
- 1【2023年电赛国一必备】H题报告模板--可直接使用_电赛设计报告模板
- 2Docker安装kafka_docker安装kafka最新版
- 3基于分散遗传算法的多Agent系统分散任务分配_遗传算法任务分配
- 4【AI Agent系列】【MetaGPT多智能体学习】1. 再理解 AI Agent - 经典案例和热门框架综述_ai agent框架
- 5【leetcode】203. 移除链表元素(python)_python 移除链表元素完整代码
- 6【贪心思想】兄弟总爱贪小便宜,原来是把贪心算法掌握得如此熟练【经典例题讲解】
- 7新国立祭出视频生成“无限宝石“:2300帧仅需5分钟,提速100倍_video-infinity
- 8225. Web前端网页制作 520粒子动画浪漫表白计时中 大学生期末大作业 html
- 9upload-labs-01_upload-labs-linux 1
- 10Pytorch实现ResNet V2-Pre-activation ResNet_pre-activation (v2) resnet
大语言模型技术及发展趋势总结_大语言模型发展措施
赞
踩
引言
大模型将成为通用人工智能的重要途径。在这个由0和1编织的数字时代,人工智能的腾飞已不是科技梦想,而是日益切实的现实。其中,大模型作为人工智能的核心力量,正以前所未有的方式重塑着我们的生活、学习和工作。无论是智能语音助手、自动驾驶汽车,还是医疗诊断系统,大模型都是幕后英雄,让这些看似不可思议的事情变为可能。
人工智能的发展历史
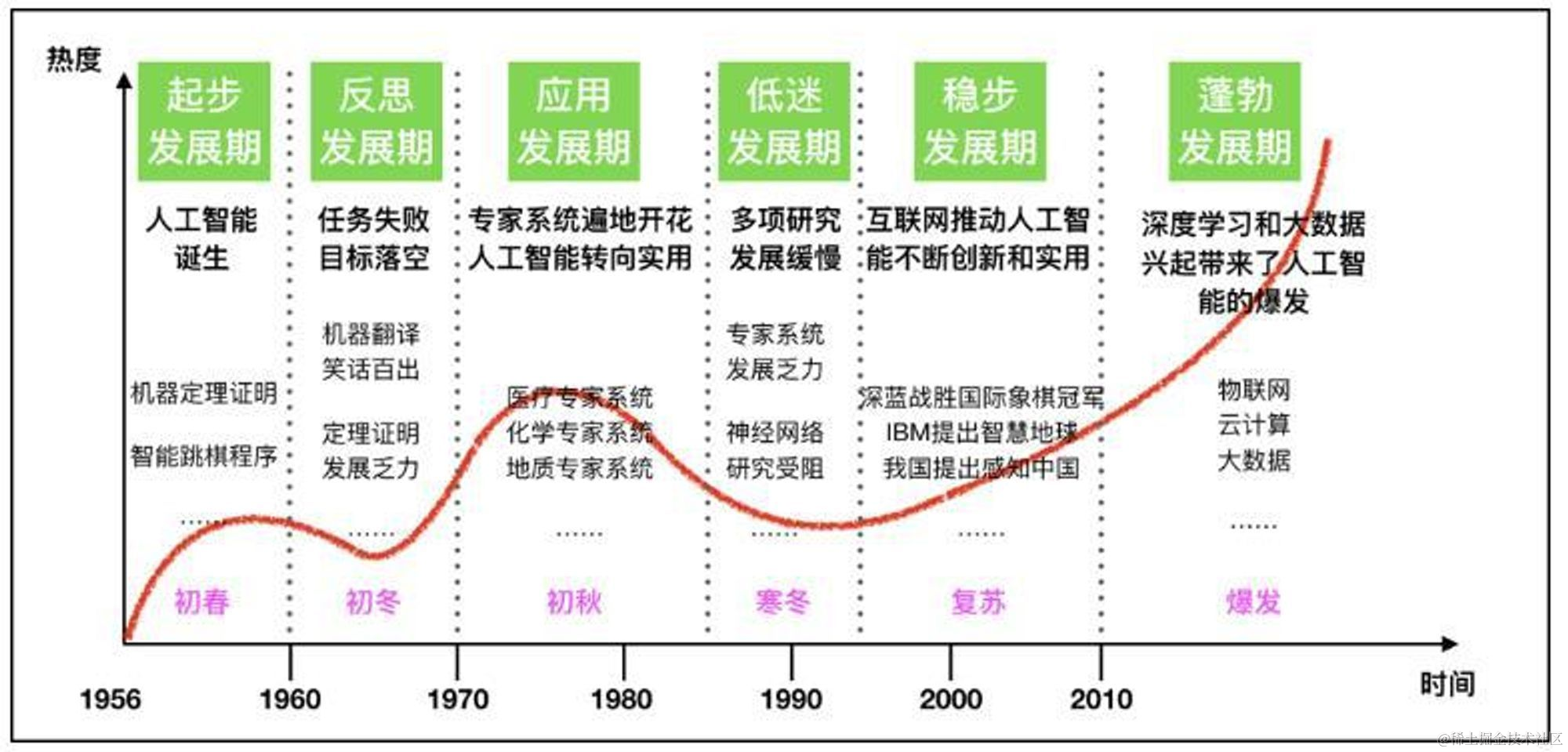
1.1950s-1970s:AI的诞生和早期发展
◦1950年,图灵测试的提出,为机器智能提供了一个评估标准。
◦1956年,达特茅斯会议标志着人工智能作为一门学科的正式诞生。
◦1960年代,早期的AI研究集中在逻辑推理和问题解决上。
2.1980s:专家系统的兴起
◦专家系统的成功应用,如MYCIN在医学诊断领域的应用。
◦机器学习算法开始发展,如决策树和早期的神经网络。
3.1990s:机器学习的进展
◦反向传播算法的提出,极大地推动了神经网络的研究。
◦1997年,IBM的深蓝击败国际象棋世界冠军,展示了AI在策略游戏中的能力。
