- 1amcharts图表使用总结
- 2vue使用print.js打印插件_print.js中文官网
- 3超市管理系统代码分享 - C语言控制台程序_利用c语言开发一套超市管理系统。系统要求以菜单方式工作,因而根据题目要求,提供
- 403-03 创建和编辑AutoCAD实体(三) 使用选择集(2)_cad中 selectionfilter如何构建多个条件,这些条件是或的关系
- 5一个流程模版都包含那些元素?_流程建模库元素
- 6C++学习 | VS2015下配置FFTW3库的方法,亲测实用_fftw3.h
- 7修改el-table表格单元格边框颜色_el-table border颜色
- 8docker (六)-进阶篇-数据持久化最佳实践MySQL部署
- 9仿知乎可拖动悬停按钮_android开发 可拖拽悬浮按钮
- 10Windows Server 2019 会话远程桌面-快速部署(RemoteApp)_remoteapp服务器搭建
Pytorch之经典神经网络RNN(二) —— GRU()_pytorch gru
赞
踩
2014年提出的
GRU,Gate Recurrent Unit,门控循环单元,是循环神经网络RNN的一种。
GRU也是为了解决长期记忆和反向传播中的梯度等问题。
我们知道Vanilla RNN 当时间步数较⼤或者时间步较小时,RNN的梯度较容易出现衰减或爆炸。虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题。通常由于这个原因,循环神经⽹络在实际中较难捕捉时间序列中时间步距离较⼤的依赖关系。
⻔控循环神经⽹络(gated recurrent neural network)的提出,正是为了更好地捕捉时间序列中时间步距离较⼤的依赖关系。它通过可以学习的⻔来控制信息的流动。其中,⻔控循环单元(gated recurrent unit, GRU)是⼀种常⽤的⻔控循环神经⽹络。另⼀种常⽤的⻔控循环神经⽹络就是LSTM
·GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢?
我们在我们的实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
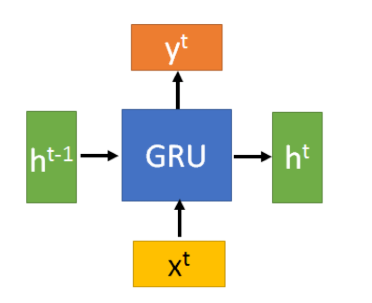
GRU的结构
GRU引入了重置⻔(reset gate)和更新⻔(update gate)的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。
重置门(相关门)和更新门
⻔控循环单元中的重置⻔和更新⻔的输⼊均为当前时间步输⼊ Xt 与上⼀时间步隐藏状态 Ht-1,输出由激活函数为sigmoid函数的全连接层计算得到。
sigmoid函数可以将元素的值变换到0和1之间。因此,重置⻔Rt和更新⻔Zt中每个元素的值域都是[0, 1]
候选隐藏状态
接下来,门控循环单元将计算候选隐藏状态来辅助稍后的隐藏状态计算。如图所示,我们将当前时间步重置⻔的输出与上⼀时间步隐藏状态做按元素乘法(符号为⊙)。如果重置⻔中元素值接近0,那么意味着重置对应隐藏状态元素为0,即丢弃上⼀时间步的隐藏状态。如果元素值接近1,那么表⽰保留上⼀时间步的隐藏状态。然后,将按元素乘法的结果与当前时间步的输⼊连结,再通过含激活函数tanh的全连接层计算出候选隐藏状态,其所有元素的值域为[-1,1]
隐藏状态 Ht
值得注意的是,更新⻔可以控制隐藏状态应该如何被包含当前时间步信息的候选隐藏状态所更新,如上图所⽰。假设更新⻔在时间步t′到t(t′ < t)之间⼀直近似1。那么,在时间步t′到t之间的输⼊信息⼏乎没有流⼊时间步t的隐藏状态Ht。实际上,这可以看作是较早时刻的隐藏状态Ht′-1⼀直通过时间保存并传递⾄当前时间步t。这个设计可以应对循环神经⽹络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较⼤的依赖关系。
GRU的设计的作用
- 重置⻔有助于捕捉时间序列⾥短期的依赖关系;
- 更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。
从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。
如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。
GRU与LSTM
使用门控机制学习长期依赖关系的基本思想和 LSTM 一致
GRU与LSTM最大的不同在于GRU将遗忘门和输入门合成了一个“更新门”。同时网络不再额外给出记忆状态Ct,而是将输出结果ht作为记忆状态不断向后传递
其他关键区别:
- GRU 有两个门(重置门与更新门),而 LSTM 有三个门(输入门、遗忘门和输出门)。
- GRU 并不会控制并保留内部记忆(c_t),且没有 LSTM 中的输出门。
- LSTM 中的输入与遗忘门对应于 GRU 的更新门,重置门直接作用于前面的隐藏状态。
- 在计算输出时并不应用二阶非线性。
GRU结构的其他画法
单个门控单元的具体结构
GRU表达式的其他写法