
- 1利用jieba实现分词、高频词统计、词性标注_利用jieba软件包对采集到1000条评论数据进行分词、词性标注
- 2面试官:“谈谈Spring中都用到了那些设计模式?”。_为什么 spring 开发都没有人使用抽象类
- 3怎么把word里面的彩色图转化为灰度图,直接在word里面操作,无需转其他软件,超简单!(位图和矢量图都可以)_word 灰度化
- 4华为畅享9 plus鸿蒙系统,华为鸿蒙系统支持的手机型号_鸿蒙系统支持华为哪几款手机...
- 5原创《基于深度特征学习的细粒度图像分类研究综述》_ma-cnn
- 6Android 允许其他应用读取本应用的私有目录
- 7Nessus离线激活_离线激活nessus
- 8Label Studio简单使用
- 9ONLYOFFICE:开源、免费、安全,打造定制化办公平台的最佳选择_onlyoffice免费部署
- 10logcat的介绍 - 安卓生态圈的log命令工具
Sora 究竟有多烧钱?Sora的推理与训练的计算成本被扒出来了
赞
踩
Sora一经发布,世界再次被AI的力量所震撼。要知道Runway、Pika等明星模型都还在突破几秒内的连贯性的时候,Sora已经可以直接生成长达60s的一镜到底视频。
大家对Sora的更进一步信息和细节都非常好奇,但遗憾的是,OpenAI并未公布它的技术细节,而只有一份简单的技术报告。
今天我们就来扒一扒网上对Sora训练和推理的估算,看看Sora惊艳效果背后的算力究竟是如何的惊人。
分享几个自用的Claude 3和GPT-4的镜像站给大家吧,均为国内可用:
hujiaoai.cn(最牛的Claude 3 Opus,注册即用,测评下来完全吊打了GPT4)
higpt4.cn(稳定使用一年的chatgpt-4研究测试站,非商业目的,而且用的是最牛的128k窗口的版本)

▲Sora生成的视频效果
从DiT到Sora
在Sora的技术报告中,作者提到Sora的设计很大程度上受到了《Scalable Diffusion Models with Transformers》论文的影响,这篇论文中提到的模型DiT是用于图像生成的,Sora将这项工作扩展到了视频生成。
我们先来看看DiT模型,最大的DiT模型DiT-XL具有675M参数,需要次浮点运算进行训练。为了使这个数字更容易理解,这相当于大约一台H100运行12天。

下面是对Sora所需的计算量做一个估算:
1、DiT只对图像进行建模,但Sora是视频模型,我们假设Sora在把图片变成视频的过程中没有额外计算。
Sora可以生成1分钟的视频,如果我们假设视频以24fps编码,则一个视频有1440帧(24fps * 60s)。Sora的像素到潜在映射似乎在空间和时间上都进行了压缩。如果我们假设与DiT论文(8x)的压缩率相同,我们最终在潜在空间中得到180帧(1440/8)。
2、Sora明显大于675M参数,之前有传言GPT3.5的模型大小是20B
所以我们估计Sora为20B是可行的,这需要DiT的30倍计算量。
3、Sora应该是接受了图像和视频的混合训练,OpenAI没有过多谈论他们的数据集,但他们暗示它非常大:“我们从大型语言模型中汲取灵感,这些模型通过对互联网规模数据进行训练来获得通才能力。
假设Sora数据集比DiT使用的数据集大10倍到100倍,但DiT在相同数据上重复训练,若有更大数据集,则此方法并非最佳。因此将计算量增加4-10倍是合理的,取中值7倍作为估算。
所以,把上面的估算结果相乘,训练Sora的总浮点数计算量约为:
这相当于14739张H100运行一个月!

