hash操作,将该key放到对应的Bucket中,进而build一张Hash Table。
3、扫描Student表全表,根据Join条件对Join Key做Hash操作,映射到对应的Bucket上,此时会跟Hash Table中Score映射出来tuple的Key匹配上,此时还会再做一次Join条件和filter条件的判断,才会最终输出匹配的数据。
Broadcast Hash Join
我们直接上源码
-
- case class BroadcastHashJoinExec(
- leftKeys: Seq[Expression],
- rightKeys: Seq[Expression],
- joinType: JoinType,
- buildSide: BuildSide,
- condition: Option[Expression],
- left: SparkPlan,
- right: SparkPlan)
- extends BinaryExecNode with HashJoin with CodegenSupport {
- //......
- }
我们可以看到该class动态混入了 HashJoin和CodegenSupport,Hash Join我就不多说了,CodegenSupport则和Codegen有关,Codegen是Spark Runtime优化性能的关键技术,核心在于动态生成java代码、即时compile和加载,把解释执行转化为编译执行,Spark Codegen分为Expression级别和WholeStage级别,简而言之Codegen就是管理执行计划优化和生成的老大了,CodegenContext是它的核心类代码。这里引用阿里云社区bean_stalk大佬文章内的一张图(文章地址我在本文文末贴出)

我们可以看到起点是execute(),随后是doExecute()方法,doExecute()主要做了两件事,分为数据获取与代码生成两部分。
数据获取走的是inputRdd->inputRdds->execute()这条路,假设物理算子节点 A 支持代码生成,物理算子节点 B 不支持代码生成,因此 B 会采用 InputAdapter 封装
代码生成则是produce()/doProduce()和consume()/doConsume()这条路,produce和consume是专门用以生成代码的
因此我们直接看doProduce()和doConsume()两被被override的源码
-
- override def doProduce(ctx: CodegenContext): String = {
- streamedPlan.asInstanceOf[CodegenSupport].produce(ctx, this)
- }
-
- override def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = {
- joinType match {
- case _: InnerLike => codegenInner(ctx, input)
- case LeftOuter | RightOuter => codegenOuter(ctx, input)
- case LeftSemi => codegenSemi(ctx, input)
- case LeftAnti => codegenAnti(ctx, input)
- case j: ExistenceJoin => codegenExistence(ctx, input)
- case x =>
- throw new IllegalArgumentException(
- s"BroadcastHashJoin should not take $x as the JoinType")
- }
- }
-
-
Produce()方法就是生成java code的执行计划,我们来看下doConsume()方法,可以看到里面有很多case,有Inner、Outer、semi、Anti各种Join类型,其中ExistenceJoin是底层自己调用的Join类型,我们并不会使用到。
任意点进一个case的返回类,以InnerLike为例,以下是CodegenInner的源码
- /**
- * Generates the code for Inner join.
