
- 1牛津大学出品:随机噪声对抗训练_数据存在噪声时使用对抗学习
- 2【AIGC调研系列】AIGC+Jmeter实现接口自动化测试脚本生成
- 3腾讯云容器与Serverless的融合:探索《2023技术实践精选集》中的创新实践
- 4MTCNN 人脸检测论文解读,及tensorflow代码实现_该算法训练数据来源于wider公开的数据库,wider提供人脸检测数据,在大图上标注了人
- 5国科大 - 自然语言处理(刘洋)- 期末复习_国科大 自然语言处理 期末 刘洋
- 6TCP中RTT时延的理解_rtt延迟
- 7吴恩达2022机器学习专项课程(一) 5.1 多元特征回归
- 8跨过野蛮生长的直播电商下一步该走向何方?_野哥电商
- 9中文医学信息处理评测基准CBLUE2.0介绍_cmeee数据集
- 10Github万星!北航发布零代码大模型微调平台LlamaFactory
NLP自然语言处理——04.Attention的实现机制_如何输出bear的attention
赞
踩
1.Attention的介绍
在普通的RNN结构中,Encoder需要把一个句子转化为一个向量,然后在Decoder中使用,这就要求 Encoder把源句子中所有的信息都包含进去,但是当句子长度过长的时候,这个要求就很难达到,或者说会产生瓶颈(比如,输入一片文章等长内容),当然我们可以使用更深的RNN和大多的单元来解决这个问题,但是这样的代价也很大。
为此,Bahdanau等人在2015年提出了Attention机制,Attention翻译成为中文叫做注意力,把这种模型称为Attention based model。就像我们自己看到一幅画,我们能够很快说出画的主要内容,而忽略画中的背景,因为我们注意的,更关注的往往是其中的主要内容。
通过这种方式,在我们的RNN中,我们有通过LSTM或者是GRU得到的所有消息,那么这些信息中只去关注重点,而不需要在Decoder的每一个time step使用全部的Encoder的信息,这样就可以解决第一段所说的问题了。
那么现在要讲的Attention机制就能够帮助我们解决这个问题。
2.Attention的实现机制
假设我们有一个文本翻译的要求,即机器学习翻译为machine learning,那么这个过程通过前面所学习的seq2seq就可以实现
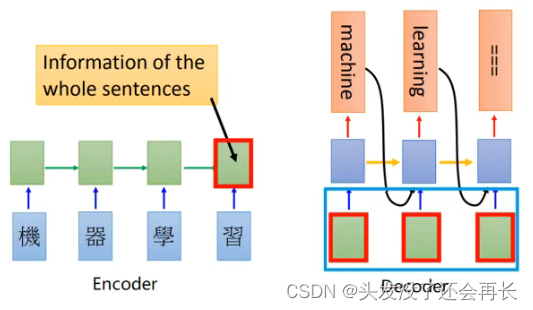
上图的左边是Encoder,能够得到hidden_state在右边使用
Decoder中蓝色方框中的内容,是为了提高模型的训练速度而使用teacher forcing手段,否则的话会把前一次的输出作为下一次的输入(但是在Attention模型中不再是这样了)
那么在整个过程中如果使用Attention应该怎么做呢?
在之前我们把Encoder的最后一个输出,作为decoder的初始的隐藏状态,现在我们不再这样做
2.1Attention的实现过程
- 初始化一个
Decoder的隐藏状态z0 - 这个
z0会和Encoder第一个time step的output进行match操作(或者是socre操作),得到α0^1,这里的match可以使用很多种操作,比如:- z和h的余弦值
- 是一个神经网络,输入为z和h
- 或者 α=h^TWz等
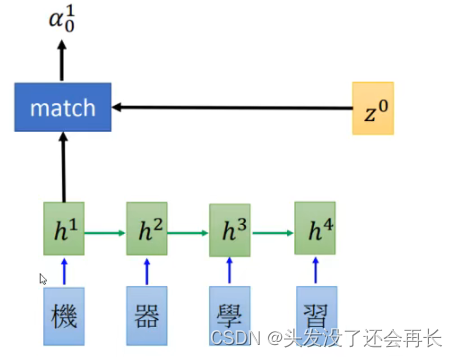
