
- 1【程序人生】马斯克:我一直有种存在的危机感_马斯克设计好的程序人生
- 2《MidJourney零基础教学:在线提示词查询字典》:为你的创作之路增添更多的惊喜和乐趣_midjourney零基础教学:在线提示词查询字典
- 3paddleNLP 安装_paddlenlp安装
- 4【AdaSeq基础】30+NER数据汇总,涉及多行业、多模态命名实体识别数据集收集_命名实体识别数据集多大
- 5基于自然语言处理技术的智能客服系统开发及实现_基于自然语言处理的智能客服系统
- 6NLP09-Gensim源码简析[TfidfModel]_gensim tfidfmodel
- 7AAAI-2024-计算机视觉(CV)CCF-A类顶会,已接受论文合集
- 8SD-WAN如何解决更有性价比地跨境网络问题
- 9Ubuntu20.04安装Nvidia显卡驱动、CUDA11.5、cuDNN8.3、Anaconda及Tensorflow-GPU版本详细图文操作教程_ubuntu20.04下载anaconda,cuda11.5
- 10视觉3D感知(三):双目深度估计
Deepfacelab 新手教程(转载)_deepfacelab新手教程
赞
踩
1. 四款换脸软件介绍
FakeAPP Faceswap Openfaceswap Deepfacelab
1.1 四款软件的简介
| 名称 | FakeAPP | Faceswap | Openfaceswap | Deepfacelab (集成环境版) |
|---|---|---|---|---|
| 简介 | 可能是国内网络传播最广的换脸软件 GUI最为亲切但是2.2版本很差 | 开源软件 后期版本有GUI 源码玩家可以修改测试 | Faceswap的GUI套壳版 目前停更且作者网站跳转到Deepfacelab | 目前最好玩的换脸软件 但没有GUI |
| 需要部署的环境 | Visual Studio Python CUDA+CUDNN FakeApp内核 | Visual Studio Python CUDA+CUDNN | CUDA+CUDNN | 无要求 |
| 743285272 QQ群内使用人数 | ★★★ | ★★ | ★★ | ★★★★★ |
1.2 四款软件作者页面链接
FakeAPP 作者网站不好找,最新版还不一定好,主流版本还是1.1和2.2,链接为Baidu搜索
Faceswap GitHub上经常更新,新版不兼容旧版MODEL,使用时候请注意
Openfaceswap 作者的论坛已消失,点进去就自动跳转到Deepfacelab的GitHub页面
Deepfacelab GitHub上有介绍,介绍文末处有论坛链接可以下载集成环境版
2 Deepfacelab 新手教程
(在开始前建议使用Chrome浏览器,因为访问流畅,并且自带谷歌翻译,不管是去下载东西还是去学习教程,翻译都是有很大帮助的)
2.1 下载Deepfacelab软件包
- https://github.com/iperov/DeepFaceLab 拉到文末,有一个俄文论坛链接,或者直接点击进入这个俄文的论坛链接:https://rutracker.org/forum/viewtopic.php?p=75318742 文章最上面介绍内容的偏下面的部分,有个磁力链接,下载这个磁链的种子可能会很难,我们群里也会不定期更新新版的种子文件。(本人比特彗星长期挂机上传BT长效种子)。
- 下载时候有两个包,一个是CPU版,一个是正常版,一般情况用NVIDIA显卡玩不需要下载CPU版本,如果你的显卡不能玩或者你想试试看,那你就下CPU版吧。一般情况下,一台台式机游戏级别配置的CPU的速度是GPU的1/10左右,这大概是个平均值,超过1/10不要回来喷我,除非你能弄出比同价位显卡更快的数据。
- 解压开你会发现Deepfacelab文件夹内有两个文件夹,和一堆bat批处理指令,下面请看我的介绍:

上图这张图是大概2018年6月的版本的列表,新版和旧版总体bat的功能不会差太多(2019/1/3作者更新了1个新算法,目前群内大神测试没太大用)。
另外你如果玩熟练了你可以自己弄一些拿到前面来,这样会很方便:

