
- 1FunAudioLLM-SenseVoice+CosyVoice-论文阅读笔记
- 2【Spark】一个例子带你了解Spark运算流程_spark 计算流程
- 3【第3期】Springboot集成SpringSecurity+RSA+ECS免密登录_spring-security-rsa
- 4使用gTTS模块在Python中进行文本到语音转换
- 5算法回忆录:母函数解决整数拆分_整数拆分 母函数
- 6Mac OS下Docker的安装与配置_mac安装docker
- 7【转载】Git 常用命令大全_jgit merge-tree 命令
- 8Mac之终端下运行shell脚本_mac命令脚步
- 9贵州省计算机专业大学排名,贵州大学的计算机专业全国排名第几?
- 10Apache IoTDB进行IoT相关开发实践_aiotdb
基于YOLO_v8的车牌号码识别_opencv yolov8 车牌检测
赞
踩
1. 数据集
我使用的数据集是CCPD: Chinese City Parking Dataset
子数据集
ccpd_base:包含1000张不同角度、不同距离、不同照明、不同场景的图片。
ccpd_blur:包含1000张图片,其中图片模糊程度较大。
ccpd_challenge:包含1000张图片,这是LPDR算法最难的基准。
ccpd_db:包含1000张LP区域照明较暗或极亮的图片。
ccpd_fn:包含1000张从LP到拍摄地点的距离比较远或很近的图片。
ccpd_np:包含1000张图片,其中图片中的汽车没有LP。
ccpd_rotate:包含1000张图片,具有很大的水平倾斜度。
ccpd_tilt:包含1000张图片,水平倾斜度和垂直倾斜度都比较大。
ccpd_weather:包含1000张雨天拍摄的图片。
图片的标注性命名
示例图像的名称是“025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg”。每个名字可以被"-"符号分成7个字段。这些字段解释如下。
面积:车牌面积与整个图片面积的比例(025)
倾斜度:水平倾斜度(95)和垂直倾斜度(113)
边界框坐标:左上顶点的坐标(154&383)和右下顶点的坐标(386&473)
四个顶点的位置:LP的四个顶点在整个图像中的确切(x, y)坐标,这些坐标从右下角的顶点开始(386&473_177&454_154&383_363&402)
车牌号码:在CCPD中,每张图像只有一个LP。每个LP数字由一个汉字、一个字母和五个字母或数字组成(0_0_22_27_27_33_16),数字分别表示车牌号码在数组中的位置。
亮度:车牌区域的亮度(37)
模糊度:车牌区域的模糊度(15)
由于对模型还在了解阶段,所以我只取CCPD: Chinese City Parking Dataset的一部分作为数据集
代码来源
https://www.kaggle.com/code/harits/chinese-license-plate-recognition-yolov8-cnocr
系统
2. Praperation
导入模块
代码
- #导入了warnings模块,并使用filterwarnings()函数来忽略警告信息
- import warnings
- warnings.filterwarnings("ignore")
- #这些语句导入了一些操作系统、文件操作、时间处理、随机数生成、图像处理、数组操作、数据处理、文件匹配、进度条显示和正则表达式处理相关的库和模块
- import os
- import gc
- import shutil
- import time
- import random
- import cv2
- import numpy as np
- import pandas as pd
- import glob
- from tqdm import tqdm
- tqdm.pandas()
- import re
- #这些语句导入了一些数据可视化相关的库和模块,包括matplotlib、plotly等。
- import matplotlib
- import matplotlib.pyplot as plt
- import matplotlib.image as mpimg
- import plotly
- import plotly.graph_objects as go
- import plotly.express as px
- from plotly.subplots import make_subplots
- from IPython.display import Image, display
- #这行代码导入了PyTorch深度学习框架和Numba的CUDA模块,用于进行深度学习和GPU加速计算。
- import torch
- from numba import cuda

表示车牌号的数组和基础路径设置
- #定义车牌号码表示数组
- provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
- alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W',
- 'X', 'Y', 'Z', 'O']
- ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
- 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
- #训练集子集数组
- list_sub = ["ccpd_base", "ccpd_fn", "ccpd_db", "ccpd_rotate", "ccpd_weather", "ccpd_blur"]
- #训练集基础路径设置
- BASE_PATH = "CCPD2019"
这里的BASE_PATH要根据自己的需求修改
3. Data Exploration
数据探索:在数据分析过程中,对数据进行初步了解和分析的过程,通常包括数据清洗、数据可视化和统计分析等步骤。
这里我只是对数据进行简单的读取和了解。
3.1. Sample Images读取样本数据
代码
- # 创建子图
- fig, axs = plt.subplots(6, 6, figsize=(13, 18))
-
- # 遍历子数据集列表(序号和名称)
- for i, sub in enumerate(list_sub):
- axs[i, 0].text(0.5, 0.5, sub, ha='center', va='center', fontsize=12)
