
- 1RK3568 OpenHarmony3.2 音频Audio之MIC调试_openharmony 麦克风
- 2LangChain - 01 - 快速开始_to install langchain-community run `pip install -u
- 3Python缺失值处理_python连续变量缺失值
- 4nn.MultiheadAttention详解 -- forward()中维度、计算方式_multi_head_attention_forward
- 5在pycharm中导入pytorch项目 | 10-10-2020_pycharm导入pytorch没有python.exe
- 6零基础HTML入门教程(21)——无序列表_web无序列表代码
- 7自然语言处理 - Language model和RNN_rnn language model
- 8深度学习-GRU_深度学习中的gru
- 9Android Jetpack:简化开发、提高Android App质量的利器
- 10个人记录jenkins编译ios过程 xcode是9.4.1_jenkins xcodebuild' requires xcode, but active dev
想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(一)_deepfacelab论坛
赞
踩
DeepFaceLab相关文章
一:《简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项》
二:《继续聊聊DeepFaceLab(DeepFake)不断演进的2.0版本》
三:《如何翻译DeepFaceLab(DeepFake)的交互式合成器》
四:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(一)》
五:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(二)》
六:《友情提示DeepFaceLab(DeepFake)目前与RTX3080和3090的兼容问题》
七:《高效使用DeepFaceLab(DeepFake)提高速度和质量的一些方法》
八:《支持DX12的DeepFaceLab(DeepFake)新版本除了CUDA也可以用A卡啦》
九:《简单尝试DeepFaceLab(DeepFake)的新AMP模型》
十:《非常规的DeepFaceLab(DeepFake)小花招和注意事项》
一 常规步骤
如果你已经会用DeepFaceLab,那么下面的常规步骤一定是很清楚的了。
- 准备目标视频:\DeepFaceLab_NVIDIA\workspace\data_dst.mp4
- 将目标视频解成每一帧的单独图像。
- 识别目标视频中的脸部。
- 准备源脸(可以从某个视频中提取,但最好是提前准备好)
- 训练
- 合成
- 合成结果从图片转为\DeepFaceLab_NVIDIA\workspace\result.mp4视频
下面我准备聊聊这些步骤中的一些注意事项和技巧。
二 注意事项与技巧
2.1 目标脸准备
2.1.1 挑选加工目标视频
首先目标视频不能太模糊。
当然也不能过于锐利。
像电影风格的画面或者噪点很多的视频,我们在得到目标视频前,最好对视频进行一下降噪处理。
如果面部太模糊识别可能出错,或者位置偏差。
如果面部噪点太多那么训练中容易把噪点当成面部特征。
PS:下面片段就进行了降噪处理。

2.1.2 目标视频帧解成图片
将目标视频解成图像,
这一步基本不会有什么问题:
3) extract images from video data_dst FULL FPS.bat
- 1
执行这个批处理命令后,\DeepFaceLab_NVIDIA\workspace\data_dst.mp4,
就会被解开每一帧成为若干图片,如果你机器好空间大可以选png格式,否则就选jpg吧。
解开的图片在:\DeepFaceLab_NVIDIA\workspace\data_dst\下,命名方式是00001.jpg到xxxxx.jpg。
