- 1【AI绘画】从零开发AI绘画微信小程序_可以利用ai设计图形界面吗微信小程序界面
- 2 Serverless Computing:现状与基础知识
- 3Fixed-Point Designer:Create Fixed-Point Data
- 4Navicat Premium15 下载与安装(免费版)以及链接SqlServer数据库_navicat premium 15下载
- 5零信任相关标准、框架及落地实践(下)_华三零信任 反向代理
- 6Triton inference server系列(0)——相关资料整理_triton server 相关文献
- 7Mac 更新 Homebrew软件包时提示 zsh: command not found: brew 错误
- 8十大开源测试工具和框架_bestdb 6.0.0是开源的吗
- 9[注意力机制]--Non-Local注意力的变体及应用_nonlocal注意力
- 10Linux安装oracle 19c_linux安装oracle19c
本地部署离线通义千问-1_8B-Chat与通义千问-14B-Chat模型及使用Lora方法对它们进行微调与验证(非常详细,值得大家借鉴且效果比Chatglm3-6B微调效果好)_通义千问本地离线部署
赞
踩
一、下载需要部署和微调的代码
1.下载地址
https://github.com/QwenLM
- 1
进入之后,如下所示:里面有不同模型版本的代码,大家可以根据自己的需求进行下载
2.进行下载:我这里选择了Qwen进行下载
https://github.com/QwenLM/Qwen
- 1
进入之后,如下所示:点击下载
二、下载需要部署和微调的模型
1.下载地址:在魔搭社区里面进行下载
魔搭(ModelScopeGPT)是阿里巴巴旗下的大模型调用工具,由阿里云在2022年的云栖大会上发布。它汇聚了280万开发者、2300多个优质模型,模型下载量超过1亿,成为中国规模最大、最活跃的AI开发者社区。
https://modelscope.cn/models
- 1
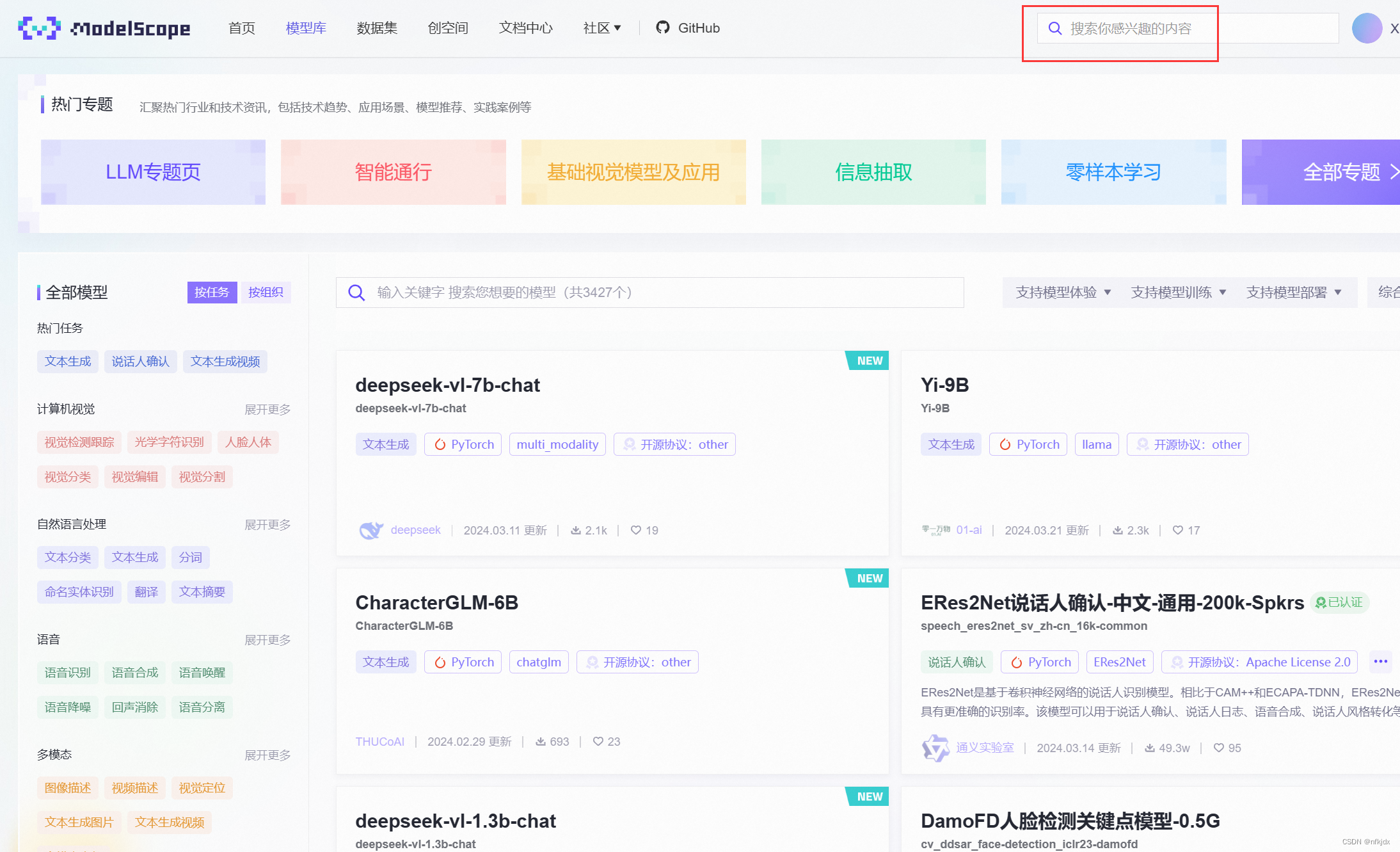
2.搜索需要下载的模型,进行下载
(1)搜索下载地址
https://modelscope.cn/search?page=1&search=%E9%80%9A%E4%B9%89%E5%8D%83%E9%97%AE&type=model
- 1
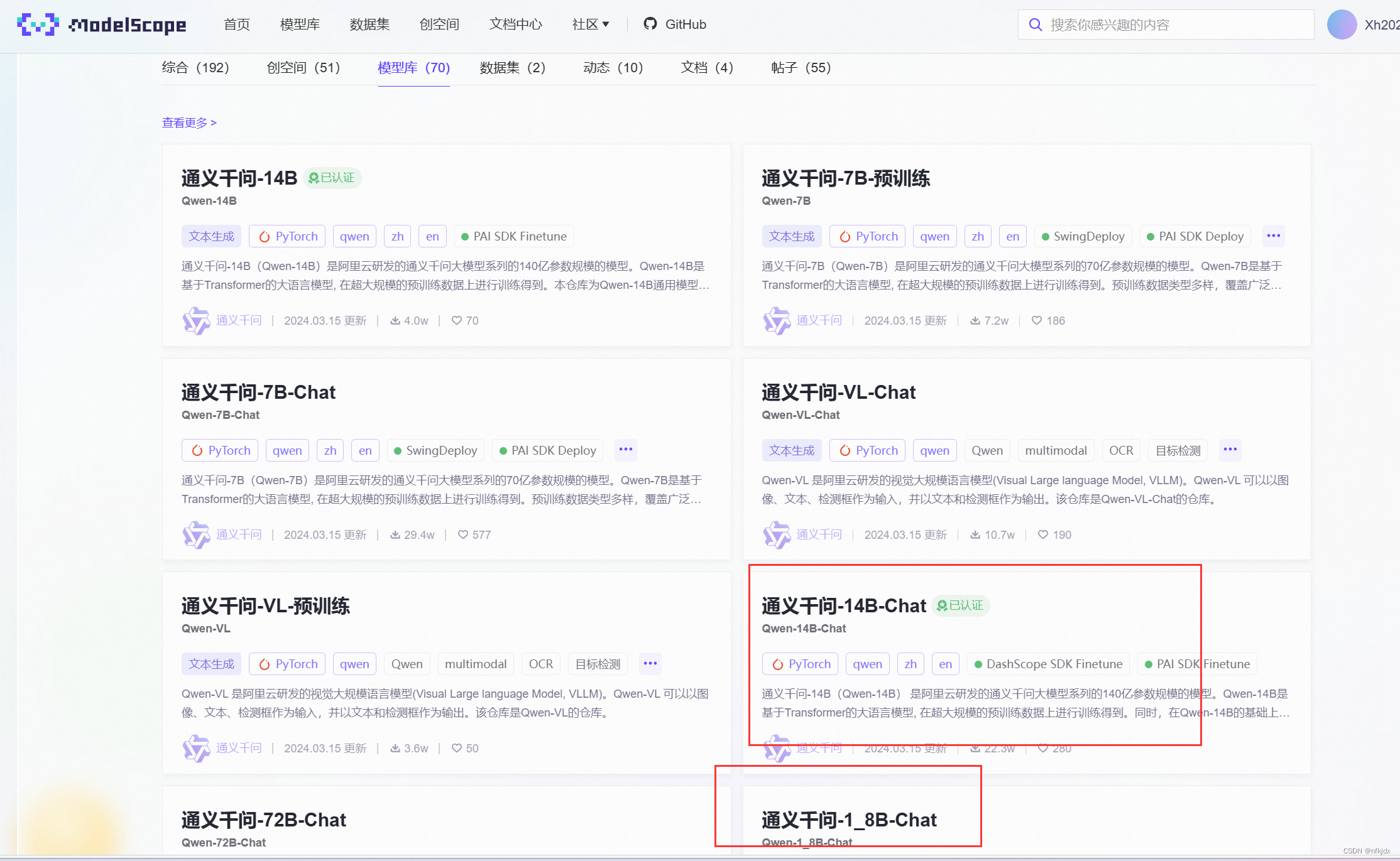
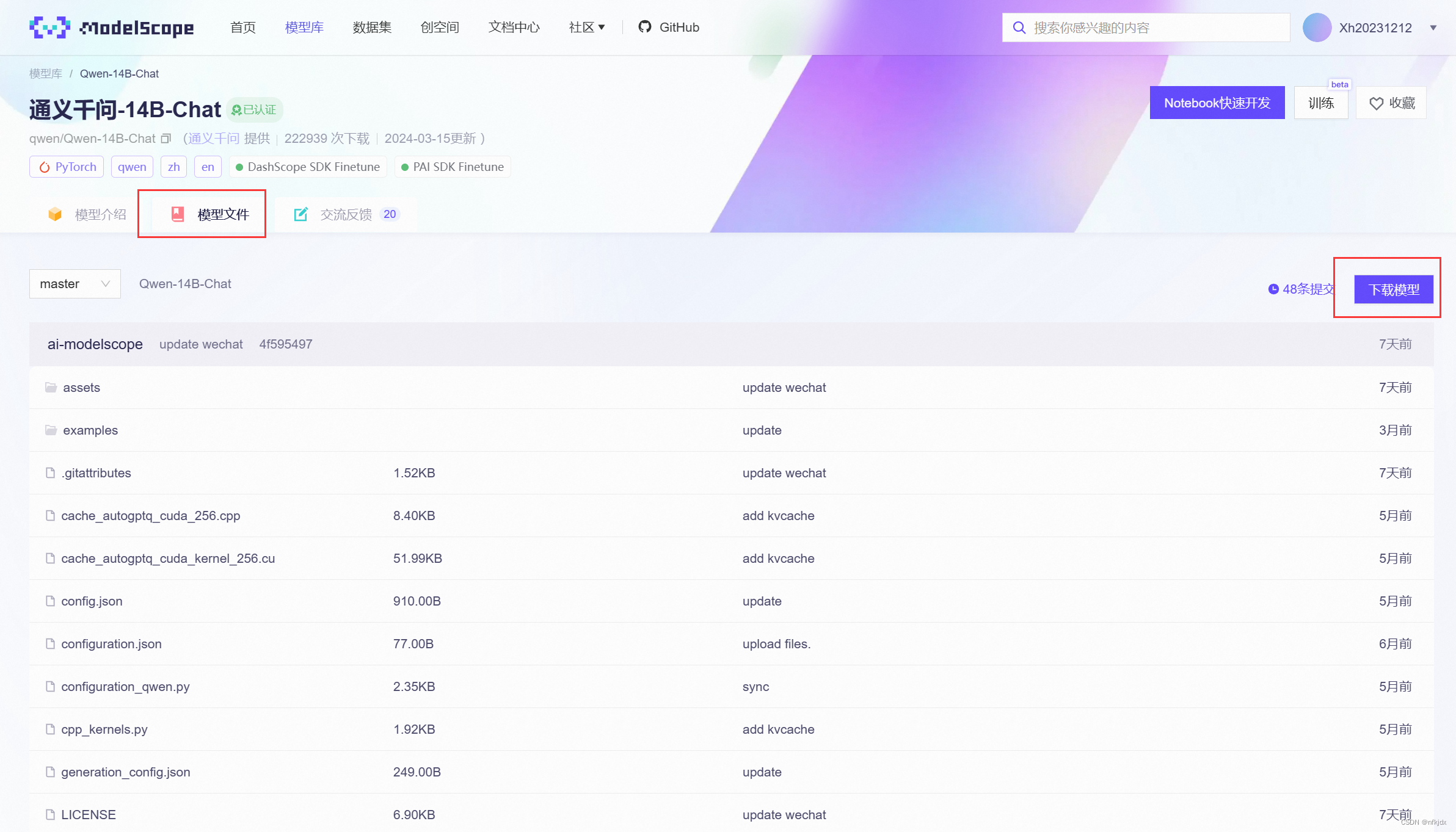
(2)点击【模型文件】,再点击【下载模型】
(3)这里提供了两种下载方式,我这里选择SDK下载
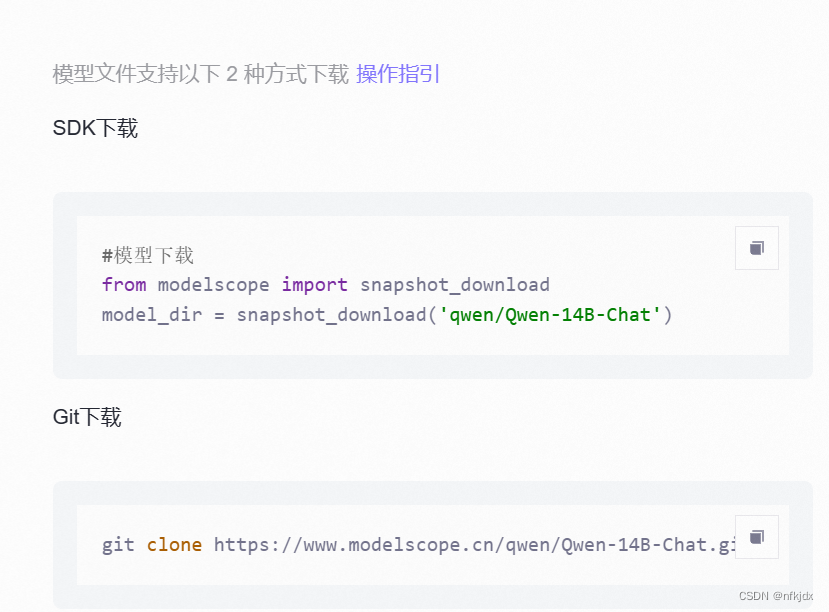
这里下载时需要注意:根据自己的需求进行下载
#这种下载方式:没有指定下载版本和保存路径
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-14B')
- 1
- 2
- 3
#这种下载方式:指定下载版本和保存路径
