
- 1LLM大模型推理加速实战:vllm、fastllm与llama.cpp使用指南
- 2【论文笔记】——从transformer、bert、GPT-1、2、3到ChatGPT_chatgpt和transformer
- 3自然语言处理:Word embedding 技术_基于word2vec模型的词嵌入分析会用到啥技术支持
- 4边缘计算框架_中国首发的开源边缘计算框架
- 5AI/DM相关conference ddl(更新中)_iclr2024
- 6AI 全自动玩斗地主,靠谱吗?Douzero算法教程
- 7matlab代码——最大相关性最小冗余性(MRMR)_mrmr的输出结果
- 8AB测试的介绍与实施
- 9google最新大语言模型gemma本地化部署_gemma 要求
- 10关于优先队列_c++优先队列的参数
图像风格迁移_AI绘画第二弹——图像风格迁移
赞
踩
这篇文章是我的《AI绘画系列》的第三篇,点击此处可以查看整个系列的文章
本篇文章的源码可以在微信公众号「01二进制」后台回复「图像风格迁移」获得
简介
所谓图像风格迁移,是指将一幅内容图A的内容,和一幅风格图B的风格融合在一起,从而生成一张具有A图风格和B图内容的图片C的技术。目前这个技术已经得到了比较广泛的应用,这里安利一个app——"大画家",这个软件可以将用户的照片自动变换为具有艺术家的风格的图片。

准备
其实刚开始写这篇文章的时候我是准备详细介绍下原理的,但是后来发现公式实在是太多了,就算写了估计也没什么人看,而且这篇文章本来定位的用户就是只需要实现功能的新人。此外,有关风格迁移的原理解析的博客实在是太多了,所以这里我就把重点放在如何使用 TensorFlow 实现一个快速风格迁移的应用上,原理的解析就一带而过了。如果只想实现这个效果的可以跳到**"运行"**一节。
第一步我们需要提前安装好 TensorFlow,如果有GPU的小伙伴可以参考我的这篇文章搭建一个GPU环境:《AI 绘画第一弹——用GPU为你的训练过程加速》,如果打算直接用 CPU 运行的话,执行下面一行话就可以了
pip install numpy tensorflow scipy 复制代码原理
本篇文章是基于A Neural Algorithm of Artistic Style一文提出的方法实现的,如果嫌看英文论文太麻烦的也可以查看我对这篇文章的翻译【译】一种有关艺术风格迁移的神经网络算法。
为了将风格图的风格和内容图的内容进行融合,所生成的图片,在内容上应当尽可能接近内容图,在风格上应当尽可能接近风格图,因此需要定义内容损失函数和风格损失函数,经过加权后作为总的损失函数。

预训练模型
CNN具有抽象和理解图像的能力,因此可以考虑将各个卷积层的输出作为图像的内容,这里我们采用了利用VGG19训练好的模型来进行迁移学习,一般认为,卷积神经网络的训练是对数据集特征的一步步抽取的过程,从简单的特征,到复杂的特征。训练好的模型学习到的是对图像特征的抽取方法,而该模型就是在imagenet数据集上预训练的模型,所以理论上来说,也可以直接用于抽取其他图像的特征,虽然效果可能没有在原有数据集上训练出的模型好,但是能够节省大量的训练时间,在特定情况下非常有用。
加载预训练模型
def vggnet(self): # 读取预训练的vgg模型 vgg = scipy.io.loadmat(settings.VGG_MODEL_PATH) vgg_layers = vgg['layers'][0] net = {} # 使用预训练的模型参数构建vgg网络的卷积层和池化层 # 全连接层不需要 # 注意,除了input之外,这里参数都为constant,即常量 # 和平时不同,我们并不训练vgg的参数,它们保持不变 # 需要进行训练的是input,它即是我们最终生成的图像 net['input'] = tf.Variable(np.zeros([1, settings.IMAGE_HEIGHT, settings.IMAGE_WIDTH, 3]), dtype=tf.float32) # 参数对应的层数可以参考vgg模型图 net['conv1_1'] = self.conv_relu(net['input'], self.get_wb(vgg_layers, 