- */
- private def codegenInner(ctx: CodegenContext, input: Seq[ExprCode]): String = {
- val (broadcastRelation, relationTerm) = prepareBroadcast(ctx)
- val (keyEv, anyNull) = genStreamSideJoinKey(ctx, input)
- val (matched, checkCondition, buildVars) = getJoinCondition(ctx, input)
- val numOutput = metricTerm(ctx, "numOutputRows")
-
- val resultVars = buildSide match {
- case BuildLeft => buildVars ++ input
- case BuildRight => input ++ buildVars
- }
- if (broadcastRelation.value.keyIsUnique) {
- s"""
- |// generate join key for stream side
- |${keyEv.code}
- |// find matches from HashedRelation
- |UnsafeRow $matched = $anyNull ? null: (UnsafeRow)$relationTerm.getValue(${keyEv.value});
- |if ($matched != null) {
- | $checkCondition {
- | $numOutput.add(1);
- | ${consume(ctx, resultVars)}
- | }
- |}
- """.stripMargin
-
- } else {
- val matches = ctx.freshName("matches")
- val iteratorCls = classOf[Iterator[UnsafeRow]].getName
- s"""
- |// generate join key for stream side
- |${keyEv.code}
- |// find matches from HashRelation
- |$iteratorCls $matches = $anyNull ? null : ($iteratorCls)$relationTerm.get(${keyEv.value});
- |if ($matches != null) {
- | while ($matches.hasNext()) {
- | UnsafeRow $matched = (UnsafeRow) $matches.next();
- | $checkCondition {
- | $numOutput.add(1);
- | ${consume(ctx, resultVars)}
- | }
- | }
- |}
- """.stripMargin
- }
- }
总体流程如下:
1、prepareBroadcast,生成广播变量以便发送出去
2、genStreamSideJoinKey,生成能生成Join Key的代码
3、getJoinCondition,生成用于过滤row的Join Condition的代码
4、最后返回Inner Join的代码
以上就是BroadcastHashJoinExec做的一些基本的事,prepareBroadcast是其核心。
Broadcast Hash Join的总体流程
数据收集阶段:利用 collect 算子将小表的数据先收集到Driver端上
Broadcast阶段:选取小表生成broadcast分发到个Executor上,进而避免Shuffle
Hash Join阶段:各点上自己做Hash Join
其实就是分布式操作(Broadcast分发)+Hash Join = Broadcast Hash Join,总体还是比较好理解的
如何判断小表的大小?
在实际生产环境中,可能因为落地数据有经过Snappy等方式的压缩,导致数据进入到内存后展开变得更大,从而使我们对小表的数据大小判断不准确
我们可以使用spark的method对小表数据做一个统计
- val plan = sparkSession.sql(
- """select 1 as col
- |union all
- |select 2 as col) """.stripMargin).queryExecution.logical
- println(sparkSession
- .sessionState
- .executePlan(plan)
- .optimizedPlan
- .stats.sizeInBytes
- )
这里再总结一下特点
Broadcast Hash Join特点
- 仅支持等值连接,join key不需要排序
- 除full outer join外其他join类型均支持
- 需要对小表构建Hash map,如果小表比较大可能会OOM,同时将在Driver端存储小表数据,可以通过spark.sql.autoBroadcastJoinThreshold设置,默认为10M
- 被广播表的大小阈值不能超过8GB,如果大于8GB就会直接throw Exception了,这点在源码中有所体现
Shuffle Hash Join
Shuffle Hash Join同样也是大表join小表的一种处理方式,只不过这里的小表略有特殊,这里的小表是由一张较大的表切分而出的。因为在我们真实的环境中,不可能每次参与join的对象都是很小的表,所Shuffle Hash Join诞生了,采用了分治的思想,将大表分而治之,也就是根据join Key先将数据做一次Shuffle。
直接上源码
- case class ShuffledHashJoinExec(
- leftKeys: Seq[Expression],
- rightKeys: Seq[Expression],
- joinType: JoinType,
- buildSide: BuildSide,
- condition: Option[Expression],
- left: SparkPlan,
- right: SparkPlan)
- extends BinaryExecNode with HashJoin {
-
- override lazy val metrics = Map(
- "numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output rows"),
- "buildDataSize" -> SQLMetrics.createSizeMetric(sparkContext, "data size of build side"),
- "buildTime" -> SQLMetrics.createTimingMetric(sparkContext, "time to build hash map"))
-
- override def requiredChildDistribution: Seq[Distribution] =
- HashClusteredDistribution(leftKeys) :: HashClusteredDistribution(rightKeys) :: Nil
-
- private def buildHashedRelation(iter: Iterator[InternalRow]): HashedRelation = {
- val buildDataSize = longMetric("buildDataSize")
- val buildTime = longMetric("buildTime")
- val start = System.nanoTime()
- val context = TaskContext.get()
- val relation = HashedRelation(iter, buildKeys, taskMemoryManager = context.taskMemoryManager())
- buildTime += (System.nanoTime() - start) / 1000000
- buildDataSize += relation.estimatedSize
- // This relation is usually used until the end of task.