- axs[i, 0].axis('off')
- # 构建子数据集路径
- sub_path = os.path.join(BASE_PATH, sub)
- # 获取子数据集中的前五个文件名
- sub_files = os.listdir(sub_path)[:5]
-
- for j in range(5):
- file_name = os.path.join(sub_path, sub_files[j])
- image = cv2.imread(file_name)
- image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
- axs[i, j+1].imshow(image)
- axs[i, j+1].axis("off")
-
- # Title
- plt.suptitle("License Plate Based on Sub-Datasets", x=0.55, y=0.93)
-
- # Show
- plt.show()
运行结果

3.2. Image Description 描述ccpd_base的图片
代码
- #将基础路径(BASE_PATH)"CCPD2019"和"ccpd_base"连接起来,生成一个新的路径
- ccpd_base_path = os.path.join(BASE_PATH, "ccpd_base")
- #列出了"ccpd_base"路径下的所有文件
- ccpd_base_files = os.listdir(ccpd_base_path)
- #遍历"ccpd_base"路径下的前三个文件
- for file in ccpd_base_files[:3]:
- #生成每个文件的完整路径
- file_name = os.path.join(ccpd_base_path, file)
- #从文件名中提取出文件名的主体部分,去掉了文件扩展名
- file_splitting = file_name.split("\\")[-1][:-4]
- #打印文件名
- print("文件名:", file_splitting)
- #将文件名主体部分按照"-"分割,得到一系列的信息
- file_splitting = file_splitting.split("-")
- #区域比例
- area_ratio = file_splitting[0]
- print("区域比例:", area_ratio)
- #倾斜角度
- tilt_degrees = file_splitting[1]
- hor_tilt_degrees = tilt_degrees.split("_")[0]
- ver_tilt_degrees = tilt_degrees.split("_")[1]
- print("倾斜角度")
- #水平倾斜度
- print("- 水平倾斜度:", hor_tilt_degrees)
- #垂直倾斜度
- print("- 垂直倾斜度:", ver_tilt_degrees)
- #边界框
- bounding_box = file_splitting[2]
- left_up_bbox = bounding_box.split("_")[0]
- right_bot_bbox = bounding_box.split("_")[1]
- print("边界框(一个)")
- print("- 左上:", left_up_bbox)
- print("- 右下:", right_bot_bbox)
- #精确顶点
- vertices = file_splitting[3]
- right_bot_vtc = vertices.split("_")[0]
- left_bot_vtc = vertices.split("_")[1]
- left_up_vtc = vertices.split("_")[2]
- right_up_vtc = vertices.split("_")[3]
- print("精确顶点")
- print("- 右下:", right_bot_vtc)
- print("- 左下:", left_bot_vtc)
- print("- 左上:", left_up_vtc)
- print("- 右上:", right_up_vtc)
- #车牌号码
- lcn = file_splitting[4]
- chi_let = provinces[int(lcn.split("_")[0])]
- alp_let = alphabets[int(lcn.split("_")[1])]
- alp_num_let = lcn.split("_")[2:]
- alp_num_let = "".join([ads[int(char)] for char in alp_num_let])
- all_let = chi_let + alp_let + " " + alp_num_let
- print("车牌号码:", all_let)
- #亮度
- brightness = file_splitting[5]
- print("亮度:", brightness)
- #模糊度
- blurriness = file_splitting[6]
- print("模糊度:", blurriness)
- #使用OpenCV库读取图像文件
- img = cv2.imread(file_name)
- #将图像从BGR颜色空间转换为RGB颜色空间
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- #使用matplotlib库显示图像
- plt.imshow(img)
- plt.show()
运行结果
文件名: 00205459770115-90_85-352&516_448&547-444&547_368&549_364&517_440&515-0_0_22_10_26_29_24-128-7 区域比例: 00205459770115 倾斜角度 - 水平倾斜度: 90 - 垂直倾斜度: 85 边界框(一个) - 左上: 352&516 - 右下: 448&547 精确顶点 - 右下: 444&547 - 左下: 368&549 - 左上: 364&517 - 右上: 440&515 车牌号码: 皖A YL250 亮度: 128 模糊度: 7
