
- 1从零开始创建Hi3516DV300在EMMC上的根文件系统_海思hi3516dv300 文件系统打包流程
- 21394b基础学习笔记
- 3Linux查看当前目录并输出到文件
- 4Sora 究竟有多烧钱?Sora的推理与训练的计算成本被扒出来了
- 5LPA算法原理_lpa线性检测原理
- 6干货 | 循环神经网络(RNN)和LSTM初学者指南
- 7python波形识别_python,地震波形、时频图、频谱图计算和显示软件
- 8在U-Net中加入注意力机制时出现维度不匹配的问题_为什么加注意力机制总是通道不匹配
- 9Liunx 离线安装 JDK1.8 (超级详细版)_linux 离线安装jdk1.8
- 10必须收藏!可能是最完整的全球AI大模型名单_全球有多少大模型公司
Learning Disentangled Representations of Negation and Uncertainty_private-shared disentangled multimodal vae for lea
赞
踩
学习否定和不确定性的分解表示法
Jake Vasilakes 1 , Chrysoula Zerva 2,3 , Makoto Miwa 4,5 , Sophia Ananiadou 1,5 1 National Centre for Text Mining, Department of Computer Science, The University of Manchester 2 Instituto Superior Técnico, 3 Instituto de Telecomunicações 4 Toyota Technological Institute 5 Artificial Intelligence Research Center, National Institute of Advanced Industrial Science and Technology {jake.vasilakes, sophia.ananiadou}@manchester.ac.uk , chrysoula.zerva@tecnico.ulisboa.pt makoto-miwa@toyota-ti.ac.jp
摘要
否定和不确定性建模是自然语言处理中长期存在的任务。
语言学理论认为,否定和不确定性的表达在语义上是相互独立的,它们所修饰的内容也是相互独立的。然而,以前关于表征学习的工作并没有明确地模型这种依赖关系。因此,我们尝试使用变分自动编码器1来分离否定、不确定性和内容的表示。
我们发现,简单地监督潜在表征可以获得良好的分解,但基于对抗学习和互信息最小化的辅助目标可以提供额外的分解收益。
1引言
非正式语义、否定和不确定性是其语义功能独立于所修改的命题内容的操作符(Cann,1993a,b)2。也就是说,只改变其中一个方面,而其他方面保持不变,就可以形成流畅的陈述。因此,否定、不确定性和内容可以被视为知识和信念陈述的分解生成因素(见图1)。
变异因素的分解表征学习(DRL)可以提高表征的稳健性及其在任务中的适用性(Bengio et al.,2013)。具体而言,否定和不确定性对于下游NLP任务非常重要,如情绪分析(Benamara et al.,2012;Wiegand et al.,2010)、问答(Yatskar,2019;Yang et al.,2016)和信息提取(Stenetorp et al.,2012)。因此,将否定和不确定性分离可以为这些任务提供可靠的表示,将它们与内容分离可以帮助完成依赖于核心内容保存的任务,如受控生成(Logeswaran et al.,2018)和抽象总结(Maynez et al.,2020)。
然而,正如语言学理论所表明的那样,之前的工作还没有测试是否可以分解否定、不确定性和内容,尽管之前的工作有分解的属性,如语法、语义和风格(Balasubramanian et al.,2021;John et al.,2019;Cheng et al.,2020b;Bao et al.,2019;Hu et al.,2017;Colombo et al.,2021)。为了填补这一空白,我们的目标是回答以下研究问题:RQ1:是否有可能估计一个支持否定、不确定性和内容之间拟议的统计独立性的陈述模型?。
RQ2:已经为文本探索了许多现有的分解目标,所有这些都给出了有希望的结果。这些目标与在这项任务上实施“分解”相比如何?。

图1:显示不确定性、否定和内容之间区别的示例。“树有叶子”的内容由否定(粗体)和不确定性(下划线)因素修改。[行]
1.1贡献
在解决这些研究问题时,我们做出了以下贡献:1。生成模型:我们提出了一个语句的生成模型,其中否定、不确定性和内容是独立的潜在变量。继之前的工作之后,我们使用变分自动编码器(VAE)(Kingma and Welling,2014;Bowman et al.,2016)对该模型进行了评估,并通过一套评估指标对现有辅助目标进行了比较,以实施分解。
2、简单的潜在表示:我们注意到否定和不确定性有一个二元函数(正或负,确定或不确定)。
因此,我们试图学习这些变量对应的一维潜在表示,每个值之间有明确的分隔。
3、数据扩充:包含否定和不确定性注释的数据集相对较小(Farkas et al.,2010;Vincze et al.,2008;Jiménez Zafra et al.,2018),根据我们的初步实验,这导致句子重建较差。为了解决这一问题,我们使用一个简单的朴素贝叶斯分类器为大量amazon 3和Yelp 4评论生成弱标签,该分类器在一个较小的英语评论数据集上进行了训练的,该数据集对否定和不确定性进行了注记(Kon-stantinova et al.,2012),并使用它来估计我们的模型。详情见第4.1.1节。
