
- 1奶茶点餐|奶茶店自助点餐系统|基于微信小程序的饮品点单系统的设计与实现(源码+数据库+文档)_奶茶店微信小程序的源代码运行结果图片
- 2最炙手可热的行业——大数据就业方向和学习路线图详解!_数据科学与大数据技术 就业拓扑图
- 3记录一下Android Studio设置模拟器的安装位置_mac android studio 查看模拟器路径
- 4PyTorch搭建LeNet训练集详细实现
- 5内网搭建Ubuntu(银河麒麟)的apt本地源服务器_银河麒麟配置本地apt源
- 6平衡搜索二叉树之红黑树(拒绝死记硬背,拥抱理解记忆)_java 平衡二叉树 红黑树
- 7人脸识别之人脸对齐(一)--定义及作用
- 8设计一个聊天系统200问?
- 9烤仔TVのCCW丨密码学通识(四)选择密文攻击
- 10Promise详解
AI人工智能产业发展三大核心趋势:多模态预训练大模型、高质量数据智能、智能算力的崛起_预训练大模型,高质量数据的重要性
赞
踩
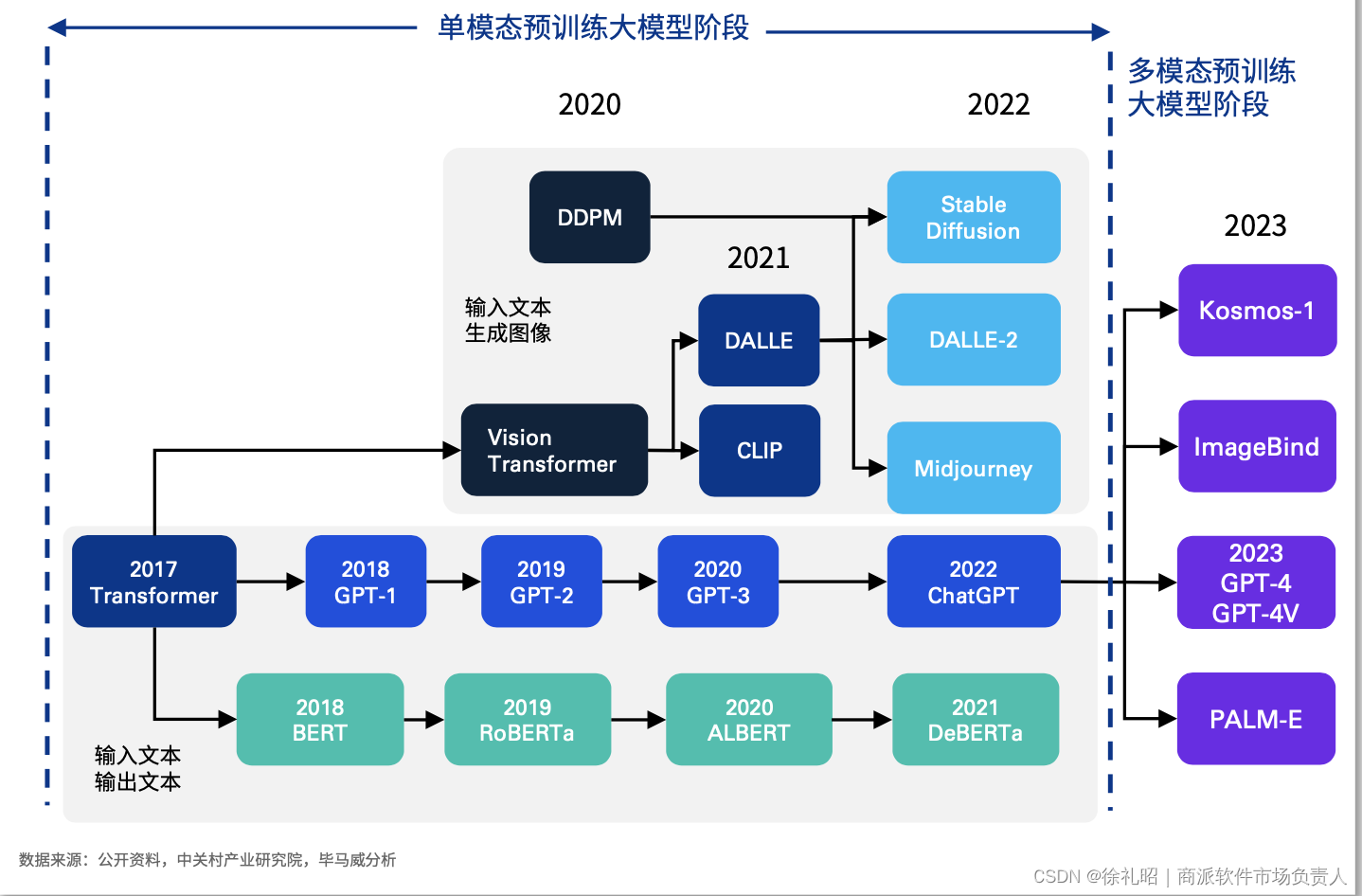
随着ChatGPT引发的大模型创新浪潮的持续涌动,我们正面临着一场可能比工业革命和信息革命更为深刻的人工智能革命。在这一时代背景下,无论是推动大模型从单模态发展到多模态,还是倡导高质量数据和计算新范式,我们都在强调人工智能技术变革的本质——那就是算法、数据、算力这三大基础要素的精巧配合和相互促进。
一、多模态预训练大模型:人工智能产业的新标配
多模态预训练大模型,这一前沿技术,主要包括三层含义。首先,“大模型”也称为基础模型(Foundation Models),是基于大规模数据训练的模型,具有广泛的应用领域。其次,“预训练”强调大模型的训练发生在模型微调(fine-tuning)之前,这一阶段能够集中学习到尽可能泛化的通用特征,而在微调阶段,则需要结合较小规模、特定任务的数据集进行调整,从而达到广泛适用各类任务场景的效果。最后,“多模态”则是指用于训练大模型的数据来源和形式具有多样性,例如,人类通过视觉、听觉、嗅觉等多种感官获取信息,再通过声音、文字、图像等多种载体进行沟通表达,这就是多模态的输入和输出。
预训练大模型的发展起源于自然语言处理(NLP)领域,当前已进入“百模大战”阶段。预计随着大模型创新从单模态转向多模态,多模态预训练大模型将逐渐成为人工智能产业的标配。值得注意的是,目前所公开的模型大部分仅支持文本输入,较为前沿的GPT-4还支持图像输入,但模型的输出只能实现文本和图像两种模态。然而,自2023年9月底以来,OpenAI将ChatGPT 4升级至GPT-4 with vision(GPT-4V),增强了视觉提示功能。在相关样本观察中,GPT-4V在处理任意交错的多模态输入(interleaved multimodal inputs)方面表现突出。这种多模态的模型训练方法更接近于人类接收、处理、表达信息的方式,能更为全面地展现信息原貌,是未来人工智能模型演进的重点方向。
AI大模型的发展趋势正在从支持文本、图像、音频、视频等单一模态下的单一任务,逐渐发展为支持多种模态下的多种任务。这意味着,未来大模型的比拼重点将不再是单一模态下参数量的提升,而是转向多模态信息整合和深度挖掘。通过预训练任务的精巧设计,模型将能够更精准地捕捉到不同模态信息之间的关联。这一转变将为人工智能产业带来巨大的影响力和价值潜力,标志着人工智能技术正朝着更全面、更深入的方向发展。
二、高质量数据的稀缺性与数据智能的飞跃