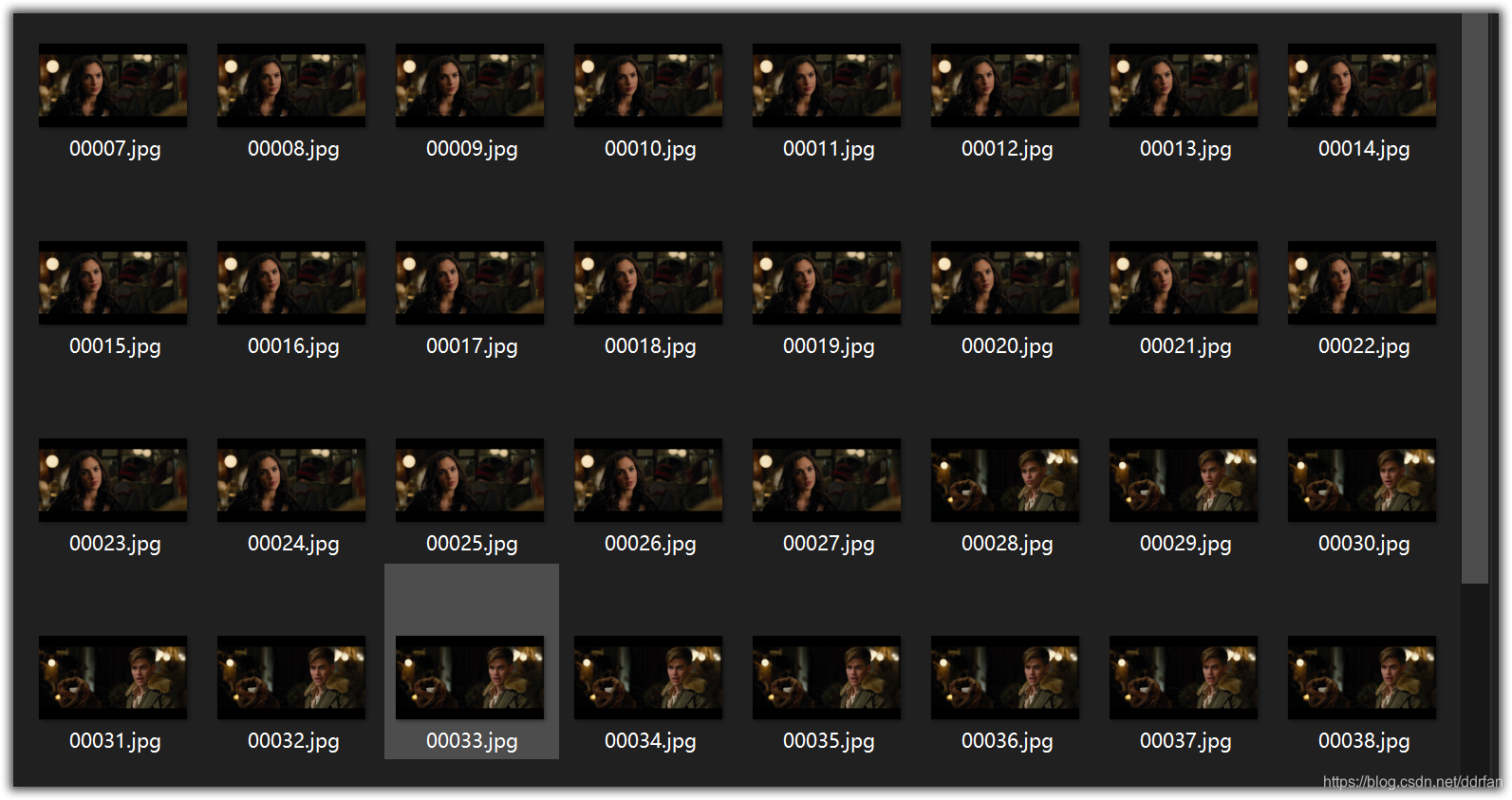
2.1.3 识别目标帧中的面部
虽然可以用这句全自动执行:
5) data_dst extract full_face S3FD.bat
- 1
但最好用下面这一句,在自动识别完成后,手动去修正未能识别到面部的帧。
如果你的目标视频面部非常清晰,没什么运动模糊的场景,也可能需要手动修正的帧为0。
5) data_dst extract full_face S3FD + manual fix.bat
- 1
2.1.4 去掉其他人的多余面部
有时一帧图像里有2个或多个人,我们需要去掉不需要替换的人脸。
有时也会识别错误,把不是人脸的东西识别成人脸,这也需要去掉。
我们可以检查解开后的脸部:
\DeepFaceLab_NVIDIA\workspace\data_dst\aligned\00001_0.jpg到xxxxx_x.jpg
如果出现了:xxxxx_1.jpg 甚至 xxxxx_2.jpg,说明这一帧里面有其他的脸。
我们大概浏览后,就可以直接删掉那些不用的脸。
最终我们确认,只剩一个人脸,没有别的奇怪的东西。
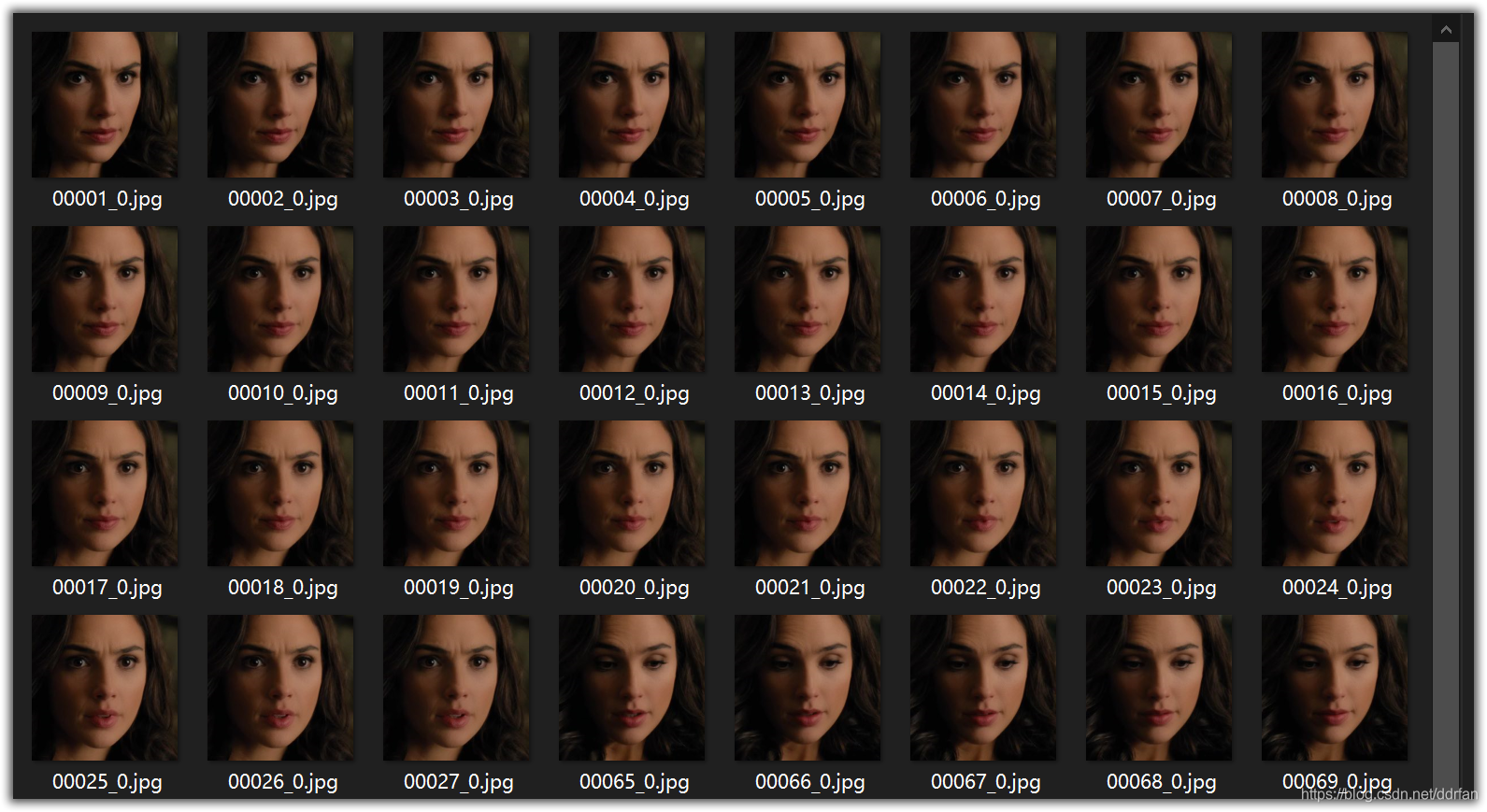
2.1.5 重新识别扭曲的面部
然后我们再检查解开脸部的debug目录:
\DeepFaceLab_NVIDIA\workspace\data_dst\aligned_debug\00001.jpg到xxxxx.jpg
如果可能的话,确认每一帧都是正确的。下面的图就是正确的例子:
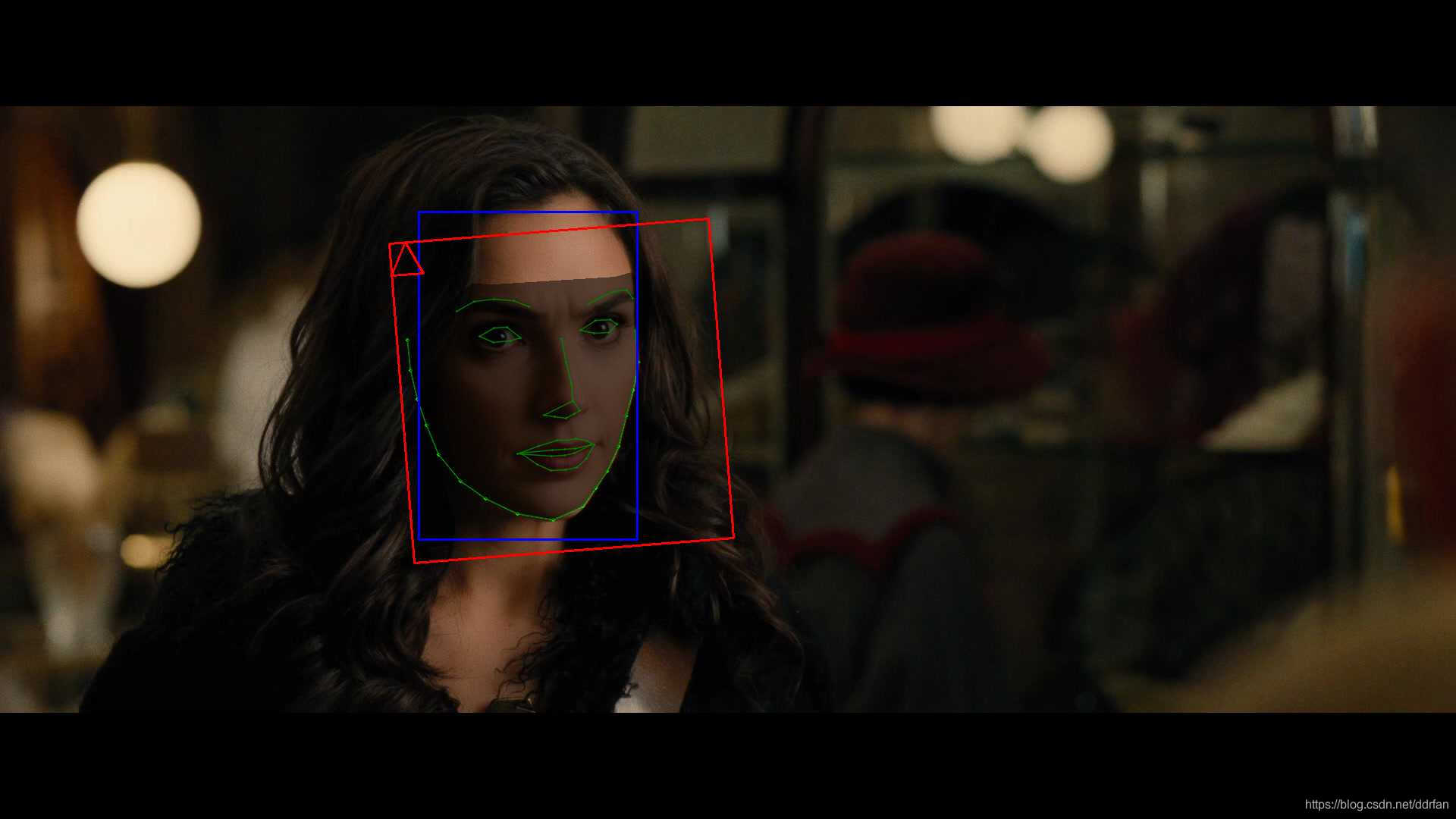
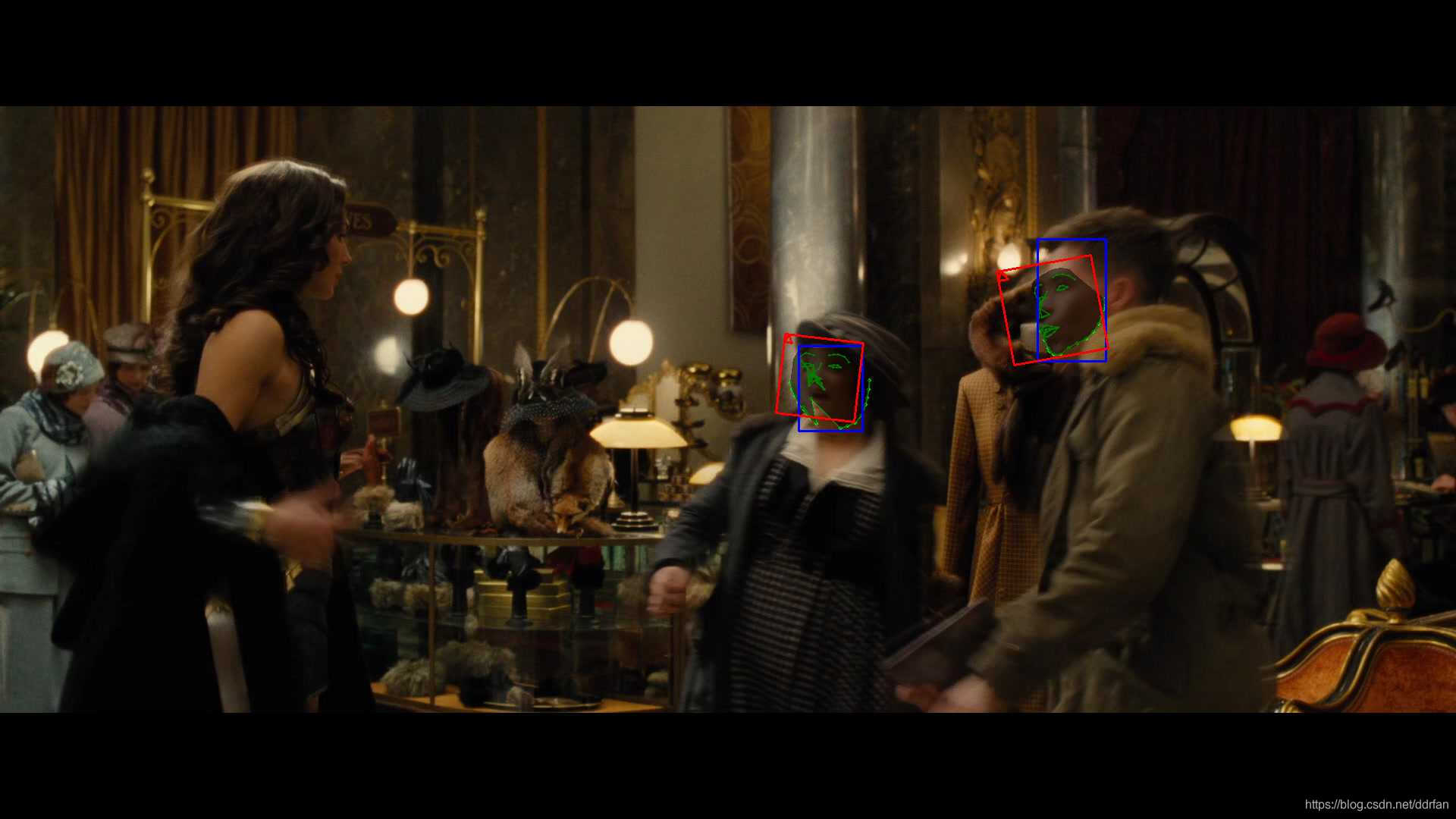
有时虽然需要的脸部位置大概正确,但是五官却有些扭曲。
这里没有适合的例子……
假设下图女生的脸部是我们需要的(只是举例,这里找不到神奇女侠识别扭曲的图片),那么这张图就扭曲了。
我们需要找到类似这种我们需要的脸,但是识别扭曲了的debug目录下的图片,删掉debug图片,执行下面的脚本:
