
热门标签
热门文章
- 1基于神经网络的依存句法分析_神经网络 依存句法分析
- 2启动spark报错java.net.UnknownHostException: unknown error解决方案_spark-sql报错 java.net.unknownhostexception: maxc1
- 3Stability AI官宣Stable Code Instruct 3B模型,编程效率迎新突破|TodayAI
- 4jupyter notebook中安装NTLK库方法_怎么在notebook里面安装nltk
- 5AI做算法和做工程_ai agent 算法与工程分工
- 6Transformer详解(附代码实现及翻译任务实现)_transformer代码
- 7多标签分类(二):Deep Learning with a Rethinking Structure for Multi-label Classification_二进制相关性 br
- 83 — NLP 中的标记化:分解文本数据的艺术_标记化技术的参数
- 9全量知识系统 程序详细设计之“ AI操作系统” (百度AI的Q&A)
- 10pytorch 训练数据以及测试 全部代码(9)---deeplab v3+ 对Cityscapes数据的处理_class cityscapessegmentation(data.dataset):
当前位置: article > 正文
AI人工智能进阶-BERT/Torch/Huggingface知识集锦_bert图像分类
作者:知新_RL | 2024-03-25 20:25:17
赞
踩
bert图像分类
[x]
span翻译成“文段”
。Cambridge dictionary的定义是:the length of something from one end to the other,所以在一段文本里,就是连续的若干token (usually represented as word in English or character in Chinese) ,
通常在NLP中所说的SPAN指的是一个片段,如图所示的span指的是位置2-4(包含)对应的“中国人”这个文本片段。


tokenizer的不同功能:
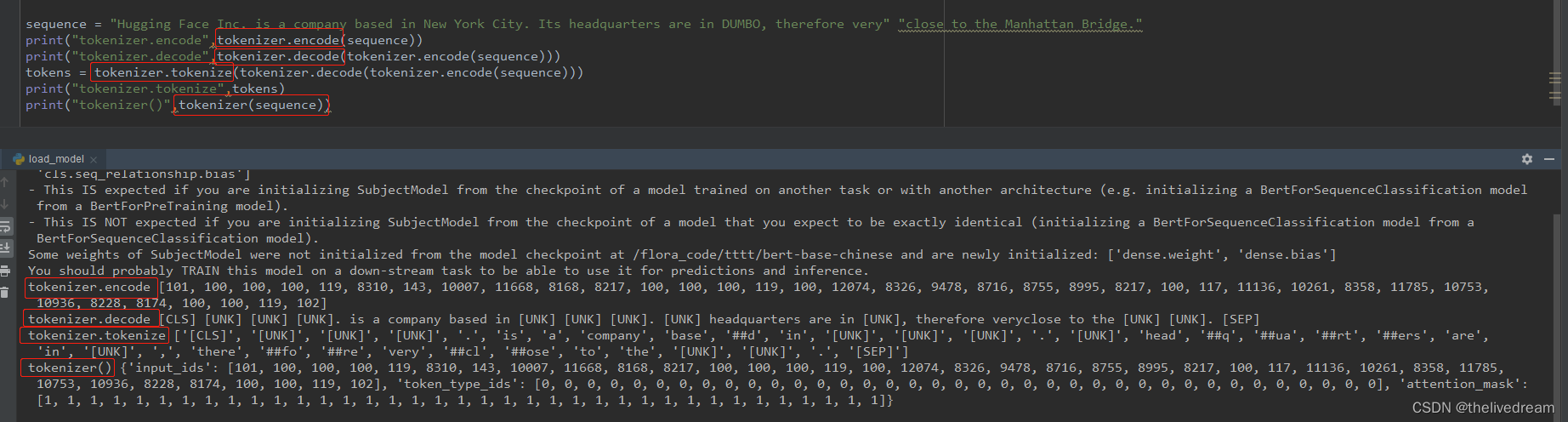
学习率的调试:
关于学习率的选择,请参考:
https://arxiv.org/pdf/1506.01186.pdf


预训练与微调(fine tuning)?