文件名: 00221264367816-91_91-283&519_381&553-375&551_280&552_285&514_380&513-0_0_7_26_17_33_29-95-9 区域比例: 00221264367816 倾斜角度 - 水平倾斜度: 91 - 垂直倾斜度: 91 边界框(一个) - 左上: 283&519 - 右下: 381&553 精确顶点 - 右下: 375&551 - 左下: 280&552 - 左上: 285&514 - 右上: 380&513 车牌号码: 皖A H2T95 亮度: 95 模糊度: 9
文件名: 00223060344828-90_89-441&517_538&546-530&552_447&548_447&512_530&516-0_0_13_16_33_30_33-148-14 区域比例: 00223060344828 倾斜角度 - 水平倾斜度: 90 - 垂直倾斜度: 89 边界框(一个) - 左上: 441&517 - 右下: 538&546 精确顶点 - 右下: 530&552 - 左下: 447&548 - 左上: 447&512 - 右上: 530&516 车牌号码: 皖A PS969 亮度: 148 模糊度: 14
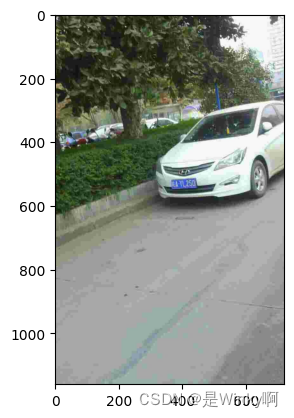


3.3. Sample Bounding Box and Exact Vertices采样边界框和精确的顶点
代码
- # 创建子图
- fig, axs = plt.subplots(3, 4, figsize=(13, 15))
- # 遍历文件列表,绘制车牌图像、边界框和精确顶点
- for i, file in enumerate(ccpd_base_files[2:8]):
- # 获取文件名
- file_name = os.path.join(ccpd_base_path, file)
- file_splitting = file_name.split("\\")[-1][:-4]
- file_splitting = file_splitting.split("-")
- # 提取车牌号码信息
- lcn = file_splitting[4]
- chi_let = provinces[int(lcn.split("_")[0])]
- alp_let = alphabets[int(lcn.split("_")[1])]
- alp_num_let = lcn.split("_")[2:]
- alp_num_let = "".join([ads[int(char)] for char in alp_num_let])
- all_let = chi_let + alp_let + alp_num_let
- # 提取边界框信息
- bounding_box = file_splitting[2]
- lu_bbox = bounding_box.split("_")[0]
- x1, y1 = list(map(int, lu_bbox.split("&")))
- rb_bbox = bounding_box.split("_")[1]
- x2, y2 = list(map(int, rb_bbox.split("&")))
- # 读取图像并绘制边界框
- bbox_img = cv2.imread(file_name)
- bbox_img = cv2.cvtColor(bbox_img, cv2.COLOR_BGR2RGB)
- cv2.rectangle(bbox_img, (x1, y1), (x2, y2), (30, 240, 100), 10)
- # 在子图上显示图像
- axs[i//2, (i*2)%4].imshow(bbox_img)
- axs[i//2, (i*2)%4].set_title("Bounding Box", fontsize=8)
- axs[i//2, (i*2)%4].axis("off")
- axs[i//2, (i*2)%4]
- # 提取精确顶点信息
- vertices = file_splitting[3]
- vertices_split = vertices.split("_")
- # 读取图像并绘制精确顶点
- exver_img = cv2.imread(file_name)
- exver_img = cv2.cvtColor(exver_img, cv2.COLOR_BGR2RGB)
- for j in range(4):
- x1, y1 = list(map(int, vertices_split[j].split("&")))
- x2, y2 = list(map(int, vertices_split[(j+1)%4].split("&")))
- cv2.line(exver_img, (x1, y1), (x2, y2), (30, 240, 100), thickness=10)
- # 在子图上显示图像
- axs[i//2, (i*2+1)%4].imshow(exver_img)
- axs[i//2, (i*2+1)%4].set_title("Exact Vertices", fontsize=8)
- axs[i//2, (i*2+1)%4].axis("off")
- axs[i//2, (i*2+1)%4]
- # 设置标题
- plt.suptitle("Sample Bounding Box and LPR Images", x=0.55, y=0.93)
- # 显示图像
- plt.show()
运行结果

4. Plate Detection - YOLOv8
运用YOLO_v8对车牌进行目标检测
4.1. Data Preparation
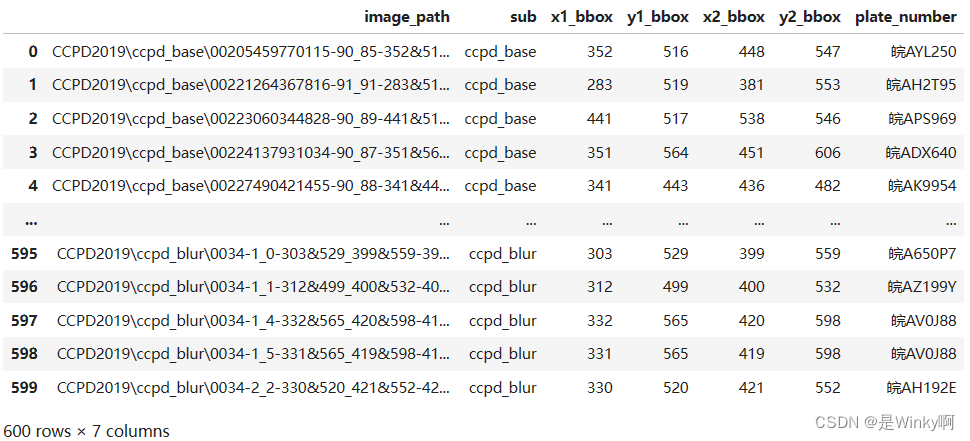
4.1.1. Create Metadata创建元数据
代码
- #Create Metadata
- #从车牌号码字符串中提取出省份简称、字母简称和数字字母组合
- def extract_plate_number(plate_number):
- # 提取省份简称
- chi_let = provinces[int(plate_number.split("_")[0])]
- # 提取字母简称
- alp_let = alphabets[int(plate_number.split("_")[1])]
- # 提取数字字母组合
- alp_num_let = plate_number.split("_")[2:]
- # 将数字字母组合转换为字符串
- alp_num_let = "".join([ads[int(char)] for char in alp_num_let])
- # 拼接省份简称、字母简称和数字字母组合
