
热门标签
热门文章
- 1实操教学|用Serverless 分分钟部署一个 Spring Boot 应用,真香!
- 2色彩校正及OpenCV mcc模块介绍_有mcc的opencv
- 3文本----简单编写文章的方法(中),后端接口的编写,自己编写好页面就上传到自己的服务器上,使用富文本编辑器进行编辑,想写好一个项目,先分析一下需求,再理一下实现思路,再搞几层,配好参数校验,lomb
- 4【Flink实战系列】Flink+kafka+redis 实时计算 wordcount_flink 读写redis
- 5【ViViT】A Video Vision Transformer 用于视频数据特征提取的ViT详解_视频vit
- 6数据结构之——简说链表
- 7【专题】2024中国汽车业人工智能行业应用发展图谱报告合集PDF分享(附原数据表)...
- 8浅谈Nginx负载均衡原理与实现_nginx 负载均衡 必须在局域网吗为什么
- 9二、Neo4j的使用(知识图谱构建射雕人物关系)
- 10推荐9个好玩的AI作图网站_mental ai
当前位置: article > 正文
【机器学习实战】使用sklearn中的朴素贝叶斯方法实现新闻文本分类_任务描述 本关任务:使用sklearn完成新闻主题分类任务。 相关知识 为了完成本关任
作者:知新_RL | 2024-04-03 06:55:47
赞
踩
任务描述 本关任务:使用sklearn完成新闻主题分类任务。 相关知识 为了完成本关任
1. 数据集

2. 实现
2.1 代码
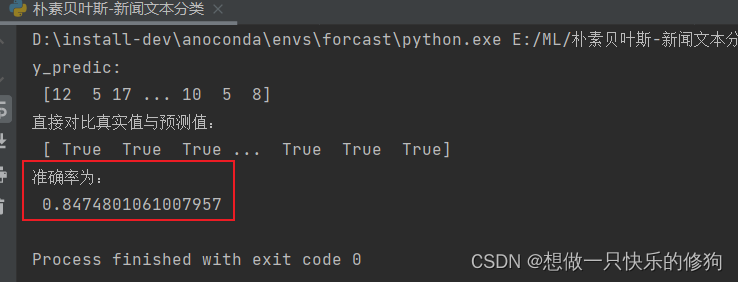
from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB def bayesian_demo(): ''' 朴素贝叶斯-文本分类 :return: ''' # 1. 获取数据 news = fetch_20newsgroups(subset='all') # 2. 划分数据集 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.2) # 3. 特征工程 transfer = TfidfVectorizer() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 4. 朴素贝叶斯算法预估器流程 estimator = MultinomialNB() estimator.fit(x_train, y_train) # 5. 模型评估 # 5.1 直接对比真实值、预测值 y_predict = estimator.predict(x_test) print('y_predic:\n', y_predict) print('直接对比真实值与预测值:\n', y_test == y_predict) # 5.2 计算准确率 score = estimator.score(x_test,y_test) print('准确率为:\n', score) if __name__ == '__main__': bayesian_demo()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2.2 结果
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