1.1. 什么是预训练
你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是 pre-training。
深度网络存在问题:
网络越深,需要的训练样本数越多。若用监督则需大量标注样本,不然小规模样本容易造成过拟合。深层网络特征比较多,会出现的多特征问题主要有多样本问题、规则化问题、特征选择问题。
多层神经网络参数优化是个高阶非凸优化问题,经常得到收敛较差的局部解;
梯度扩散问题,BP算法计算出的梯度随着深度向前而显著下降,导致前面网络参数贡献很小,更新速度慢。
解决方法:
逐层贪婪训练,无监督预训练(unsupervised pre-training)即训练网络的第一个隐藏层,再训练第二个…最后用这些训练好的网络参数值作为整体网络参数的初始值。
经过预训练最终能得到比较好的局部最优解。
2.2. 什么是模型微调fine tuning
用别人的参数、修改后的网络和自己的数据进行训练,使得参数适应自己的数据,这样一个过程,通常称之为微调(fine tuning).
模型的微调举例说明:
我们知道,CNN 在图像识别这一领域取得了巨大的进步。如果想将 CNN 应用到我们自己的数据集上,这时通常就会面临一个问题:通常我们的 dataset 都不会特别大,一般不会超过 1 万张,甚至更少,每一类图片只有几十或者十几张。这时候,直接应用这些数据训练一个网络的想法就不可行了,因为深度学习成功的一个关键性因素就是大量带标签数据组成的训练集。如果只利用手头上这点数据,即使我们利用非常好的网络结构,也达不到很高的 performance。这时候,fine-tuning 的思想就可以很好解决我们的问题:我们通过对 ImageNet 上训练出来的模型(如CaffeNet,VGGNet,ResNet) 进行微调,然后应用到我们自己的数据集上。
所以,预训练 就是指预先训练的一个模型或者指预先训练模型的过程;微调 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程
2. 微调时候网络参数是否更新?
答案:会更新。
finetune 的过程相当于继续训练,跟直接训练的区别是初始化的时候。
直接训练是按照网络定义指定的方式初始化。
finetune是用你已经有的参数文件来初始化。
3. fine-tuning 模型的三种状态
状态一:只预测,不训练。 特点:相对快、简单,针对那些已经训练好,现在要实际对未知数据进行标注的项目,非常高效;
状态二:训练,但只训练最后分类层。 特点:fine-tuning的模型最终的分类以及符合要求,现在只是在他们的基础上进行类别降维。
状态三:完全训练,分类层+之前卷积层都训练 特点:跟状态二的差异很小,当然状态三比较耗时和需要训练GPU资源,不过非常适合fine-tuning到自己想要的模型里面,预测精度相比状态二也提高不少。
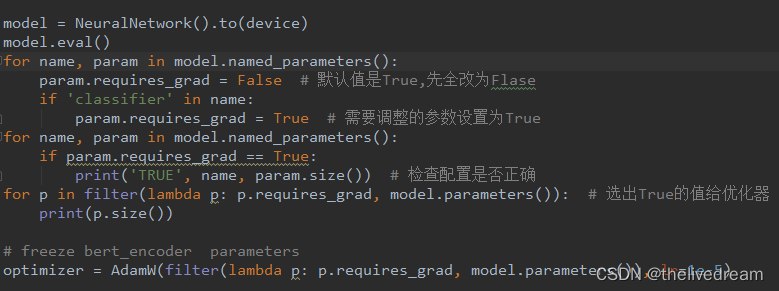
如何冻结参数?