我们注意到,与其他关于否定和不确定性建模的工作相比,这些工作侧重于否定和不确定性提示和范围检测的标记级任务,这项工作旨在学习目标因素的语句级表示,与之前关于文本DRL的工作相一致。
2背景
我们在这里提供了否定和不确定性处理的相关背景,NLP中的分解表征学习,以及讨论这项研究如何与以前的工作相适应。
2.1 NLP中的否定和不确定性
否定和不确定性有助于确定文本中陈述和事件的断言准确性(Saurí和Pustejovsky,2009;Thompson et al.,2017;Kilicoglu et al.,2017),这对于处理知识和信仰的NLP下游任务至关重要。例如,否定检测为情绪分析提供了强有力的线索(Barnes等人,2021;Ribeiro等人,2020),不确定性检测有助于虚假新闻检测(Choy和Chong,2018)。之前关于否定和不确定性处理的工作重点是线索识别和范围检测的分类任务(Farkas等人,2010),使用条件随机场(CRF)等序列模型(Jiménez-Zafra等人,2020;Li和Lu,2018),卷积和递归神经网络(CNN和RNN)(Qian等人,2016;Adel和Schütze,2017;Ren等人,2018),LSTM(Fancellu等人,2016;Lazib等人,2019),以及最近的transformer架构(Khandelwal和Sawant,2020;Lin等人,2020;Zhao和Bethard,2020)。
虽然这些工作主要侧重于学习句子中否定和不确定性的局部表示,但我们试图学习对语句否定和不确定性状态的高级信息进行编码的全局表示。
2.2分解表征学习
目前还没有一致同意的解纠缠定义。关于DRL的早期工作试图学习单个向量空间,其中每个维度独立于其他维度,并表示所建模对象的一个地面真值生成因子(Higgins et al.,2016)。Higgins et al.(2018)给出了一个群论定义,根据该定义,生成因子被映射到独立的向量空间。这个定义放松了先前的假设,即表示应该是一维的,并根据不变性的概念形式化了分离的概念。Shu et al.(2019)将不变性要求分解为一致性和限制性,描述了表示和生成因子之间不变性的具体理想属性。除了独立性和不变性之外,可解释性也是分解的一个重要标准。Hig-gins等人(2016年)指出,虽然PCA等方法能够学习独立的潜在代表性,但由于这些方法不能代表可解释的变异因素,因此无法分解。因此,我们希望我们所学的表述能够预测有意义的变化因素。我们采用伊斯特伍德和威廉姆斯(2018)的术语“信息性”来表示这一要求。
以前关于DRL for text的工作都使用某种形式的监督来加强潜在表征的信息性。Hu et al.(2017)、John et al.(2019)、Cheng et al.(2020b)和Bao et al。
(2019)所有作品都使用了生成因素的金标准标签,而其他作品则采用了相似性度量(Chen和Batmanghelich,2020;Balasub-ramanian等人,2021)。相比之下,我们的方法使用弱标签来表示否定和不确定性,这些否定和不确定性是使用在一小部分金标准数据上训练的的分类器生成的。
之前关于文本DRL的这些工作都使用了类似的架构:序列VAE(Kingma and Welling,2014;Bowman et al.,2016)将输入映射到L个不同的向量空间,每个向量空间都被限制为通过监督信号表示不同的目标生成因子。我们还将此总体架构用于模型估计,并将其用作基于对抗式学习(John et al.,2019;Bao et al.,2019)和互信息最小化(Cheng et al.,2020b)的现有分离目标试验的基础,如第3.4节所述。然而,与之前学习所有潜在因素的高维表示的工作不同,我们的目标是根据二元函数学习否定变量和不确定性变量的一维表示。
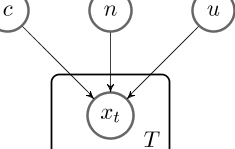
图2:生成模型图。c为内容,n为否定状态,u为不确定性。
3拟定方法
我们在第3.1节中描述了我们的整体模型。第3.2节列举了分解表示的三个具体要求,第3.3节和第3.4节描述了我们如何满足这些要求。
3.1生成模型
我们提出了一个生成性模型,根据该模型,否定、不确定性和内容是独立的潜在变量。图2给出了我们提出的模型的示意图。模型详情见附录A。
我们使用序列VAE来估计该模型(Kingma和Welling,2014;Bowman等人,2016)。
与标准自动编码器不同,VAE在潜在表示空间Z(通常为标准高斯)上施加先验分布,并用神经网络参数化后验qφ(Z | x)的学习近似值代替确定性编码器。除了尽可能减少输入和重建之间的损失,如在标准AE中,VAE使用额外的KL散度项来保持近似的后验分布接近先验分布。
在我们的实现中,三个线性层将BiLSTM编码器的最终隐藏状态映射到三组高斯分布参数(µ,σ),这些参数化了否定、不确定性和内容潜在分布∈ {n,u,c},分别。因为我们将每个输入映射到三个不同的潜在空间,所以我们在公式(1)中给出的证据下限(ELBO)训练目标中包括三个KL散度项
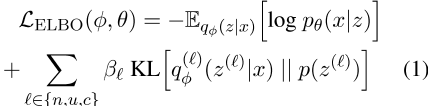
。
其中φ表示编码器的参数,θ表示解码器的参数,p(z())是标准高斯先验,β超参数加权每个潜在空间的KL散度项∈ L
使用重新参数化技巧(Kingma和Welling,2014),即