我自己挑出来的这些像排序部分,有些是要自己修改bat内容的。
记住,bat 批处理文件是可以修改的,文件夹里的只是送你的案例而已
2.2 让我们开始换脸操作
所有软件对应的两边素材:
A即DST 就是原版的视频素材,就是身体和背景不换,要换掉脸的视频
B即SRC 就是要使用到的脸的素材
把两边素材称为A和B的软件,一般都可以互换方向,但是总体操作都是B脸放A上,SRC脸放DST上
DST和SRC素材都可以是图片或者视频
换脸软件的操作是通过SRC脸图集,运算出MDOEL,然后放到DST序列图上,最后把DST序列图连接为视频



新手操作流程:
- 【手动】把DST视频放到“workspace”文件夹下,并且命名为“data_dst”(后缀名和格式一般不用管)
下面步骤的文件目录均在workspace下,如“workspace\data_src”,我将省略为“data_src” - 【手动】把SRC素材(明星照片,一般需要700~1500张)放到“data_src”下。
- 【bat】分解DST视频为图片(需要全帧提取,即Full FPS),bat序号3.2 你会看到“data_dst”下有分解出来的图片。
- 【bat】识别DST素材的脸部图片,bat序号5 有DLIB和MT两种分解方式,一般情况建议DLIB,具体差别什么自己摸索,后面不要带Manual和Debug,这俩一个是手动一个是调试。
- 【bat】识别SRC素材的脸部图片,bat序号4 具体操作同步骤4。
- 【手动】第4步和第5步识别并对齐的人脸素材在“data_dst\aligned”和“data_src\aligned”内,你需要把这些人脸不正确识别的内容删除,否则影响MODEL训练结果,如果脸图特别小,或者翻转了,那么基本判定为识别错误,但是要说明的是,DST脸超出画面的半张脸需要留着不要删除,SRC脸超出画面基本没用,直接删除吧。
删除SRC错误脸图前可以使用bat序号4.2系列的排序,直方图排序和人脸朝向排序可以较为方便地找出错误人脸,这属于进阶内容,具体不给教程,有需要自己Baidu翻译一下。 - 【bat】现在你已经有DST的序列帧(图片)素材和SRC的脸部(图片)素材了,你需要运行MODEL训练,bat序号6 一样也是有好多种MODEL,目前建议新手直接跑H128的MODEL(除非你的显卡比较差,那就跑H64)其他MDOEL算法请看GitHub上的介绍。
跑MODEL是可以中断的,在预览界面按回车键,软件会自动保存当前进度,MDOEL文件在“model”文件夹下,不同的MODEL文件名不一样,建议定期备份MODEL,并建议SRC专人专用MODEL - 【bat】上面MODEL如果是第一次跑,可能需要10+小时才有合理的效果,结束训练后请运行MODEL导出合成图,bat序号7 这里就根据你的MODEL类型来运行就好了
※ 这里会出现一个问题就是软件会在DOS界面给你好多好多选项,请看下文“导出合成图的选项”。 - 【bat】导出图片后需要把图片转成视频,那么就运行 bat序号8 就行了,根据你要的最终格式来定。
2.3 导出合成图的选项
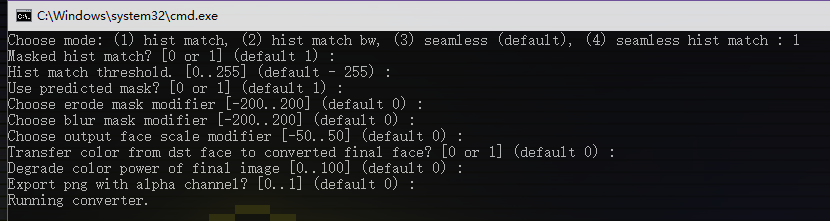
所有选项直接按回车即使用标注的默认选项(default)
第一个问答是问你要哪个合成模式,可以理解为:
1、普通
2、普通+直方图匹配
3、无缝(默认)
4、无缝+直方图匹配
可能每个视频需要的效果都不一样,一般情况我个人建议用:1普通
第一个问答结束后后面有一堆问题,具体作者给了说明:
※ 这里的图挂了,因为我原来是拉取Lab的GitHub上面的图片。最近Lab作者更新了GitHub上面的页面,这张图我找不到了,而更多的是官方给的视频教程(YouTube)
目前本文缺少这些参数的介绍(或许最近的新版已经取消掉了这些手动参数吧)
GitHub链接:https://github.com/iperov/DeepFaceLab
3 请注意保留源素材
不论哪款软件,流程结束后建议复制并分类保留:
SRC素材(脸图或原图)
MODEL(丢了就浪费10小时了)
4 FAQ
4.1 人脸素材需要多少?
