
- 1力扣竞赛周赛320场_力扣周赛 题目
- 2uni-app 小程序平台 echarts 性能优化_uniapp引入echarts速度慢怎么解决
- 3基于SpringBoot左岸小区车位管理系统的设计与实现_小区地下车位管理系统的数据库设计
- 4HTML 网页表白,520
- 5人工智能狂潮下的赢家与输家:你在哪一边?
- 6CentOS7 linux 配置与管理FTP服务器 案例2——配置本地用户访问的FTP服务器_centos中ftp本地用户登录真实案例
- 7switch 与 if else 的区别_switch if else
- 8类的封装,继承与多态(Java8.6实战练习)_对于构造方法参数个数不足以初始化4个数 据成员时,在构造方法中采用自己指定默认
- 9vue3实现video控件的h5端进度条拖拽与跳转_vue-video-player 拖动进度条
- 10解释词超文本标记语言html,超文本标记语言html的解释
图像去雾去雨去模糊去噪_雨纹去除 图像处理
赞
踩
一坑未平,一坑又起。前阵子研究的Ocr检测+识别算法算是告一段落。整体来说目前相关算法效果算是不错的了,通用于身份证通行证等各类证件识别,车票识别,彩票,发票等各类票据识别,车牌识别,温度仪表盘等。
接下来即将进行的工作是图像去去除雨滴,去雾,去除噪声,去尘土和去模糊等都是这一类的,图像复原(低级图像处理/视觉任务)。采用生成对抗网络和感知损失进行这类研究的有相当一部分。下面进行相关汇总(资料调用)。
传统方法
1.首先列传统算法,最经典的莫过于凯明男神去雾算法:
《Single Image Haze Removal Using Dark Channel Prior》一文中图像去雾算法的原理、实现、效果(速度可实时)
在图像去雾这个领域,几乎没有人不知道《Single Image Haze Removal Using Dark Channel Prior》这篇文章,该文是2009年CVPR最佳论文。
code可以参考:
1).dehaze 暗通道去雾
2.Non-Local Image Dehazing
简单明了的图像去雾算法。
csdn:https://blog.csdn.net/cv_family_z/article/details/52849543
code:
1)https://github.com/xianshunw/scindapsus/tree/master/berman2016non-local
2)https://github.com/danaberman/non-local-dehazing
3)https://github.com/Sar-Kerson/dehazeProcessor
深度学习算法
1、Density-aware Single Image De-raining using a Multi-stream Dense Network CVPR2018
有感知/特征损失,[paper]、[testing code]
密度感知多路密集网络DID-MDN,联合完成雨点密度估计和雨点去除。
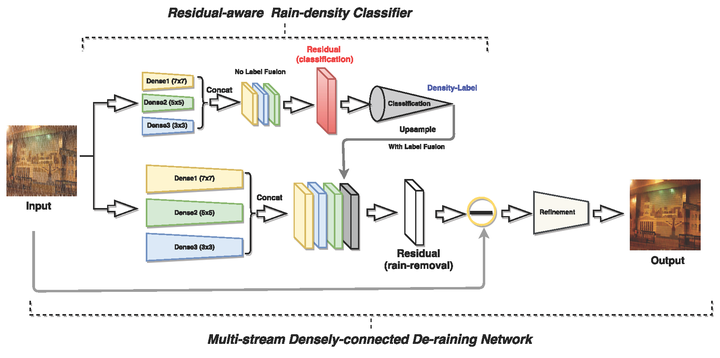
图 一
效果非常好,速度也是非常快,应该是目前最好的模型。算法中的预训练,然后联合训练,估计是很tricky的。
2、Attentive Generative Adversarial Network for Raindrop Removal from a Single Image CVPR2018
[paper]

图 二
该模型基于pix2pix,增加了attention-recurrent network,效果上比eigen2013的论文(第一个使用DL解决该问题的工作)好,也比pix2pix好。
但是给论文没有和其他算法比。
3、Densely Connected Pyramid Dehazing Network CVPR2018