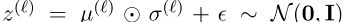
从这些参数定义的正态分布中对潜在表示z进行采样。
然后将潜在表示串联起来,并用于初始化LSTM解码器,该解码器旨在重建输入。图3给出了我们架构的可视化,附录E给出了实现细节。
我们使用一维否定和不确定性空间以及62维内容空间,总潜在大小为64。值得注意的是,我们不监督内容空间,不像以前的作品(John et al.,2019;Cheng et al.,2020b),这些作品通过预测输入的单词包来监督内容空间。这种监督技术会鼓励内容空间预测否定和不确定性线索,从而阻碍分离。因此,在我们的模型中,我们定义了三个潜在空间∈ {n,u,c}但仅使用来自2个目标生成因子k的信号∈ {n,u}。
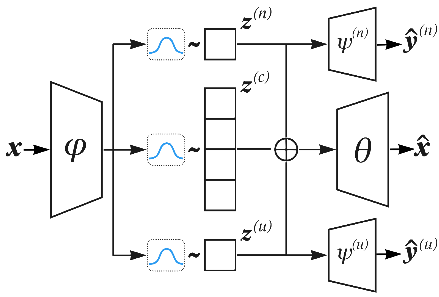
图3:与L ELBO+L INF目标相对应的拟议架构(见第3.4节)。由φ参数化的BiL-STM编码器将每个输入示例x映射到三个不同的分布,从中对潜在表示z()进行采样。然后将否定z(n)和不确定性z(u)潜在空间传递给线性分类器,由ψ()参数化,试图预测基本真值因子。最后,潜在值初始化由θ参数化的LSTM解码器,该解码器尝试重构输入。
3.2分解需求
我们的目标是满足先前作品提出的以下分解陈述的要求。
1、信息性:表述应能预测地面真相生成因素(Higgins et al.,2016;Eastwood and Williams,2018);2、独立性:每个相关生成因子的表示应位于独立向量空间中(Higgins et al.,2018);3、不变性:从数据到表示的映射应该对其他生成因素的变化保持不变(Higgins et al.,2018;Shu et al.,2019);以下部分详细介绍了我们的模型如何增强这些需求。
3.3信息性
继伊斯特伍德和威廉姆斯(2018)之后,我们通过预测相应生成因子的能力来衡量表征的信息性。与之前关于文本DRL的工作类似(John et al.,2019;Cheng et al.,2020b),我们在每个潜在空间上训练监督线性分类器5,并反向传播预测误差。因此,除了方程式(1)中的ELBO目标外,我们还为否定和不确定性定义了信息性目标
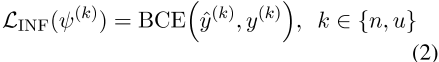
。
其中,y(k)是因子k的真标签,ŷ(k)是分类器的预测,ψ(k)是该分类器的参数,BCE是二元交叉熵损失。
3.4独立性和不变性
我们比较了执行这些要求的三个目标:1。信息性(INF):这是基于这样一个假设,即如果否定、不确定性和内容是独立的生成因素,那么第3.3节中描述的信息性目标将足以驱动独立性和不变性。Balasubramanian等人发现,这种方法在从内容中分离风格方面取得了很好的效果。
( 2021 ).
对抗性(ADV):潜在表征只能预测其目标生成因素。因此,受约翰等人的启发。
(2019),我们在每个潜在空间上训练额外的对抗性分类器,试图预测非目标生成因子的值,而模型试图构建潜在空间,以便这些分类器的预测分布尽可能不具有预测性。
互信息最小化(MIN):两个变量之间独立性的自然度量是互信息(MI)。因此,该目标最小化了每对潜在空间之间MI的上界估计,如下(Cheng等人,2020a,b;Colombo等人,2021)。
下面给出了ADV和MIN目标的详细信息。
对抗性目标。对抗性目标(ADV)由两部分组成:1)对抗性分类器试图从每个潜在空间预测所有非目标因素的值;2) 旨在最大化敌对分类器预测分布的熵的损失。
对于给定的潜在空间,一组线性分类因子分别预测每个非目标因子k 6=的值,并计算每个非目标因子的二元交叉熵损失
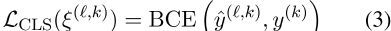
。
式中,ξ(,k)是来自潜在空间的对抗式分类器预测因子k的参数,ŷ(,k)是相应的预测。
例如,我们为内容空间=c引入了两个这样的分类器,一个用于预测否定,另一个用于预测不确定性,k∈ {n,u}。重要的是,这些分类器的预测错误不会反向传播到VAE的其余部分。我们为每个敌对分类器增加了一个额外的目标,目的是使其预测分布尽可能接近均匀分布。我们按照John et al.(2019)和Fu et al.(2018)的方法,通过最大化预测分布的熵(方程(4))并反向传播误差来实现这一点
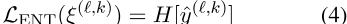
。
由于目标是最大限度地提高这一数量,总的对抗目标是ADV目标,目的是使潜在表征尽可能对非目标因素缺乏信息。与信息性目标一起,它推动表征专注于其目标生成因素。
MI最小化目标。MI最小化(MIN)目标的重点是使每个潜在空间的分布尽可能不同。
我们根据方程(6)最小化每对潜在空间之间的MI
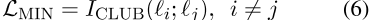
。
其中,ÎCLUB(I;j)是MI的对比学习上限(CLUB)估计值(Cheng等人,2020a)。具体而言,我们引入一个单独的神经网络来近似条件变分分布pσ(i | j),该网络用于使用潜在空间的样本估计MI的上界。
方程(7)给出了完整的模型目标以及相关的hy-perparameters权重λ。
附录E中给出了我们的超参数设置和进一步的实现细节
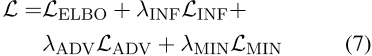
。
在接下来的部分中,我们将对完整目标中的不同术语子集及其对分解的影响进行实验。我们训练一个模型,只使用ELBO目标作为我们的分离基线。
4实验