- all_let = chi_let + alp_let + alp_num_let
- return all_let
-
- #创建一个空的DataFrame
- df_metadata = pd.DataFrame()
- #遍历每个子数据集,获取子文件夹路径
- for sub in list_sub:
- sub_path = os.path.join(BASE_PATH, sub, "*")
- sub_files = glob.glob(sub_path)
- # 只取前100个文件
- sub_files = sub_files[:100]
- #将子文件夹路径添加到df_metadata中
- df_metadata = df_metadata._append(sub_files)
- # 重命名列名并重置索引
- df_metadata = df_metadata.rename(columns={0: "image_path"}).reset_index(drop=True)
- # 提取子文件夹名称、详细信息、边界框信息、车牌号码等信息,并添加到df_metadata中
- df_metadata["sub"] = df_metadata["image_path"].apply(lambda x: x.split("\\")[1])
- df_metadata["detail"] = df_metadata["image_path"].apply(lambda x: x.split("\\")[2])
- df_metadata["bbox"] = df_metadata["detail"].apply(lambda x: x.split("-")[2])
- df_metadata["x1_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[0].split("&")[0]))
- df_metadata["y1_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[0].split("&")[1]))
- df_metadata["x2_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[1].split("&")[0]))
- df_metadata["y2_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[1].split("&")[1]))
- df_metadata["plate_number"] = df_metadata["detail"].apply(lambda x: x.split("-")[4])
- df_metadata["plate_number"] = df_metadata["plate_number"].apply(lambda x: extract_plate_number(x))
- # 删除不需要的列
- df_metadata = df_metadata.drop(["detail", "bbox"], axis=1)
-
- df_metadata
这两行代码中的索引号要根据自己路径的实际情况修改
- df_metadata["sub"] = df_metadata["image_path"].apply(lambda x: x.split("\\")[1])
- df_metadata["detail"] = df_metadata["image_path"].apply(lambda x: x.split("\\")[2])
运行结果
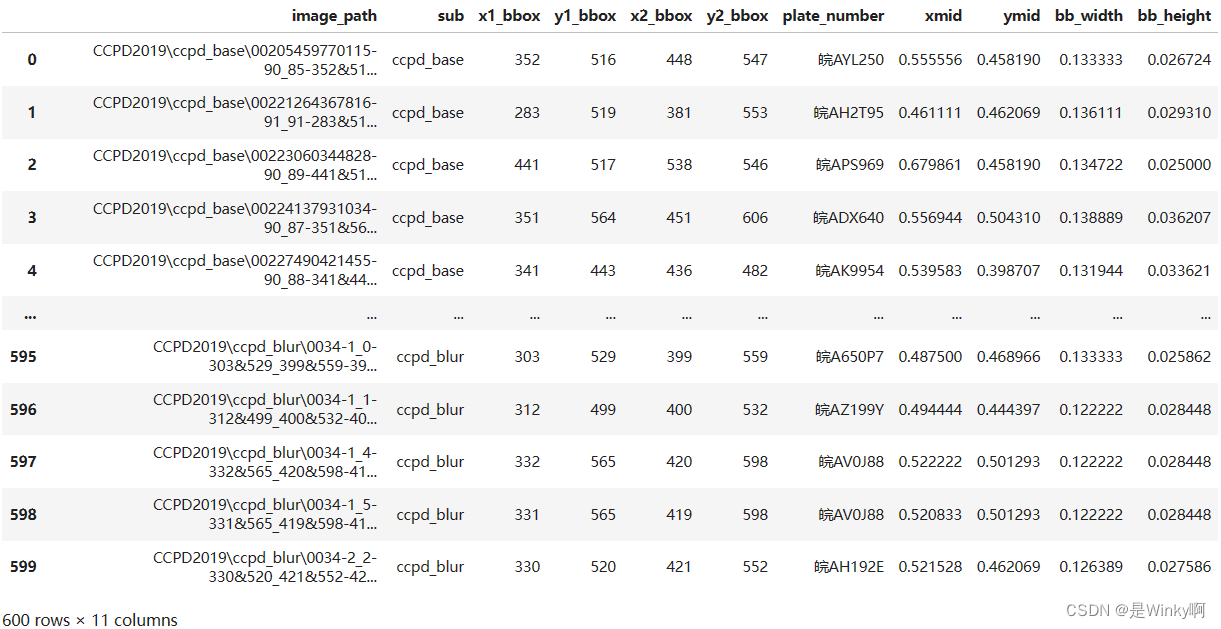
4.1.2. Create YOLOv8 Bounding Box Format
代码
- df_metadata['xmid'] = (df_metadata['x1_bbox'] + df_metadata['x2_bbox']) / (2*720)
- df_metadata['ymid'] = (df_metadata['y1_bbox'] + df_metadata['y2_bbox']) / (2*1160)
-
- df_metadata['bb_width'] = (df_metadata['x2_bbox'] - df_metadata['x1_bbox']) / 720
- df_metadata['bb_height'] = (df_metadata['y2_bbox'] - df_metadata['y1_bbox']) / 1160
-
- df_metadata
运行结果
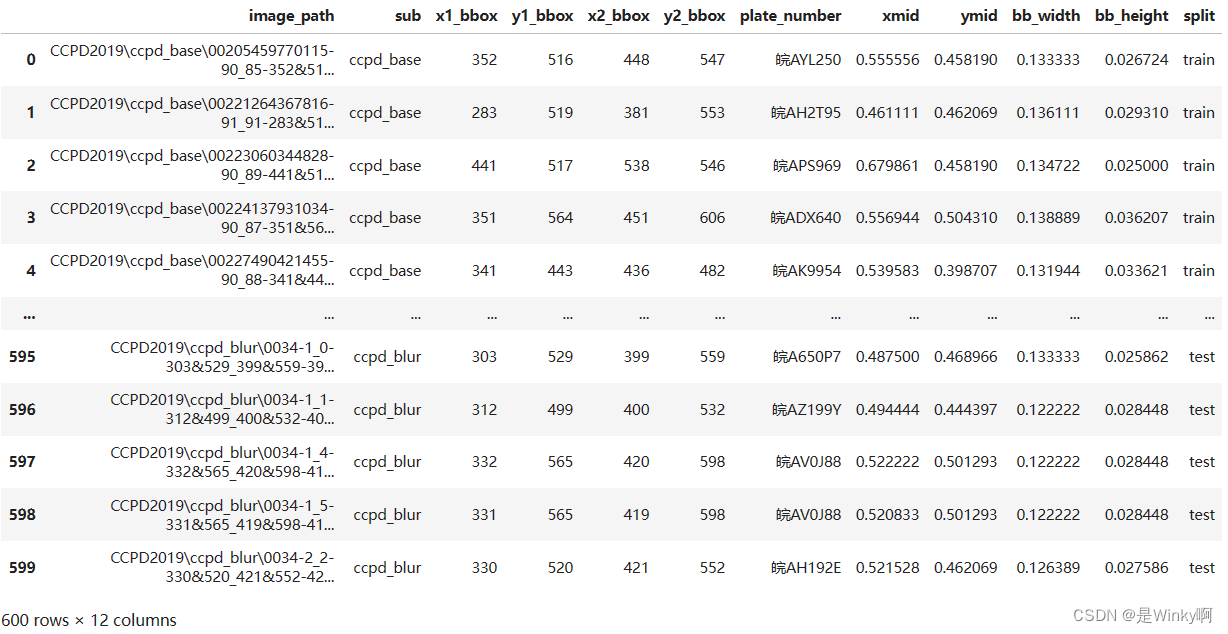
4.1.3. Data Splitting
代码
- # Train : 5000 (ccpd_base), Val and Test : 50 for each sub (except ccpd_base)
- list_split = ["train"] * 270058
- for i in range(5):
- list_split.extend(["val"]*170)
- list_split.extend(["test"]*170)
- df_metadata["split"] = list_split
- df_metadata
运行结果
4.2. YOLOv8 Preparation
代码
这段代码是用于克隆Ultralytics项目的GitHub仓库并安装ultralytics库的命令。
- ###这个命令用于克隆Ultralytics项目的GitHub仓库到本地
- ###https://github.com/ultralytics/ultralytics 是Ultralytics项目的GitHub仓库地址
- !git clone https://github.com/ultralytics/ultralytics
- ###这个命令用于安装名为ultralytics的Python库
- ###在克隆了Ultralytics项目的GitHub仓库后,可以通过这个命令安装项目中的Python库
- !pip install ultralytics
运行结果
