
- 1前端错误 “TypeError Cannot read properties of undefined (reading ‘xxx‘)_[system] typeerror: cannot read properties of unde
- 2Java程序员必看!深入理解java虚拟机pdf下载_《深入理解java虚拟机》第四版 pdf 下载
- 3深度学习最全面试题总结(二)_深度学习面试题 神经网络的深度和宽度分别指的是什么?
- 4Grounded-Segment-Anything环境安装踩坑记录_ground segment anything安装
- 5基于html5在线音乐动态网站,基于html5的音乐网站.doc
- 6米哈游客户端笔试题_校招进米哈游客户端开发岗位需要具备哪些能力?
- 7Android Studio错误project :app > org.jetbrains.kotlin:kotlin-stdlib-jdk7:1.6.10
- 8macOS Sonoma 14beta 2 With OpenCore 0.9.3 and winPE双引导黑苹果镜像_macos sonoma 14.3.1 23d60 installer for oc 0.9.8 a
- 9MT6737 Android N 平台 Audio系统学习----Accdet
- 10【MarkDown】CSDN Markdown之流程图graph&flowchart详解_markdown 流程图
【基于序列的推荐】:Session-based Recommendations with Recurrent Neural Networks (附开源代码)
赞
踩
论文下载地址:https://arxiv.org/pdf/1511.06939.pdf
论文实现代码:https://github.com/Shicoder/GRU4Rec
首先解释一下什么是Session,Session就是从用户进入推荐界面到其离开的一次完整的行为流程。
作者将rnn应用到session推荐任务中。在传统的推荐任务中,往往着重考虑用户最后一次的点击行为,而与之同一时间段下前几次的点击行为关联分析则较为忽视。要考虑一次session的数据,利用矩阵分解方法显然不足。一般这种情况的解决方式,就是推荐和近期点击的item最相似的item。作者提出了将Session做为整个行为数据流,而RNN正好擅长处理这种序列数据,因此利用RNN对其进行建模。
介绍
在实际问题中,基于session的推荐较多都难以处理。因为很多电商推荐系统(尤其是一些小商家),通常都不会去跟踪用户进入推荐平台后的一系列行为数据。所以很少有针对session的推荐,就是有,大部分可能只考虑了最后一次的点击行为,然后根据item-to-item来推荐最相似的item。
现在常见的推荐系统化主要有factor models 和neighborhood methods。factor 主要通过分解稀疏的user-item 交互矩阵,将user和item分解为向量。而推荐的问题可以定义为将矩阵进行重建的问题,即对矩阵中缺失的行为数据进行填充。归结起来就是稀疏矩阵的缺失值填充问题。但是因为缺乏用户画像,factor model很难应用到session推荐任务中。另一方面,neighborhood 方法依赖基于画像或者session中items的共现来计算items或者users之间的相似度,因此neighborhood方法可以很好的在session推荐任务中推广。
过去几年深度学习在图像和语音识别中发展如日中天,如CNN在图像和语音这种非结构化数据中的应用。而RNN现在也被大量的应用到序列数据的建模中。
在本文中,作者就将RNN应用到了基于session的推荐中,并获得来显著的效果。作者将基于sesssion的推荐定义一个稀疏序列数据推荐问题,针对rnn建模定义来一个新的rank损失函数,以满足当前的任务需求。我们将用户进入网站后的第一次点击作为rnn的初始输入,然后基于训练的模型去找到基于该初始输入的推荐item,而每一个连续的点击序列,都会基于完整的点击序列产生一个新的推荐输出item。
相关工作
基于session的推荐
现在推荐系统主要还是集中在对用户行为数据建模,利用用户画像来对用户行为进行建模预测。而针对session的推荐或者一些缺失用户画像的推荐只能通过item-2-item的方法来进行推荐。但是大多数的方法都只考虑其最近一次的点击行为,而忽视来整个session的推荐行为。
另外一个基于session的推荐是利用马尔可夫决策过程MDPs。MDPs定义为一个四元组:<S,A,Rwd,tr>,其中S是状态集合,A是行为集合,Rwd是奖励函数,tr是状态转移函数。在推荐系统中,行为可以等价与推荐item,而下一次的推荐行为可以通过计算状态转移概率来确定推荐不同item的概率值。而使用马尔可夫链处理session推荐的主要问题在于将所有可能的用户选择序列作为状态,那么整个状态空间将非常大。