我们在第4.1节中描述了我们的数据集、预处理和数据扩充方法。第4.2节描述了我们的评估指标,以及这些指标如何针对第3.2节中给出的分解要求。
4.1数据集
我们使用SFU评论语料库(Konstantinova et al.,2012)作为主要数据集。该语料库包含17000个来自各种英语产品评论的句子,最初用于情感分析,用否定和不确定性线索及其范围进行注释。许多SFU句子都很长(>30个tokens),初步实验表明,这会导致重建效果不佳。因此,我们利用SFU的带注释语句连词tokens将多语句语句拆分为单语句语句语句,以降低复杂性并增加示例数量。此外,为了降低复杂性,我们在之前的工作之后删除了>15个tokens的句子(Hu et al.,2017),从而产生了14000个句子。
我们将所有提示范围注释转换为语句级注释。多级不确定性注释被证明是相当不一致和嘈杂的,与二进制注释相比,注释者之间的一致性较低(Rubin,2007)。因此,我们将确定性标签二值化如下(Zerva,2019)。
4.1.1数据扩充
尽管做出了上述努力,我们发现仅SFU语料库不足以获得流畅的重建。因此,我们使用两个具有单词袋(BOW)特征6的朴素贝叶斯分类器,为大量额外的亚马逊和Yelp评论数据生成了弱否定和不确定性标签。这些分类器分别在SFU训练分割中进行训练的,以预测句子层面的否定和不确定性。Amazon和Yelp数据集很好地适应了SFU的数据分布,也包括用户评论,并已在之前的文本DRL工作中使用,并取得了良好的效果(John et al.,2019;Cheng et al.,2020b)7。附录C总结了SFU+亚马逊组合数据集的统计数据。在附录D中,我们对SFU+Yelp组合数据集进行了补充评估。
4.2评估
评估所学表征的分解需要第3.2节:信息性、独立性和不变性中给出的需求的补充度量。
为了测量信息量,我们报告了一个逻辑回归模型的精确度、召回率和F1分数,该模型经过训练的,可以预测每个潜在空间的每个地面真相标签,紧随East-wood和Williams(2018)。我们还报告了每个潜在分布和因子之间的MI,因为这可以进一步了解信息量。
为了衡量独立性,我们使用互信息差距(MIG)(Chen等人,2018年)。MIG位于【0,1】,数值越大,表明分解程度越大。MIG计算详情见附录E.1。
我们通过使用预测的潜在分布样本计算每对潜在变量之间的Pear-son相关系数来评估不变性。
评估模型重构输入的能力也很重要。具体而言,我们的目标是重建忠实度(即输入和重建匹配的程度)和流畅度。我们根据模型保留否定、不确定性和输入内容的能力来评估忠诚度。通过对重构进行重新编码,根据重新编码的潜在值预测否定和不确定状态,并根据基本真值标签8计算精度、回忆和F1分数,来衡量否定和不确定度保留。继之前的工作之后,我们通过计算输入和重构(自BLEU)之间的BLEU分数,近似计算在没有任何明确内容注释的情况下的内容保存度量(Bao等人,2019年;Cheng等人,2020b;Balasubramanian等人,2021)。我们通过计算GPT-2下的困惑(PPL)来评估重建的流畅性,GPT-2是一种强大的通用领域语言模型(Radford et al.,2019)。
最后,我们评估了模型翻转输入否定或不确定性状态的能力。对于每个测试示例,我们覆盖要更改的潜在因子的值,以表示其基本真值标签的对立面。模型控制否定和不确定性的能力是通过重新编码从被覆盖的潜在值获得的重构、从重新编码的潜在值预测以及相对于基本真值标签的计算精度来衡量的。
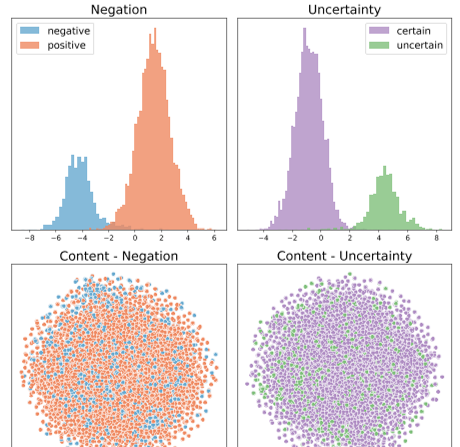
图4:通过INF+ADV+MIN模型学习的模态、否定和内容空间的直方图和t-SNE(vanderMaaten和Hinton,2008)可视化。
5结果
在下文中,第5.1节报告了分离结果,第5.2节报告了忠实度和流利度结果。第5.3节讨论了这些结果如何解决第1节中提出的两个研究问题。
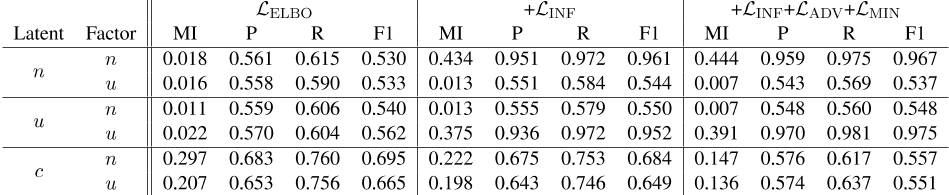
表1:各潜在因子和因子之间的互信息估计。每个因素的潜在空间分类器的精度、召回率和F1。n:否定。u:不确定性。c:内容。所示为从SFU+亚马逊测试集上每个示例的30个潜在分布重采样计算的平均值。因为它们的结果类似于L ELBO+L INF+L ADV+L MIN,所以不包括L ELBO+{L ADV,L MIN}以节省空间。我们提供了一组更广泛的结果,涵盖表10中的所有模型。
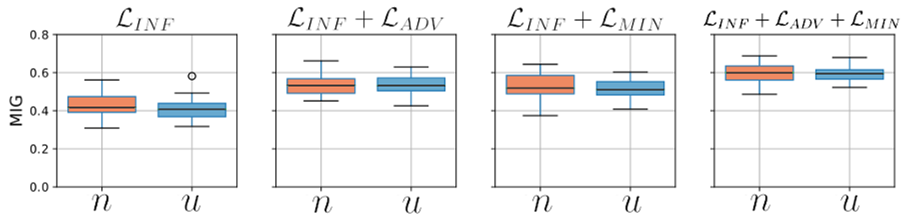
图5:在测试集上计算的否定因子和不确定因子的每个分解目标的互信息差距(MIG)方框图。基线ELBO目标的MIG值太小,无法包含在该图中≈ 0 . 014表示否定和不确定性。
5.1分解
表1显示了每个潜在空间相对于每个目标因子的信息量,作为预测性能和MI。
仅仅是ELBO的基线目标并不能解决这个问题。它将几乎所有的表现力都放在内容空间中,尽管如此,内容空间仍然不受否定和不确定性因素的影响,MIs和F1s较低。然而,使用信息辅助目标的模型确实能够实现良好的分解:否定和不确定性空间对其目标因素具有高度的信息性,而对非目标因素9则没有信息性。然而,内容空间仍然略微预测否定和不确定性,F1s分别为0.684和0.649。这随着ADV和MIN目标的提高而提高,其中内容空间显示否定和不确定性的近似随机预测性能,而否定和不确定性空间对其目标因子的预测性能略有提高。图4中的可视化显示了这些结果,图4显示了否定和不确定性潜在分布中的类之间的明显分离,但内容空间中的类之间没有区别。此外,我们注意到,尽管否定和不确定性潜伏期是简单的一维编码,但它们具有良好的预测性能。