fatal: destination path 'ultralytics' already exists and is not an empty directory.Requirement already satisfied: ultralytics in d:\env\anaconda\lib\site-packages (8.2.10) Requirement already satisfied: matplotlib>=3.3.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (3.8.0) Requirement already satisfied: opencv-python>=4.6.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (4.9.0.80) Requirement already satisfied: pillow>=7.1.2 in d:\env\anaconda\lib\site-packages (from ultralytics) (10.2.0) Requirement already satisfied: pyyaml>=5.3.1 in d:\env\anaconda\lib\site-packages (from ultralytics) (6.0.1) Requirement already satisfied: requests>=2.23.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (2.31.0) Requirement already satisfied: scipy>=1.4.1 in d:\env\anaconda\lib\site-packages (from ultralytics) (1.11.4) Requirement already satisfied: torch>=1.8.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (2.3.0) Requirement already satisfied: torchvision>=0.9.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (0.18.0) Requirement already satisfied: tqdm>=4.64.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (4.65.0) Requirement already satisfied: psutil in d:\env\anaconda\lib\site-packages (from ultralytics) (5.9.0) Requirement already satisfied: py-cpuinfo in d:\env\anaconda\lib\site-packages (from ultralytics) (9.0.0) Requirement already satisfied: thop>=0.1.1 in d:\env\anaconda\lib\site-packages (from ultralytics) (0.1.1.post2209072238) Requirement already satisfied: pandas>=1.1.4 in d:\env\anaconda\lib\site-packages (from ultralytics) (2.1.4) Requirement already satisfied: seaborn>=0.11.0 in d:\env\anaconda\lib\site-packages (from ultralytics) (0.12.2) Requirement already satisfied: contourpy>=1.0.1 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (1.2.0) Requirement already satisfied: cycler>=0.10 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (0.11.0) Requirement already satisfied: fonttools>=4.22.0 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (4.25.0) Requirement already satisfied: kiwisolver>=1.0.1 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (1.4.4) Requirement already satisfied: numpy<2,>=1.21 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (1.26.4) Requirement already satisfied: packaging>=20.0 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (23.1) Requirement already satisfied: pyparsing>=2.3.1 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (3.0.9) Requirement already satisfied: python-dateutil>=2.7 in d:\env\anaconda\lib\site-packages (from matplotlib>=3.3.0->ultralytics) (2.8.2) Requirement already satisfied: pytz>=2020.1 in d:\env\anaconda\lib\site-packages (from pandas>=1.1.4->ultralytics) (2023.3.post1) Requirement already satisfied: tzdata>=2022.1 in d:\env\anaconda\lib\site-packages (from pandas>=1.1.4->ultralytics) (2023.3) Requirement already satisfied: charset-normalizer<4,>=2 in d:\env\anaconda\lib\site-packages (from requests>=2.23.0->ultralytics) (2.0.4) Requirement already satisfied: idna<4,>=2.5 in d:\env\anaconda\lib\site-packages (from requests>=2.23.0->ultralytics) (3.4) Requirement already satisfied: urllib3<3,>=1.21.1 in d:\env\anaconda\lib\site-packages (from requests>=2.23.0->ultralytics) (2.0.7) Requirement already satisfied: certifi>=2017.4.17 in d:\env\anaconda\lib\site-packages (from requests>=2.23.0->ultralytics) (2024.2.2) Requirement already satisfied: filelock in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (3.13.1) Requirement already satisfied: typing-extensions>=4.8.0 in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (4.9.0) Requirement already satisfied: sympy in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (1.12) Requirement already satisfied: networkx in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (3.1) Requirement already satisfied: jinja2 in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (3.1.3) Requirement already satisfied: fsspec in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (2023.10.0) Requirement already satisfied: mkl<=2021.4.0,>=2021.1.1 in d:\env\anaconda\lib\site-packages (from torch>=1.8.0->ultralytics) (2021.4.0) Requirement already satisfied: colorama in d:\env\anaconda\lib\site-packages (from tqdm>=4.64.0->ultralytics) (0.4.6) Requirement already satisfied: intel-openmp==2021.* in d:\env\anaconda\lib\site-packages (from mkl<=2021.4.0,>=2021.1.1->torch>=1.8.0->ultralytics) (2021.4.0) Requirement already satisfied: tbb==2021.* in d:\env\anaconda\lib\site-packages (from mkl<=2021.4.0,>=2021.1.1->torch>=1.8.0->ultralytics) (2021.12.0) Requirement already satisfied: six>=1.5 in d:\env\anaconda\lib\site-packages (from python-dateutil>=2.7->matplotlib>=3.3.0->ultralytics) (1.16.0) Requirement already satisfied: MarkupSafe>=2.0 in d:\env\anaconda\lib\site-packages (from jinja2->torch>=1.8.0->ultralytics) (2.1.3) Requirement already satisfied: mpmath>=0.19 in d:\env\anaconda\lib\site-packages (from sympy->torch>=1.8.0->ultralytics) (1.3.0)
代码
这段代码是用于在YOLOv8中创建数据集文件夹的。它会创建四个文件夹。
- # Create Dataset Folder in YOLOv8
- ###主数据集文件夹,用于存放所有与数据集相关的文件和子文件夹
- !mkdir "ultralytics\\datasets"
- ###训练集文件夹,用于存放训练过程中使用的图片和标签文件
- !mkdir "ultralytics\\datasets\\train"
- ###验证集文件夹,用于存放验证过程中使用的图片和标签文件
- !mkdir "ultralytics\\datasets\\val"
- ###测试集文件夹,用于存放测试过程中使用的图片和标签文件
- !mkdir "ultralytics\\datasets\\test"
运行结果
因为之前已经运行过一次这个文件,所以显示已经存在。
子目录或文件 ultralytics\\datasets 已经存在。 子目录或文件 ultralytics\\datasets\\train 已经存在。 子目录或文件 ultralytics\\datasets\\val 已经存在。 子目录或文件 ultralytics\\datasets\\test 已经存在。
代码
这段代码的主要功能是将图像文件和对应的文本信息复制到YOLOv8数据集文件夹中。
首先根据传入的参数(train、val或test),筛选出对应的数据行,并重置索引。
然后遍历每一行数据,将图像文件复制到目标文件夹中,并生成包含标签信息的文本文件内容,将文本文件内容写入目标文本文件中。
最后分别处理训练集、验证集和测试集数据。
- # 定义一个函数,用于将图像和对应的文本信息复制到YOLOv8数据集文件夹中
- def image_and_text_yolo(split):
- # 根据传入的参数(train、val或test),筛选出对应的数据行,并重置索引
- df = df_metadata[df_metadata["split"]==split].reset_index(drop=True)
- # 拼接目标文件夹路径
- folder_path = os.path.join("ultralytics\\datasets", split)
