
- 1test测试文档_文档test
- 2paho.mqtt.c使用的总结_paho.mqtt.cpp 手册
- 3python pool.map 多线程 多参数_pool.map多个参数
- 4如何在MAC 指定文件夹打开终端(terminal)_macos13怎么在指定文件夹开启终端
- 5最新版go-cqhttp的sign搭建教程和新版傻妞需要的插件
- 6树莓派通过网线连接电脑(校园网也能连接),实现SSH连接_树莓派ssh连接笔记本电脑
- 75600U PVE安装WIN10后直通核显_pve核显直通
- 8android打开相册的intent,Android 调用相机、打开相册、裁剪图片
- 9散布矩阵(scatter_matrix)及相关系数(correlation coefficients)实例分析
- 10node.js 安装及配置环境变量只看此文_node环境变量设置
国产开源模型标杆大升级,重点能力比肩ChatGPT!书生·浦语2.0发布,支持免费商用_浦医2.0
赞
踩
本文来自微信公众号”量子位”,作者:明敏,景联文科技经授权发布。
1月17日,新一代大语言模型书⽣·浦语2.0(InternLM2)正式发布并开源。
2种参数规格、3种模型版本,共计6个模型,全部免费可商用。
它支持200K超长上下文,可轻松读200页财报。200K文本全文范围关键信息召回准确率达95.62%。

不借助任何外部工具,内生数理能力超过ChatGPT。配合代码解释器,可达到和GPT-4相仿水平。

同时还带来工具多轮调用、更高共情等能力。
据了解,这些都得益于书生·浦语2.0在基础建模能力上完成大幅升级,语料质量更高、信息密度更大。
所以,书生·浦语2.0带来哪些升级?又是如何做到?
上海AI实验室领军科学家林达华教授,向我们披露了背后机密。
重点能力比肩ChatGPT
书生·浦语2.0共包含2种参数规格:7B和20B。
7B面向轻量级研究和应用,20B综合性能更强可支持更复杂的使用场景。
每个规格中包含3个模型版本。
l InternLM2-Base
l InternLM2
l InternLM2-Chat
Base版本是2.0中新增加的版本,它是标准版InternLM2 在进行能力强化前的版本,更加基础、可塑性也更高,因此更适合做探索研究。
标准版InternLM2是在Base基础上,对多个能力进行强化。它的评测成绩更好,同时保持了很好的通用语言能力,适合大部分应用。
Chat版本在Base基础上经过SFT和RLHF,在对话能力上进行加强,具有很好的指令遵循、共情、调用工具等能力。
具体能力方面,相较于上一代,InternLM2核心加强了基础语言建模能力。
可以看到两代模型在大规模高质量验证语料上的loss分布,第二代分布整体左移,表明语言建模能力实质性增强。
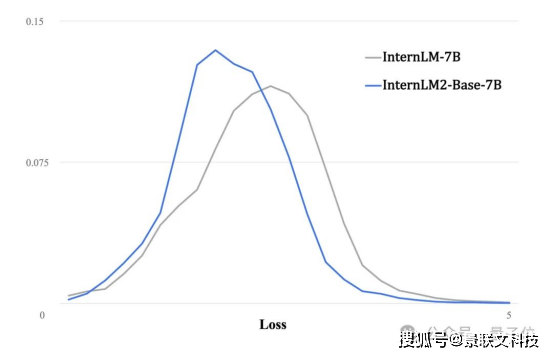
由此下游任务实现全方位提升,包括:
l 有效支持200K tokens超长上下文
l 支持复杂智能体搭建、工具多轮调用
l 内生数理能力超越ChatGPT
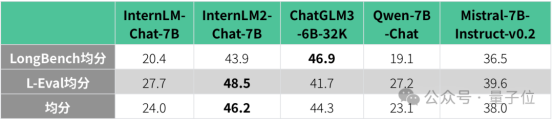
综合性能处于同规模开源模型领先水平
InternLM2现在有效支持20万字超长上下文,同时保持很高的信息召回成功率,相较于上一代提升明显。
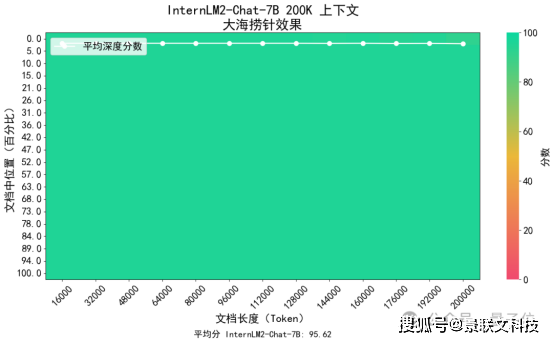
对InternLM2进行“大海捞针”实验,通过将关键信息随机插入一段长文本的不同位置构造问题,测试模型是否能从长文本中提取关键信息。
结果显示,InternLM2-Chat召回准确率始终保持在高位,16K以内的平均准确率达到 95.65%。
在实际场景中,InternLM2可以处理长达3个小时的会议记录、212页长的财报内容。
内生计算能力也有大幅提升。
InternLM2在不依靠计算器等外部工具的情况下,可进行部分复杂数学题的运算和求解。
100以内数学运算上可做到接近100%准确率,1000以内达到80%准确率。