图5给出了否定因子和不确定因子的MIG值方框图。我们再次看到,INF目标单独导致不雅的分解,MIG中值≈ 0 . 4.
ADV和MI目标提供了MIG的类似增加,达到≈ 0 . 55表示否定和不确定,它们的组合ADV+MIN进一步提高MIG,达到≈ 0 . 6,表明这些目标是互补的。
我们在表2中展示了我们模型的否定和不确定性表示的不变性。
虽然仅ELBO目标就导致了高度协变的否定和不确定性潜在分布(0.706),但在INF(0.200)下,这一分布显著下降,ADV和MIN目标(0.159)导致了额外的减少。
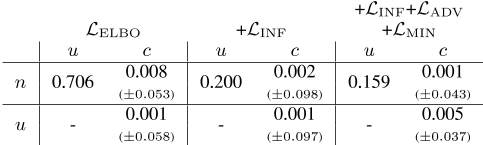
表2:模型中每对潜在表示之间的皮尔逊相关系数。由于内容空间是62维的,我们计算每个维度之间的相关系数,并在下面的括号中报告平均值和标准偏差。
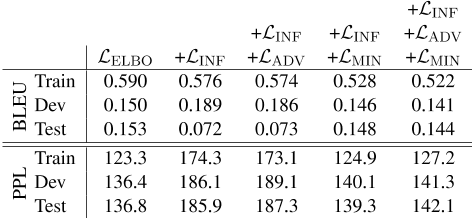
表3:每个模型在每次数据分割时的重建自我BLEU和重建困惑(PPL)。使用GPT-2计算困惑(Radford et al.,2019)。
5.2重建评估
5.2.1忠实和流利
表3报告了每个分解目标的自我模糊和困惑。表9给出了重建示例。这些结果表明,这些模型在训练集合上的内容重建方面非常一致,但在开发和测试时,这种一致性会下降。虽然ADV和MIN的目标比INF提供了分解收益,但BLEU分数表明,尽管存在更好的困惑,但内容保存能力可能会稍差。
虽然self-BLEU表示重建内容的一致性,但它不一定表示重建内容在否定和不确定性方面的一致性,因为否定和不确定性通常通过一个token与相反的值计数器部分不同。表4报告了INF和INF+ADV+MIN模型在这些因素方面的一致性。仅INF目标在某种程度上是一致的,对于否定和不确定性,重新编码的F1s分别为0.830和0.789。辅助目标将其显著提高至0.914和0.893,表明表1和图5中的分解增益对重建的一致性具有正影响。
5.2.2受控生成
表5显示了按传输方向划分的受控生成任务中每个模型的精度。我们发现,对于否定和不确定性而言,修改输入状态只在一个方向上有效:从否定到正,从不确定到确定。
将一个句子从否定变为正或从不确定变为确定,通常需要删除提示tokens(例如,not、never、may),而相反的方向需要添加它们。通过内容表示和tokens数量之间的线性回归,我们发现内容空间对句子长度的信息量很大,这有效地阻止了解码器添加所需的否定或不确定性tokens 10。人工检查正确和错误修改的句子表明,解码器试图通过修改输入中的tokens来表示否定/不确定性状态,而不是添加或删除它们,以满足长度限制。当需要删除时,提示token通常被与表示一致的新tokens替换。然而,只有在可能将现有的token更改为提示token时,才会包含否定/不确定性提示tokens。附录C.3中给出了线性回归的详细信息以及成功/失败传输的示例。
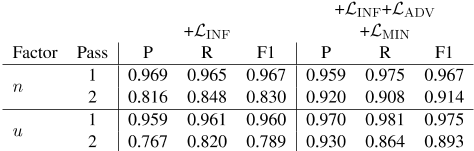
表4:解码器与测试集上评估的否定和不确定度的基本真值的一致性。过程1是指原始输入的预测。过程2是指重新编码重建的预测。第1关可以视为第2关性能的上限。
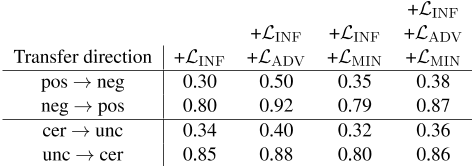
表5:按传输因子和方向划分的受控生成精度。
5.3研究问题
RQ1:有可能学习否定、不确定性和内容的分解表示吗?。
结果表明,根据第3.2节中概述的三个要求,确实可以估计一个统计模型,其中否定、不确定性和内容是分解的潜在变量。具体而言,表1显示了各目标之间否定空间和不确定性空间的高度信息性,每个潜在空间对非目标因素的预测能力较差,表明了独立性。图5进一步显示了各车型的独立性,MIG得分中值在0.4-0.6范围内。最后,表2中的低协方差证明了潜在表示相互之间的不变性。
RQ2:对于这项任务,现有的分解目标相比之下如何?。
值得注意的是,根据我们的三个要求,仅INF目标就可以产生良好的解纠缠,这表明仅监督就足以解纠缠。尽管如此,ADV和MIN目标的增加导致信息量略微增加(表1)和独立(表2)。
虽然表3中报告的自我BLEU分数表明,内容保存通常在辅助目标中保持,但在使用MIN目标的目标中,会出现小幅度下降。这一趋势也适用于困惑,表明虽然MIN目标有助于分解收益,但它可能会导致更差的重建。
6结论
受语言学理论的启发,我们提出了一个生成性模型,其中否定、不确定性和内容是分解的潜在变量。
我们使用VAE评估了该模型,并比较了现有分解目标的性能。通过一系列评估,我们表明,确实可以理清这些因素。
虽然基于对抗性学习和MI最小化的目标导致了分解和一致性增益,但我们发现,通过对潜在表征(即INF目标)的简单监督,可以在变量分解和重建能力之间获得适当的平衡。此外,我们的一维否定和不确定性表示法尽管简单,但仍具有很高的预测性能。未来的工作将探索其他潜在分布,如离散分布(Jang等人,2017;Dupont,2018),这可能更好地代表这些运营商。
这项工作有一些局限性。首先,我们的模型不处理否定和不确定性范围,而是假设操作符的范围覆盖整个语句。我们的模型是在相对较短的单陈述句上估计的,以满足这一假设,但未来的工作将研究如何将运算符分解与运算符范围模型统一起来,以便将其应用于具有多个子句的较长示例。其次,虽然我们的模型实现了高度的分解,但它们没有达到受控的生成任务。我们发现,这可能是由于记忆句子长度的模型,限制了重建的方式与添加否定和不确定性线索tokens不兼容。(Bosc和Vincent,2020)也注意到了VAEs中句子长度记忆的这种趋势,未来将探索他们建议的补救措施,如编码器预训练。
