
- 1opencv python 把图(cv2下)BGR转RGB,且HWC转CHW_opencv transpose(2,0,1)
- 22024年网易Java岗面试必问,2024蚂蚁金服Java面试真题解析
- 3通用图形处理单元GPGPU计算管线(General Purpose computation on Graphics Processing Units)介绍
- 4Gitee崩了?大量仓库被关闭!官方答复“迫于无奈”
- 5国开大学2024《学前儿童游戏指导》(统设课)
- 6多光谱遥感时空融合综述、分类、方法、应用以及未来方向_多光谱遥感应用
- 7Blender图解教程:使用运动路径(Motion Path)观察骨骼的运动轨迹_blender motion path
- 8用Pygame写俄罗斯方块_pygame俄罗斯方块代码
- 9数据结构之链表(Java实现)_java实现链表
- 10windows下启动Apache报443错误!
如何构造强一致性系统?理解数据一致性里的2PC和TCC模式原理,以及如何做(有图)_tcc一致性 两个系统
赞
踩
背景
首先,读这篇文章的时候你应该先了解什么是事务、什么是分布式事务。
我这里举2个例子,典型场景有两个:
1、一个应用有两个数据库,一个数据库是订单,另一个数据库是积分,要求下订单的时候同时给用户积分,不能给了积分、订单却没下成,也不能订单下成了不给积分。
2、一个应用有两个微服务,调用订单服务返回HTTP 200没什么问题,但是到积分那里返回了HTTP 500,此时因为异常抛出,前端只能提示下单失败,但实际订单已经订完了。
2PC模式
那我们为了解决问题,最先想到的就是俩数据源的事务一起提交不就完事了。但限于各种业务逻辑处理可能会有报错,所以这事得在业务代码之外封装一层框架,把业务代码代理起来才能搞。
因为多个数据库连接管理起来方便,2PC模式一般适用于单体架构,一个单体对多个数据库。可以使用atomikos之类的框架,执行过程看图,不废话。
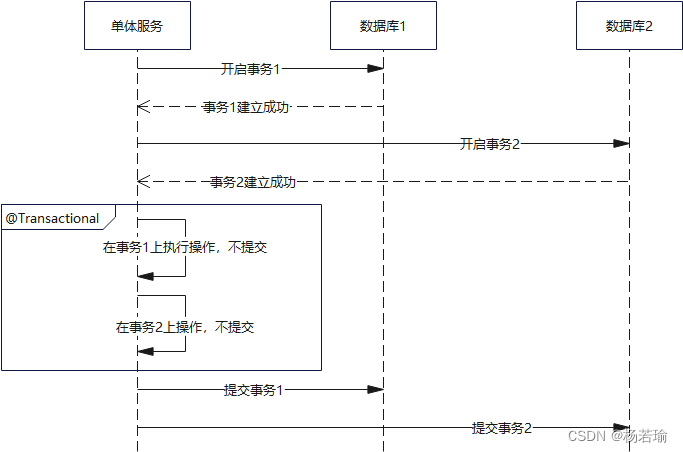
无论出没出异常,所有的提交操作都会被重写的提交方法捕获,等待整个程序段执行完毕后再提交,这个被拦截的过程叫做预提交。如果这个时候有哪个环节出问题抛出异常了,则会进行整体回滚。
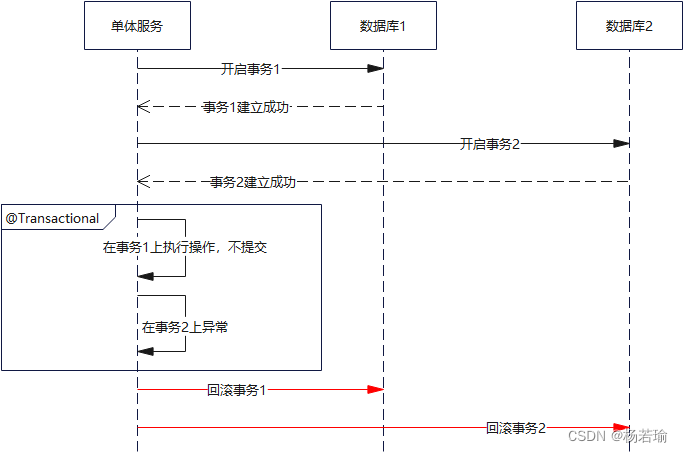
简单吧,这就是2PC的原理。说了半天原理,咱上一下核心代码:
XADataSource dataSource=new DruidXADataSource();
dataSource.setUrl(这里填写Url);
dataSource.setUsername(这里填写用户名);
dataSource.setPassword(这里填写密码);
dataSource.setDriverClassName(这里填写驱动);
dataSource.setInitialSize(最小连接池大小);
dataSource.setMaxActive(最大连接池大小);
dataSource.setValidationQuery("SELECT 1");
AtomikosDataSourceBean atomikosDs = new AtomikosDataSourceBean();
atomikosDs.setXaDataSource(dataSource);
atomikosDs.setMaxPoolSize(最大连接池大小);
atomikosDs.setMinPoolSize(最小连接池大小);
atomikosDs.setUniqueResourceName(全局唯一编码,比如ds1、ds2);
atomikosDs.init();
// 拿到连接,随便做业务,你可以产生多个Connection
