
- 1大数据处理算法三:分而治之/hash映射 + hash统计 + 堆/快速/归并排序_大数组hash计算
- 2fpga定点数表示数据的理解_小于1的小数和大于1的小数的定点化
- 3SpringBoot Druid对配置文件中数据库密码加密_druid的配置文件
- 4fork一个github上的project后,同步更新
- 5大模型PEFT(一)之推理实践学习记录_peft精调后推理
- 6Prim算法:最小生成树的构建_prim算法怎么构建最小生成树
- 7KubeBlocks v0.9发布啦!API全面升级、支持Redis Cluster、MySQL主备...更多新功能等你发现!
- 8软件测试方法和技术---简答题题库(极简速记)
- 9mysql8强制用户开启ssl_mysql8.0 使用 x509设置加密连接
- 10如何只提交特定的代码块?使用git add -p
小白学大模型——Qwen2_qwen2 gqa
赞
踩
qwen2
思考:
1.教程提供了Qwen2大模型的模型构造以及源码,我们作为初学者,对于我们最应该关注的是什么?是模型的层数?还是模型的构造?还是模型的?
2.除了decoder layer 我们还应该有什么Layer decoder layer的构造是什么
3.需要什么样的前置知识,更好的理解教程。
answer:
1.我自己的话,会关注模型的结构,比如参数有哪些,层有哪些,gqa和mha这两个attention有什么区别。然后就是代码实现的技巧,比如在实现多头attention的时候,是把hidden state拆成多个头,而不是写一个循环遍历多次。(助教回答)
3.attention机制,decoder,encoder模块 , residual connection残差连接机制,norm归一化,transformer框架
这两个层——残差连接和RMSNorm——在变换器模型中发挥着关键的作用,下面详细解释这两个层的工作原理和它们的重要性:
小白学习大模型的规划
1.补充前置知识
2.跑起来大模型
3.个性化大模型 (微调训练特定领域 RAG应用等)
前置的知识
首先我们会学习Qwen2,Qwen2的整体模型架构如下,可以看到涉及到了很多pytorch 模块
模型架构图:
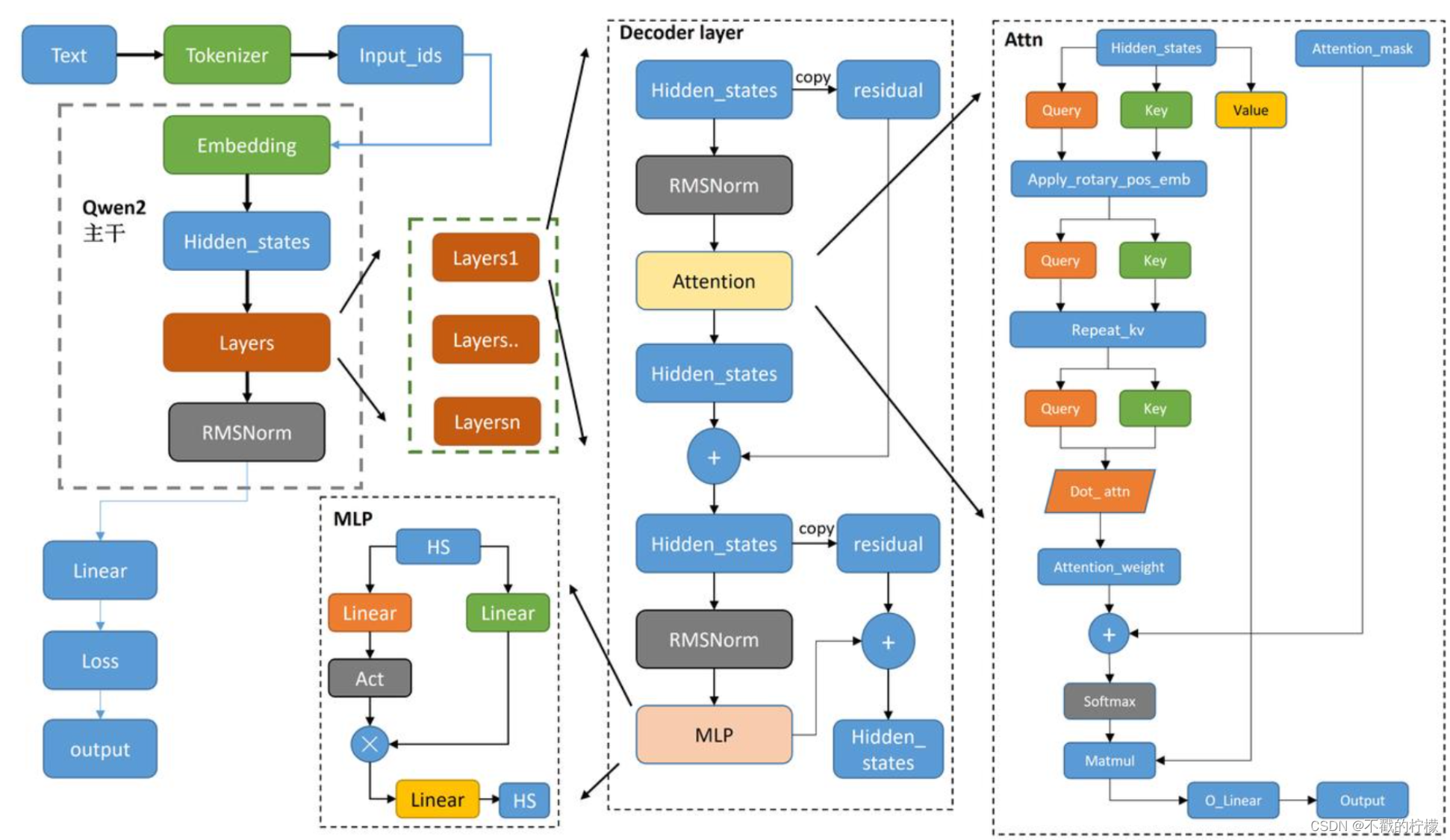
可以看到较为核心的Layer全部都为decoder 模块,decoder层有很多组件组成,有很多hidden state在进行传递。
残差连接(Residual Connection)
残差连接是深度学习中用来帮助解决梯度消失问题的一种技术。在深层网络中,信息必须通过多个层传递,每层都有可能导致信息丢失,尤其是在反向传播过程中,梯度可能会随着层数增加而逐渐减小到几乎为零。这会导致网络底层的权重更新非常缓慢,从而影响整个网络的学习效率。