0)) net['conv1_2'] = self.conv_relu(net['conv1_1'], self.get_wb(vgg_layers, 2)) net['pool1'] = self.pool(net['conv1_2']) net['conv2_1'] = self.conv_relu(net['pool1'], self.get_wb(vgg_layers, 5)) net['conv2_2'] = self.conv_relu(net['conv2_1'], self.get_wb(vgg_layers, 7)) net['pool2'] = self.pool(net['conv2_2']) net['conv3_1'] = self.conv_relu(net['pool2'], self.get_wb(vgg_layers, 10)) net['conv3_2'] = self.conv_relu(net['conv3_1'], self.get_wb(vgg_layers, 12)) net['conv3_3'] = self.conv_relu(net['conv3_2'], self.get_wb(vgg_layers, 14)) net['conv3_4'] = self.conv_relu(net['conv3_3'], self.get_wb(vgg_layers, 16)) net['pool3'] = self.pool(net['conv3_4']) net['conv4_1'] = self.conv_relu(net['pool3'], self.get_wb(vgg_layers, 19)) net['conv4_2'] = self.conv_relu(net['conv4_1'], self.get_wb(vgg_layers, 21)) net['conv4_3'] = self.conv_relu(net['conv4_2'], self.get_wb(vgg_layers, 23)) net['conv4_4'] = self.conv_relu(net['conv4_3'], self.get_wb(vgg_layers, 25)) net['pool4'] = self.pool(net['conv4_4']) net['conv5_1'] = self.conv_relu(net['pool4'], self.get_wb(vgg_layers, 28)) net['conv5_2'] = self.conv_relu(net['conv5_1'], self.get_wb(vgg_layers, 30)) net['conv5_3'] = self.conv_relu(net['conv5_2'], self.get_wb(vgg_layers, 32)) net['conv5_4'] = self.conv_relu(net['conv5_3'], self.get_wb(vgg_layers, 34)) net['pool5'] = self.pool(net['conv5_4']) return net复制代码训练思路
我们使用VGG中的一些层的输出来表示图片的内容特征和风格特征。比如,我使用[‘conv4_2’,’conv5_2’]表示内容特征,使用[‘conv1_1’,’conv2_1’,’conv3_1’,’conv4_1’]表示风格特征。在settings.py中进行配置。
# 定义计算内容损失的vgg层名称及对应权重的列表CONTENT_LOSS_LAYERS = [('conv4_2', 0.5),('conv5_2',0.5)]# 定义计算风格损失的vgg层名称及对应权重的列表STYLE_LOSS_LAYERS = [('conv1_1', 0.2), ('conv2_1', 0.2), ('conv3_1', 0.2), ('conv4_1', 0.2), ('conv5_1', 0.2)]复制代码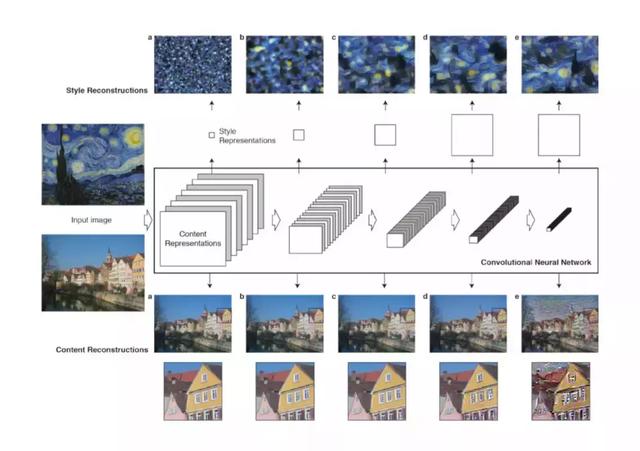
内容损失函数
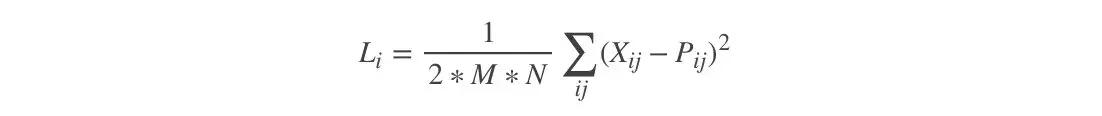
其中,X是噪声图片的特征矩阵,P是内容图片的特征矩阵。M是P的长*宽,N是信道数。最终的内容损失为,每一层的内容损失加权和,再对层数取平均。