4.2000s:大数据和计算能力的提升
◦互联网的普及带来了海量数据,为机器学习提供了丰富的训练素材。
◦计算能力的提升,尤其是GPU的广泛应用,加速了深度学习的发展。
5.2010s:深度学习革命
◦2012年,AlexNet在ImageNet竞赛中的胜利,标志着深度学习在图像识别领域的突破。
◦深度学习在语音识别、自然语言处理等领域取得显著进展。
6.2017年:Transformer和自注意力机制
◦2017年,Transformer模型的提出,引入了自注意力机制,极大地提升了模型的性能。
◦Transformer模型在自然语言处理任务中取得了革命性的成果,如BERT、GPT等模型。
7.2020s:大模型和多模态学习
◦大模型如chatGPT、Claude、Gemini、Llama、chatglm、Kimi等等都展示了强大的能力。
◦多模态学习的发展,如CLIP模型,能够理解和生成跨模态内容。
大模型的本质
大模型是能够从海量数据中学习、利用这些数据进行推理,并使用这些推理来回答用户的问题或是执行特定的任务。大模型(如ChatGPT、LLM等)在人工智能领域中被广泛应用,其核心理念和工作原理可以总结为以下几个方面:
1. LLM的组成 - 两个文件
大模型由以下两个关键部分构成:一个是 参数集,另一个是 执行代码。
•参数集: 这是模型的"大脑",包含了通过训练学习到的神经网络权重。
•执行代码: 这是模型的"引擎",包含用于运行参数集的软件代码,可以采用任何编程语言实现。
训练大模型需要对大量互联网数据进行有损压缩,是一项计算量更大的任务,通常需要一个巨大的GPU集群。
有趣的是,你只需要一台标准的计算机就可以运行像Llama-3这样的LLM并得出推论。在本地服务器上运行,因此,甚至不需要互联网连接。
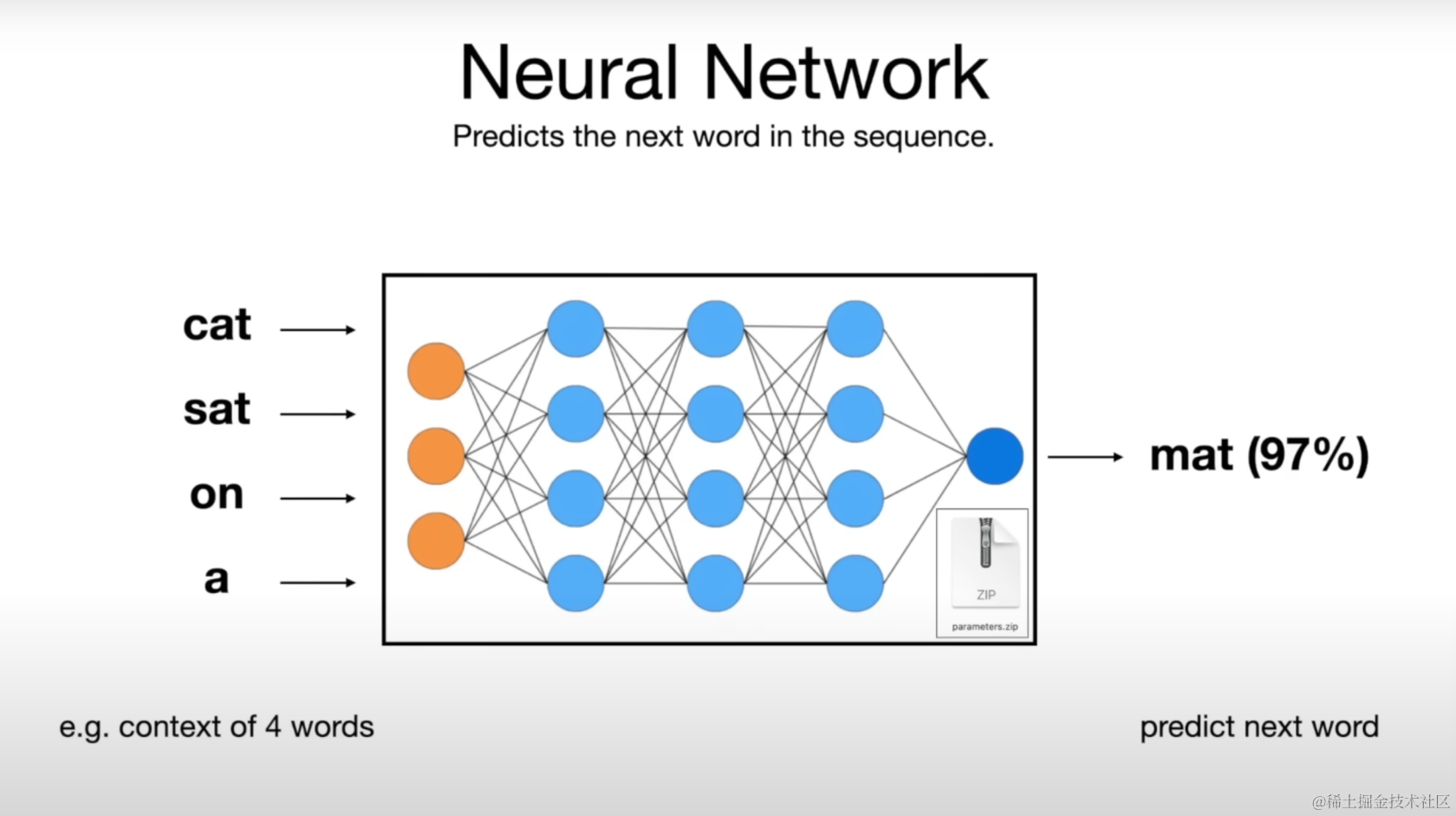
2. LLM的神经网络究竟在“想”什么 - 预测下一个单词
大模型的核心功能之一是预测文本序列中的下一个单词:
•输入一个“部分”句子,如“cat sat on a”。
•利用分布在网络中的参数及其连接关系预测下一个最可能的单词,并给出概率。如“mat(97%)”
•模拟了人类语言生成的方式,使得模型能够生成连贯和符合语境的句子,如生成完整的句子“cat sat on a mat”
