
- 1利用AI设计从线稿到效果图,SD室内设计轻松搞定_sd线稿转效果图
- 2BeautifulSoup-爬虫案例(一)_beautifulsoup爬虫案例
- 3Python实现俄罗斯方块(带完整源码)_python俄罗斯方块
- 4NLP语料库索引_21世纪世宗计划语料库
- 5ip地址告诉别人安全吗?ip地址告诉别人会有什么风险_对外提供公网ip和端口危险吗
- 6cadence—virtuosoic617的使用技巧收集区_scs文件cadence
- 7第九章 Spring AI API中文版 - Ollama Embeddings API_ollama embedding api
- 8开发者看亚马逊云科技1024_apecloud
- 9请教Table()使用方法 select * from table(....)_select * from table()
- 10DNS负载均衡的底层实现原理
Tensorflow之知识图谱---(2)Keras快速入门_tensorflow 知识图谱
赞
踩
目录
一、数据集:鸢尾花数据集 iris
一般的机器学习工具自带iris数据集 --- sklearn包中
- sklearn包安装:一定要注意版本冲突!!!
pip install -U scikit-learn
- 下载好后直接调用
from sklearn.datasets import load_iris
data = load_iris()
二、Keras顺序模型Sequential()
- import numpy as np
- import tensorflow as tf
-
- from sklearn.datasets import load_iris
- data=load_iris()
- iris_target = data.target
- iris_data = np.float32(data.data)
-
- iris_target = np.float32(tf.keras.utils.to_categorical(iris_target,num_classes=3))
- iris_data = tf.data.Dataset.from_tensor_slices(iris_data).batch(50)
- iris_target = tf.data.Dataset.from_tensor_slices(iris_target).batch(50)
-
- model = tf.keras.models.Sequential()
-
- model.add(tf.keras.layers.Dense(32,activation='relu'))
- model.add(tf.keras.layers.Dense(64,activation='relu'))
- model.add(tf.keras.layers.Dense(3,activation='softmax'))
-
- opt = tf.optimizers.Adam(1e-3)
-
- for epoch in range(1000):
- for _data,label in zip(iris_data,iris_target):
- with tf.GradientTape() as tape:
- logits = model(_data)
- loss_value = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=label,y_pred =logits))
- grads = tape.gradient(loss_value,model.trainable_variables)
- opt.apply_gradients(zip(grads,model.trainable_variables))
-
- print("epoch",epoch,"'s training loss is:",loss_value.numpy())
- 顺序模型:先定义model 再model.add()来添加网络层
model = tf.keras.models.Sequential() model.add(tf.keras.layers.Dense(32,activation='relu')) model.add(tf.keras.layers.Dense(64,activation='relu')) model.add(tf.keras.layers.Dense(3,activation='softmax'))
- 模型训练 初始化思路
for epoch in range(1000):
for _data,label in zip(iris_data,iris_target):
with tf.GradientTape() as tape:
logits = model(_data)
loss_value = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_true=label,y_pred =logits))
grads = tape.gradient(loss_value,model.trainable_variables)
opt.apply_gradients(zip(grads,model.trainable_variables))
- tf.GradientTape() :梯度求解器(求导)
- logits:模型预测结果
- loss_value:误差值
- grads:计算误差的幅度
- opt.apply_gradients:根据误差幅度进行梯度更新
- trainable_variables:模型中可训练的变量
三、使用Keras函数式编程
- 顺序模型自由度有较大影响:需要对输入数据进行重新计算时,顺序模型不适用。
- 函数式编程:只需要建立模型,导入输入和输出的“形式参数”即可。
- #1.输入端
- inputs= tf.keras.layers.Input(shape=(4,))
-
- #2.中间层
- x = tf.keras.layers.Dense(32,activation='relu')(inputs)
- x = tf.keras.layers.Dense(64,activation='relu')(x)
-
- #3.输出端:直接将计算的最后一个层座位输出端
- predictions= tf.keras.layers.Dense(3,activation='softmax')(x)
-
- model= tf.keras.Model(inputs=inputs,outputs = predictions)
1.Input函数
tf.keras.Input(
shape=None, #形状元组 shape=(32,)---输入是32维向量
batch_size=None, #静态批量的大小--整数
name=None, #自定图层名字(一般不要重复
dtype=None, #数据类型(float32、float64...