- context.addTaskCompletionListener[Unit](_ => relation.close())
- relation
- }
-
- protected override def doExecute(): RDD[InternalRow] = {
- val numOutputRows = longMetric("numOutputRows")
- streamedPlan.execute().zipPartitions(buildPlan.execute()) { (streamIter, buildIter) =>
- val hashed = buildHashedRelation(buildIter)
- join(streamIter, hashed, numOutputRows)
- }
- }
- }
我们发现其源码并不多,只有doExecute()方法,那我们从doExecute中开始看起,该方法返回了一个RDD,内部首先做了Hashed的获得,其次调用了Hash Join的join方法进行了对不同join的调用,从这里可以看出它的核心流程还是Hash Join。
Shuffle Hash Join的总体流程
Shuffle阶段:将两张表根据Join条件Shuffle到不同的partition上
HashJoin阶段:在每个Executor上做单点的Hash Join
Shuffle Hash Join的特点
- 仅支持等值连接,join key不需要排序
- 除full outer join外其他join类型均支持
- 仍需要对小表构建Hash map,如果小表比较大可能会OOM,虽然对较小的大表进行了划分,但是划分出的小表不会超过spark.sql.autoBroadcastJoinThreshold的设置,一样可以通过spark.sql.autoBroadcastJoinThreshold设置,默认为10M
- 被shuffle的小表大小还要额外满足两个条件,一个是Size(小表) < spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions,第二个是Size(小表)*3 <=Size(大表)
- 由于在spark底层的Join策略的优先级顺序是Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join,所以将参数spark.sql.join.prefersortmergeJoin(默认为true)置为false,有利于提高Shuffle Hash Join的使用率
大表join大表--Sort Merge Join
由于在spark底层的Join策略的优先级顺序是Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join,所以当Broadcast Hash Join不满足触发条件时,spark底层会自动选择Sort Merge Join执行。
Sort Merge Join,意如其名,其中有排序的操作,主要用于两张大表join时的处理
直接上源码
- protected override def doExecute(): RDD[InternalRow] = {
- val numOutputRows = longMetric("numOutputRows")
- val spillThreshold = getSpillThreshold
- val inMemoryThreshold = getInMemoryThreshold
- left.execute().zipPartitions(right.execute()) { (leftIter, rightIter) =>
- val boundCondition: (InternalRow) => Boolean = {
- condition.map { cond =>
- newPredicate(cond, left.output ++ right.output).eval _
- }.getOrElse {
- (r: InternalRow) => true
- }
- }
-
- // An ordering that can be used to compare keys from both sides.
- val keyOrdering = newNaturalAscendingOrdering(leftKeys.map(_.dataType))
- val resultProj: InternalRow => InternalRow = UnsafeProjection.create(output, output)
-
- joinType match {
- //。。。
- }
-
- }
- }
我们直接看关键部分,我们可以很明显的看到先做了newNaturalAscendingOrdering这个明显的Key排序操作,接下来才做了JoinType的匹配,进行两张表的Join。
Sort Merge Join的总体流程
Shuffle阶段:将两张表根据Join条件的key,Shuffle相应的数据到相同的partition上
Sort阶段:两边Key做升序排序
Join阶段:两边Key进行Join,符合条件就匹配输出结果
Sort Merge Join的特点
- 仅支持等值连接,join key需要排序
- 所有join类型均支持
- 由于在spark底层的Join策略的优先级顺序是Broadcast Hash Join > Sort Merge Sort > Shuffle Hash Join,所以参数spark.sql.join.prefersortmergeJoin默认为true
为什么Sort Merge Join的优先级大于Shuffle Hash Join呢?