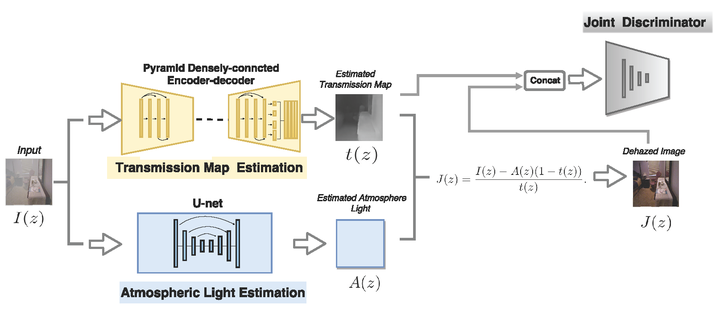
图 三
使用黄色网络估计transmission,利用蓝色网络估计atmospheric light,然后利用公司,计算得到去雾图像。
论文中总损失有4个子损失,训练非常tricky。。。
4、Deep Joint Rain Detection and Removal from a Single Image CVPR2017
比1差。
其中B是原图,O是带雨的图片,其他的量代表雨滴带来的影响。S指叠加的雨滴的强度,R指含雨滴范围的一个 binary mask,A对雨雾进行建模。之所以将S、R分别描述并分别用网络预测,是为了避免只回归S影响了图中不含雨滴的部分,R实际上描述了雨滴存在的区域,这也是标题中rain detection的含义。S、R预测的例子可见下图。t指的是图片中多个方向的雨叠加的效果,训练所用的合成雨的图片就是多次叠加的结果。最后A描述了一个图像整体的偏移,这是由大雨中远处大量雨滴叠加造成的类似雾的效果,实际算法中也用了去雾算法做处理。
在训练时作者使用了多分支的dilated convolution网络,以在节约计算量的同时扩大网络的感受,也获得更多的context信息。网络级联地预测S和R,在训练时都提供loss,在测试时得到S、R后,按之前的模型进行去雨处理。在实际实验中还发现采用去雨1次 – 去雾1次 – 再去雨1次的流程得到的结果是最好的。
此外在训练数据和测试方法上都是沿用之前工作的方法。训练数据都是使用不带雨的图片人工合成带雨的图片,并从图中抽取patch进行训练。在测试流程上,对于合成图片,主要比较衡量图片结构相似度的SSIM指标。对于真实环境的带雨图片,主要是视觉上的qualitative比较。
5、Image De-raining Using a Conditional Generative Adversarial Network 2017
1中作者的以前工作,类似pix2pix。
6、Clearing the Skies: A Deep Network Architecture for Single-Image Rain Removal TIP2017
[paper]
7、Removing rain from single images via a deep detail network CVPR2017
对于雨滴模型的创新主要是提出了2点insights。
1、类似ResNet的思路,回归带雨图像与原图的残差,而不是直接输出还原图像。这样一来可以使算法操作的图像目标值域缩小,稀疏性增强。实际上这一点在超分辨率等很多问题中已经被广泛应用。
2、使用频域变换,分离图像中的低频部分和高频部分,只对高频部分做去雨操作。原因是雨滴基本只存在于高频部分,分离后可以使得操作目标进一步稀疏化,实验效果显著优于不做这一操作的结果。
实现上作者使用了一个26层的ResNet,为了保证输出分辨率不变,去掉了所有的Pooling操作。实验表明:与直接输入带雨图像、输出原图相比,一个26层的ResNet效果已经与原始方法50层的ResNet效果相近,并显著优于其他旧方法。这证明了两个技巧的有效性。
8、Rain Streak Removal Using Layer Priors CVPR2016
[paper]
9.Single Image Rain Streak Decomposition Using Layer Priors TIP2017
10、Perceptual Adversarial Networks for Image-to-Image Transformation 2017
类似pix2pix,有感知损失,[paper]

图 四
11.Non-locally Enhanced Encoder-Decoder Network for Single Image De-raining(2018ACM)
深入研究了一种有效的端到端神经网络结构,用于更强的特征表达和空间相关学习。具体来说,我们提出了一种非局部增强的编码器 - 解码器网络框架,它由嵌入式索引编码器 - 解码器网络组成,有效地学习越来越抽象的特征表示,以便更精确地进行雨条纹建模,同时完美地保留图像细节。所提出的编码器 - 解码器框架由一系列非局部增强的密集块组成,这些块不仅可以完全利用来自所有卷积层的分层特征,而且可以很好地捕获长距离依赖性和结构信息。对合成和真实数据集的大量实验表明,所提出的方法可以有效地去除各种密度的雨天图像上的雨条纹,同时保留图像细节,与最近的最新方法相比,实现了显着的改进
小结:
以上工作的可迁移性包括:去除眼镜
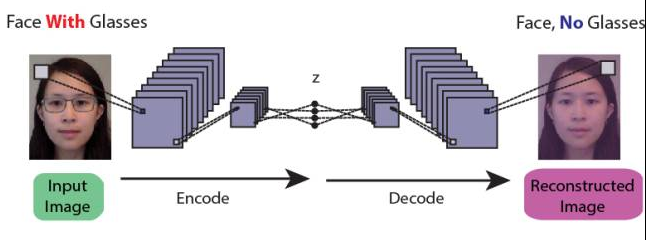
去除栅栏

参考链接:
1.知乎:https://www.zhihu.com/question/272305330/answer/366831382
2.https://www.jianshu.com/p/15ca85da6ae2