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-14B', cache_dir=r'D:\Qwen_models', revision='v1.0.8')
- 1
- 2
- 3
三、创建虚拟环境,安装所需要的包/库
1.打开cmd或者Anaconda Prompt(install)创建虚拟环境
方法一:默认情况下虚拟环境创建在Anaconda安装目录下的envs文件夹中
conda create --name QwenLora0 #QwenLora0是虚拟环境名称(自定义)
- 1
方法二:如果想将虚拟环境创建在指定位置,使用–prefix参数即可:
conda create --prefix /home/Zeroad/Envs/QwenLora0 python==3.9 #/home/Zeroad/Envs地址(自定义)
- 1

2.安装所需要的包/库
(1)首先进入下载的代码项目文件内,查看所需要安装的包/库:
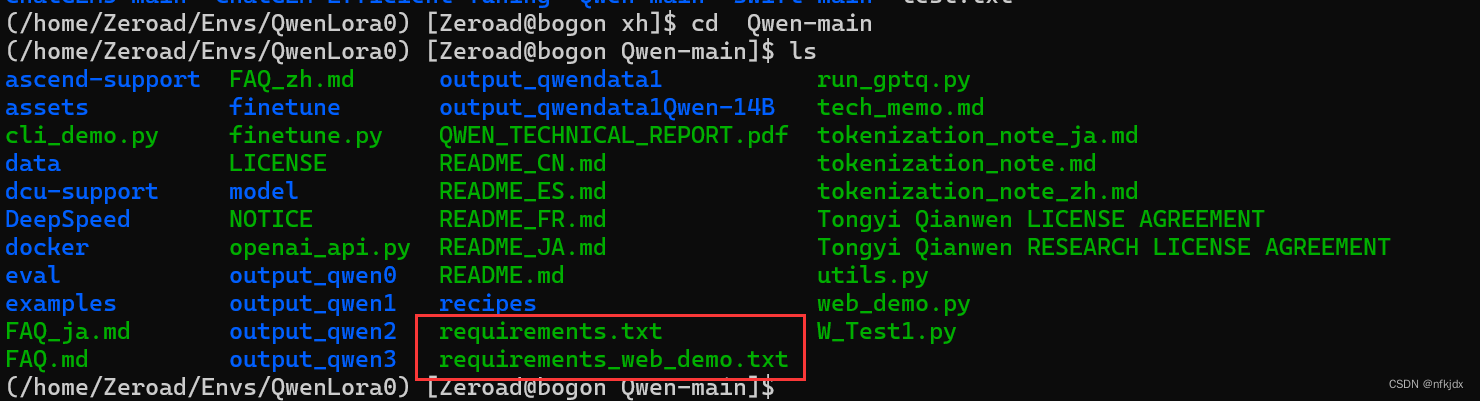
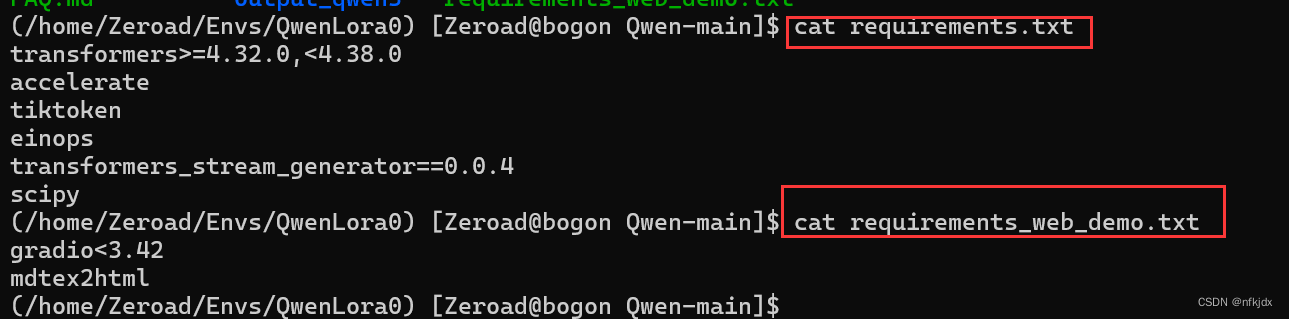
(2)查看具体的包和库:
cat requirements.txt
cat requirements_web_demo.txt
- 1
- 2
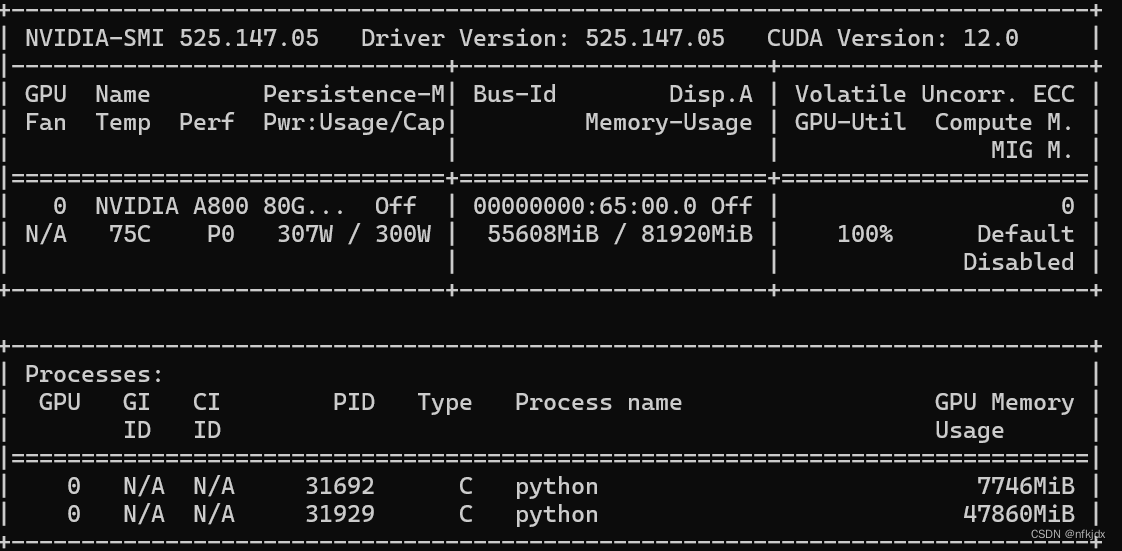
(3)进行安装:
3.1首先查看本机的cuda版本,再根据版本去安装合适的torch
nvidia-smi
- 1
打开网址:https://pytorch.org/get-started/previous-versions/,查找本机对应的torch,并通过命令在线安装,如下图所示;
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
- 1

3.2接着安装requirements.txt与requirements_web_demo.txt文件里面的包/库
使用清华镜像等进行快速安装,如下所示:
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
比如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ transformers==4.30.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.3使用以下命令查看安装好的包/库
pip list
- 1
四、启动模型,进行本地离线聊天
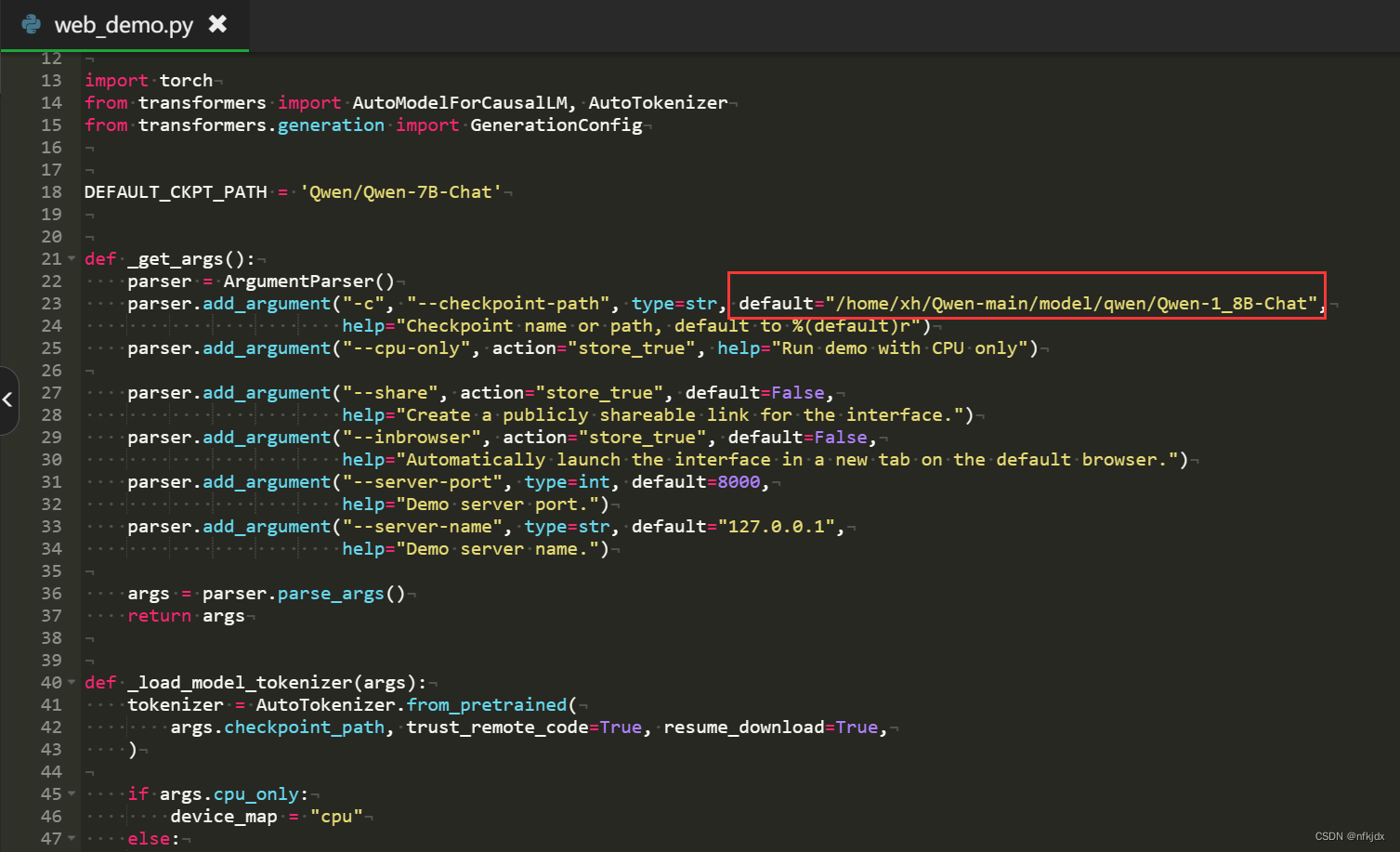
1.以web_demo.py方式启动:进入项目文件,对web_demo.py进行修改,然后运行该文件
(1).将存放模型的路径放入web_demo.py文件中–checkpoint-path选项的default内
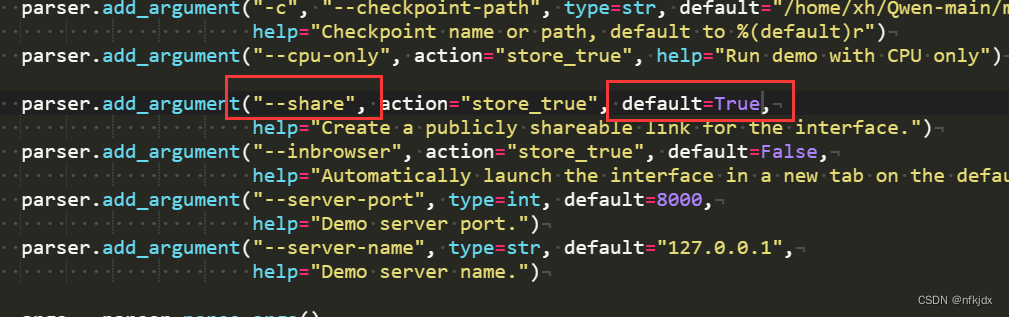
(2).将share选项default=False改为True,至此修改完毕!