以当前H100市场价约3万美元算,14739张H100约需要4.4亿美元,老黄直接狂喜。

在能耗方面,H100 GPU的最大功耗约为700W,这需要大概kWh的电力,这相当于一架波音757飞机飞行七百万公里的碳排放,可以绕地球赤道转173圈,环保人士已经要坐不住了。

我们需要更多的显卡
Sora的训练已经消耗这么多了,我们再来估计一下推理所需的资源。
我们再次使用DiT来推断Sora,DiT-XL每步使用FLOPS,250个扩散步骤总共FLOPS,同样的方法,乘上30再乘180,我们可以估计:
一个Nvidia H100 GPU大约每小时能生成5分钟的视频。
如果视频作者要依靠Sora来创作,那么他至少需要十张以上的H100,才能十分钟内生成合理时长的视频。这个成本将非常高,肯定不适合普通人来使用。
盈亏平衡
盈亏平衡,即模型达到一个推理的使用量,使得推理和训练期间的花费相同。
我们倾向于关注的另一个重要考虑因素是训练成本与推理成本的比较。众所周知,训练成本非常大,但也是一次性成本。相比之下,推理成本要小得多,但推理是频繁调用的,推理计算会随着用户数量的增加而增加,因此,查看“盈亏平衡点”是有用的。
按照前面的计算,我们得出下面DiT和Sora的训练与推理计算的比较。
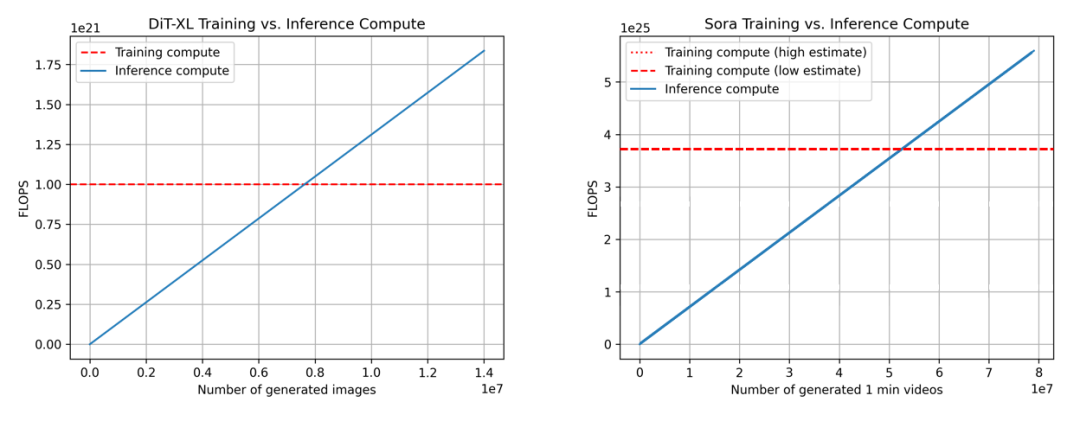
我们可以看到,DiT在生成7.6M图像后达到盈亏平衡点,而Sora在生成53.4M分钟的视频后达到盈亏平衡点(约101.53年)
推理成本比GPT4高出几个量级
为了进一步见识Sora所需计算量之巨大,我们可以对比一下不同模型的每单位输出,推理计算所需的计算量。
我们先划定一个标准,对于Sora,每单位输出是一个1分钟长的视频,对于DiT来说,它是一个512x512像素的图像,对于Llama 2和GPT-4,我们将单位输出定义为包含1000个token的单个文档。
下面是这些模型的对比图,横坐标是单位输出的个数,纵坐标是所需计算量,因为相差巨大,我们采用对数形式作图。
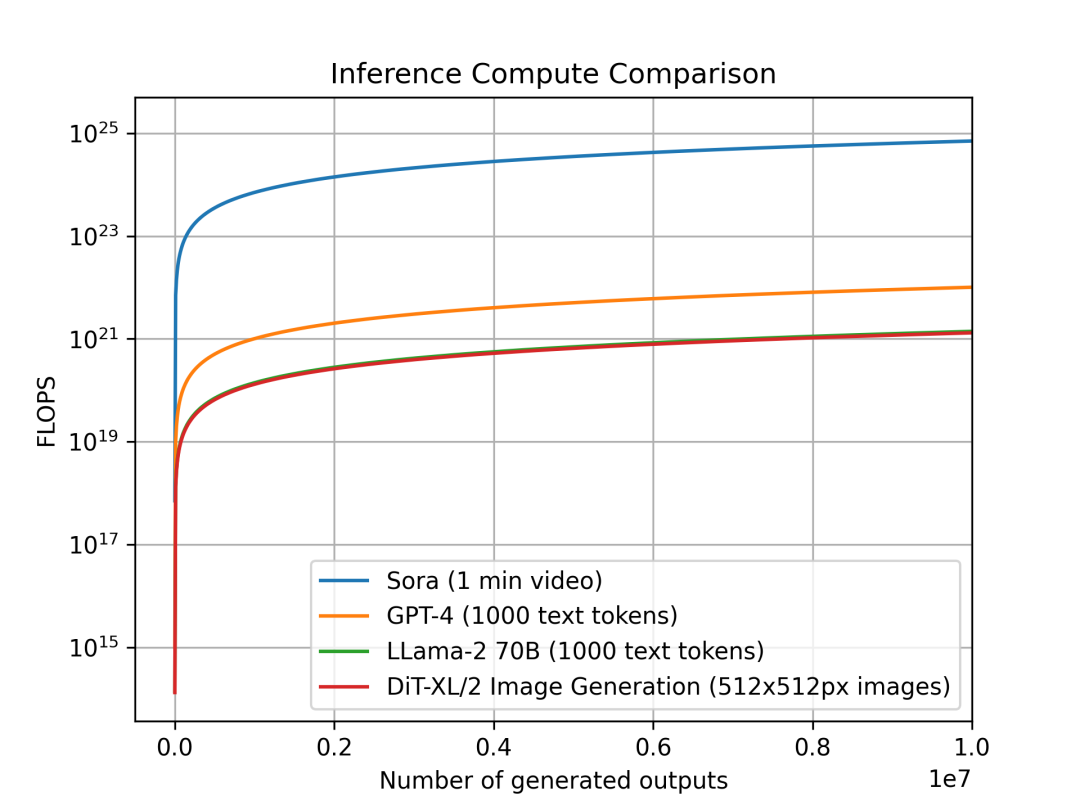
对于Sora和DiT,我们使用上面的推理估计。对于Llama 2和 GPT-4,我们使用 FLOPS = 2 的经验法则公式估计,即FLOPS=2×参数数量×生成的令牌数量。对于 GPT-4,我们假设该模型是一个混合专家 (MoE) 模型,具有2个专家,每个专家220B参数,且每次前向传递都处于活动状态。
我们可以进一步看到,Sora在推理工作负载方面甚至比GPT-4贵几个数量级。