如果配合代码解释器,20B模型已可以求解积分等大学级别数学题。

工具调用方面,基于更强和更具有泛化性的指令理解、工具筛选与结果反思等能力,InternLM2可更可靠地支持复杂智能体搭建,支持工具进行有效多轮调用、完成复杂任务。
综合性能方面,InternLM2在推理、数学、代码方面表现突出。
不仅相较于上一代提升明显,而且在标准测评集上,部分指标已经超越ChatGPT。

比如InternLM2-Chat-20B在MATH、GSM8K上,表现都超过ChatGPT。在配合代码解释器的条件下,则能达到和GPT-4相仿水平。

在AGIEval、 BigBench-Hard(BBH)等对推理能力有较高要求的评测上,新一代20B模型的表现优于ChatGPT。
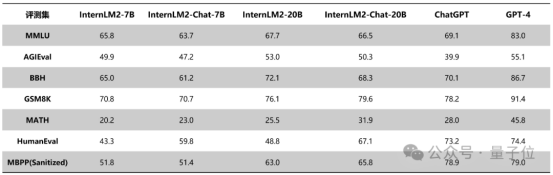
同时InternLM2还和其他开源模型进行了全方位性能对比。
对比规格相近基座模型和对话模型,结果如下:
6B-7B基座模型对比

13B-20B基座模型对比
注:Mixtral-8x7B每次推理会激活约 13B 参数,而且这个模型近期也备受关注,因此其表现也列在此处作为参考。
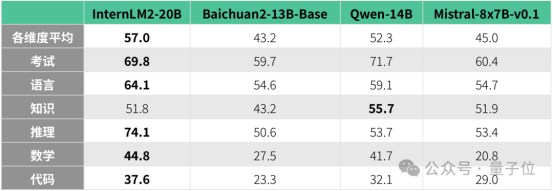
6B-7B对话模型对比
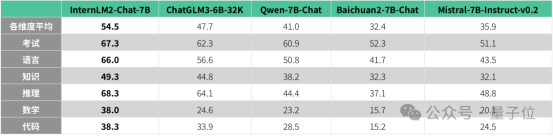
13B-20B对话模型对比