模型根据它所获得的大量训练数据,生成“合理的延续”,即生成符合人类语言习惯的文本。
注:Transformer架构为这个神经网络提供了动力。
3. 神经网络“真正”的工作方式仍然是个谜
尽管我们可以将数十亿个参数输入到网络中,并通过反复微调训练这些参数,从而获得更好的预测效果,但我们并不完全理解这些参数在网络中是如何准确协作的,以及为什么它们能够生成如此准确的回答。科学上,这种现象被称为涌现。
我们知道,这些参数构建并维护了某种形式的知识数据库。然而,这种数据库有时表现得既奇怪又不完美。例如,一个大型语言模型(LLM)可能会正确回答“谁是小明的母亲?”这个问题,但如果你问它“X的儿子是谁?”,它可能会回答“我不知道”。这种现象通常被称为递归诅咒。
4. 训练大模型的步骤
预训练,训练需要对大量互联网数据进行有损压缩,输出参数文件
•收集大量互联网文本数据。
•准备强大的计算资源,如GPU集群。
•执行训练,生成基本模型。
微调阶段:
•准备高质量的训练数据,如问答对。
•在这些数据上调整模型参数,优化性能。
•进行评估和部署,确保模型达到预期效果。

微调阶段 - 比较
对于每个问题,人工标注者都会比较辅助模型的多个答案,并标注出最佳答案。这一步骤称为从人类反馈中强化学习(RLHF)。
5. 模型性能提升
1.模型越大,能力越强:
◦参数量: 模型的规模通常与其参数量成正比。参数是模型学习到的知识的载体,参数越多,模型能够捕捉的信息和模式就越丰富,从而能够处理更复杂的任务。
◦学习能力: 大模型通常拥有更强的学习能力。它们能够从大量数据中学习到更深层次的特征和规律,这使得它们在诸如自然语言处理、图像识别等任务上表现更佳。
◦泛化能力: 大模型往往有更好的泛化能力,即在面对未见过的数据时,也能做出准确的预测和判断。
2.工具越多,能力越强:
◦功能扩展: 为AI模型提供各种工具,可以使其功能得到显著扩展。例如,集成搜索引擎可以让模型访问互联网信息,增强其回答问题的能力。
◦多任务处理: 工具的集成使得AI模型能够同时处理多种任务。例如,集成计算器功能可以让模型执行数学计算,集成编程接口则可以让模型编写代码。
◦灵活性和适应性: 拥有多种工具的AI模型更加灵活和适应性强,能够根据任务需求快速调整其行为和策略。类似于人类通过使用工具解决各种任务。