5) data_dst extract full_face MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.bat
- 1
通过这个脚本,重新手动来识别一次删掉的图片,保证得到正确识别的脸部。
2.1.6 手工修正面部遮罩
执行脚本:
5.3) data_dst mask editor.bat
- 1
检查每一张脸部遮罩,注意范围,不要有遮挡物,不要包括了头发。
PS:之前对比度太高,后来稍微调节了一下目标视频,但是头发等部位的识别还是有偏差。
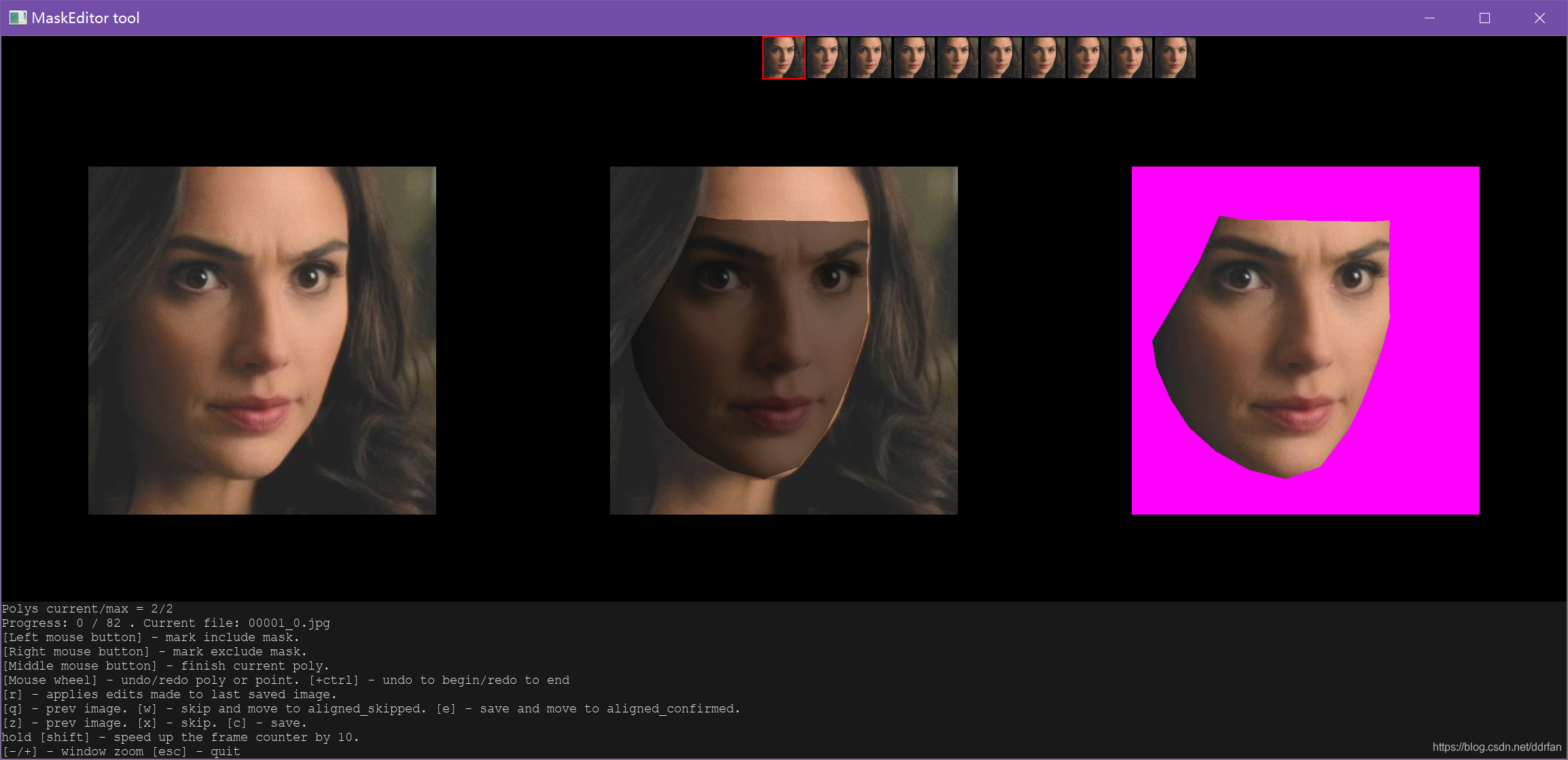
有时候真的需要一帧一帧的看。。。
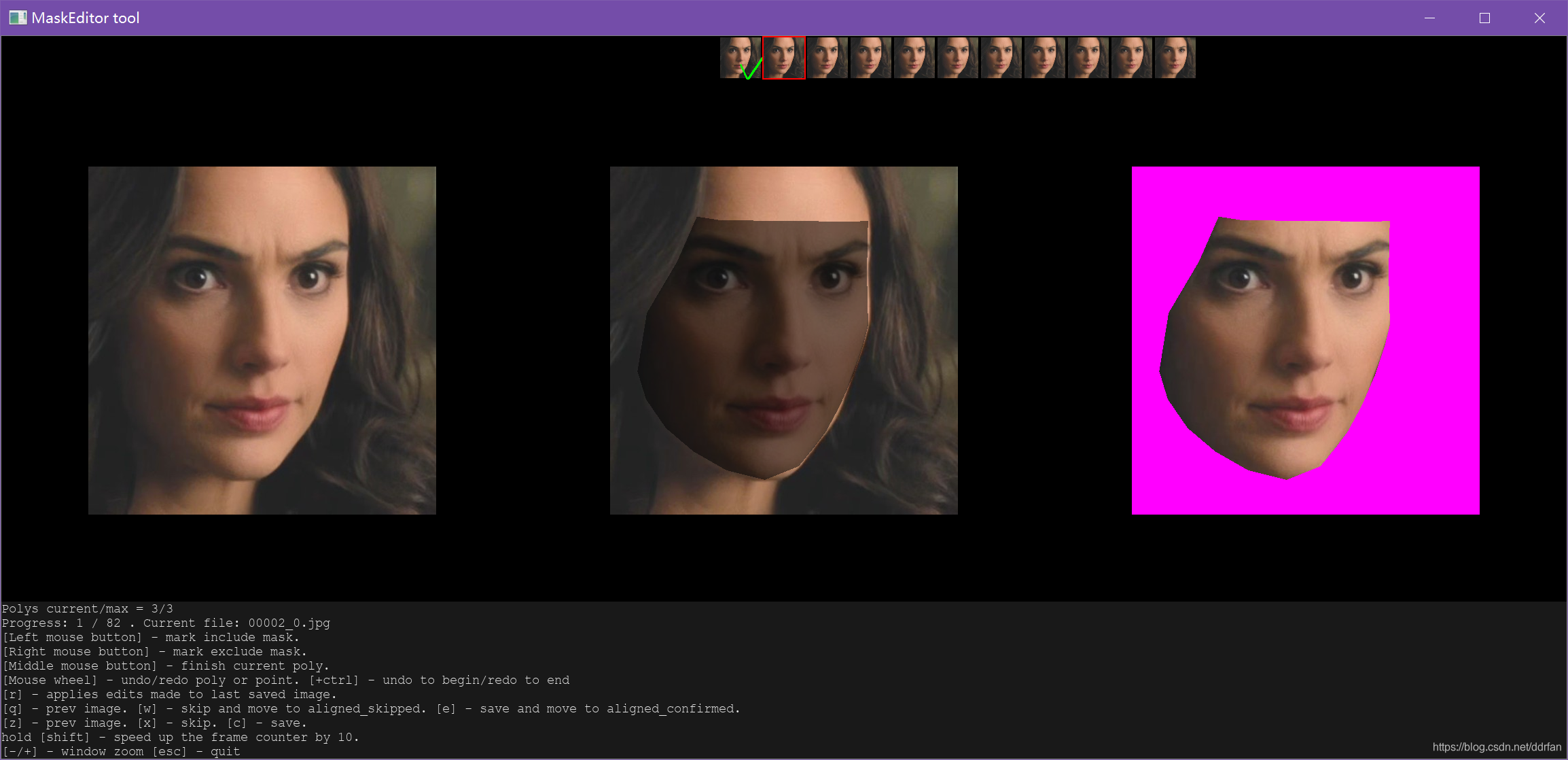
2.1.7 二次确认
每个步骤我们做完以后,都可以再进行一次。
检查一下我们修正的结果。
正确的脸是最重要的。
2.2 源脸准备
源脸可以和目标脸一样,从一段视频中取得。
但最好事先多费点时间,先准备好脸部集合,遵从下面的规则:
- 尽量不要刘海
- 脸部不要有其他遮挡物(比如手,话筒)
- 女生的话最好妆容统一(不同妆容的可以准备多套,一套内最好统一或者接近)
- 尽量有各种角度,各种光照方向。
- 足够清晰,不要模糊的。
准备了足够多的脸部后,我们可以执行:
4.2) data_src sort.bat
- 1
对源脸进行排序(左右方向,上下方向,模糊,相似),通过排序,我们去掉那些模糊的,遮挡的不适合的。
源脸和目标脸最大的区别是:源脸不合适直接删掉就OK了,而目标需要的脸每一帧都得识别正确。
2.3 训练
我们可以先用Quick96模型试试:
6) train Quick96.bat
- 1
因为Quick96不需要任何参数,而且作者有经过预训练,所以出成果的时间非常短。
第一次运行我们需要给模型起一个名字。
如下,可以看到偏离的数字下降真的是非常快:
Running trainer. [new] No saved models found. Enter a name of a new model : WW WW Model first run. Choose one or several GPU idxs (separated by comma). [CPU] : CPU [0] : GeForce GTX 1060 6GB [0] Which GPU indexes to choose? : 0 Initializing models: 100%|###############################################################| 5/5 [00:03<00:00, 1.40it/s] Loading samples: 100%|############################################################| 1041/1041 [00:01<00:00, 815.12it/s] Loading samples: 100%|################################################################| 82/82 [00:00<00:00, 285.19it/s] ... ... Starting. Press "Enter" to stop training and save model. Trying to do the first iteration. If an error occurs, reduce the model parameters. [16:18:28][#000002][0257ms][6.3158][6.6779] [16:33:23][#003987][0236ms][1.0592][0.4914] [16:48:23][#007997][0234ms][0.7373][0.2563] [17:03:23][#011972][0237ms][0.6592][0.2110] [17:18:23][#015925][0236ms][0.6155][0.1879] [17:33:23][#019846][0224ms][0.5847][0.1736] [17:48:23][#023784][0237ms][0.5622][0.1631] [18:03:23][#027712][0249ms][0.5421][0.1546] [18:08:19][#029013][0225ms][0.5331][0.1666]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
此例中可能也因为片段短吧,两小时不到就这个程度了:
PS:为了保护隐私,源脸我打马赛克了……
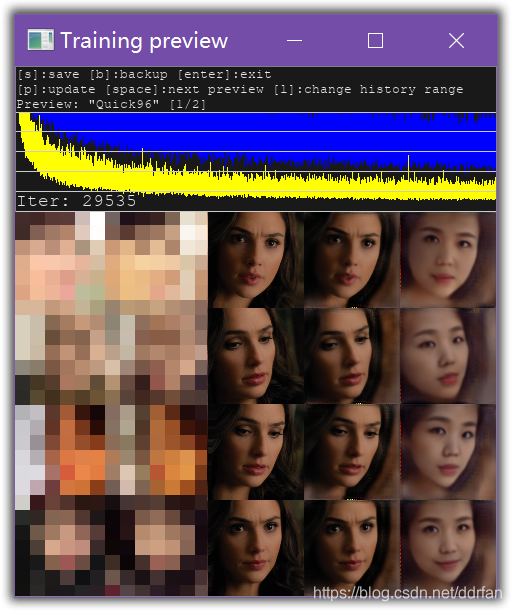
当然如果训练半天,发现偏离数值一直下不去,那么可能就得停下来检查一下了。
看看有没有下述的情况,否则是得不到理想的结果的。
- 源脸没有覆盖目标脸的方向?
- 目标噪点太多?
- 清晰度不够?
- 扭曲太大?
如果没有问题,那么Quick96训练个8-24小时,基本效果就出来了。
2.4 合成
既然例子里面选的是Quick96,那么就执行进行合成:
7) merge Quick96.bat
- 1
当然我们要用交互式合成器:
Running merger. [y] Use interactive merger? ( y/n ) : y Choose one of saved models, or enter a name to create a new model. [r] : rename [d] : delete [0] : WW - latest : 0 Loading WW_Quick96 model... Choose one or several GPU idxs (separated by comma). [CPU] : CPU [0] : GeForce GTX 1060 6GB [0] Which GPU indexes to choose? : 0 Initializing models: 