-
- # 获取需要处理的数据值
- values = df[['image_path','xmid','ymid','bb_width','bb_height']].values
- # 遍历每一行数据
- for file_name, x, y, w, h in values:
- # 获取图像文件名
- image_name = os.path.split(file_name)[-1]
- # 获取文本文件名(去掉扩展名)
- txt_name = os.path.splitext(image_name)[0]
-
- # 拼接目标图像文件路径
- dst_image_path = os.path.join(folder_path, image_name)
- # 拼接目标文本文件路径
- dst_label_file = os.path.join(folder_path, txt_name+'.txt')
-
- # 将图像文件复制到目标文件夹中
- shutil.copy(file_name, dst_image_path)
-
- # 生成包含标签信息的文本文件内容
- label_txt = f'0 {x} {y} {w} {h}'
- # 将文本文件内容写入目标文本文件中
- with open(dst_label_file, mode='w') as f:
- f.write(label_txt)
- f.close()
-
- # 调用函数,处理训练集数据
- image_and_text_yolo("train")
- print("Train Dataset Created")
- # 调用函数,处理验证集数据
- image_and_text_yolo("val")
- print("Val Dataset Created")
- # 调用函数,处理测试集数据
- image_and_text_yolo("test")
- print("Test Dataset Created")
运行结果
Train Dataset Created Val Dataset Created Test Dataset Created
代码
我最开始的代码是这么写的
- ###这是一个Jupyter Notebook的魔法命令,用于将接下来的代码写入到指定的文件中
- ###这里是将代码写入到ultralytics\custom_dataset.yaml文件中
- %%writefile ultralytics\\custom_dataset.yaml
- ### 创建自定义数据集配置的
- ###训练集的路径
- train: ultralytics\\datasets\\train
- ###验证集的路径
- val: ultralytics\\datasets\\val
- ###测试集的路径
- test: ultralytics\\datasets\\test
- ###数据集中的类别数量:1,表示只有一个类别
- nc: 1
- ###这一行定义了数据集中的类别名称:license_plate,表示这个类别的名称是车牌。
- names: [
- 'license_plate'
- ]
就报了这样的错误,但是在前面的代码中我都是用"\\"表示"\",我猜测可能是注释干扰了"\\"

于是修改代码
- %%writefile ultralytics\\custom_dataset.yaml
- # Create Custom Dataset Configuration
- train: ultralytics\\datasets\\train
- val: ultralytics\\datasets\\val
- test: ultralytics\\datasets\\test
-
- nc: 1
-
- names: [
- 'license_plate'
- ]
运行结果
因为之前已经运行过一次这个文件,所以显示重写'ultralytics\\custom_dataset.yaml'文件。
Overwriting ultralytics\\custom_dataset.yaml
4.3. YOLOv8 Training
为YOLO_v8的使用做准备,安装相应的库、释放缓存
代码
- ### 安装GPUtil库,用于获取GPU使用情况
- !pip install GPUtil
- ### 导入GPUtil库中的showUtilization函数,并将其重命名为gpu_usage
- from GPUtil import showUtilization as gpu_usage
- ### 定义一个名为free_gpu_cache的函数,用于释放GPU缓存
- def free_gpu_cache():
- ### 打印初始GPU使用情况
- print("Initial GPU Usage")
- ### 调用gpu_usage函数,显示GPU使用情况
- gpu_usage()
- ### 清空PyTorch的CUDA缓存
- torch.cuda.empty_cache()
- ### 选择第一个GPU设备
- cuda.select_device(0)
- ### 关闭当前选中的GPU设备
- cuda.close()
- ### 再次选择第一个GPU设备
- cuda.select_device(0)
- #### 打印清空缓存后的GPU使用情况
- print("GPU Usage after emptying the cache")
- ### 调用gpu_usage函数,显示GPU使用情况
- gpu_usage()
- ### 调用free_gpu_cache函数,执行释放GPU缓存的操作
- free_gpu_cache()
运行结果
该代码在Python环境中使用GPUtil库(版本号为1.4.0)来获取GPU的使用情况。
初始的GPU使用情况:ID为0的GPU的GPU占用率为0%,内存占用也为0%。
清空了PyTorch的CUDA缓存后GPU的使用情况:ID为0的GPU的GPU占用率变为了2%,内存占用也变为了2%。
这段代码的目的是通过清空CUDA缓存来释放GPU资源,并观察GPU使用情况的变化。
(释放缓存之后占用率还变高了?)
Requirement already satisfied: GPUtil in d:\env\anaconda\lib\site-packages (1.4.0) Initial GPU Usage | ID | GPU | MEM | ------------------ | 0 | 0% | 0% | GPU Usage after emptying the cache | ID | GPU | MEM | ------------------ | 0 | 2% | 2% |