广义分解模型也可以用于基于sesion的推荐。它通过将所有事件进行求和来表示一个sessio。它将item分为两种潜在的表征。一种是它本身,另外一种是将其作为session的一部分。这样的话一个session其实就可以表示为session中所有item表征的和。但是这种方法并没有考虑到session各个item之间的前后点击顺序关系。
推荐中的深度学习
最早的将神经网络引入推荐的是将RBM应用到协同过滤当中。还有其他如利用深度模型去对无结构数据进行特性提取,丰富画像。
引入RNN的推荐系统
RNN主要用于序列数据的推荐。具体RNN的原理可以看这里:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
传统RNN中cell的更新公式如下:
h_t=g(Wx_t+Uh_t_-_1)
这里的g就是一个非线形映射函数,可以是tanh或者sigmoid等。而其输入就是在时间t时刻的输入值。RNN可以根据当前的状态,根据当前输入来预测该序列下一个输出数据的概率。
GRU是RNN的一种变体,RNN存在验证的梯度消失问题,所以出现了像LSTM和GRU这样的变体,用于克服RNN优化过程中带来的梯度消失问题。算了,这里不再具体将GRU的cell了,自行百度吧。下面直接讲下本文的算法实现。
就单个session而言,算法的思路就是将利用GRU来对整个session序列建模,把每个item作为一个time step下的输入,但是和一般的处理不同的是,作者每输入一次item就预测并更新一次GRU参数,保存当前的cell的状态,并在该状态下继续输入下一个item,并预测下下次的会出现的item。训练完成的GRU模型即可以通过连续输入整个session的item来预测之后可能点击的item。比如说session是{item_1,item_2,...,item_n},那么预测的时候就是输入item_1 保存state,在当前state下继续输入item_2,更新状态为新的state,继续输入item_3,直到最后一次输出的预测的结果。
当然在输入item的时候,需要做one_hot或者embedding。
并行session 最小批
正常的自然语言处理中,序列的批处理往往都是将序列进行截断成同样长度的子序列,然后把一批子序列输入模型来按批训练。但是这里因为每个session的长度都不一样,所以作者提出来一个并行session最小批方法。

如上图所示,并行session最小批的处理方式是,假设选择来n个序列为一个批,那么选出每个session的第一个item,即有n个item,作为第一个输入rnn的batch。然后第二个batch就是取出每个session的第二个item。如果其中任何一个session结束了,那么再选一个新的session,来代替。可以想象为定义来n个队列,一个队列放一个session,然后每个队列按顺序同时从头部弹出一个item。如果任何一个队列空了。则选择一个新的session填充队列。继续重复操作。
输出采样
一般的推荐系统中,item的数量都很大,所以在GRU训练过程中,我们不可能对所有的item都去计算score。所以需要对item进行采样,说白了,正样本就一个,负样本是剩下的整个item集合中的所有item。显然不合理。作者采用了一个取巧的方法对负样本进行了采样。他将同一个训练batch中其他session中的item作为负样本,这样不管是对计算还是对模型都方便了很多。并且也按每个item的流行度进行了采样。
排序损失
样本有了,接下来就是损失函数的定义了。推荐系统的实践证明,把问题抽象化为rank排序问题要比分类问题更好。常见的排序损失函数有基于point-wise的,只需要确保目标物体的得分较高就可以了。还有及时pair-wise lose,这样的损失函数需要正负样本,训练的目标是需要正样本的得分高于负样本。还有一个是list-wise,是对整个推荐的list进行排序,确保正样本都在负样本前面。
作者选择了利用pair-wise作为损失函数,分别是BPR和TOP1。
BPR的公式如下:
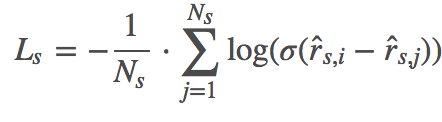
这里
TOP1 公式如下:
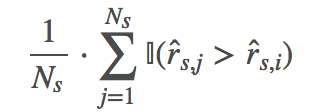
其中这里的损失函数使用的是sigmoid()。
总结
作者做了多组基线实现来对比本文的算法,以及做模型具体参数调参结果都做了详细的实验。整体的思路很新颖,这个应该是当时最早采用RNN来做序列推荐的论文。之后也有很多对这篇论文的改进,比如引入session中不同item之间的时间差,或者进入一些用户的特征来作为辅助等等。本文提出的算法虽然新颖,但是因为需要处理变长的session,训练完成的模型处理单个session还有,但是要应用到实际的工业环境中去,如果线上实时预测,很难处理不同序列长度的问题,也会带来一部分的性能问题。
该论文的代码可以直接在github搜GRU4Rec找到。