Connection conn1 = atomikosDs.getConnection()
// 这个事务管理器是全局唯一、线程绑定的
TransactionManager tx=new UserTransactionManager();
// 开启分布式事务一致性
tx.begin();
// 这里写你的业务代码
// 统一提交
tx.commit();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
如果你想让Spring Boot或Spring Cloud用注解来接管事务,那就写以下这两个类:
import com.atomikos.icatch.jta.UserTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionException;
import org.springframework.transaction.support.AbstractPlatformTransactionManager;
import org.springframework.transaction.support.DefaultTransactionStatus;
/**
* 事务管理器
* @author 杨若瑜
*/
public class DbTransactionManager extends AbstractPlatformTransactionManager {
@Override
protected Object doGetTransaction() throws TransactionException {
return new UserTransactionManager();
}
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) throws TransactionException {
UserTransactionManager tx = (UserTransactionManager) transaction;
try {
tx.begin();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
protected void doCommit(DefaultTransactionStatus status) throws TransactionException {
UserTransactionManager tx = (UserTransactionManager) status.getTransaction();
try {
tx.commit();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
protected void doRollback(DefaultTransactionStatus status) throws TransactionException {
UserTransactionManager tx = (UserTransactionManager) status.getTransaction();
try {
tx.rollback();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
/**
* 事务管理器配置
* @author 杨若瑜
*/
@Configuration
public class TransactionConfig {
@Bean
public PlatformTransactionManager transactionManager() {
return new DbTransactionManager();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