(3).运行web_demo.py文件,启动模型,打开生成的地址就可以进行对话聊天
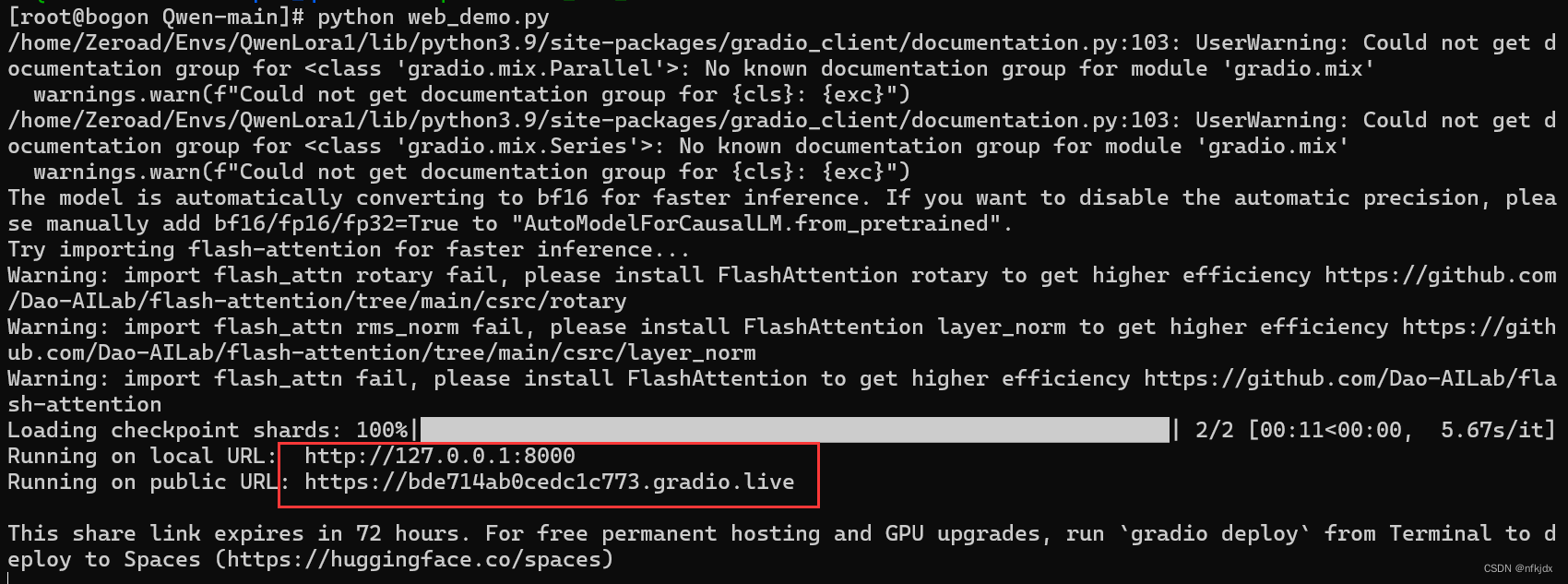
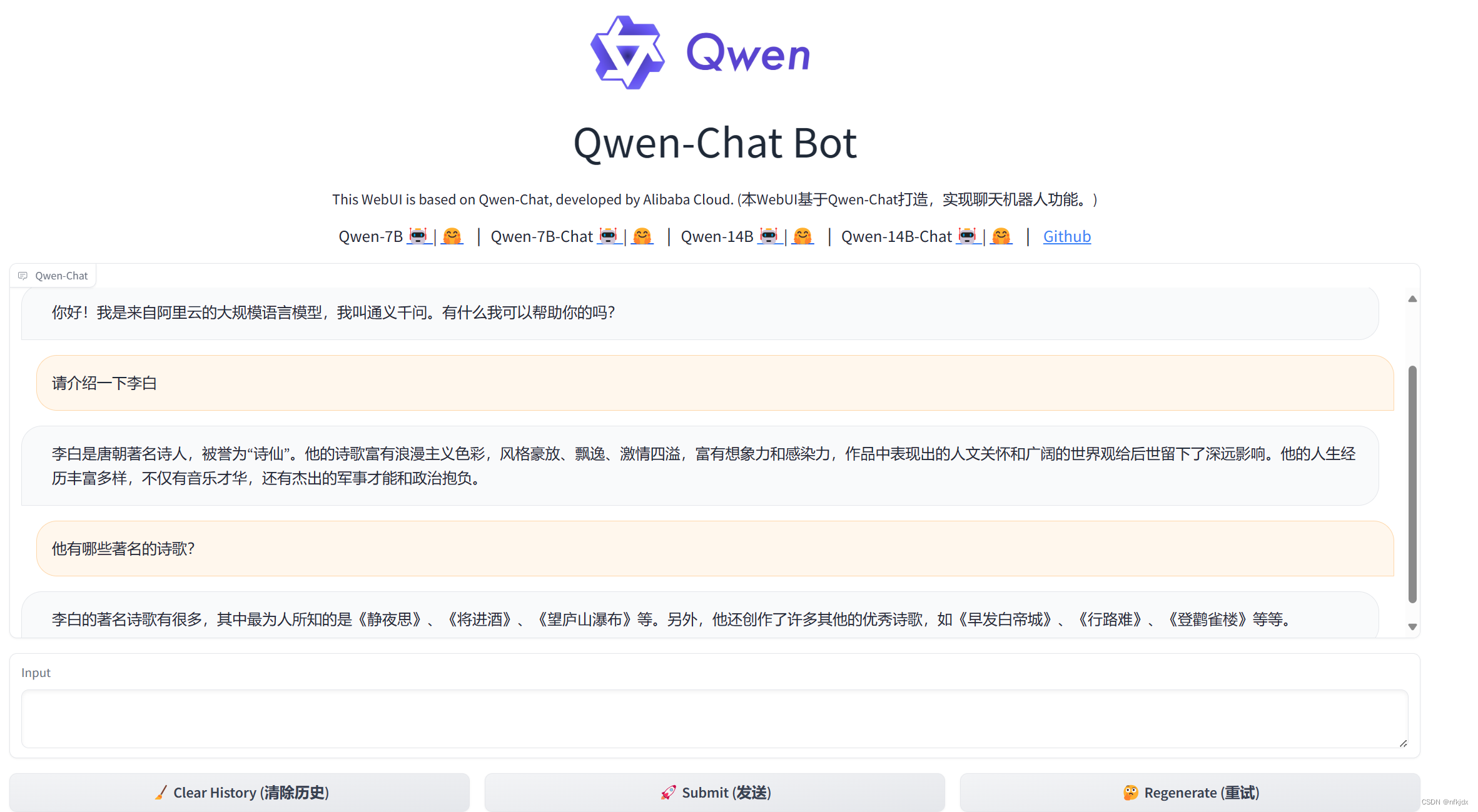
如果是在Linux系统下进行的操作,生成的地址可能无法访问,这时会提醒一个错误:Could not create share link
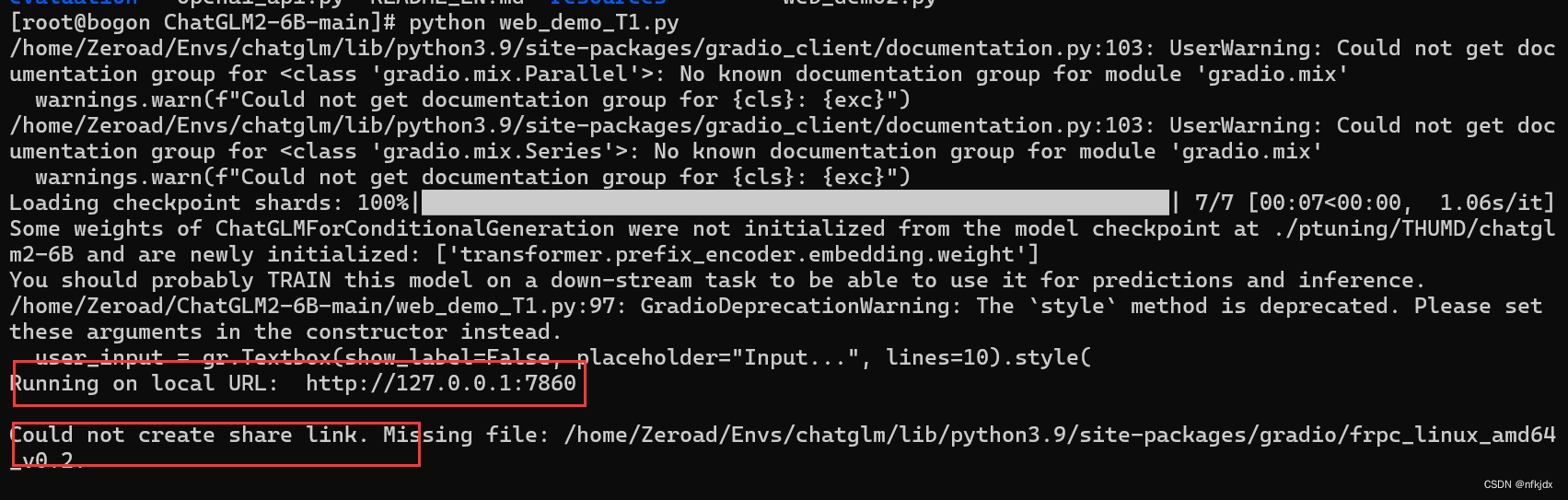
请参照我写的解决方法进行解决即可:https://blog.csdn.net/nfkjdx/article/details/136829773?spm=1001.2014.3001.5502
- 1
2.以cli_demo.py方式启动:进入项目文件,对cli_demo.py进行修改,然后运行该文件
(1).cli_demo.py文件修改更简单,只需要更换模型地址即可
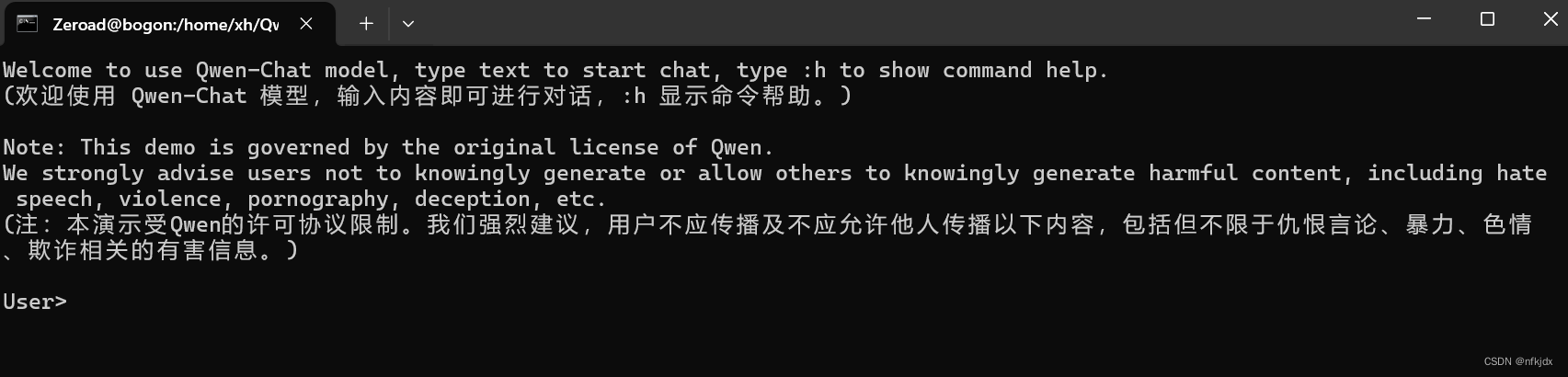
(2).运行cli_demo.py文件就可以进行对话聊天
3.以openai_api.py方式启动:进入项目文件,对openai_api.py进行修改,然后运行该文件
(1).openai_api.py文件修改也简单,只需要更换模型地址即可
(2).运行openai_api.py文件就可以进行对话聊天
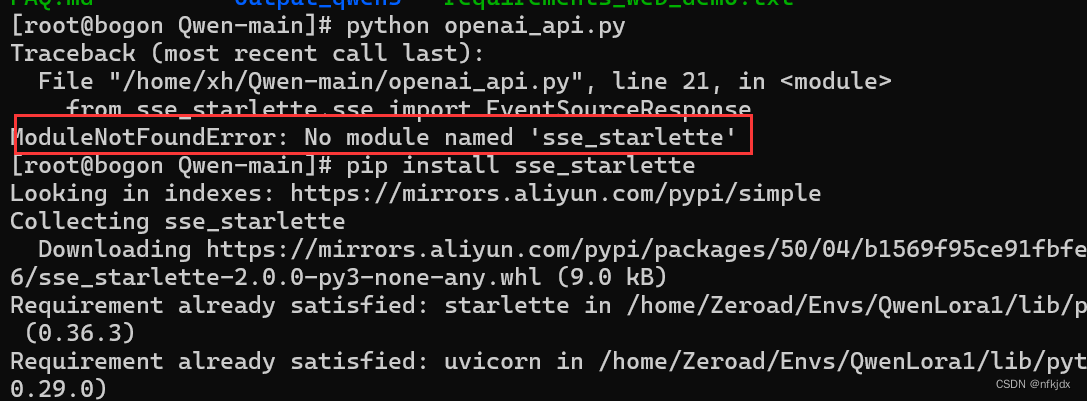
但是在运行openai_api.py报了一个错误:ModuleNotFoundError: No module named ‘sse_starlette’
因此安装此包即可,如下所示:
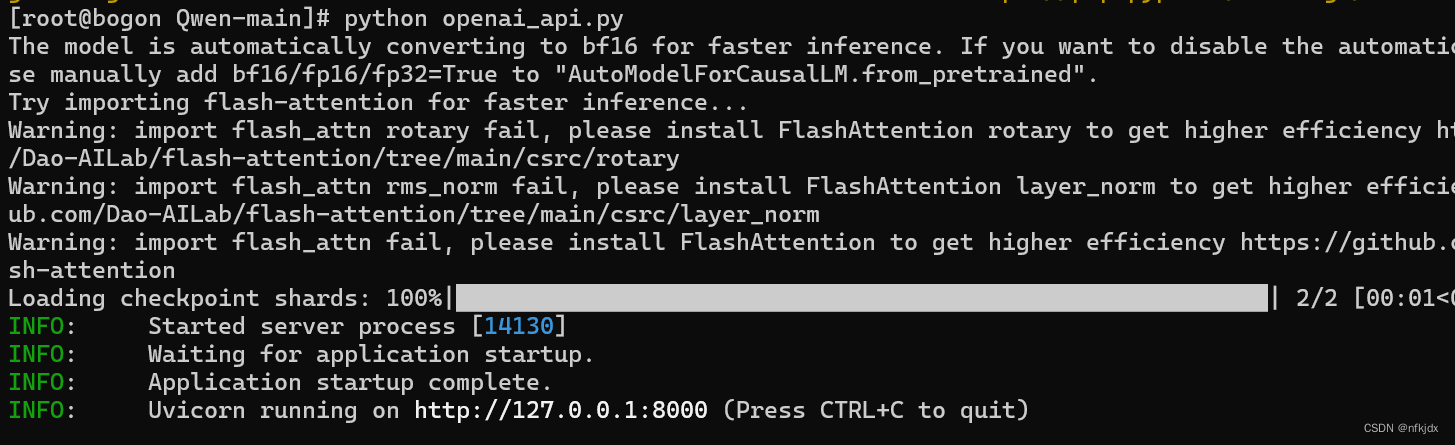
再次运行openai_api.py,如下所示:
打开生成的地址,发现无法访问:原因是我在CentOS 7下进行的,可能存在以下原因:
(1)防火墙设置:CentOS 7默认启用了防火墙(firewalld),如果您的服务运行在一个非标准端口上,或者您手动配置了防火墙规则,可能会导致无法访问。您可以通过检查防火墙规则并临时关闭防火墙来测试是否是防火墙导致的问题。
临时关闭防火墙的命令为:
sudo systemctl stop firewalld
(2)网络配置:确保您的CentOS 7服务器的网络配置正确,包括IP地址、子网掩码、网关等设置。您可以使用命令 ifconfig 或 ip addr 来查看网络配置信息。
(3)服务绑定地址:如果您的服务绑定在特定的IP地址或者网络接口上,而不是通配地址(0.0.0.0),那么只有在绑定的地址上才能访问到服务。您可以检查服务的配置文件,确保它在正确的地址上监听。
(4)服务状态:确保您的服务正在正确地运行,并且没有出现任何错误。您可以使用 systemctl status <service_name> 来查看服务的状态,并检查日志文件以获取更多信息。
(5)网络连通性:最后,确保您的本地计算机和CentOS 7服务器之间存在网络连通性。您可以尝试使用 ping 命令来测试是否可以到达服务器的IP地址。