未来可期
尽管目前Sora消耗巨大,但它不仅仅是一项技术,还是一个起点,我们相信,未来的视频生成将会形成一套完整的生态,从上游的模型到下游的应用,整个产业将会逐渐被建立。
Sora生成的视频,无论是在细节水平方面,还是在时间一致性方面(例如,当物体被暂时遮挡时,该模型可以正确处理物体的持久性),对于某些类型的场景来说,已经足够使用。目前OpenAI选择和一些艺术和电影工作室合作。
Shy Kids是一家多媒体制作公司,他们利用Sora制作了关于气球人的短片《Air Head》,导演Walter Woodman评论说:
“尽管Sora在创造看似真实的东西方面很出色,但让我们兴奋的是它能够创造出完全超现实的东西”,“来自世界各地的人们已经准备好从他们的胸膛里迸发出故事,终于有机会向世界展示里面的东西”

Don Allen III是一位跨学科的创作者,他说:
“很长一段时间以来,我一直在制作增强现实混合生物,我认为这些生物在我的脑海中会是有趣的组合。现在,我有了一种更简单的方法”,“不受传统物理定律或思维惯例的束缚”,与Sora合作将他的注意力从“技术障碍转移到纯粹的创造力......开启一个即时可视化和快速原型制作的世界”

当我们站在视频内容创作新时代的门槛上时,像Sora这样的模型的影响远远超出了技术领域。我们相信未来随着技术的优化,一个每个人都能拥抱AI,以 前所未有的方式讲述自己的故事。