DST:尽量不要少,因为它是有限的且需要被替换的素材
SRC:根据各软件的脸图筛选规则和网上大神的建议,总体来说,SRC脸图最好是大概700~3999的数量,像Deepfacelab的作者,他就认为1500张够了。对于SRC,各种角度、各种表情、各种光照下的内容越多越好,很接近的素材没有用,会增加训练负担。
4.2 手动对齐识别人脸模式如何使用?

回车键:应用当前选择区域并跳转到下一个未识别到人脸的帧
空格键:跳转到下一个未识别到人脸的帧
鼠标滚轮:识别区域框,上滚放大下滚缩小
逗号和句号(要把输入法切换到英文):上一帧下一帧
Q:跳过该模式
老实说,这个功能极其难用,画面还放得死大……4.3 MODEL是个什么东西?
MODEL是根据各种线条或其他奇怪的数据经过人工智能呈现的随机产生的假数据,就像PS填充里的“智能识别”
你可以从 https://affinelayer.com/pixsrv/ 这个网站里体验一下什么叫MODEL造假
4.4 MODEL使用哪种算法好?
各有千秋,一般Deepfacelab使用H128就好了,其他算法可以看官方在GitHub上写的介绍:https://github.com/iperov/DeepFaceLab
4.5 Batch Size是什么?要设置多大?
Batch Size的意思大概就是一批训练多少个图片素材,一般设置为2的倍数。数字越大越需要更多显存,但是由于处理内容更多,迭代频率会降低。一般情况在Deepfacelab中,不需要手动设置,它会默认设置显卡适配的最大值。
根据网上的内容和本人实际测试,在我们这种64和128尺寸换脸的操作中,越大越好,因为最合理的值目前远超所有民用显卡可承受的范围。
新手建议自动或从大的数值减少直到能够正常运行(比如128→64→32→16…),具体操作方法是在MODEL训练的BAT中添加一行:
- @echo off
- call _internal\setenv.bat
-
- %PYTHON_EXECUTABLE% %OPENDEEPFACESWAP_ROOT%\main.py train ^
- --training-data-src-dir %WORKSPACE%\data_src\aligned ^
- --training-data-dst-dir %WORKSPACE%\data_dst\aligned ^
- --model-dir %WORKSPACE%\model ^
- --model H128
-
- pause
上面是原版,需要加一行“–batch-size ?”并不要忘记上一行的“^”,如下:
- @echo off
- call _internal\setenv.bat
-
- %PYTHON_EXECUTABLE% %OPENDEEPFACESWAP_ROOT%\main.py train ^
- --training-data-src-dir %WORKSPACE%\data_src\aligned ^
- --training-data-dst-dir %WORKSPACE%\data_dst\aligned ^
- --model-dir %WORKSPACE%\model ^
- --model H128 ^
- --batch-size 4
-
- pause
4.6 MODEL训练过,还可以再次换素材使用吗?
换DST素材:
可以!而且非常建议重复使用。
新建的MODEL大概10小时以上会有较好的结果,之后换其他DST素材,仅需0.5~3小时就会有很好的结果了,前提是SRC素材不能换人。
换SRC素材,那么就需要考虑一下了:
第一种方案:MODEL重复用,不管换DST还是换SRC,就是所有人脸的内容都会被放进MODEL进行训练,结果是训练很快,但是越杂乱的训练后越觉得导出不太像SRC的脸。
第二种方案:新建MODEL重新来(也就是专人专MODEL)这种操作请先把MODEL剪切出去并文件夹分类,这种操作可以合成比较像SRC的情况,但是每次要重新10小时会很累。
第三种方案:结合前两种,先把MODEL练出轮廓后,再复制出来,每个MODEL每个SRC脸专用就好了。
4.7 合成图连接成视频后发现部分画面面部颤抖怎么办?
本人想到的方法是:把DST视频通过其他软件放大些尺寸再重新进行操作。因为逻辑上分析,扩大了画面后,软件识别偏移的步长比例会小一些。
我有其它问题我该如何向你提问?
这位大哥有关于其他的问题回复:
https://www.cnblogs.com/wangpg/tag/DeepFaceLab/