根据您的具体情况,您可以尝试上述方法来诊断并解决无法访问CentOS 7服务器的问题。如果问题仍然存在,您可能需要提供更多的细节信息以便我们更好地帮助您解决问题。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
防火墙已经关闭,网络也配置好了,网络也连通(ping没有问题),最后估计是服务绑定了地址,于是修改openai_api.py里面的发布地址和端口:如下图所示:修改成服务器地址
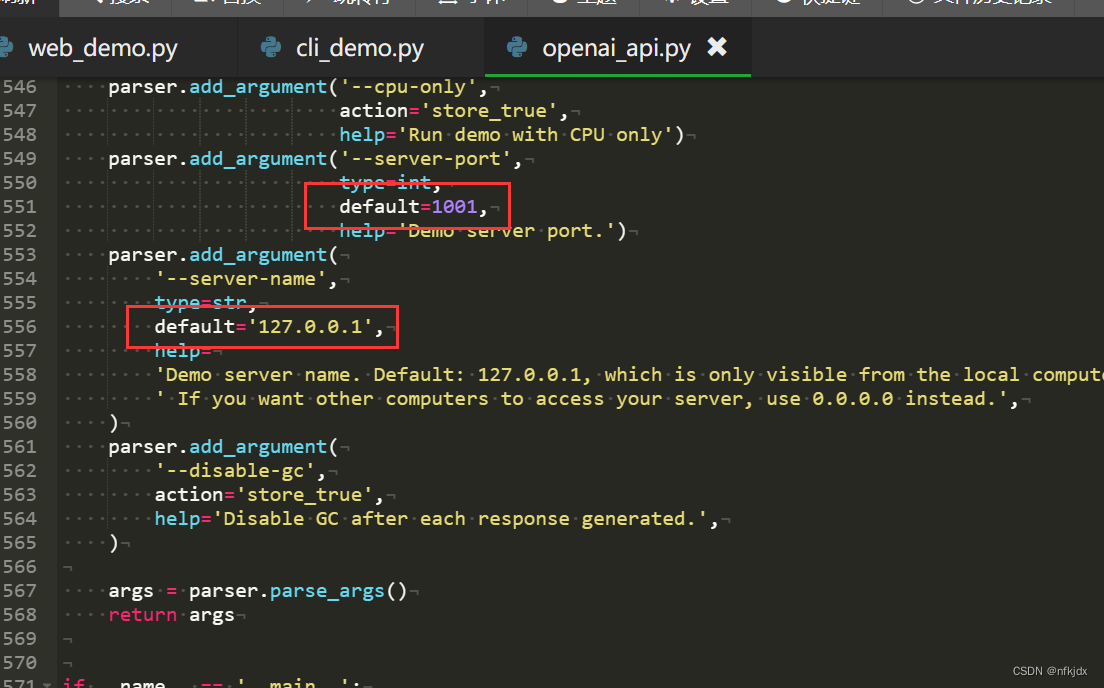
再次运行openai_api.py,如下所示:
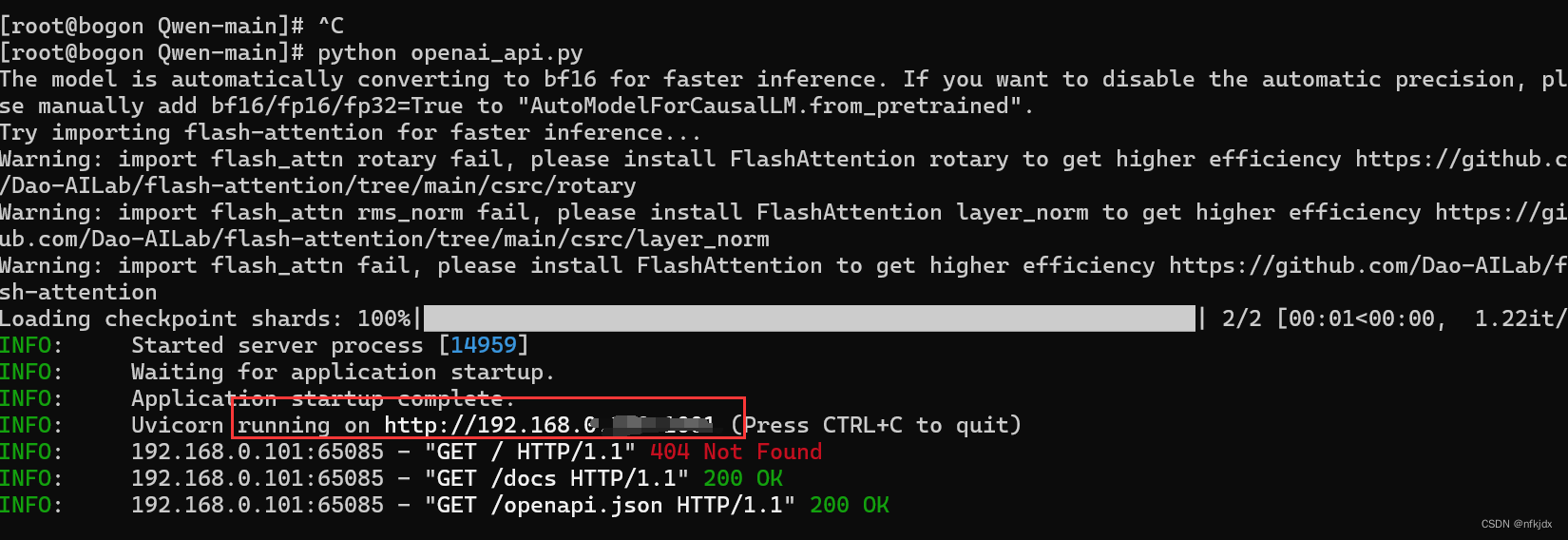
打开该地址:进行接口访问
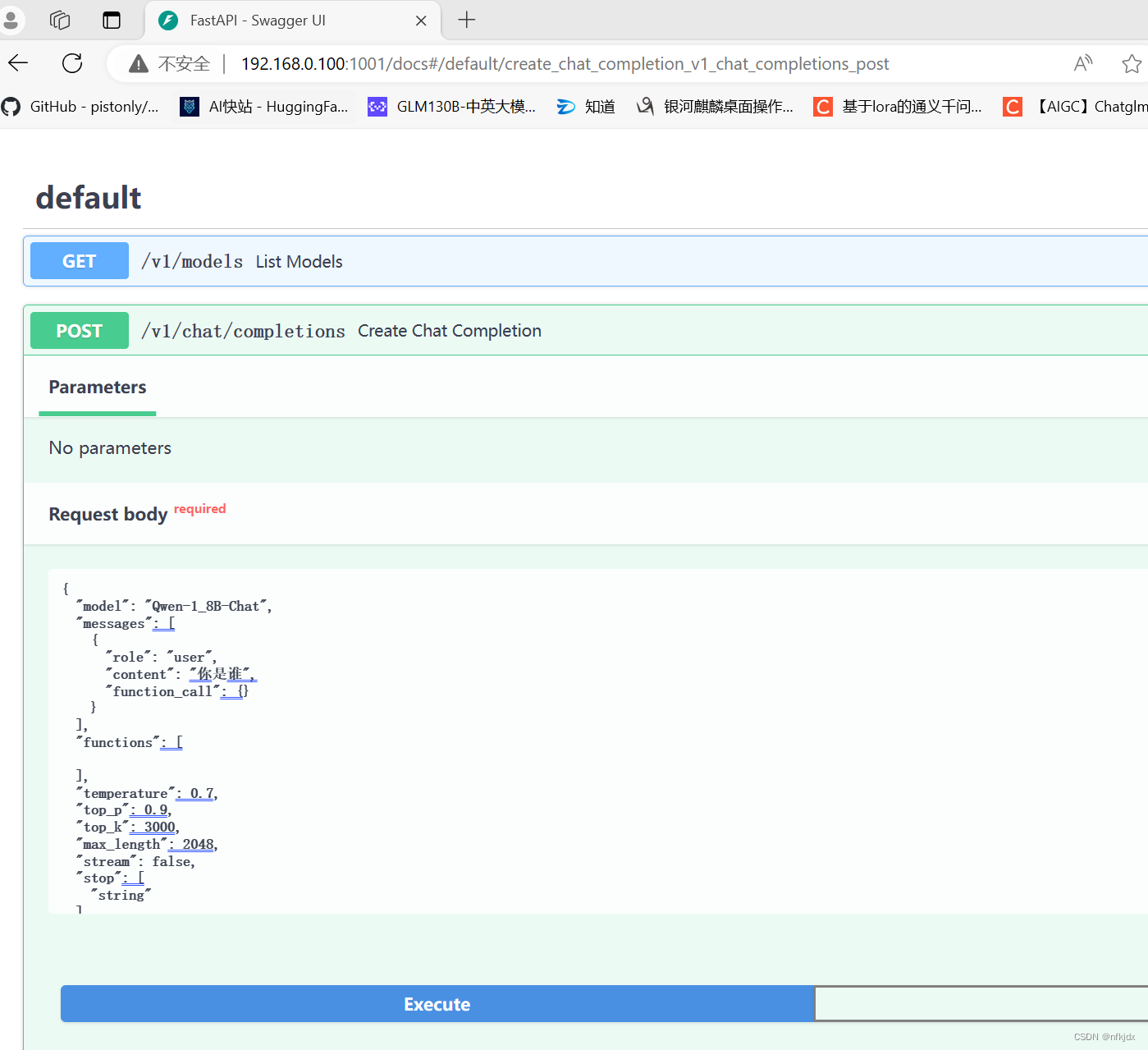
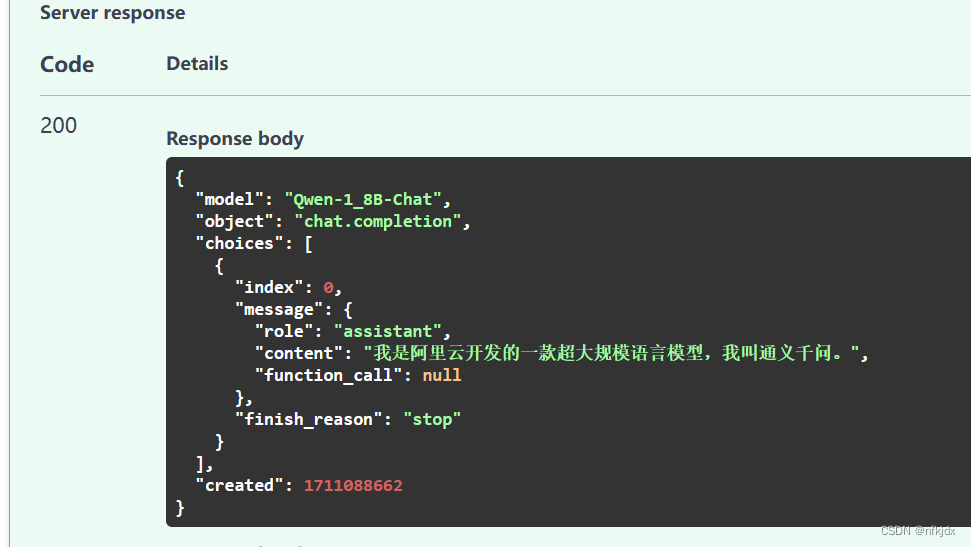
再给大家展示一下调用接口怎么实现上下文传参:
2.1 先询问关于李白的第一个问题,“function_call”: {}传的为空
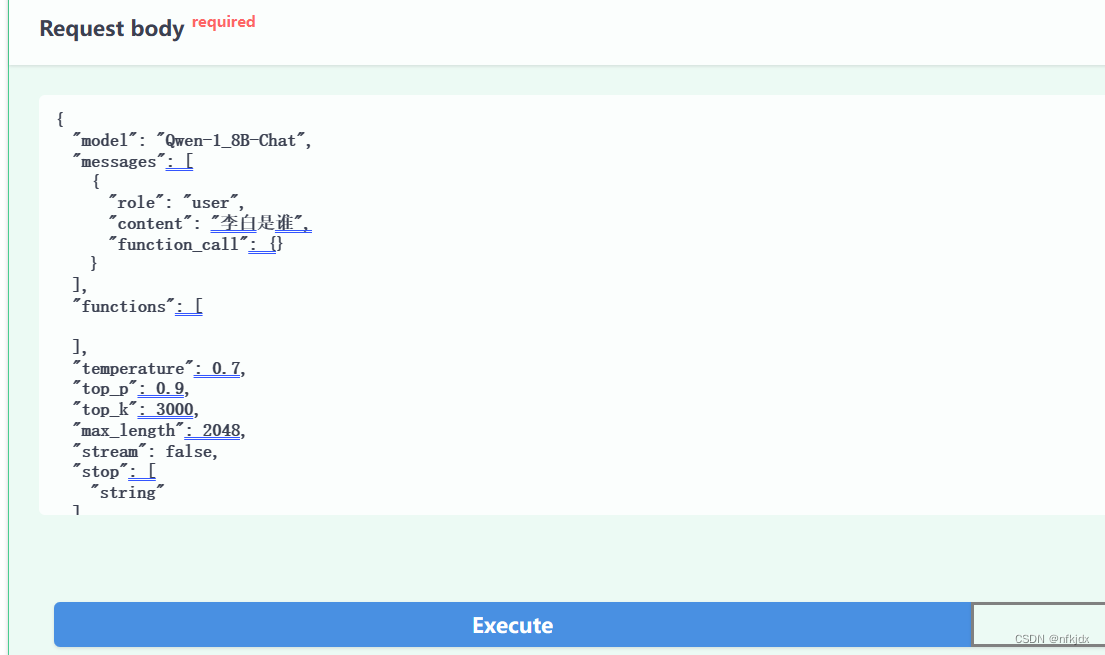
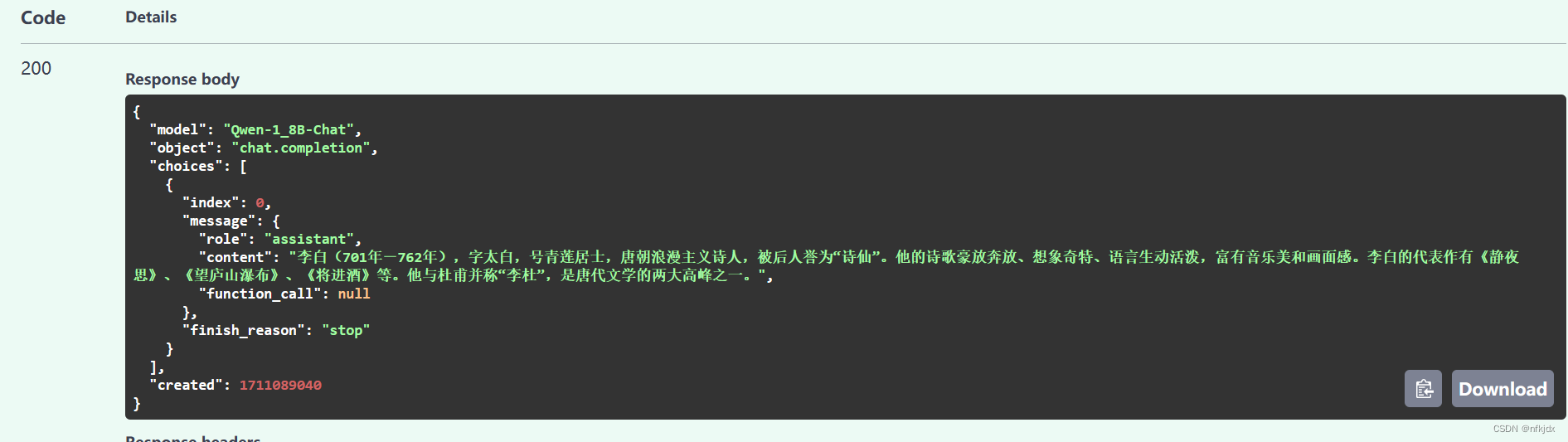
2.2 再询问关于李白的第二个问题,“function_call”: {}传入前一次返回的message信息
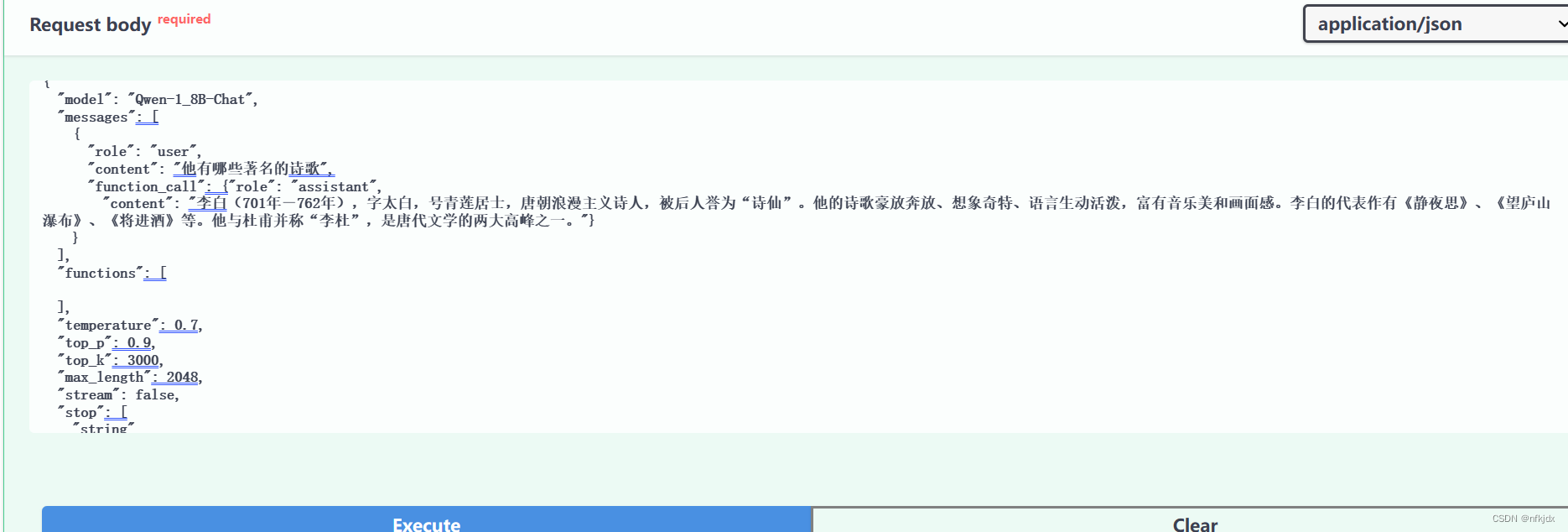
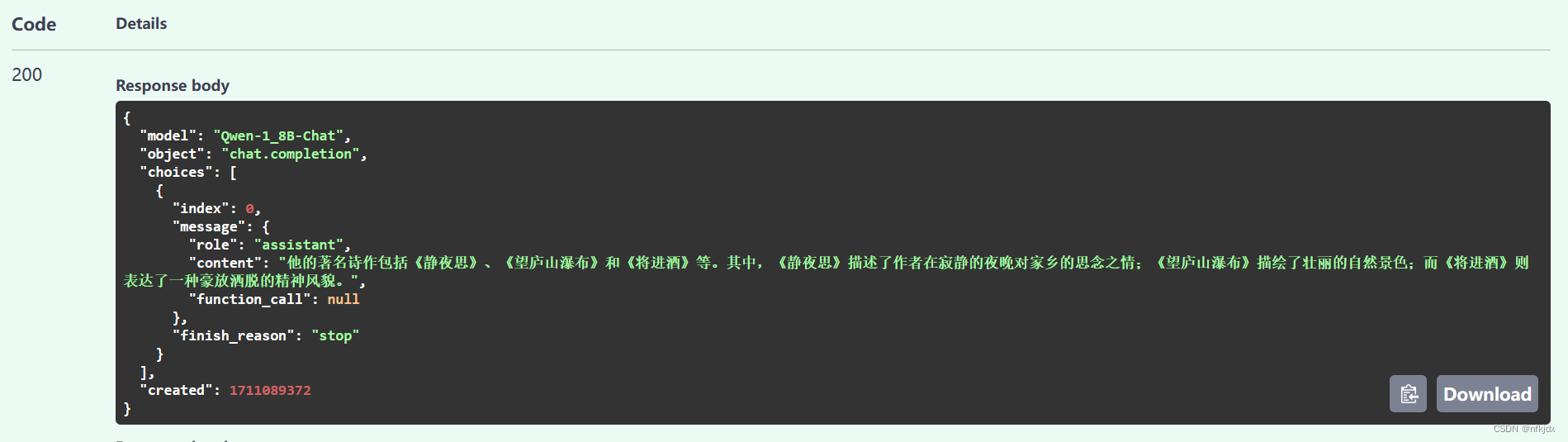
4.还可以自己模仿它的代码写一些接口进行测试和对话
五、使用Lora方法进行微调
1.准备数据集:类似以下数据格式,大家也可以参照以下网址提供的数据集
https://gitcode.com/liukangjia666/qwen_data_process/blob/main/q_answer/chat.json
- 1
[ { "id": "identity_0", "conversations": [ { "from": "user", "value": "医满意产品特点" }, { "from": "assistant", "value": "患者视角:从患者角度来看医疗服务质量水平,并回溯医院的真实管理现状。第三方评价:通过独立第三方开展数据采集分析,保持客观性。大数据分析:通过大数据分析从医院/部门/科室的真实医疗服务质量,并与全国同级同类水平的医院做比较。云端技术:系统平台不需要与医院的HIS系统对接,快速部署。" } ] }, { "id": "identity_1", "conversations": [ { "from": "user", "value": "患者体验" }, { "from": "assistant", "value": "患者体验即患者的就医体验,是患者就医时跟医疗机构的全方位的、综合的互动体验,通过患者的视角观察医疗服务机构是怎么对待他的。" } ] }, { "id": "identity_2", "conversations": [ { "from": "user", "value": "医满意产品优势" }, { "from": "assistant", "value": "专业优势:数年理论研究基础,多次参与国家标准建设,国家医患体验研究基地唯一技术支持单位。