随着AI大模型商业化竞争的日益加剧,作为模型训练“原料”的数据,尤其是高质量数据,正面临短缺危机。据Epoch AI Research团队的研究预测,高质量的语言数据存量将在2026年耗尽,而低质量的语言数据和图像数据存量则分别在2030年至2050年、2030年至2060年枯竭。这一趋势意味着,除非有新的数据源出现或数据利用效率得到显著提升,否则2030年以后,AI大模型的发展速度将大幅放缓。
数据智能的重要性
数据智能是指从数据中提炼、发掘和获取有揭示性和可操作性的信息,为基于数据的决策或任务执行提供有效的智能支持。它融合了多种底层技术,包括数据处理、数据挖掘、机器学习、人机交互和可视化等,并可划分为数据平台技术、数据整理技术、数据分析技术、数据交互技术和数据可视化技术等部分。
高质量数据的挑战与机遇
大模型的训练对高质量数据有着巨大的需求,但目前的数据质量存在诸多问题,如数据噪声、数据缺失和数据不平衡等,这些问题直接影响大模型的训练效果和准确性。然而,预计大模型领域对高质量数据的不断增长的需求将推动数据在大规模、多模态和高质量三个维度上实现全面提升。这一趋势有望为数据智能相关技术带来跨越式发展的机遇。
为了满足这一需求,我们需要创新的数据收集、清洗和标注方法,以提高数据的质量和多样性。同时,通过改进数据增强技术和迁移学习方法,我们可以更有效地利用现有数据资源,缓解高质量数据的短缺问题。这些努力将共同推动人工智能领域实现更高水平的发展。
三、智能算力的崛起与计算新范式的加速实现
算力,作为大模型训练的“燃料”,以高效且成本较低的方式为人工智能发展注入源源不断的核心动力,已成为产业界的共识。在深度学习出现之前,AI训练的算力增长大约每20个月翻一番,基本符合摩尔定律;然而,深度学习出现后,这一增长周期缩短至每6个月翻一番。特别是2012年后,全球头部AI模型的训练算力需求更是加速到每3-4个月翻一番,平均每年算力增长幅度高达惊人的10倍。当前,随着大模型的蓬勃发展,训练算力需求有望扩张到原来的10-100倍,使得算力需求的指数级增长曲线更加陡峭。
但这一迅猛增长的算力需求也带来了巨大的成本挑战。以构建GPT-3为例,OpenAI的数据显示,满足GPT-3的算力需求至少需要上万颗英伟达GPU A100,一次模型训练的总算力消耗约为3,640PF-days(即每秒一千万亿次计算,运行3,640天),成本超过1,200万美元。这还未考虑到模型推理成本和模型后续升级所需的训练成本。
在此背景下,变革传统计算范式变得势在必行。产业界正加速推动芯片和计算架构的创新。例如,谷歌自2016年以来不断研发专为机器学习定制的专用芯片TPU(Tensor Processing Unit,张量处理器),并利用TPU进行了大量的人工智能训练工作。英伟达则紧抓AI大模型爆发的契机,大力推广“GPU+加速计算”方案。此外,也有观点认为TPU、GPU并非通用人工智能的最优解,指出量子计算具有原理上远超经典计算的强大并行计算能力。例如,IBM在2023年宣布将与东京大学和芝加哥大学合作建造由10万个量子比特(量子信息处理的基本单位)驱动的量子计算机,这有望推进量子计算在新药物研发、探索暗物质、破译密码等方面的应用。
新硬件、新架构的竞相涌现意味着现有芯片、操作系统、应用软件等都可能面临重大变革。预计在未来,“万物皆数据”“无数不计算”“无算不智能”将成为现实,智能算力将无处不在。这一趋势将呈现“多元异构、软硬件协同、绿色集约、云边端一体化”四大特征,共同推动人工智能进入一个新的发展纪元。