Word2vec
的是
词嵌入/词向量
WordEmbeding
的主流的实现算法
之一,他是基于预测的词嵌入方法,是
一个三层的神经网络,
训练时采用CBOW和Skip-gram两种训练模式。
隐藏层的参数矩阵就是我们要的词向量,他是训练模型的附属产物。
英语
论文:
word2vec.pdf
主要区别与优势:
优点:由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
优点:比之前的 Embedding方 法维度更少,所以速度更快
优点:通用性很强,可以用在各种 NLP 任务中
缺点:由于词和向量是一对一的关系,所以一词多义的问题无法解决。
缺点:Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
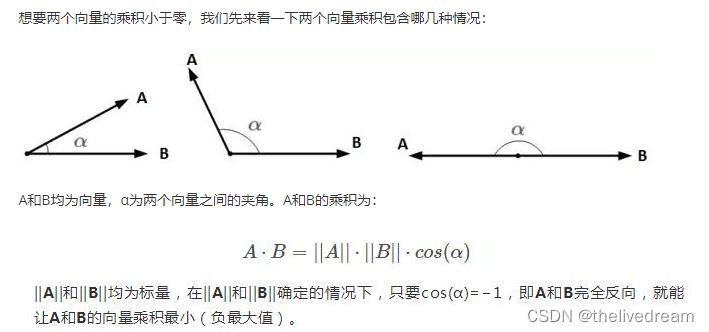
向量乘积
一、基于神经网络的语言模型根据学习方法不同大体可以分为两大类,分别是Feature-based和Fine-tune。
共同点:都是基于已训练好的语言模型LM,完成特定的任务task_specific_model(分类,序列标注等)
Feature-based
: LM的参数不变化,通过语言模型LM得到词语的embedding,换句话说就是通过神经网络得到更恰当的向量来表示词库中的每一个词语,Feature-based 方法不使用模型本身,而是使用模型训练得到的参数作为词语的 embedding;feature-base 方法最典型的例子就是
ELMO和word2vec
Fine-tuning方法会根据下游特定的任务,在原来的模型上面进行一些修改,使得最后输出是当前任务需要的。这些修改一般是在模型的最后一层,或者在现有的网络后添加一个网络结构用于匹配下游的各种任务;GPT1 GPT2 就采用了Fine-tune 方法,GPT3得益于海量的与训练样本和庞大的网络参数,不在需要 fine-tune过程;BERT论文采用了LM + fine-tuning的方法,同时也讨论了BERT + task-specific model的方法。
三、PyTorch 中的大部分方法都继承自
torch.nn.Module,而 torch.nn.Module 的__call__(self)函数中会返回
forward()函数 的结果,因此PyTroch中的 forward()函数等于是被嵌套在了__call__(self)函数中;因此forward()函数可以直接通过类名被调用,而不用实例化对象。
四、
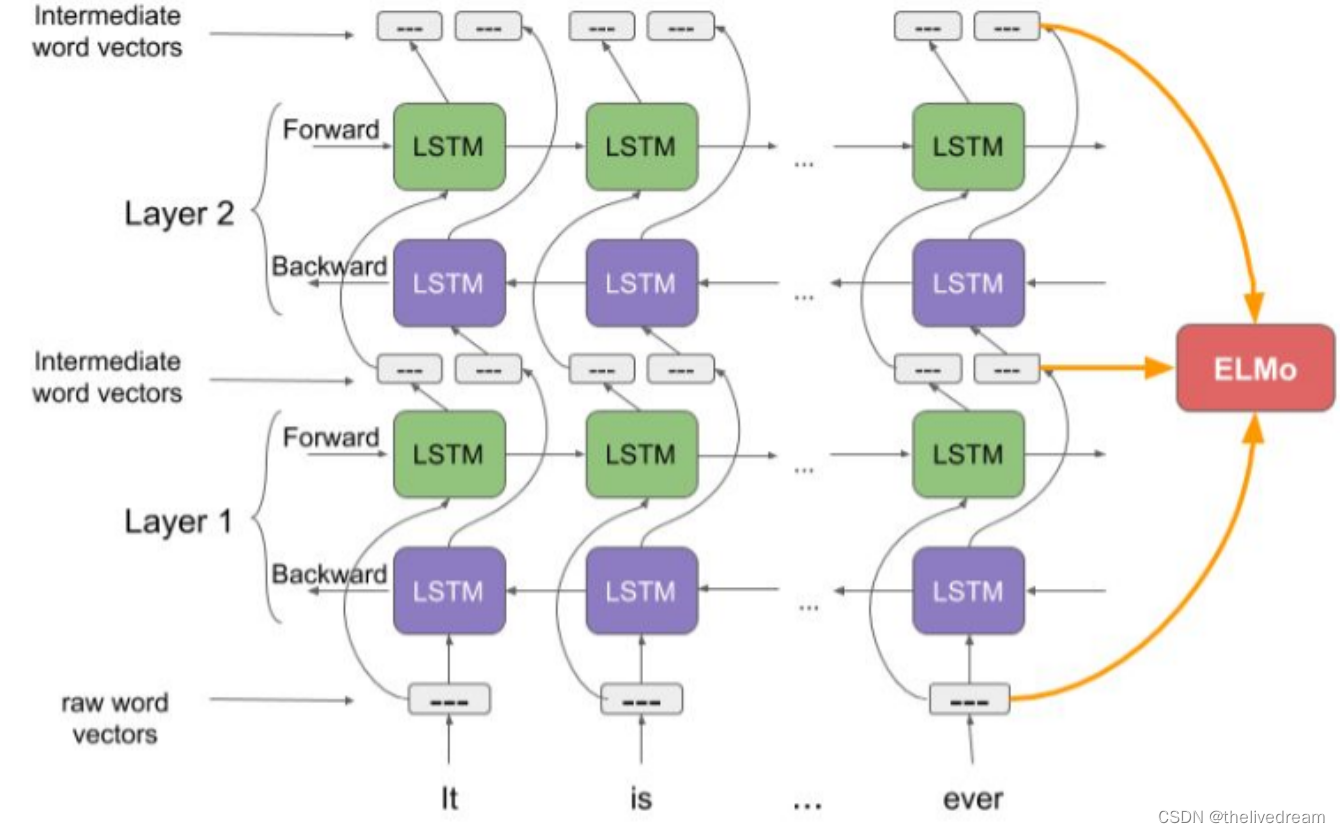
ELMo:
ELMo是一种在词向量(vector)或词嵌入(embedding)中表示词汇的新方法。
是基于deep- BLSTM的方法,
双向双层LSTM
(Embeddings from Language Models)
feature-based.其中的每一层都包含前向和后向两个LSTM层,
宅家NLP —— 词向量与ELMo
-
前向迭代中包含了该词以及该词之前的一些词汇或语境的信息
-
后向迭代中包含了该词之后的信息
-
这两种迭代的信息组成了中间词向量(intermediate word vector)
-
这些中间词向量被输入到模型的下一层
-