致谢
本文基于新能源和工业技术发展组织(NEDO)委托的JPNP20006项目的结果。这项工作还得到了曼彻斯特大学校长博士奖学金、曼彻斯特大学与人工智能研究中心、欧洲研究理事会(ERC StG DeepSPIN 758969)的合作,以及通过UIDB/50008/2020合同获得的技术合作基金会的支持。
参考文献
Heike Adel and Hinrich Schütze. 2017. Exploring different dimensions of attention for uncertainty detection . In Proceedings of the 15th Conference of the European Chapter of the Association for Computa- tional Linguistics: Volume 1, Long Papers , pages 22– 34, Valencia, Spain. Association for Computational Linguistics.
Vikash Balasubramanian, Ivan Kobyzev, Hareesh Bahu- leyan, Ilya Shapiro, and Olga Vechtomova. 2021. Polarized-VAE: Proximity based disentangled representation learning for text generation . In proceedings of the 16th Conference of the European chapter of the Association for Computational Linguistics: Main Volume , pages 416–423, Online. Association for Computational Linguistics.
Yu Bao, Hao Zhou, Shujian Huang, Lei Li, Lili Mou, Olga Vechtomova, Xin-yu Dai, and Jiajun Chen.
2019. Generating sentences from disentangled syntactic and semantic spaces . In Proceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics , pages 6008–6019, Florence, Italy. Association for Computational Linguistics.
Jeremy Barnes, Erik Velldal, and Lilja Øvrelid. 2021. Improving sentiment analysis with multi-task learning of negation . Natural Language Engineering , 27(2):249–269.
Farah Benamara, Baptiste Chardon, Yannick Mathieu, Vladimir Popescu, and Nicholas Asher. 2012. How do negation and modality impact on opinions? In Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics , pages 10–18, Jeju, Republic of Korea. Association for Computational Linguistics.
Y. Bengio, A. Courville, and P. Vincent. 2013. representation learning: A review and new perspectives . IEEE Transactions on Pattern Analysis and Machine Intelligence , 35(8):1798–1828.
Tom Bosc and Pascal Vincent. 2020. Do sequence-to- sequence VAEs learn global features of sentences? In Proceedings of the 2020 Conference on empirical Methods in Natural Language Processing (EMNLP) , page 4296–4318. Association for Compu- tational Linguistics.
Samuel R. Bowman, Luke Vilnis, Oriol Vinyals, andrew Dai, Rafal Jozefowicz, and Samy Bengio. 2016. Generating sentences from a continuous space . In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning , pages 10–21, Berlin, Germany. Association for Computa- tional Linguistics.