残差连接通过将输入直接添加到网络更深层的输出上来工作。具体来说,在每个子层(如注意力层或MLP层)的输出中,都会加上该层输入的一个副本。这样,即使更深层的梯度很小,输入也可以不经修改地“跳过”一些层,直接传递到更深的层。这种直接路径有助于保持梯度的强度,从而有效缓解了梯度消失问题,并使得深层网络的训练变得更加稳定和快速。
RMSNorm(均方根层归一化)
RMSNorm是一种层归一化的变体,它主要用于改善神经网络训练的稳定性和效率。传统的层归一化是通过计算层输入的均值和方差,然后对输入进行规范化处理。而RMSNorm则不计算均值,只计算输入的均方根(RMS),并使用这个均方根来归一化输入数据。
使用均方根归一化的好处包括:
- 简化计算:不需要计算均值,减少了一部分计算量。
- 稳定性提升:通过均方根归一化,可以减少层输入在规模上的差异,从而使网络更加稳定,尤其是在训练初期,有助于快速收敛。
- 适应性强:适合于各种规模的数据和不同深度的网络结构。
这两种技术的结合使得变换器模型在处理深度学习任务时更加高效和稳定,尤其是在需要处理长序列和复杂模式的任务中,如自然语言处理和图像识别等领域。
在RMSNorm中,计算并应用均方根归一化的数学公式如下:
-
计算均方根 (RMS):
对于层的输入 ( x ),其中 ( x ) 是一个向量,其均方根定义为:
RMS ( x ) = 1 n ∑ i = 1 n x i 2 \text{RMS}(x) = \sqrt{\frac{1}{n} \sum_{i=1}^{n} x_i^2} RMS(x)=n1∑i=1nxi2 这里,( n ) 是向量 ( x ) 中元素的数量,( x_i ) 是向量 ( x ) 的第 ( i ) 个元素。
-
归一化处理:
输入 ( x ) 的每个元素 ( x_i ) 通过均方根RMS(x) 进行归一化,公式为:
x ^ i = x i RMS ( x ) \hat{x}_i = \frac{x_i}{\text{RMS}(x)} x^i=RMS(x)xi其中,( \hat{x}_i ) 是归一化后的值。
这种归一化方法特别适用于深度神经网络中的层,因为它能够在不考虑每个样本的平均值的情况下,减少不同输入之间的规模差异,从而提高训练过程中的稳定性。通过这种方法,网络可以更有效地处理各种规模的数据,尤其是在层较深的网络中表现出良好的收敛性。
Qwen2的介绍
Qwen2大模型牵扯很多模块,例如旋转位置编码,MQA(mulit query attention),GQA(group query attention)注意力机制的不同,层归一化的方式,MLP具体的原理等等。作为新手真的看的头都大了。这里就不摆弄自己的微薄知识,推荐两位大佬写的博客,他们对于大模型的结构有着更深入的理解,也将Qwen2大模型的实现细节与其他模型进行了比较。我觉得非常好。