从各项数据来看,InternLM2已经完成了全方位升级,给开源社区带来了“ChatGPT级别”的大模型选择。
那么它是如何做到的?技术上做了哪些创新?
核心在于提升数据质量
和许多大模型迭代升级的路线不同,InternLM2并没有卷参数规模,而是把重点放在了数据方面。
上海AI实验室领军科学家林达华教授介绍,这是出于整体策略的考量。
提炼出一版非常好的数据后,它可以支持不同规格模型的训练。所以首先把很大一部分精力花在数据迭代上,让数据在一个领先的水平。在中轻量级模型上迭代数据,可以让我们走得更快。
为此,上海AI实验室研发了新一代数据清洗过滤体系,主要工作有3方面:
l 多维数据价值评估
l 高质量语料驱动的数据富集
l 有针对性的数据补齐
首先在数据价值评估上,基于语言质量、信息密度等维度对数据价值进行综合评估与提升。比如研究团队发现,论坛网页上的评论给模型能力带来的提升非常有限。
所以团队利用高质量语料的特征从物理世界、互联网以及语料库中进一步富集更多类似语料。
这样可以引导种子数据去汇聚真正有知识量的数据,加大它们的比重。
最后再针对性补充语料,重点加强世界知识、数理、代码等核心能力。
为了打造新一代数据清洗体系,研究团队训练了三位数的模型数量。因为体系每一次迭代,都起码需要训一个7B规模上的大模型做验证。
在新一代数据清洗技术的加持下,只使用约60%的训练数据,即可达到上一版数据训练1T tokens的性能表现。
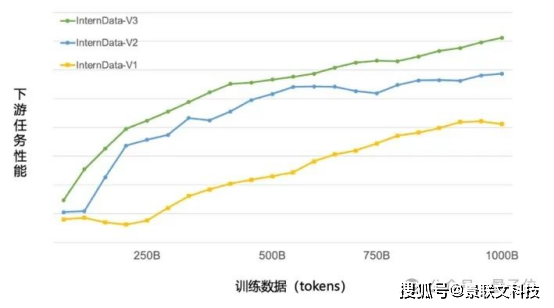
另外,为了避免数据污染导致评测结果失真,InternLM2通过更严谨的训练集构建流程,把各测试集排除在外,同时通过min-hash去重,去掉训练语料中和测试集接近的部分。
当然,InternLM2不仅关注模型基座能力,也基于当下应用趋势需求,针对一些下游任务能力做提升。
比如近来很火的超长上下文趋势,林达华教授介绍工具调用、数理推理等场景都需要更长的长下文窗口。
所以InternLM2通过拓展训练窗口大小和位置编码改进,并找到足够长且高质量、有结构以来关系的数据做训练,同时优化训练系统,将上下文窗口支持延长到了20万tokens。
在大模型对话体验方面,InternLM2采用Online RLHF,对奖励模型和对话模型进行三轮迭代更新,在每一轮更新中对前一轮模型更新偏好数据和训练prompt。
在奖励模型训练和PPO阶段都平衡地采用各类prompt,使得模型在安全性进一步提升的情况下,对话的主观体验也显著提升。
值得一提的是,研究团队同步开源了InternLM2-Chat仅SFT和SFT+RLHF的权重,供社区分析对比RLHF前后模型的变化。

总结来看,对于InternLM2的升级迭代,上海AI实验室核心关注模型基座能力,同时还结合大模型应用趋势的需求,针对部分下游任务做重点提升。
在快速演进的趋势里,这种清晰的思路很难得。
它需要团队对技术有深入理解、对趋势有准确判断,能大幅提升大模型开发效率,加速模型迭代升级。
而上海AI实验室能够得出如此思路,与其大模型初心有关。
做真正高质量的开源
2023年世界人工智能大会上,书生·浦语大模型正式开源。
通过书生·浦语的高质量全方位开源开放,我们希望可以助力大模型的创新和应用,让更多的领域和行业受惠于大模型变革的浪潮。