Ronnie Cann. 1993a. 3.3.1 Negation , Cambridge Text- books in Linguistics, page 60–61. Cambridge university Press.
Ronnie Cann. 1993b. 9.3.1 Simple modality , cambridge Textbooks in Linguistics, page 270–276. Cambridge University Press.
Junxiang Chen and Kayhan Batmanghelich. 2020. Weakly supervised disentanglement by pairwise sim- ilarities . Proceedings of the ... AAAI Conference on Artificial Intelligence. AAAI Conference on Artificial Intelligence , 34(4):3495–3502.
Ricky T. Q. Chen, Xuechen Li, Roger Grosse, and David Duvenaud. 2018. Isolating sources of disen- tanglement in VAEs . In Proceedings of the 32nd international Conference on Neural Information processing Systems , NIPS’18, page 2615–2625. Curran Associates Inc.
Pengyu Cheng, Weituo Hao, Shuyang Dai, Jiachang Liu, Zhe Gan, and Lawrence Carin. 2020a. CLUB: A Contrastive Log-ratio Upper Bound of mutual information . In International Conference on Machine Learning , page 1779–1788. PMLR.
Pengyu Cheng, Martin Renqiang Min, Dinghan Shen, Christopher Malon, Yizhe Zhang, Yitong Li, and Lawrence Carin. 2020b. Improving disentangled text representation learning with information- theoretic guidance . In Proceedings of the 58th annual Meeting of the Association for Computational Linguistics , pages 7530–7541, Online. Association for Computational Linguistics.
Murphy Choy and Mark Chong. 2018. Seeing through misinformation: A framework for identifying fake online news . arXiv preprint arXiv:1804.03508 .
Pierre Colombo, Pablo Piantanida, and Chloé Clavel. 2021. A novel estimator of mutual information for learning to disentangle textual representations . In Proceedings of the 59th Annual Meeting of the association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 6539– 6550, Online. Association for Computational Lin- guistics.
Emilien Dupont. 2018. Learning disentangled joint continuous and discrete representations . In proceedings of the 32nd International Conference on Neu- ral Information Processing Systems , NIPS’18, page 708–718. Curran Associates Inc.
Cian Eastwood and Christopher K. I. Williams. 2018. A framework for the quantitative evaluation of disentangled representations . In International Conference on Learning Representations .
Federico Fancellu, Adam Lopez, and Bonnie Webber. 2016. Neural networks for negation scope detection . In Proceedings of the 54th Annual Meeting of the association for Computational Linguistics (Volume 1: Long Papers) , page 495–504. Association for Com- putational Linguistics.
Richárd Farkas, Veronika Vincze, György Móra, János Csirik, and György Szarvas. 2010. The conll-2010 shared task: learning to detect hedges and their scope in natural language text . In Proceedings of the fourteenth Conference on Computational Natural language Learning—Shared Task , pages 1–12.
Zhenxin Fu, Xiaoye Tan, Nanyun Peng, Dongyan Zhao, and Rui Yan. 2018. Style transfer in text: exploration and evaluation . In AAAI Conference on artificial Intelligence .
Irina Higgins, David Amos, David Pfau, Sebastien Racaniere, Loic Matthey, Danilo Rezende, and Alexander Lerchner. 2018. Towards a Definition of Disentangled Representations . arXiv:1812.02230 [cs, stat] . ArXiv: 1812.02230.
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. 2016. beta- VAE: Learning basic visual concepts with a constrained variational framework . In International Conference on Learning Representations .
Zhiting Hu, Zichao Yang, Xiaodan Liang, Ruslan Salakhutdinov, and Eric P. Xing. 2017. Toward controlled generation of text . In International Conference on Machine Learning , page 1587–1596. PMLR.
Eric Jang, Shixiang Gu, and Ben Poole. 2017. Categori- cal reparameterization with Gumbel-softmax . In 5th International Conference on Learning Representa- tions, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net.
Salud María Jiménez-Zafra, Roser Morante, Eduardo Blanco, María Teresa Martín Valdivia, and L. Al- fonso Ureña López. 2020. Detecting negation cues and scopes in Spanish . In Proceedings of the 12th Language Resources and Evaluation conference , pages 6902–6911, Marseille, France. European Language Resources Association.
Salud María Jiménez-Zafra, Mariona Taulé, M Teresa Martín-Valdivia, L Alfonso Urena-López, and M An- tónia Martí. 2018. SFU review SP-NEG: a Spanish corpus annotated with negation for sentiment analy- sis. a typology of negation patterns . Language resources and Evaluation , 52(2):533–569.
Vineet John, Lili Mou, Hareesh Bahuleyan, and Olga Vechtomova. 2019. Disentangled representation learning for non-parallel text style transfer . In proceedings of the 57th Annual Meeting of the association for Computational Linguistics , pages 424–434, Florence, Italy. Association for Computational Lin- guistics.
Aditya Khandelwal and Suraj Sawant. 2020. Neg- BERT: A transfer learning approach for negation detection and scope resolution . In Proceedings of the 12th Language Resources and Evaluation conference , page 5739–5748. European Language resources Association.
Halil Kilicoglu, Graciela Rosemblat, and Thomas C. Rindflesch. 2017. Assigning factuality values to semantic relations extracted from biomedical research literature . PLOS ONE , 12(7):e0179926.
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization . In 3rd international Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings .
Diederik P. Kingma and Max Welling. 2014. Auto- encoding variational bayes . In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, conference Track Proceedings .