代码
!yolo train model=yolov8s.pt data="D:\\target_detection\\yolov8-master\\ultralytics\\custom_dataset.yaml" epochs=25 verbose=True batch=32运行结果

训练代码我组用了远程GPU4090,且训练集只有600个样本。但每次训练代码时,都一直显示*号, 训练不出权重文件,但是又确实是在训练,由于找不到原因,我决定换代码来解决这个任务。
数据集配置文件
- # Create Custom Dataset Configuration
- train: D:\\target_detection\\yolov8-master\\ultralytics\\datasets\\train
- val: D:\\target_detection\\yolov8-master\\ultralytics\\datasets\\val
- test: D:\\target_detection\\yolov8-master\\ultralytics\\datasets\\test
-
- nc: 1
-
- names: [
- 'license_plate'
- ]
以下是runs文件夹里保存的训练结果
train13
weights文件夹为空
生成的.yaml文件
- task: detect ##任务类型为目标检测
- mode: train ##模式为训练
- model: yolov8s.pt ##使用的预训练权重文件为yolov8s.pt
- data: ultralytics\\custom_dataset.yaml ##数据集配置文件路径为ultralytics\custom_dataset.yaml
- epochs: 25 ##训练的总轮数为25
- time: null ##未设置时间限制
- patience: 100 ##当验证损失在连续100个epoch没有改善时,停止训练
- batch: 32 ##每个批次的样本数量为32
- imgsz: 640 ##输入图像的大小为640x640
- save: true ##保存模型权重
- save_period: -1
- cache: false
- device: null
- workers: 8
- project: null
- name: train13
- exist_ok: false
- pretrained: true
- optimizer: auto
- verbose: true
- seed: 0
- deterministic: true
- single_cls: false
- rect: false
- cos_lr: false
- close_mosaic: 10
- resume: false
- amp: true
- fraction: 1.0
- profile: false
- freeze: null
- multi_scale: false
- overlap_mask: true
- mask_ratio: 4
- dropout: 0.0
- val: true
- split: val
- save_json: false
- save_hybrid: false
- conf: null
- iou: 0.7
- max_det: 300
- half: false
- dnn: false
- plots: true
- source: null
- vid_stride: 1
- stream_buffer: false
- visualize: false
- augment: false
- agnostic_nms: false
- classes: null
- retina_masks: false
- embed: null
- show: false
- save_frames: false
- save_txt: false
- save_conf: false
- save_crop: false
- show_labels: true
- show_conf: true
- show_boxes: true
- line_width: null
- format: torchscript
- keras: false
- optimize: false
- int8: false
- dynamic: false
- simplify: false
- opset: null
- workspace: 4
- nms: false
- lr0: 0.01
- lrf: 0.01
- momentum: 0.937
- weight_decay: 0.0005
- warmup_epochs: 3.0
- warmup_momentum: 0.8
- warmup_bias_lr: 0.1
- box: 7.5
- cls: 0.5
- dfl: 1.5
- pose: 12.0
- kobj: 1.0
- label_smoothing: 0.0
- nbs: 64
- hsv_h: 0.015
- hsv_s: 0.7
- hsv_v: 0.4
- degrees: 0.0
- translate: 0.1
- scale: 0.5
- shear: 0.0
- perspective: 0.0
- flipud: 0.0
- fliplr: 0.5
- bgr: 0.0
- mosaic: 1.0
- mixup: 0.0
- copy_paste: 0.0
- auto_augment: randaugment
- erasing: 0.4
- crop_fraction: 1.0
- cfg: null
- tracker: botsort.yaml
- save_dir: runs\detect\train13
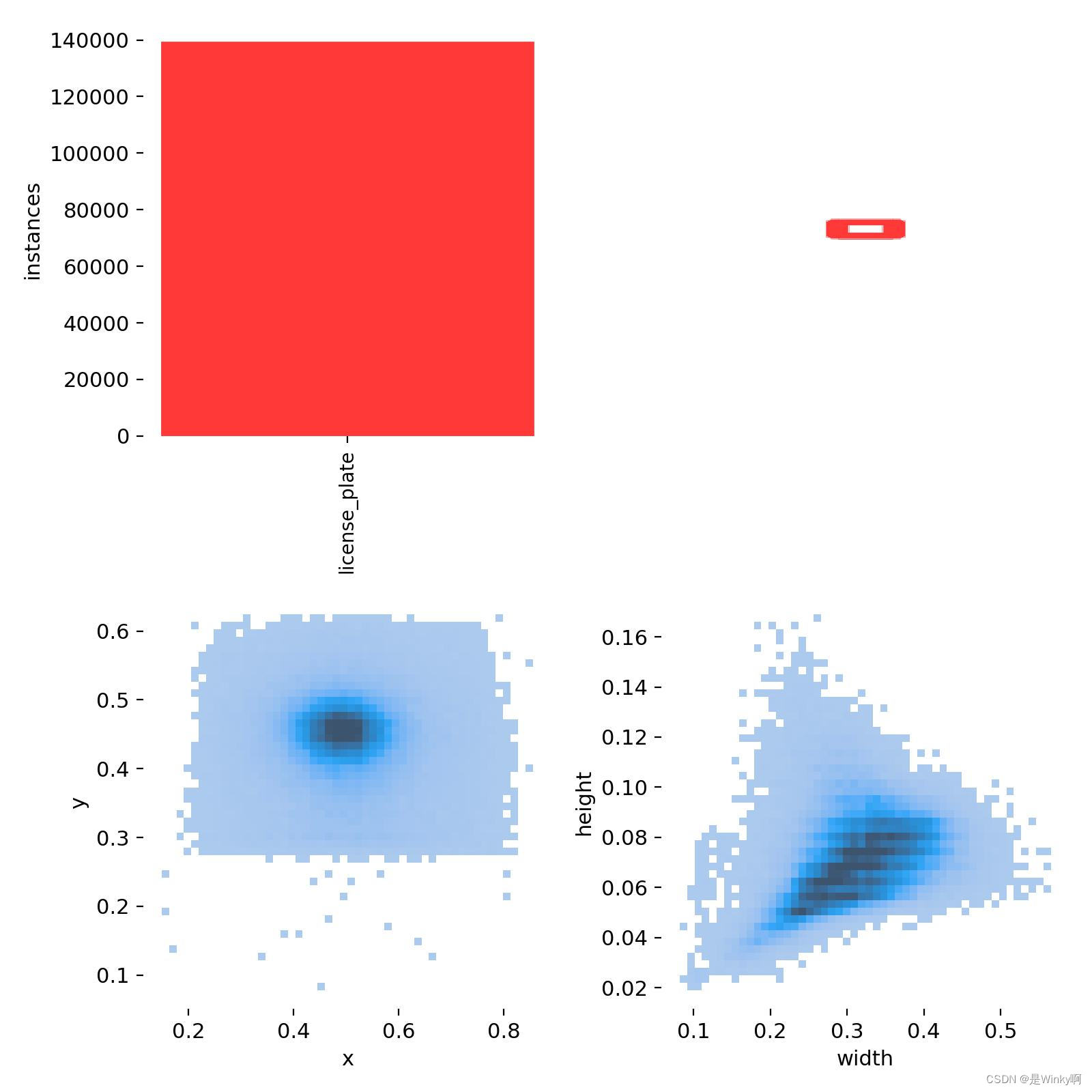




由输出可知,模型没有成功训练,但jupyter notebook并没有提供相应错误信息,于是这个项目将交由另一个代码解决。
5. Review
由于大项目需要很多精力去研读理解,我之前写代码比较偏向jupyter notebook。
经过这次实践,我发现jupyter notebook对于解决工程问题不太适用,jupyter notebook的长项在于记录,而在跑比较复杂的项目时会出现不太稳定,信息显示不详细等问题。
在之后的项目中,我会合理运用jupyter notebook。