这其实跟spark底层的Shuffle类型有关,我们知道2.0之后spark内部只有一个Sort Bash Join,而排序的操作正是在Shuffle Write阶段完成的,Map Task读取数据后写入PartitionedPairBuffer或者PartitionedAppendOnlyMap里,经过排序溢写直到所有数据读完,最后再汇成一个Shuffle中间文件落到磁盘里去,我们对比一下Shuffle的过程和Sort Merge Join的过程,会发现它们有一个共同之处,就是都有排序,所以说如果在Sort Base Shuffle处做了排序,意味着Sort Merge Join通过Shuffle Read过程只需要读取数据就行,排序的任务其实已经在Shuffle处被处理了,那么是不是大大减少了工作量呢。
非等值连接--Broadcast Nested Loop Join与Cartesian Join
Broadcast Nested Loop Join
当上述3种Join策略都无法触发时,spark底层将会自动选择Braodcast Nested Loop Join作为Join策略,它和Broadcast Hash join的分布式处理思想其实有点类似,都是发送Broadcast以避免Shuffle,但是由于非等值连接的原因,他循环判断很多次,所以其名字中有Loop的存在
Broadcast Nested Loop Join的特点
- 支持等值和非等值连接
- 支持所有的JOIN类型,当右外连接时要广播左表。当左外连接时要广播右表。当内连接时,要广播左右两张表
Cartesian Join(笛卡尔积)
就是笛卡尔积操作,具体实现方法在本文前半部分描述笛卡尔积Cross Join已经描述了,这里就不多赘述了,就描述一下其
Cartesian Join特点
- 同时支持等值和不等值连接
- 仅支持Inner Join
- 需要开启参数spark.sql.crossJoin.enabled=true,否则会被系统提示
- 由于spark底层的Join优化机制,有时候就算使用了Cross Join也不会触发Cartesian Join,在数据量小的时候基本会触发Broadcast Nested Loop Join
Spark的Join选择策略
上面提到了Spark五种Join选择策略,那么在底层选择这五种策略的源码如下
- def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
-
- // --- BroadcastHashJoin --------------------------------------------------------------------
-
- // broadcast hints were specified
- case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
- if canBroadcastByHints(joinType, left, right) =>
- val buildSide = broadcastSideByHints(joinType, left, right)
- Seq(joins.BroadcastHashJoinExec(
- leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
-
- // broadcast hints were not specified, so need to infer it from size and configuration.
- case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
- if canBroadcastBySizes(joinType, left, right) =>
- val buildSide = broadcastSideBySizes(joinType, left, right)
- Seq(joins.BroadcastHashJoinExec(
- leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
-
- // --- ShuffledHashJoin ---------------------------------------------------------------------
-
- case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
- if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)
- && muchSmaller(right, left) ||
- !RowOrdering.isOrderable(leftKeys) =>
- Seq(joins.ShuffledHashJoinExec(
- leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))
-
- case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
- if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)
- && muchSmaller(left, right) ||
- !RowOrdering.isOrderable(leftKeys) =>
- Seq(joins.ShuffledHashJoinExec(
- leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))
-
- // --- SortMergeJoin ------------------------------------------------------------
-
- case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)
- if RowOrdering.isOrderable(leftKeys) =>
- joins.SortMergeJoinExec(
- leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil
-
- // --- Without joining keys ------------------------------------------------------------
-
- // Pick BroadcastNestedLoopJoin if one side could be broadcast
- case j @ logical.Join(left, right, joinType, condition)
- if canBroadcastByHints(joinType, left, right) =>
- val buildSide = broadcastSideByHints(joinType, left, right)