面临的问题
幻觉
幻觉问题指的是大模型在生成文本时可能会产生与现实世界事实不一致的内容。这种现象可以分为几种类型:
1.事实性幻觉(Factuality Hallucination): 模型生成的内容与可验证的现实世界事实不一致。大模型可能生成听起来合理但实际上错误的信息,例如,生成一篇关于一个不存在的历史事件的文章,模型可能生成一篇关于“拿破仑在月球上宣布法国胜利”的文章,尽管这在现实中从未发生过。
2.忠实性幻觉(Faithfulness Hallucination): 模型生成的内容与用户的指令或上下文不一致。例如在一个关于健康饮食的讨论中,模型可能突然开始讨论健身运动,尽管这与用户的问题不直接相关。
产生幻觉的原因可能包括:
•使用的数据集存在错误信息或偏见。
•模型过度依赖训练数据中的模式,可能导致错误的关联。
•预训练阶段的架构缺陷,如基于前一个token预测下一个token的方式可能阻碍模型捕获复杂的上下文关系。
•对齐阶段的能力错位,即模型的内在能力与标注数据中描述的功能之间可能存在错位。
为了缓解幻觉问题,研究者们提出了多种方法,如改进预训练策略、数据清理以消除偏见、知识编辑、检索增强生成(RAG)等。
安全性问题
安全性问题涉及大模型可能遭受的恶意攻击和滥用,以及它们对用户隐私和数据安全的潜在威胁:
1.对抗样本攻击:攻击者可能构造特殊的输入样本,导致模型做出错误的预测。
2.后门攻击:在模型中植入后门,使得在特定触发条件下模型表现出异常行为。
3.成员推断攻击:攻击者尝试推断出训练集中是否包含特定的数据点。
4.模型窃取:通过查询模型来复制其功能,侵犯模型版权。
5.数据隐私泄露:模型可能泄露训练数据中的敏感信息。
为了提高大模型的安全性,业界和研究界正在探索多种安全防护策略,包括:
•加强数据的采集和清洗过程,确保数据质量和安全性。
•对模型进行加固,提高其抗攻击能力。
•采用加密存储和差分隐私技术来保护数据隐私。
•增强模型的可解释性,以便更好地理解和控制模型行为。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/861011
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