Natalia Konstantinova, Sheila C.M. de Sousa, Noa P. Cruz, Manuel J. Maña, Maite Taboada, and Rus- lan Mitkov. 2012. A review corpus annotated for negation, speculation and their scope . In proceedings of the Eighth International Conference on language Resources and Evaluation (LREC’12) , pages 3190–3195, Istanbul, Turkey. European Language Resources Association (ELRA).
Lydia Lazib, Yanyan Zhao, Bing Qin, and Ting Liu. 2019. Negation scope detection with recurrent neu- ral networks models in review texts . International Journal of High Performance Computing and Net- working , 13(2):211–221.
Hao Li and Wei Lu. 2018. Learning with structured representations for negation scope extraction . In proceedings of the 56th Annual Meeting of the association for Computational Linguistics (Volume 2: Short Papers) , page 533–539. Association for Computa- tional Linguistics.
Chen Lin, Steven Bethard, Dmitriy Dligach, Farig Sadeque, Guergana Savova, and Timothy A. Miller. 2020. Does BERT need domain adaptation for clinical negation detection? Journal of the American Medical Informatics Association , 27(4):584–591. Lajanugen Logeswaran, Honglak Lee, and Samy Ben- gio. 2018. Content preserving text generation with attribute controls . In Advances in Neural Information Processing Systems 31: Annual conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada , pages 5108–5118. Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factual- ity in abstractive summarization . In Proceedings of the 58th Annual Meeting of the Association for Com- putational Linguistics , page 1906–1919. Association for Computational Linguistics. Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. Automatic differentiation in PyTorch . Fabian Pedregosa, Gaël Varoquaux, Alexandre Gram- fort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake VanderPlas, alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Edouard Duchesnay. 2011. Scikit-learn: Machine learning in python . J. Mach. Learn. Res. , 12:2825–2830.
Zhong Qian, Peifeng Li, Qiaoming Zhu, Guodong Zhou, Zhunchen Luo, and Wei Luo. 2016. speculation and negation scope detection via convolu- tional neural networks . In Proceedings of the 2016 Conference on Empirical Methods in Natural language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016 , pages 815–825. The association for Computational Linguistics.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners . OpenAI blog , 1(8):9.
Yafeng Ren, Hao Fei, and Qiong Peng. 2018. Detect- ing the scope of negation and speculation in biomed- ical texts by using recursive neural network . In IEEE International Conference on Bioinformatics
and Biomedicine, BIBM 2018, Madrid, Spain, december 3-6, 2018 , pages 739–742. IEEE Computer Society.
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. Beyond accuracy: Behav- ioral testing of NLP models with CheckList . In proceedings of the 58th Annual Meeting of the association for Computational Linguistics , pages 4902– 4912, Online. Association for Computational Lin- guistics.
Brian C. Ross. 2014. Mutual information between discrete and continuous data sets . PLOS ONE , 9(2):e87357.
Victoria L. Rubin. 2007. Stating with certainty or stating with doubt: Intercoder reliability results for manual annotation of epistemically modalized statements . inhuman Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; companion Volume, Short Papers , pages 141–144, Rochester, New York. Association for Computational Linguis- tics.
Roser Saurí and James Pustejovsky. 2009. Factbank: a corpus annotated with event factuality . Lang. Resour. Evaluation , 43(3):227–268.
Rui Shu, Yining Chen, Abhishek Kumar, Stefano Er- mon, and Ben Poole. 2019. Weakly supervised dis- entanglement with guarantees . In International conference on Learning Representations .
Pontus Stenetorp, Sampo Pyysalo, Tomoko Ohta, Sophia Ananiadou, and Jun’ichi Tsujii. 2012. bridging the gap between scope-based and event-based negation/speculation annotations: abridge not too far . In Proceedings of the Workshop on Extra- Propositional Aspects of Meaning in Computational Linguistics , page 47–56. Association for Computa- tional Linguistics.
Paul Thompson, Raheel Nawaz, John McNaught, and Sophia Ananiadou. 2017. Enriching news events with meta-knowledge information . Lang. Resour. Evaluation , 51(2):409–438.
Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research , 9(11).
Veronika Vincze, György Szarvas, Richárd Farkas, György Móra, and János Csirik. 2008. The bioscope corpus: biomedical texts annotated for uncertainty, negation and their scopes . BMC Bioinform. , 9(S-11).
Michael Wiegand, Alexandra Balahur, Benjamin Roth, Dietrich Klakow, and Andrés Montoyo. 2010. A survey on the role of negation in sentiment analysis . In Proceedings of the Workshop on Negation and Speculation in Natural Language Processing, NeSp- NLP@ACL 2010, Uppsala, Sweden, July 10, 2010 , pages 60–68. University of Antwerp.
Zi Yang, Yue Zhou, and Eric Nyberg. 2016. Learning to answer biomedical questions: OAQA at BioASQ 4B . In Proceedings of the Fourth BioASQ workshop , pages 23–37, Berlin, Germany. Association for Com- putational Linguistics.
Mark Yatskar. 2019. A qualitative comparison of CoQA, SQuAD 2.0 and QuAC . In Proceedings of the 2019 Conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 2318–2323, Minneapolis, Min- nesota. Association for Computational Linguistics.
Chrysoula Zerva. 2019. Automatic Identification of Tex- tual Uncertainty . Ph.D. thesis, University of Manch- ester.
Yiyun Zhao and Steven Bethard. 2020. How does BERT’s attention change when you fine-tune? an analysis methodology and a case study in negation scope . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 4729–4747, Online. Association for Computational Linguistics.