- encoder中的每个output都和z0进行计算之后,得到的结果进行
softmax,让他们的和为1(可以理解为权重) - 之后把所有的softmax之后的结果和原来的Encoder的输出
hi进行 相加求和得到c^0
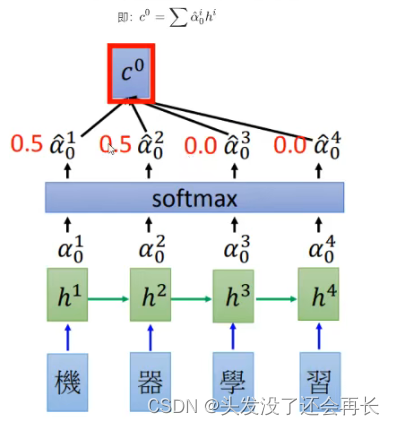
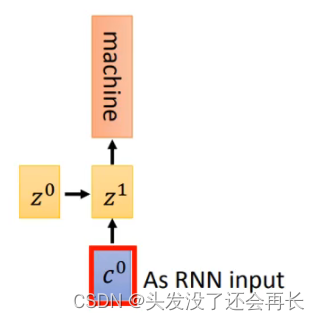
- 得到
c\^0之后,把它作为decoder的input,同和传入初始化的z\^0,得到第一个time step的输出和hidden_state(Z^1) - 再把
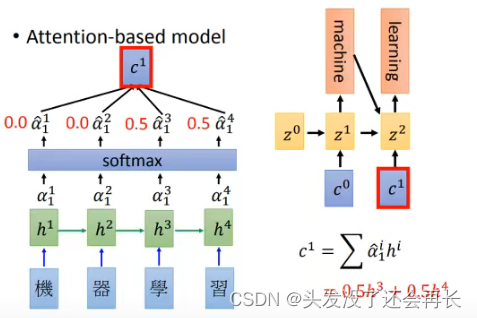
Z1再和所有的Encoder的output进行match操作,得到的结果进行softmax之后作为权重和Encoder的每个time step的结果相乘求和得到c^1 - 再把
c\^1作为decoder的input,和Z\^1作为输入得到下一个输出,如此循环,直到最终decoder的output为终止符。 - 整个过程写成数学公式如下:
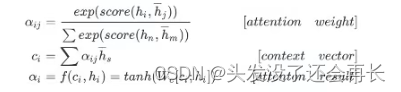
- 先计算
attention的权重:隐藏状态(zi)和Encoder的outputs计算(余弦,DNN,矩阵乘法)出的结果进行softmax之后得到的 - 再计算上下文向量,图中的
c^i:attention weight和Encoder outputs计算得到的,即αi和hi相乘求和 - 最后计算结果,往往会把当前的
output([batch_size, hidden_size])和上下文向量c^i 进行拼接 ,经过形状变换和tanh的处理之后作为当前时间步的输入。
- 先计算
总结:
初始化一个z0,和Encoder的每一个时间步的output进行match操作得到α^1,α^2…α^n,这些α进行softmax操作得到c^0,这个c^0和z^0作为Encoder的输入,得到第一个time step的输出和hidden_state(z^1),z^1和z^0经过一样的步骤和操作,得到z^2,循环往复…
2.2 Attention的分类
Global-Attention 和 Local-Attention
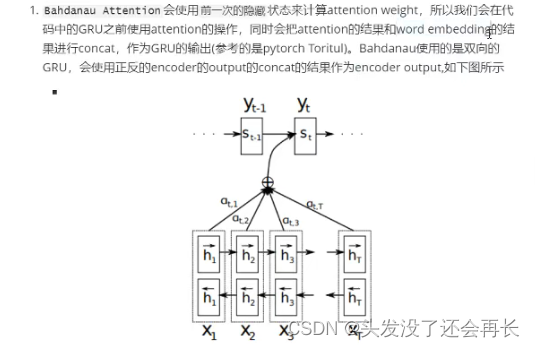
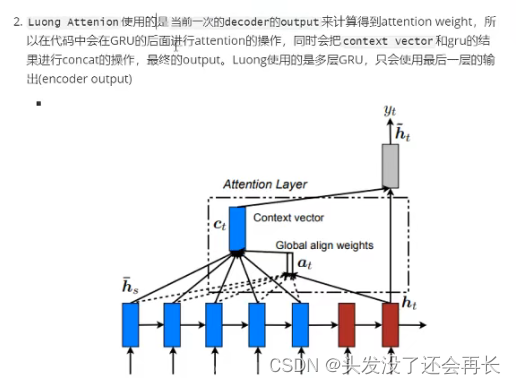
Bahdanau等人提出的Bahdanau Attention被称为local attention,后来Luong等人提出的Luong Attention是一种Global attention
所谓全局的attention是指:使用的全部的Encoder端的输入的attention的权重
local-attention就是使用了部分的Encoder端的输入的权值(当前时间步上的Encoder的hidden state),这样可以减少计算量,特别是当句子的长度比较长的时候。
前面的计算,是让decoder的输出hi和每一个Encoder的hidden state进行计算,所以是全局的attention
2.2不同类型的区别
2.2.1attention的计算数据和位置

2.2.2attention weights的方法不同