我知道很多人一看到数学公式就会头疼,简单理解就是这个公式可以让模型在训练过程中不断的抽取图片的内容。
风格损失函数
计算风格损失。我们使用风格图像在指定层上的特征矩阵的GRAM矩阵来衡量其风格,风格损失可以定义为风格图像和噪音图像特征矩阵的格莱姆矩阵的差值的L2范数。
对于每一层的风格损失函数,我们有:
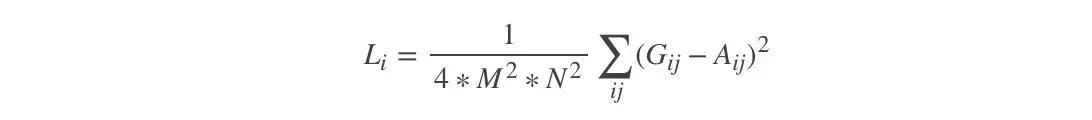
其中M是特征矩阵的长*宽,N是特征矩阵的信道数。G为噪音图像特征的Gram矩阵,A为风格图片特征的GRAM矩阵。最终的风格损失为,每一层的风格损失加权和,再对层数取平均。
同样的,看不懂公式没关系,你就把它理解为这个公式可以在训练过程中获取图片的风格。
计算总损失函数并训练模型
最后我们只需要将内容损失函数和风格损失函数带入刚开始的公式中即可,要做的就是控制一些风格的权重和内容的权重:
# 内容损失权重ALPHA = 1# 风格损失权重BETA = 500复制代码ALPHA越大,则最后生成的图片内容信息越大;同理,BETA越大,则最后生成的图片风格化更严重。
当训练开始时,我们根据内容图片和噪声,生成一张噪声图片。并将噪声图片喂给网络,计算loss,再根据loss调整噪声图片。将调整后的图片喂给网络,重新计算loss,再调整,再计算…直到达到指定迭代次数,此时,噪声图片已兼具内容图片的内容和风格图片的风格,进行保存即可。
运行
如果对上述原理不感兴趣的,想直接运行代码的可以去微信公众号「01二进制」后台回复「图像风格迁移」获得源码。接下来我们来说说如何使用这个代码跑出自己的绘画。
首先看下项目结构:
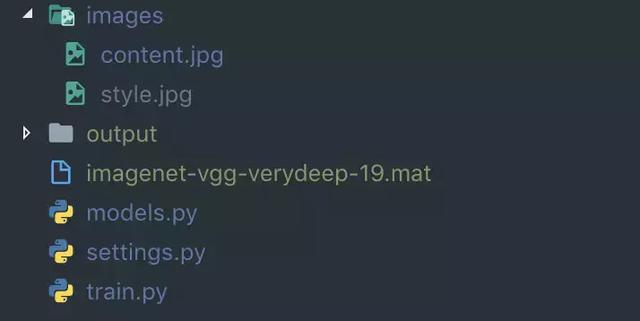
images下有两张图片,分别是内容图和风格图,output下是训练过程中产生的文件,.mat文件就是预训练模型,models.py是我们实现的用于读取预训练模型的文件,settings.py是配置文件,train.py是最终的训练文件。
想要运行该项目,我们只需要执行python train.py即可,想更改风格和内容的的话只要在images文件中更换原先的图片即可。当然你也可以在settings.py中修改路径:
参考文献:K码农-http://kmanong.top/kmn/qxw/form/home?top_cate=28# 内容图片路径CONTENT_IMAGE = 'images/content.jpg'# 风格图片路径STYLE_IMAGE = 'images/style.jpg'# 输出图片路径OUTPUT_IMAGE = 'output/output'# 预训练的vgg模型路径VGG_MODEL_PATH = 'imagenet-vgg-verydeep-19.mat'复制代码我们来看看训练后的图片:

最后
虽然通过上述代码我们可以实现图像的风格迁移,但是他有一个最大的缺点,就是无法保存训练好的模型,每次转换风格都要重新跑一遍,如果使用CPU跑1000轮的话大约是在30分钟左右,因此推荐大家使用GPU进行训练。
但是即使使用上了GPU,训练时间也无法满足商业使用的,那有没有什么办法可以保存训练好的风格模型,然后直接快速生成目标图片呢?当然是有的,斯坦福的李飞飞发表过一篇《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》,通过使用perceptual loss来替代per-pixels loss使用pre-trained的vgg model来简化原先的loss计算,增加一个transform Network,直接生成Content image的style。这里就不再多说了,感兴趣的可以参考我下面给出的两个链接:
- 《深度有趣 | 30 快速图像风格迁移》
- 《风格迁移背后原理及tensorflow实现》
以上就是本篇文章的全部内容,个人做下来感觉还是挺有意思的,因个人能力有限,文中如有纰漏错误之处,还请各位大佬指正,万分感谢!
参考
- A Neural Algorithm of Artistic Style
- 深度学习实战(一)快速理解实现风格迁移
- 深度有趣 | 04 图像风格迁移
- 学习笔记:图像风格迁移
欢迎关注我的微信公众号:「01二进制」,关注后即可获得博主认真收集的计算机资料
- maven依赖
org.apache.poi [详细] 赞
踩