大数据分优势:纵向可以进行科室、病区间对比分析,横向全国同级同类医院对比。平台优势:提供患者体验数据管理平台,协助医院管理者进行患者体验的闭环管理。客户优势:客户遍布全国31个省1200家医院,深知客户需求及关注点。服务优势:20个省级运营推广团队,2000多名采集认证员结合质控手段,确保数据真实性,并快速响应客户需求。" } ] }, { "id": "identity_3", "conversations": [ { "from": "user", "value": "至道科技公司介绍" }, { "from": "assistant", "value": "至道科技是一家由中国工程院院士和国家“千人计划”专家领衔,专业从事医患体验管理大数据应用服务的创新型高新企业。立足管理需求,以医患视角审视医疗服务,帮助各类医疗机构与管理部门提高医疗服务质量和医患体验。首创中国患者体验评价模型、标准和管理理论构架、系列AI算法。被国家、军队权威机构指定为国家医患体验大数据平台、军队满意度评价平台、健康中国行动患者体验大数据平台唯一技术支持机构。公司设有数据采集中心、技术分析中心、学术支持中心以及管理咨询中心,服务全国超过1200家医院,覆盖全国31个省(直辖市、自治区)。如301医院、郑州大学第一附属医院、山东省立医院、福建医科学大学附属第一医院、重庆医科大学附属第一医院、华润医疗集团、通用环球医疗等。" } ] },, { "id": "identity_4", "conversations": [ { "from": "user", "value": "............." }, { "from": "assistant", "value": "............." } ] }.................... ]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
2.进入项目代码内的finetune文件夹里面,找到finetune_lora_single_gpu.sh文件

3.对finetune_lora_single_gpu.sh文件进行修改
该文件内有许多参数:如下所示
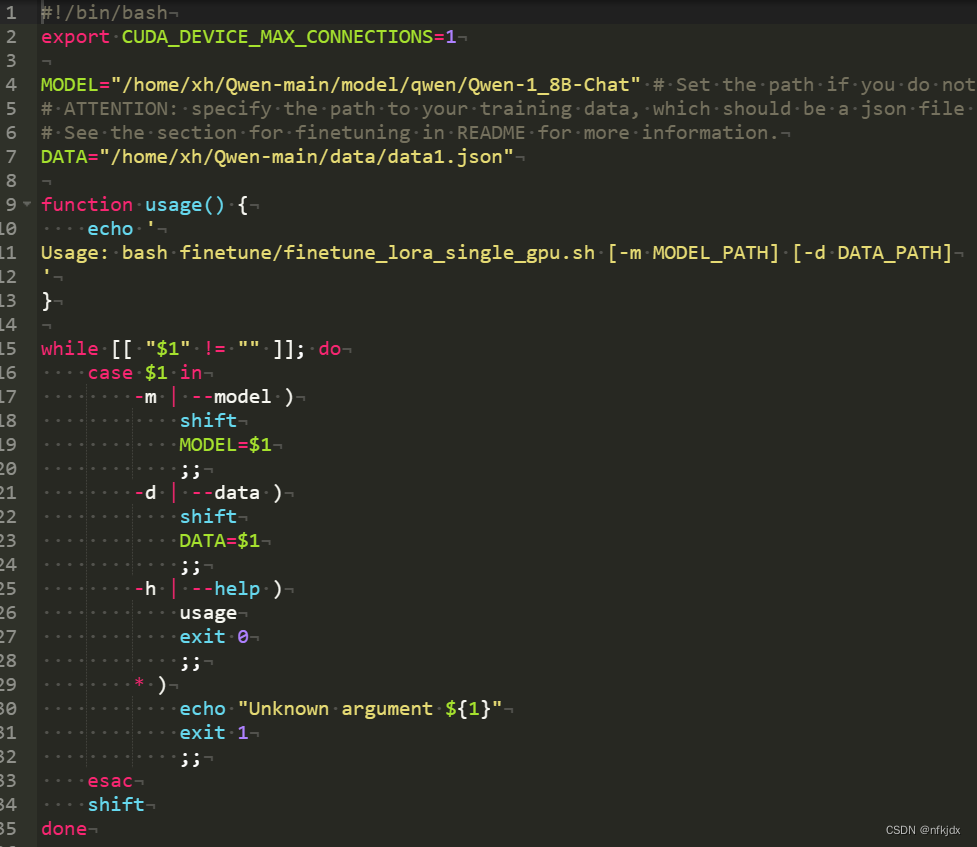
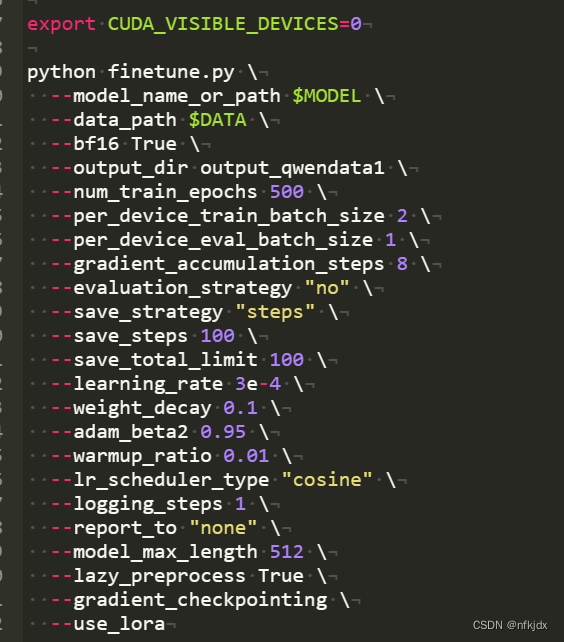
表示的含义如下:
--model_name_or_path Qwen-1_8B-Chat:指定预训练模型的名称或路径,这里是使用名为"Qwen-1_8B-Chat"的预训练模型。 --data_path chat.json:指定训练数据和验证数据的路径,这里是使用名为"chat.json"的文件。 --fp16 True:指定是否使用半精度浮点数(float16)进行训练,这里设置为True。 --output_dir output_qwen:指定输出目录,这里是将训练结果保存到名为"output_qwen"的文件夹中。 --num_train_epochs 5:指定训练的轮数,这里是训练5轮。 --per_device_train_batch_size 2:指定每个设备(如GPU)上用于训练的批次大小,这里是每个设备上训练2个样本。 --per_device_eval_batch_size 1:指定每个设备上用于评估的批次大小,这里是每个设备上评估1个样本。 --gradient_accumulation_steps 8:指定梯度累积步数,这里是梯度累积8步后再更新模型参数。 --evaluation_strategy "no":指定评估策略,这里是不进行评估。 --save_strategy "steps":指定保存策略,这里是每隔一定步数(如1000步)保存一次模型。 --save_steps 1000:指定保存步数,这里是每隔1000步保存一次模型。 --save_total_limit 10:指定最多保存的模型数量,这里是最多保存10个模型。 --learning_rate 3e-4:指定学习率,这里是3e-4。 --weight_decay 0.1:指定权重衰减系数,这里是0.1。 --adam_beta2 0.95:指定Adam优化器的beta2参数,这里是0.95。 --warmup_ratio 0.01:指定预热比例,这里是预热比例为总步数的1%。 --lr_scheduler_type "cosine":指定学习率调度器类型,这里是余弦退火调度器。 --logging_steps 1:指定日志记录步数,这里是每1步记录一次日志。 --report_to "none":指定报告目标,这里是不报告任何信息。 --model_max_length 512:指定模型的最大输入长度,这里是512个字符。 --lazy_preprocess True:指定是否使用懒加载预处理,这里设置为True。 --gradient_checkpointing:启用梯度检查点技术,可以在训练过程中节省显存并加速训练。 --use_lora:指定是否使用LORA(Layer-wise Relevance Analysis)技术,这里设置为True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
4.然后大家根据自己的需求进行修改调整:其中模型路径和微调数据路径必须修改,
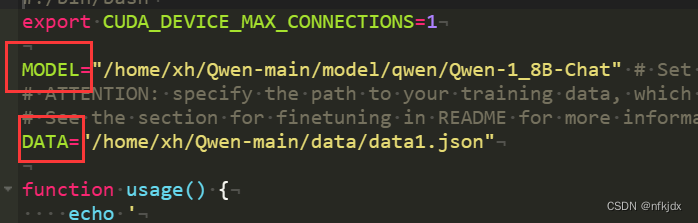
接着就是:
【结果输出目录output_dir output_qwen , 训练轮数num_train_epochs,保存步数save_steps,最多保存模型数量save_total_limit,学习率learning_rate等,根据自己的实际情况进行调整。】
4.修改好之后,运行finetune_lora_single_gpu.sh文件,进行微调
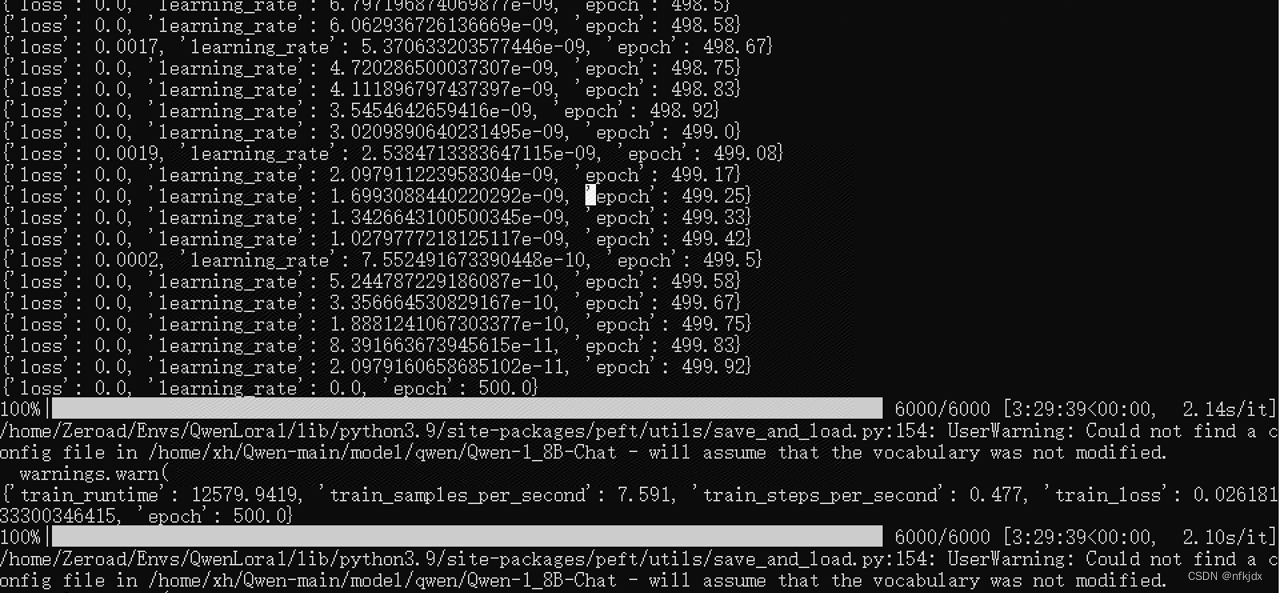
六、使用微调之后的模型进行测试验证
1.找到生成的结果文件