梳理来看,过去7个月里书生·浦语的一系列开源工作,彻底且全面。
范围覆盖通用大模型、专项任务大模型(书生·浦语灵笔)、全链条工具体系(贯穿数据、预训练、微调、部署、评测、应用)、多模态预训练语料(书生·万卷)等。
为什么要这样做?
上海AI实验室领军科学家林达华教授,给出了两方面原因。
直接原因是大模型应用趋势马上到来,开源高质量基座大模型能缩短落地过程的中间链条。
林达华教授分析,无论是公众还是商业领域,对大模型的耐心是有限度的。2024年大家必然会全力把大模型推向真正的应用落地。
做高质量基础大模型,能够让基础大模型在一个具体场景上做到应有水平,变得更方便、更迅速。
更加根本的底层原因在于,中国需要自己的高质量开源大模型。
大模型趋势由ChatGPT开启,但第二波高潮来自Meta开源LLaMA。它让更多个人、机构、企业能进入到大模型领域,发展出丰富的应用,给整个技术生态带来深刻影响。
但由于LLaMA在中文理解方面存在局限、以及合规性等方面的考虑,国内需要一个中文原生的高质量开源基座。
综合各方面因素,学术界力量更能胜任这件事。
开源基座大模型不仅要保证质量高,更关键是要长期可持续。企业也能做开源,但是它天生存在商业诉求、关注点会逐渐从底层技术转向商业应用,这本身无可厚非,所以需要上海人工智能实验室能在这里发挥自己的价值。
加之学术圈无需考虑构建商业壁垒,因此让开源更加彻底。
林达华教授介绍,上海AI实验室在做大模型时会考虑应用方面需要的能力,与合作伙伴共同打造具有开创和示范性质的创新应用,而不是打造To C的商业化应用。。
比如近期升级发布的医疗多模态基础模型群“浦医2.0”。它由上海AI实验室与上海交通大学医学院附属瑞金医院等合作伙伴联合发布,旨在为“跨领域、跨疾病、跨模态”的AI医疗应用提供能力支持。目前已经建设了智能影像诊断、数字病理科建设、数字人虚拟手术、智慧临床决策、创新医学科研五大应用场景。
这项工作同样主打开源。最新升级中不仅加入了多个领先医学大模型,新增5个开源数据集、新增评测模块等,实现了医疗大模型群“产、学、研、用、评”一站式开源。

△浦医2.0中的医疗基础模型涵盖病理、超声、CT、MR、心电等多个医疗领域
透过这些实际开源脚步,即可洞察到当下趋势正在发生哪些转变,以及上海AI实验室如何理解趋势。
2024年被业内视为大模型应用落地元年。开年伊始,上海AI实验室的动作更加聚焦应用层面。

林达华教授认为,2024年大模型领域的关键是,谁能找到大模型最具有可持续应用价值的场景。
这个应用价值可能并不是我们常见的那种交互形态,比如聊天APP。
我手机上装了十几个大模型对话APP,平均使用时长只有2个小时,因为它并不是我特别需要的应用。
所以对于整个业界来说,怎样找到一个大家公认的、真正有用的场景,是一个比较大的挑战。
一旦找到,大模型技术革命就会真正在历史上沉淀下来。”
而想要走到这一步,底层基础大模型是最根本、最关键的影响因素。
回归到技术发展上,林达华教授对于2024年也给出了一些预测和判断:
1. 大模型基础能力会逐渐收敛,之后模型间的关键区别在于谁的质量更高。
2. 目前大模型领域任何趋势热度都不会超过3个月,比如超长上下文能力很快会成为各家大模型标配。
3. 24年上半年会涌现一批开源多模态大模型。
4. 当下MoE还只是初级设计,发展到最高效设计仍需一段时间。
5 .24年国内很有希望出现比肩GPT-4的开源大模型。
总之,2024年,很有可能迎来开源大模型的高潮。
这不,开年第一枪已经由上海AI实验室打响了。
书生·浦语2.0开源链接:
https://github.com/InternLM/InternLM
免费商用授权许可申请:
https://wj.qq.com/s2/12725412/f7c1