最终表示(ELMo)是原始词向量和两个中间词向量的加权和。
优点¶
考虑上下文,针对不同的上下文生成不同的词向量。表达不同的语法或语义信息。如“活动”一词,既可以是名词,也可以是动词,既可以做主语,也可以做谓语等。针对这种情况,ELMo能够根据不同的语法或语义信息生成不同的词向量。
6 个 NLP 任务中性能都有幅度不同的提升,最高的提升达到 25% 左右,而且这 6 个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。
缺点¶
使用LSTM提取特征,而LSTM提取特征的能力弱于Transformer;
使用向量拼接方式融合上下文特征,这种方式获取的上下文信息效果不如想象中好;
训练时间长,这也是RNN的本质导致的,和上面特征提取缺点差不多。
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。如果利用A 预测B的时候,需要将 [B, C, D] Mask 起来。
优点¶
特征抽取器使用了强大的 Transformer,能够捕捉到更长的记忆信息,且较传统的 RNN 更易于并行化;
方便的两阶段式模型,先预训练一个通用的模型,然后在各个子任务上进行微调,减少了传统方法需要针对各个任务定制设计模型的麻烦。
缺点¶
GPT 最大的问题就是传统的语言模型是单向的;我们根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子 The animal didn’t cross the street because it was too tired。我们在编码 it 的语义的时候需要同时利用前后的信息,因为在这个句子中,it 可能指代 animal 也可能指代 street。根据 tired,我们推断它指代的是 animal。但是如果把 tired 改成 wide,那么 it 就是指代 street 了。Transformer 的 Self-Attention 理论上是可以同时关注到这两个词的,但是根据前面的介绍,为了使用 Transformer 学习语言模型,必须用 Mask 来让它看不到未来的信息,所以它也不能解决这个问题。
GPT 与 ELMo的区别¶
模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 Transformer encoder
针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型。
这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。
这种机制叫做自回归(auto-regression),同时也是令 RNN 模型效果拔群的重要思想。
GPT-2 不会根据第二个单词重新解释第一个单词。
1.1 自回归语言模型
第一次听到
自回归语言模型(Autoregressive LM)
这个词。我们知道一般的语言模型都是从左到右计算某个词出现的概率,但是当我们做
完型填空
或者
阅读理解
这一类NLP任务的时候词的上下文信息都是需要考虑的,而这个时候只考虑了该词的上文信息而没有考虑到下文信息。所以,反向的语言模型出现了,就是从右到左计算某个词出现的概率,这一类语言模型称之为
自回归语言模型。