- joins.BroadcastNestedLoopJoinExec(
- planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
-
- case j @ logical.Join(left, right, joinType, condition)
- if canBroadcastBySizes(joinType, left, right) =>
- val buildSide = broadcastSideBySizes(joinType, left, right)
- joins.BroadcastNestedLoopJoinExec(
- planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
-
- // Pick CartesianProduct for InnerJoin
- case logical.Join(left, right, _: InnerLike, condition) =>
- joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nil
-
- case logical.Join(left, right, joinType, condition) =>
- val buildSide = broadcastSide(
- left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)
- // This join could be very slow or OOM
- joins.BroadcastNestedLoopJoinExec(
- planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
-
- // --- Cases where this strategy does not apply ---------------------------------------------
-
- case _ => Nil
- }
- }
我们从顺序往下看,
1、首先是Broadcast Hash Join,可以看到使用了
if canBroadcastByHints(joinType, left, right)来进行判断,就是我们是否在sql中使用了hint优化指令,比如
- select /*+ BRAODCASTJOIN(B) */A.col1, B.col2
- FROM A
- JOIN B
- ON A.col1 = B.col2;
如果有则该方法判断通过,直接使用Broadcast Hash Join
2、可看到第二个case仍然是Broadcast Hash Join,但是判断条件换成了
if canBroadcastBySizes(joinType, left, right)其意思就是通过大小来判断是否应该执行Broadcast Hash Join,上文有提到一个参数spark.sql.autoBroadcastJoinThreshold,在其其底层判断就用到了,源码如下
- private def canBroadcast(plan: LogicalPlan): Boolean = {
- plan.stats.sizeInBytes >= 0 && plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold
- }
3、第三个是Shuffle Hash Join的判断(基表为左表,右表为小表的情况),我们直接看if条件
- if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)
- && muchSmaller(right, left) ||
- !RowOrdering.isOrderable(leftKeys)
首先我们可以看到conf.preferSortMergeJoin这个条件,还记得上文提到的的spark.sql.preferSortMergeJoin这个参数吗,由于其默认设为true,所以Shuffl Hash Join将不会在这里被调用。我们假设该参数已经被我们设为了true,接着往下,首先是对Join Key的一个判断,然后是对右表是否能被做成HashMap的判断,最后的muchSmaller()则是比较两边表的大小是否符合条件(本文上部分提到过应该满足小表的Size<=大表Size的1/3)
在或条件旁还存在一个判断条件RowOrdering.isOrderable(),主要是判断Join key是否能够排序,因为Sort Merge Join是需要对Key进行排序的,如果Key不能排序,自然不会去执行Sort Merge Join。
4、第四个是Shuffle Hash Join的判断(基表为右表,左表为小表的情况),条件都是一样,只是Left和Right交换了位置,这里我就不再多做赘述了。
5、第五个是Sort Merge Join的判断,内容很简单
if RowOrdering.isOrderable(leftKeys)就一个RowOrdering.isOrderable()的判断,前文已经提过了,主要是判断Join key是否能够排序,因为Sort Merge Join是需要对Key进行排序的,如果Key不能排序,自然不会去执行Sort Merge Join。
6、从下面开始就是非等值连接了,首先是对Broadcast Nested Loop Join的判断
if canBroadcastByHints(joinType, left, right)可以看到和Broadcast Hash Join的判断基本是一样的,首先是对Hints的判断
7、仍然是对Broadcast Nested Loop Join的判断
if canBroadcastBySizes(joinType, left, right)是对Size的判断
8、如果上述对Broadcast Nested Loop Join调用不成功,则执行笛卡尔积操作Cartesian Join,我们可以到看到没有判断条件,它仅仅只能对inner Join生效
9、仍然是Broadcast Nested Loop Join,属于实在是无可奈何的情况了,只能被迫选择这种调用方式,我们可以看到一句有趣的注释
// This join could be very slow or OOM可能会很慢或者OOM(Out Of Memory)
调度顺序总结
1、有Hint,使用Broadcast Hash Join
2、无Hint,按照Broadcast Hash Join -> Shuffle Hash Join(conf参数被更改) -> Sort Merge Join -> Broadcast Nested Loop Join(满足条件) ->
Cartesian Join -> Broadcast Nested Loop Join(满足条件)
后记
本文旨在学习和交流,笔者也查阅了许多资料和阅读源码与动手实践的出来的经验,如有问题欢迎指出,若需转载请进行标注。
这是本文中参考的文章地址Spark Codegen浅析-阿里云开发者社区 (aliyun.com)