100%|###############################################################| 4/4 [00:00<00:00, 8.32it/s] ... ... Collecting alignments: 100%|##########################################################| 82/82 [00:00<00:00, 425.96it/s] Computing motion vectors: 100%|####################################################| 158/158 [00:00<00:00, 2597.34it/s] Running on CPU1. Running on CPU2. Running on CPU0. Running on CPU5. Running on CPU3. Running on CPU6. Running on CPU4. Running on CPU7. Running on CPU8. Running on CPU9. Running on CPU10. Running on CPU11. Running on CPU12. Running on CPU13. Running on CPU14. Running on CPU15. Merging: 0%| | 0/158 [00:00<?, ?it/s] MergerConfig 00001.jpg: Mode: overlay mask_mode: learned erode_mask_modifier: 0 blur_mask_modifier: 0 motion_blur_power: 0 output_face_scale: 0 color_transfer_mode: rct sharpen_mode : None blursharpen_amount : 0 super_resolution_power: 0 image_denoise_power: 0 bicubic_degrade_power: 0 color_degrade_power: 0 ================
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
如果你需要中文,请看上一篇,关于合成器的翻译(我更喜欢英文原版):
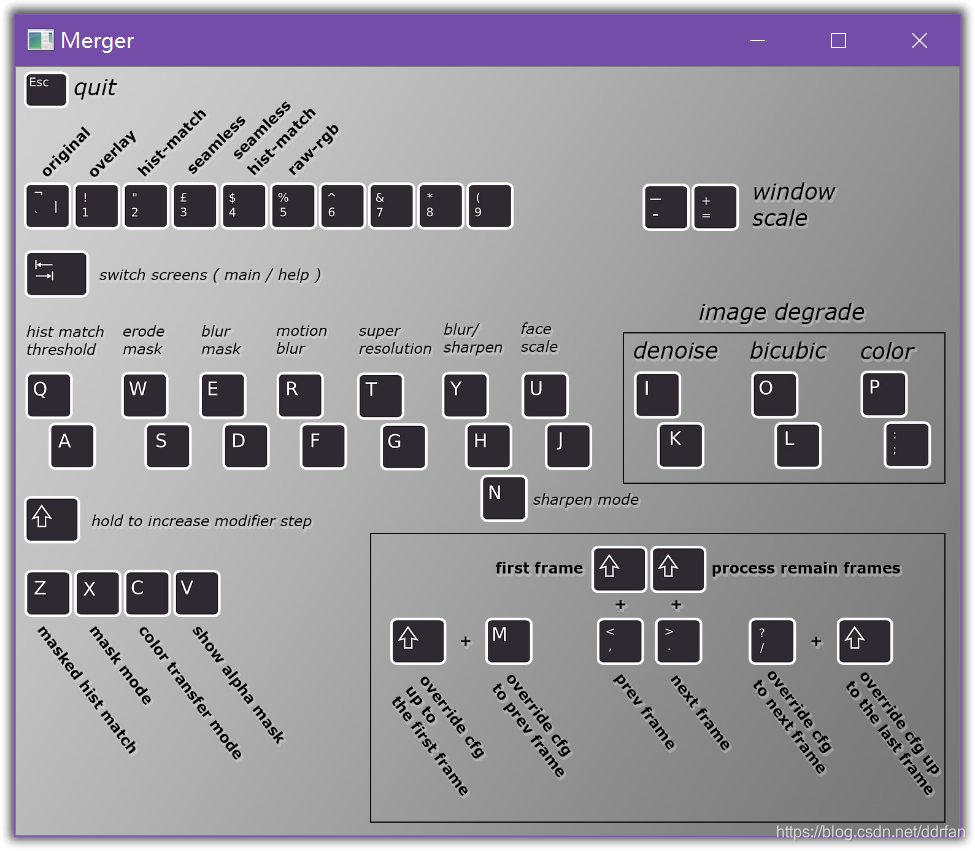
按Tab从帮助界面切换到主界面(预览界面)。
什么参数都没调整,是下面这个不忍直视的样子……
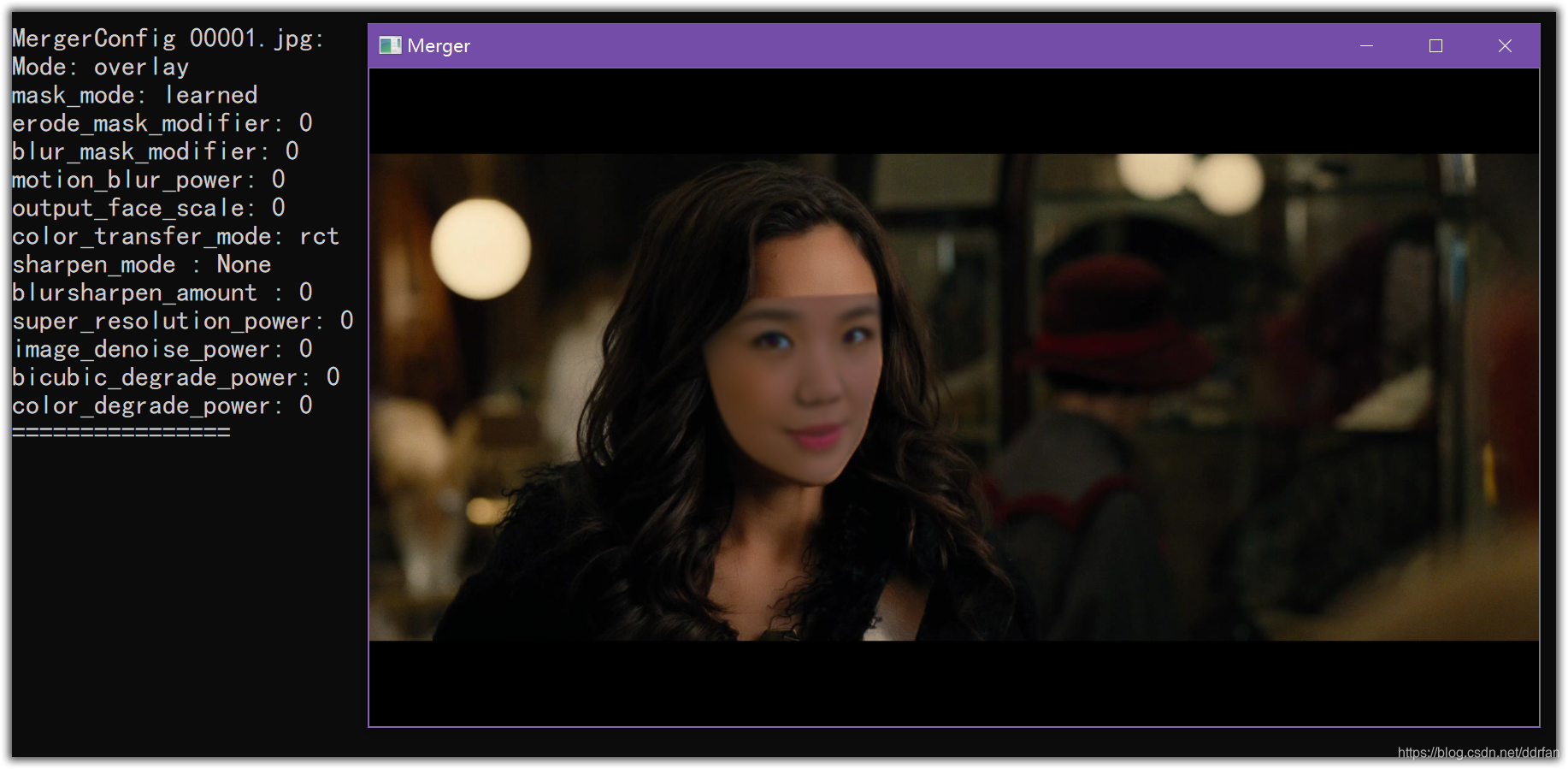
调整了下如下图:
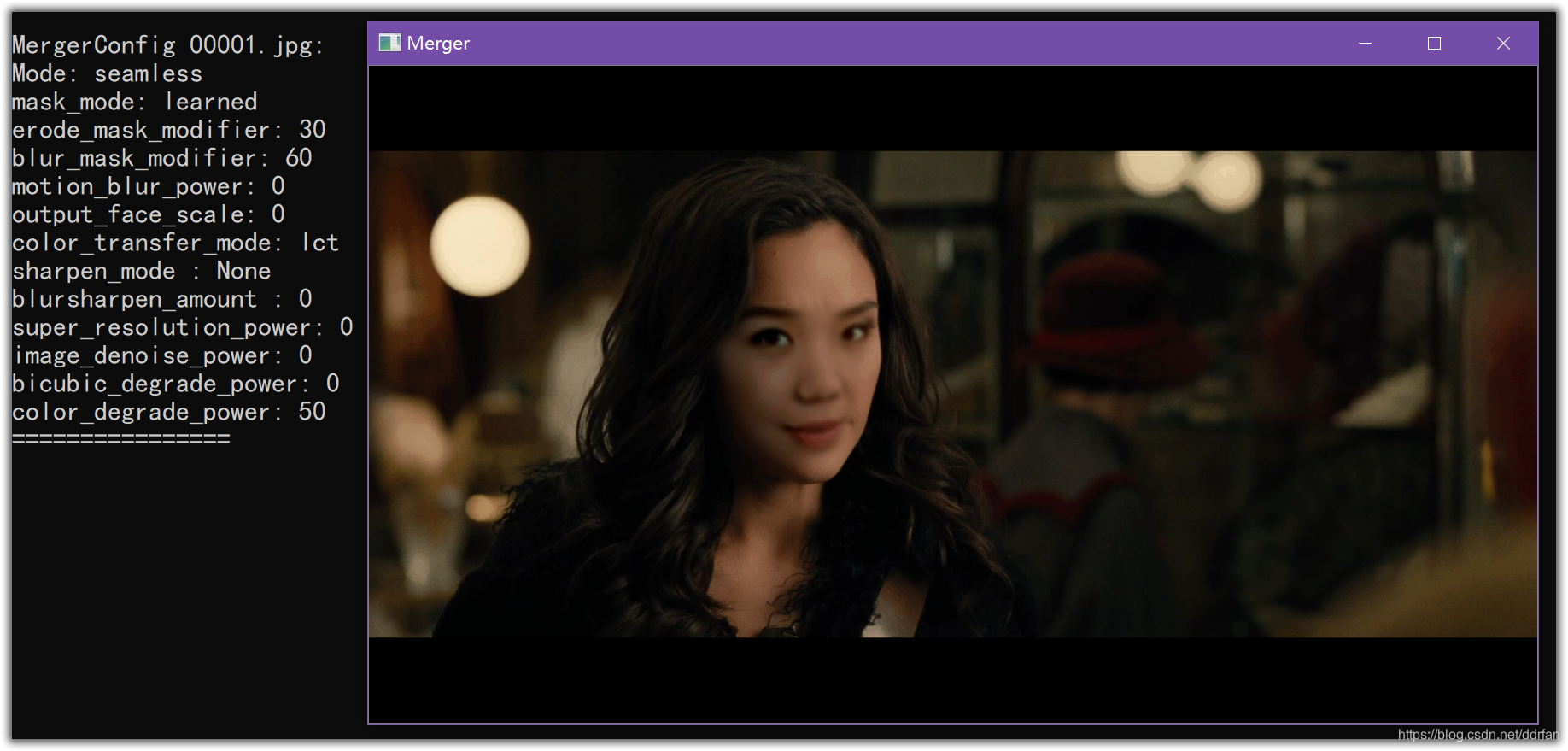
按Shift+?/把这一帧的配置,覆盖后面全部帧。
再按Shift+>处理后续全部的帧。
这里只是个例子,我们需要:
- 多训练降低偏离度
- 可以通过反复调整参数来得到最好的效果
- 如果需要的话,每一帧的参数都可以不一样(微调)
2.5 合成到视频
执行脚本将合成后的帧,最终合成视频(包括音频):
8) merged to mp4.bat
- 1
如果你需要进一步处理视频。
那么请选个比较大的比特率来保存视频(160Mbps?)。
PS:此例训练时间太短,效果不好。
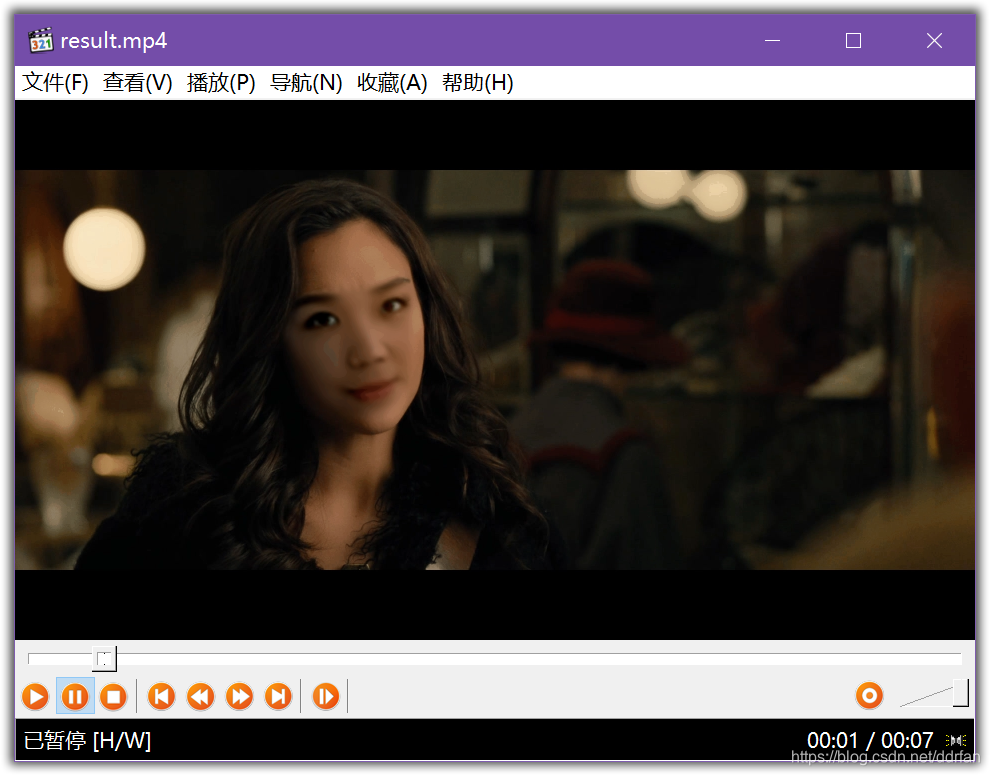
2.6 蛤?重来一次
我们可以等Quick96训练一天再看结果。
但是如果我们通过Quick96已经确认脸部和训练都没有什么问题,而96的分辨率无法满足视频的清晰度,那么也可以停下来,用SAEHD来进行训练。
6) train SAEHD.bat
- 1
SAEHD模型有丰富的参数调整,可以取得更好的效果。
但是速度相对比较慢,而且需要自己理解各种参数。
如果你显卡很好比如1080TI级别的,那么不用考虑,提高分辨率吧。
…
三 教程也会失败
- 第一次尝试失败,对比度过高。
- 第二次尝试失败,遮罩修改过多。
- ……