至于数据源在哪里产生,这个就随意了,哪里都可以用。
TCC模式
首先我们先了解TCC模式下数据的状态转换
Try操作:尝试执行,数据本体不会发生变更
Confirm操作:真正执行,数据本体会发生真实变更
Cancel操作:取消执行,数据本体会恢复到Try之前的状态
图中白色的部分并不会被查询出来(类似于伪删除的查询),而蓝绿色的部分会被正常检索到。
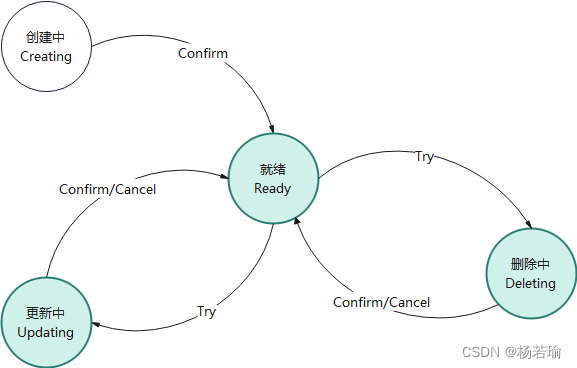
那如果分布式服务应该如何做呢?看下面这张图,仔细去悟你就明白了。
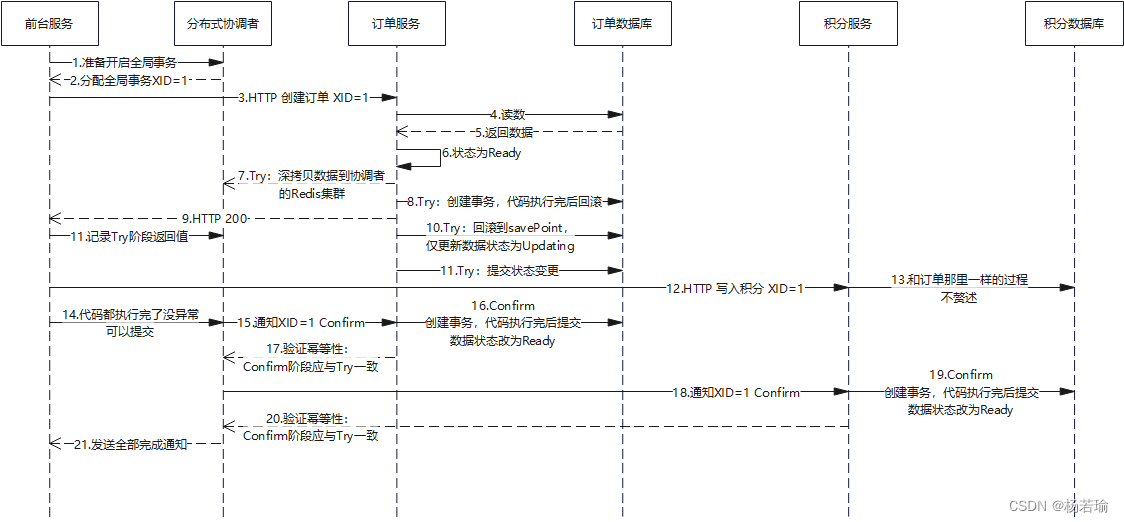
这里只展现了Try和Confirm阶段,如果是出现了异常,则由前台服务通知分布式协调者向所有服务发送Cancel指令。这里需要注意的是,我们是假设Confirm和Cancel不会抛出任何异常,如果这俩阶段出现了异常,那必须要人工介入了。
图中所展现的方法非常的简单粗暴,事实上这些都可以被Seata接管。
这里面需要注意的是,如果为了保证数据的强一致性,第5步,服务会一直卡死在那里等待状态变为Ready。如果不想效率下降,那只有一个办法:抛出异常,让前端知道这个数据在Updating,触发Cancel。
第7步中,为什么要把数据深拷贝到协调者的Redis中,主要是为了在Cancel阶段能直接用Redis中的原始数据覆盖。
而且在此过程中需要注意考虑幂等性原则,通俗的说:如果你try的时候随机产生了一个UUID,传递给积分服务,然后Confirm的时候又产生了一个新的UUID,自然积分服务拿到新的UUID会引发不可预知的错误(比如记录错误的订单主键)。因此XID和你在Try执行过程中产生的一切随机产生的变量、受到其他数据状态影响的变量都应当被缓存记录并在Confirm的时候拿出来,也就是说我如果读某个数据的状态为1,使我这次按1的逻辑去走,几秒之后别的用户把它改成了2,那我还是按1的逻辑去走,我只管按几秒前的上下文去处理,具体做底层架构的时候可以将getter和setter方法都代理起来,如果我Try的时候调和Confirm的时候调出来的结果不一样,那可不行,所以不符合幂等性时,整个GlobalTransaction都要回滚。
对于第10步中,其实所有的数据都没有被真正更新,只是更新了数据的状态,而且这里没有提到的是还有新创建的数据,状态应当是Creating,在其他功能并发检索时,应当在搜索条件中过滤掉状态为Creating的数据。
TCC的各种异常情况
突然微服务宕了
我们要考虑重启的时候移除所有Creating的数据,并将所有Updating的数据改为Ready状态。写一个Spring Boot初始化会省很多事。这里的Creating的数据因为之前宕机所以一定是调用方认为它是失败的,早已通知其他服务Cancel掉了。
突然分布式协调者宕机了
这就显示出来我们Redis存在的意义了,你有多台分布式协调者,调用方调不了它,就会重试到另一台分布式协调者上,数据还在Redis里,可以保证业务的连续。
分布式协调者在Confirm到一半的时候宕机了怎么办
没关系,同上,调用方发现在第14步发出去了返回500、Connection Refused等问题,就会进行三次重试,只要还有1个能用的协调者,就会继续发送Confirm指令。
那如果整个机房停电了呢?再结合第一个和第三个问题。
额……尽管很极端。但是还是有解决办法的,微服务自己宕机重启后会取消所有还在分布式事务里的数据,同样的,分布式协调者在启动的时候也会对所有还未Confirm的数据全部Cancel掉,挨个给微服务发指令,假设在停机的前0.01秒中别的协调者已经完成Confirm并已回写Redis,集群启动后这些数据就不会再被Cancel掉了。
后记
写这篇文章挺烧脑,不管怎样,给点个赞呗。