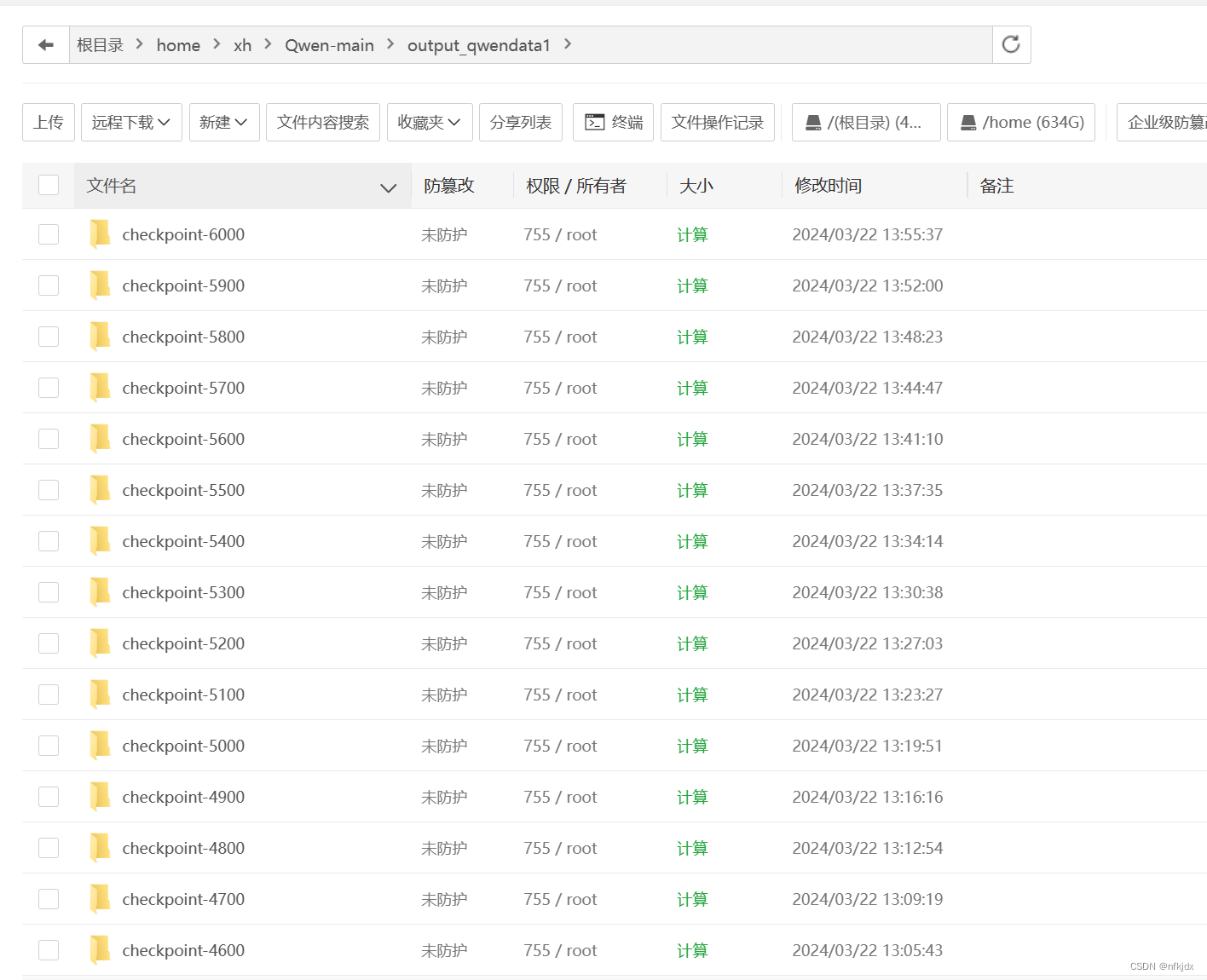
2.自己撰写了测试代码W_Test1.py:其中tokenizer = AutoTokenizer.from_pretrained() 需要填写原模型路径;model = AutoPeftModelForCausalLM.from_pretrained() 需要填写微调生成的模型权重,我这里选择了checkpoint-3600
from transformers import AutoModelForCausalLM, AutoTokenizer from transformers.generation import GenerationConfig # Note: The default behavior now has injection attack prevention off. tokenizer = AutoTokenizer.from_pretrained("/home/xh/Qwen-main/model/qwen/Qwen-1_8B-Chat", trust_remote_code=True) from peft import AutoPeftModelForCausalLM model = AutoPeftModelForCausalLM.from_pretrained( "/home/xh/Qwen-main/output_qwendata1/checkpoint-3600", # path to the output directory device_map="auto", trust_remote_code=True ).eval() stop_stream=False past_key_values, history = None, [] while True: query = input("\n用户:") if query.strip() == "stop": break if query.strip() == "clear": past_key_values, history = None, [] os.system(clear_command) print(welcome_prompt) continue print("\nQwen:", end="") current_length = 0 response, history = model.chat(tokenizer, query, history=history) print(response[current_length:], end="", flush=True) current_length = len(response) print("")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
3.运行W_Test1.py进行测试:
这是训练的私有数据:
先对私有数据进行提问:
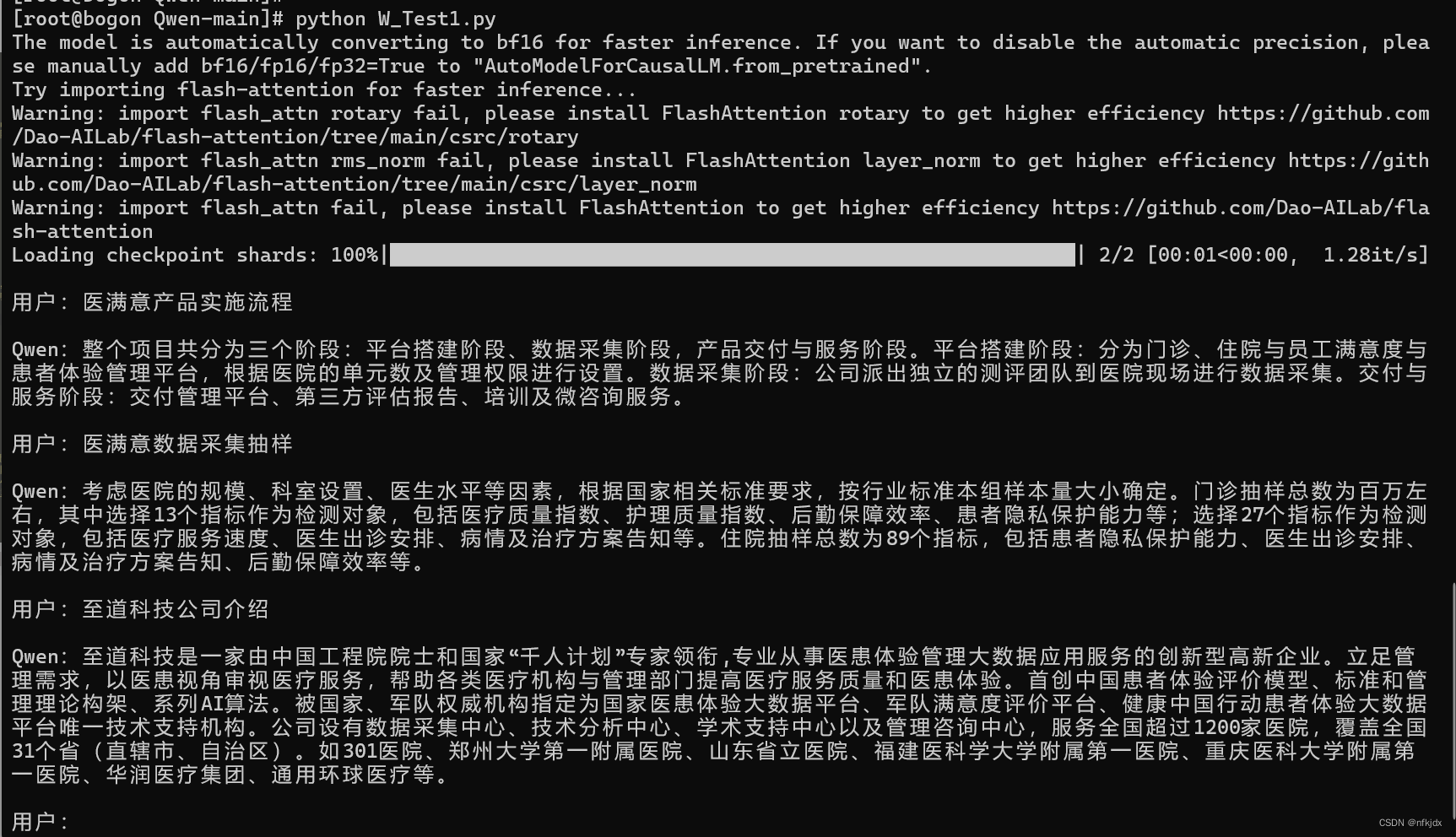
接着再测试灾难性遗忘问题和上下文问题:

发现微调的效果还是很好的且不会发生灾难性遗忘!