sparse=False, #布尔值False/True 是否创建稀疏占位符
tensor=None...) #可选现有张量包裹到Input图层 True--不创建占位符张量
2.用model自带save函数保存数据
- 保存模型
- #保存模型
- model.save('./saver/model2-2.h5')
- 复用模型
- import numpy as np
- import tensorflow as tf
-
- from sklearn.datasets import load_iris
- data=load_iris()
- iris_target = data.target
- iris_data = np.float32(data.data)
- iris_target = np.float32(tf.keras.utils.to_categorical(iris_target,num_classes=3))
-
- new_model = tf.keras.models.load_model('./saver/model2-2.h5')
- new_prediction = new_model.predict(iris_data)
-
- print(tf.argmax(new_prediction,axis=-1))
- 预测结果:
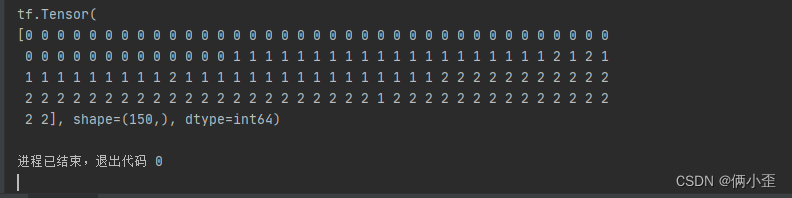
四、使用TensorFlow标准化编译
- 使用fit函数和compile函数对数据进行载入和参数分析
- import numpy as np
- import tensorflow as tf
-
- from sklearn.datasets import load_iris
- data=load_iris()
- iris_target = data.target
- iris_data = np.float32(data.data)
- iris_target = np.float32(tf.keras.utils.to_categorical(iris_target,num_classes=3))
-
- #输入格式有改变 以(iris_data,iris_target)形式输入数据和标签
- train_data = tf.data.Dataset.from_tensor_slices((iris_data,iris_target)).batch(128)
-
- input_xs = tf.keras.layers.Input(shape=(4,),name="input_xs")
- out = tf.keras.layers.Dense(32,activation="relu",name="dense_1")(input_xs)
- out = tf.keras.layers.Dense(64,activation="relu",name="dense_2")(out)
- logits = tf.keras.layers.Dense(3,activation='softmax',name='predictions')(out)
-
- model = tf.keras.Model(inputs = input_xs,outputs = logits)
- opt = tf.optimizers.Adam(1e-3)
-
- model.compile(optimizer=tf.optimizers.Adam(1e-3),loss=tf.losses.categorical_crossentropy,metrics=['accuracy'])
-
- model.fit(train_data,epochs=500)
-
- score = model.evaluate(iris_data,iris_target)
- print("last score:",score)
1.数据输入形式的改变
#输入格式有改变 以(iris_data,iris_target)形式输入数据和标签
train_data = tf.data.Dataset.from_tensor_slices((iris_data,iris_target)).batch(128)
2.构建网络层级
- input--Dense--Dense....
input_xs = tf.keras.layers.Input(shape=(4,),name="input_xs") out = tf.keras.layers.Dense(32,activation="relu",name="dense_1")(input_xs) out = tf.keras.layers.Dense(64,activation="relu",name="dense_2")(out) logits = tf.keras.layers.Dense(3,activation='softmax',name='predictions')(out)
3.建立模型 Model
- 仅传递输入和输出
- tf.keras.Model( inputs =xxx,outputs =xxx )
model = tf.keras.Model(inputs = input_xs,outputs = logits)
4.编译模型 compile
- 包含优化器optimizer、损失loss、评价指标metrics
model.compile(optimizer=tf.optimizers.Adam(1e-3),loss=tf.losses.categorical_crossentropy,metrics=['accuracy'])
5.训练模型 fit
- 以给定的数量轮次来训练模型
- 参数:x---输入、y--输出、batch_size--每次梯度更新的样本数(默认32)、epochs--迭代轮次
model.fit(train_data,epochs=500)or
model.fit(x=iris_data,y=iris_target,batch_size=128,epochs=500)
6.模型评价 evaluate
score = model.evaluate(iris_data,iris_target)
print("last score:",score)
Epoch 1/500
2/2 [==============================] - 0s 499us/step - loss: 1.4749 - accuracy: 0.3333
Epoch 2/500
2/2 [==============================] - 0s 502us/step - loss: 1.3558 - accuracy: 0.4267...
Epoch 498/500
2/2 [==============================] - 0s 0s/step - loss: 0.0908 - accuracy: 0.9667
Epoch 499/500
2/2 [==============================] - 0s 264us/step - loss: 0.0907 - accuracy: 0.9667
Epoch 500/500
2/2 [==============================] - 0s 495us/step - loss: 0.0905 - accuracy: 0.9667
5/5 [==============================] - 0s 444us/step - loss: 0.0902 - accuracy: 0.9667last score: [0.09018253535032272, 0.9666666388511658]