像坚持只用单向Transformer的GPT就是典型的自回归语言模型,也有像ELMo那种拼接两个上文和下文LSTM的变形
自回归语言模型。
1.2 自编码语言模型
自编码语言模型(Autoencoder LM)
这个名词毫无疑问也是第一次听到。区别于上一节所述,
自回归语言模型
是根据上文或者下文来预测后一个单词。那不妨换个思路,我把句子中随机一个单词用[mask]替换掉,是不是就能同时根据该单词的上下文来预测该单词。我们都知道Bert在预训练阶段使用[mask]标记对句子中15%的单词进行随机屏蔽,然后根据被mask单词的上下文来预测该单词,这就是
自编码语言模型
的典型应用。
1.3 两种模型的优缺点对比
自回归语言模型
没能自然的同时获取单词的上下文信息(ELMo把两个方向的LSTM做concat是一个很好的尝试,但是效果并不是太好),而
自编码语言模型
能很自然的把上下文信息融合到模型中(Bert中的每个Transformer都能看到整句话的所有单词,等价于双向语言模型),但
自编码语言模型
也有其缺点,就是在Fine-tune阶段,模型是看不到[mask]标记的,所以这就会带来一定的误差。XLNet将二者的上述优缺点做了一个完美的结合,在
自回归语言模型
中自然地引入上下文信息,并且解决
自编码语言模型
两阶段保持一致的问题。
在神经网络模型训练阶段开始前,通过Auto-encoder对模型进行预训练可确定编码器W的初始参数值。然而,受模型复杂度、训练集数据量以及数据噪音等问题的影响,通过Auto-encoder得到的初始模型往往存在过拟合的风险。
简单理解,在人类的感知过程中,某些模态的信息对结果的判断影响并不大。举个例子,一块圆形的饼干和一块方形的饼干,在认知中同属于饼干这一类,因此形状对我们判断是否是饼干没有太大作用,也就是噪声。如果不能将形状数据去除掉,可能会产生“圆饼干是饼干,方饼干就不是饼干”的问题(过拟合)。
当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为降噪自编码器(denoising autoencoder[DAE])。由Bengio在08年在文章《
Extracting and composing robust features with denoising autoencoders
》中提出。
降噪自编码器:一个模型,能够从有噪音的原始数据作为输入,而能够恢复出真正的原始数据。这样的模型,更具有鲁棒性。
七、PLM
八、联合训练
九、LAMB optimzer
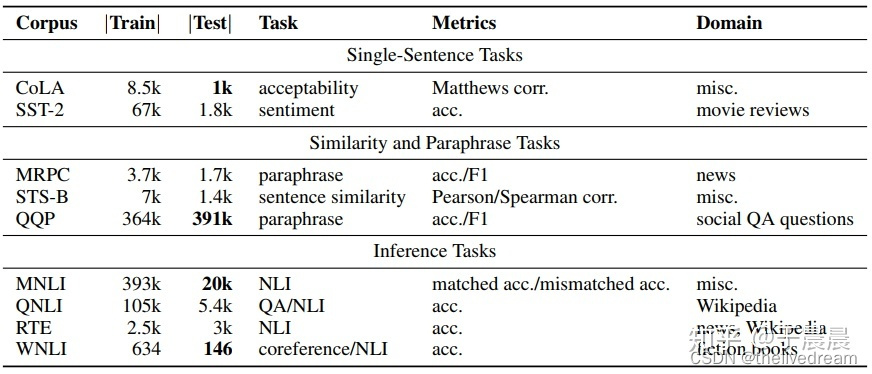
CoLA(The Corpus of Linguistic Acceptability,语言可接受性语料库),单句子分类任务,语料来自语言理论的书籍和期刊,每个句子被标注为是否合乎语法的单词序列。本任务是一个二分类任务,标签共两个,分别是0和1,其中0表示不合乎语法,1表示合乎语法。
SST-2(The Stanford Sentiment Treebank,斯坦福情感树库),单句子分类任务,包含电影评论中的句子和它们情感的人类注释。这项任务是给定句子的情感,类别分为两类正面情感(positive,样本标签对应为1)和负面情感(negative,样本标签对应为0),并且只用句子级别的标签。也就是,本任务也是一个二分类任务,针对句子级别,分为正面和负面情感。
QA数据集的经典之作——Stanford Question Answering Dataset(SQuAD)
该数据集来自中国12-18岁之间的初中和高中英语考试阅读理解,包含28,000个短文、接近100,000个问题。包含用于评估学生理解能力的多种多样的主题。该数据集中的问题中需要推理的比例比其他数据集更高,也就是说,精度更高、难度更大。
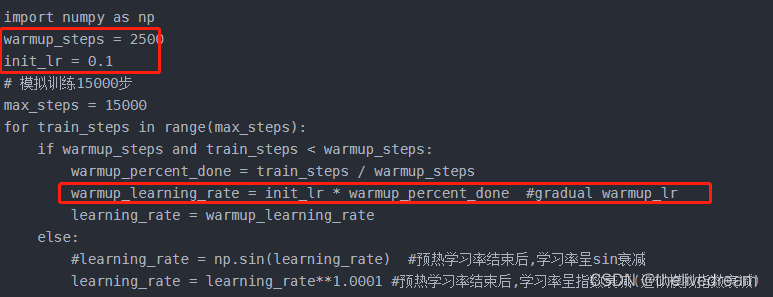
十一、使用Warmup预热学习率
模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡)
。
即先用最初的小学习率训练,然后每个step增大一点点,直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。
十二、
epoch/step/batch size

十三、
神经网络的layer介绍
Input(…): 用于实例化一个输入 Tensor,作为神经网络的输入。
average_pooling1d(…): 一维平均池化层
average_pooling2d(…): 二维平均池化层
average_pooling3d(…): 三维平均池化层
batch_normalization(…): 批量标准化层
conv1d(…): 一维卷积层
conv2d(…): 二维卷积层
conv2d_transpose(…): 二维反卷积层
conv3d(…): 三维卷积层
conv3d_transpose(…): 三维反卷积层
dense(…): 全连接层
dropout(…): Dropout层
flatten(…): Flatten层,即把一个 Tensor 展平
max_pooling1d(…): 一维最大池化层
max_pooling2d(…): 二维最大池化层
max_pooling3d(…): 三维最大池化层
separable_conv2d(…): 二维深度可分离卷积层
十四、
Gelu激活函数
(gaussian error linear units)就是我们常说的高斯误差线性单元,它是一种高性能的
神经网络
激活函数,因为gelu的非线性变化是一种符合预期的随机正则变换方式。
xP(X≤x)=xΦ(x)====>>> xσ(1.702x)
概率P ( X ≤ x ) P(X\leq x)P(X≤x)(x xx可看成当前神经元的激活值输入),即X XX的高斯正态分布ϕ ( X ) \phi(X)ϕ(X)的累积分布Φ ( x ) \Phi(x)Φ(x)是随着x xx的变化而变化的,当x xx增大,Φ ( x ) \Phi(x)Φ(x)增大,当x减小,Φ ( x ) \Phi(x)Φ(x)减小,即当x xx越小,在当前激活函数激活的情况下,越有可能激活结果为0,即此时神经元被dropout,而当x xx越大越有可能被保留。
十五、
EM(Exact Match)
是 问答系统 的一种常见的评价标准,它用来评价 预测中 匹配到正确答案(ground truth answers)的百分比。
是SQuAD的主要衡量指标。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/312276
推荐阅读

相关标签