4.将微调模型引入web_demo.py中:只需要在该文件中加入以下代码即可
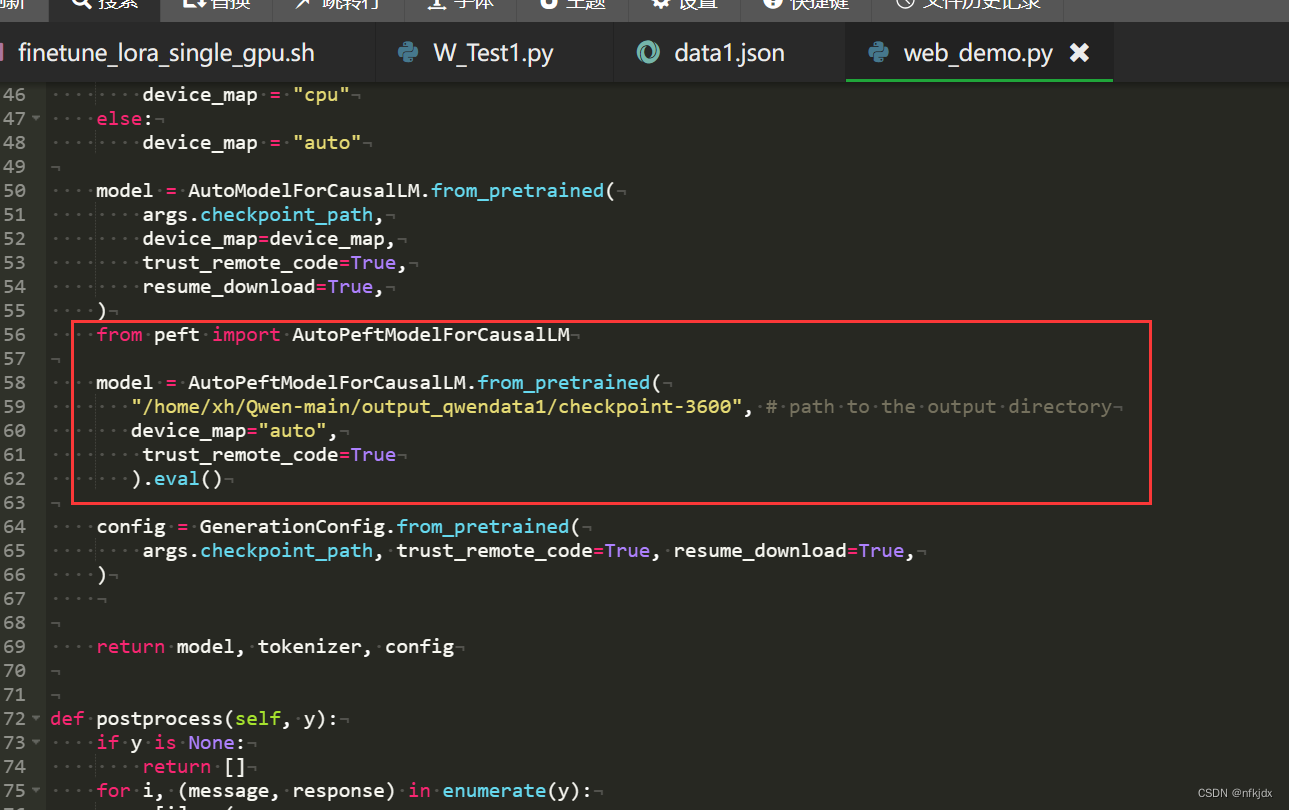
model = AutoPeftModelForCausalLM.from_pretrained(
"/home/xh/Qwen-main/output_qwendata1/checkpoint-3600", # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
- 1
- 2
- 3
- 4
- 5
接着运行web_demo.py文件,打开地址:
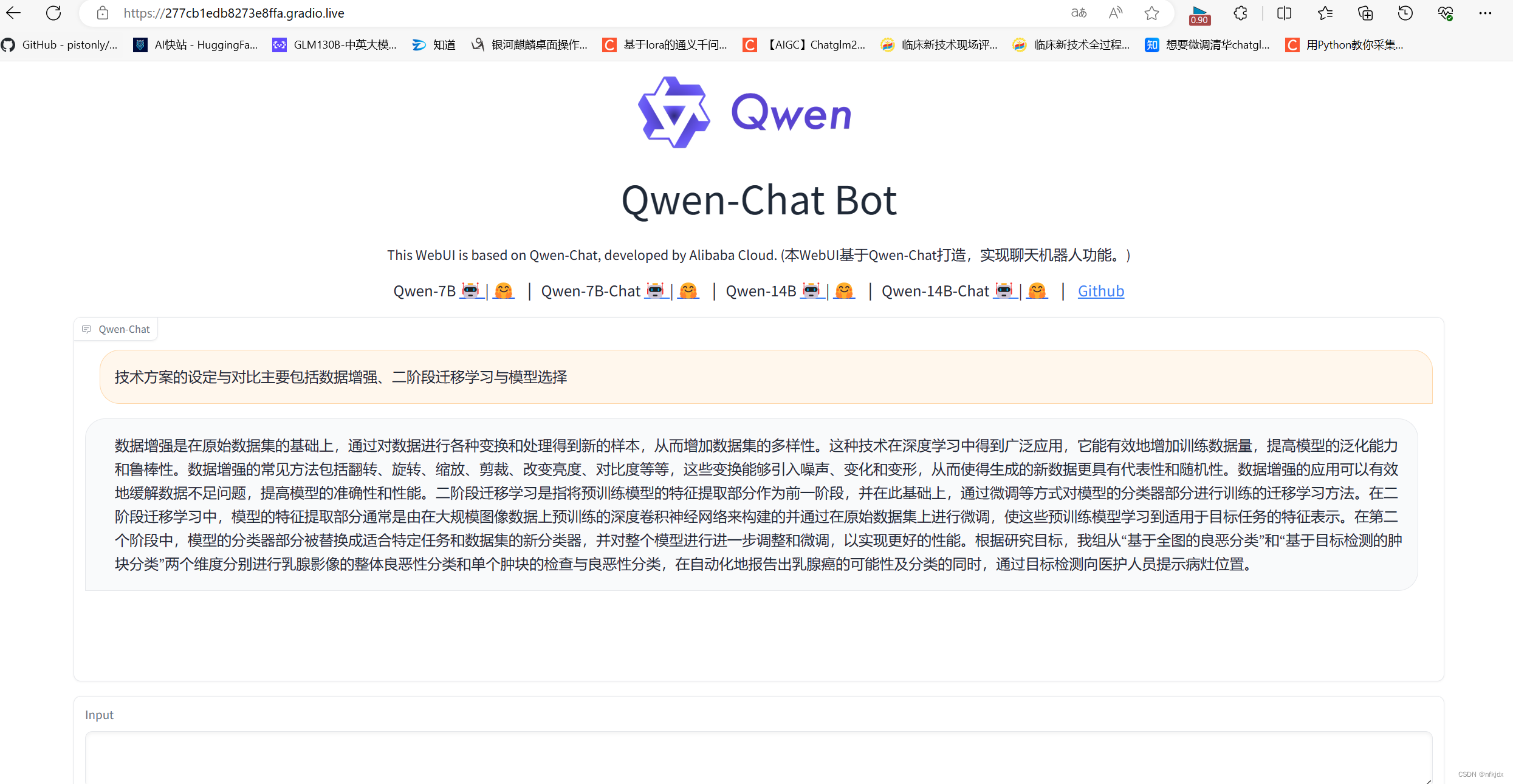
这是训练的私有数据:以下数据时本人参加竞赛时自己写的话语,因此也算私有的
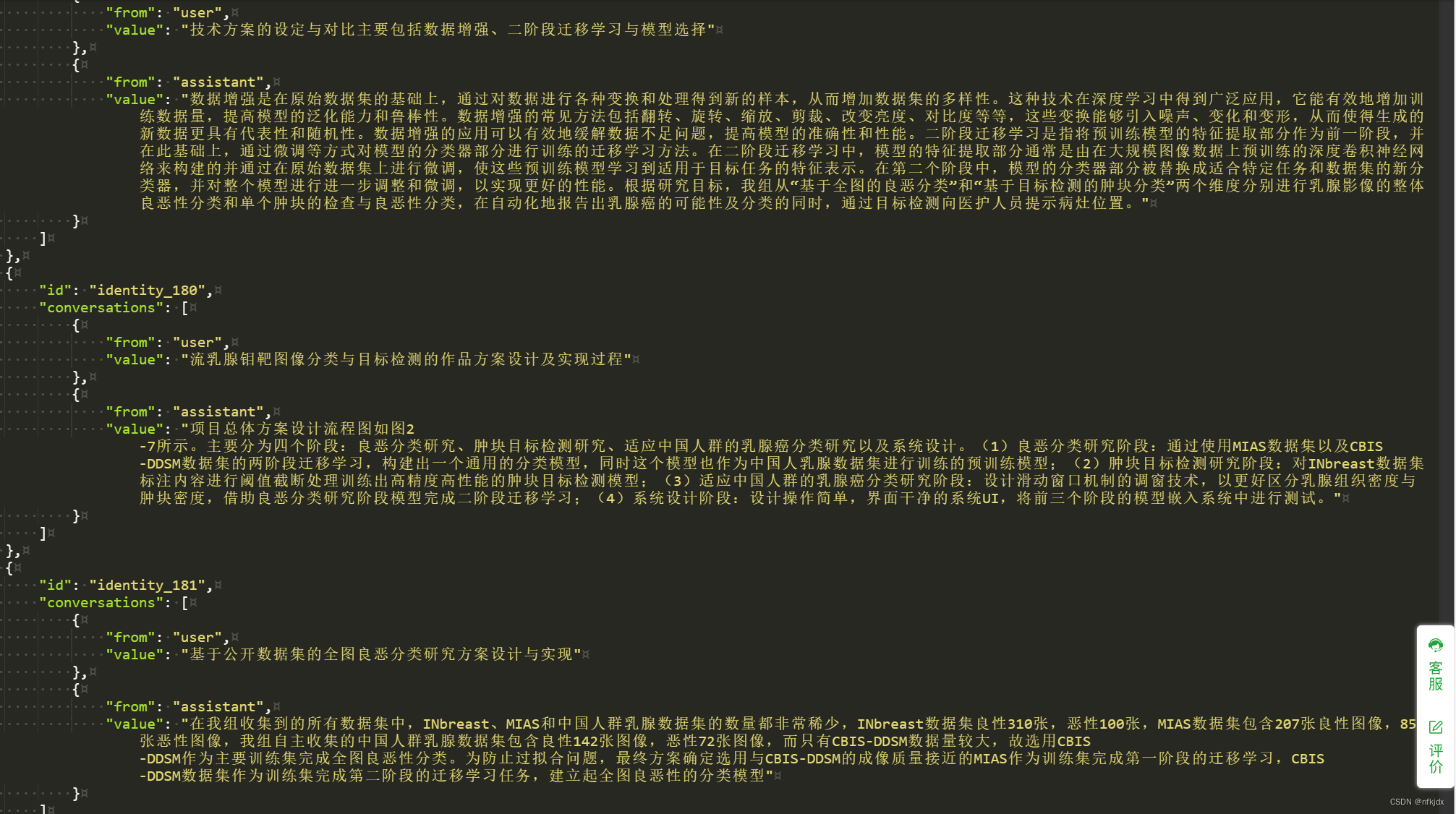
先对私有数据进行提问:

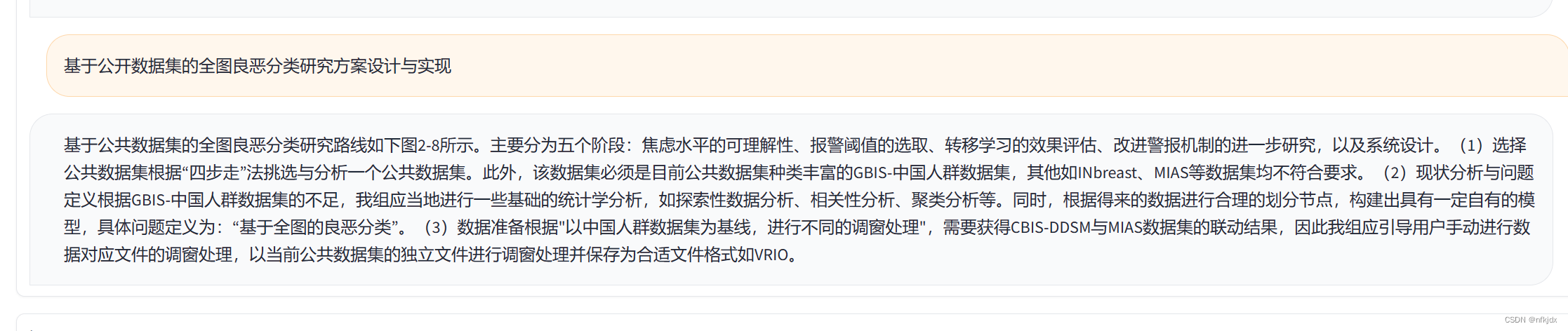
最后再测试灾难性遗忘问题和上下文问题: