
- 1尚硅谷爬虫(urllib_post请求百度翻译之详细翻译)笔记_not a(brand";v="99", "google chrome";v="121", "chr
- 2tableau数据可视化实战:大众点评成都美食(三)_大众点评招牌菜数据可视化
- 3异质网络模型metapath2vec算法
- 4预训练模型--GPT_gpt预训练
- 5论文精读:SegFormer_segformer论文
- 6《异常检测——从经典算法到深度学习》21 Anomaly Transformer:具有关联差异的时间序列异常检测
- 7Comparator--比较器_comparator比较器用法
- 8Java查询es数据,根据指定id检索(in查询),sql权限过滤,多字段匹配检索,数据排序_es根据id查询数据
- 9机器学习中正则化项L1和L2的直观理解_l1正则化
- 10基于特征点匹配全景图像拼接——MATLAB实现_基于特征匹配的matlab图像拼接
复旦大学自然语言处理实验室:如何构建和训练ChatGPT
赞
踩

©PaperWeekly 原创 · 作者 | 郑骁庆
单位 | 复旦大学自然语言处理实验室
2022 年 11 月美国人工智能研究实验室 OpenAI 发布了聊天机器人 ChatGPT,它能使用英语、汉语、法语等多种人类语言写诗做对、编写程序、回答问题、翻译撰文、闲聊对话等。发布后仅三个月,用户量就突破了一个亿,也使得 OpenAI 的估值也达到 290 亿美元。近一年多来,学术和工业界已经诞生了上百个类似的生成式语言大模型,甚至还出现了多模态(包括文本、图像、音频、视频等不同媒体类型)生成式大模型,相关构建和训练技术与方法的“神秘面纱”也慢慢被揭开了。
构建类似 ChatGPT 的语言大模型一般包括语言模型、提示精调和强化学习三个主要训练步骤,其中第一步大语言模型的训练要求较高的硬件条件和海量的数据资源,技术难度反而相对较低,而第三步使用强化学习实现对人类期望对齐既有在技术上有一定挑战,又需要多次人工标注反馈,因而实现上有一定困难。本文先用简单介绍 ChatGPT 的基本原理和使用方法,然后希望以通俗易懂方式介绍类似 ChatGPT 模型的构建和训练的完整过程(重点介绍使用强化学习与人类期望对齐这一步)。

深度学习与语言模型
深度学习就是用层数较多(深)的人工神经网络从数据中学习输入与输出之间映射关系的算法,而人工神经网络是受生物神经网络的结构和功能启发下设计的计算模型。
用深度学习训练得到的网络就叫深度神经网络,它可以简单看成一个函数,能够完成任何输入到输出的转换。比如:我们可以用它玩成语补全的游戏,输入成语的前三个字,让网络输出最后一个字(见图 1)。
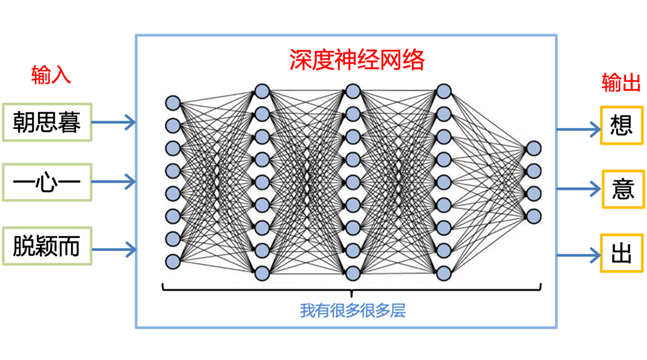
▲ 图1. 成语补全的深度神经网络
语言模型可以看成是成语补全的扩展版,它能够给定任意上文的情况下,预测下一个字或词。比如:输入“床前明月光,疑是地”,模型会输出“上”,然后将“上”添加到原输入中变成“床前明月光,疑是地上”,再输入到模型中,则会输出“霜”。如此这般,可以生成出完整的唐诗《静夜思》。使用这样的语言模型就可以完成文本生成任务了,类似技术被称为生成式人工智能(当然也还要包括生成图像、声音和视频等等啦)。
能够依据多长的上文来预测下一个字或词对模型的性能影响较大,目前一般从几千到几万个字或词不等,能够处理的上文越长,模型越强大。很多情况下,相同的上文,可以有多个不同的下文,所以模型输出实际上是不同可选字或词的概率分布。基于这些概率分布,使用随机采样方法就可以为同一个上文生成不同的下文,这种能力对于 ChatGPT 这种聊天和对话模型非常有用,因为它可以带来回答的多样性。

ChatGPT训练三步走
第一步语言模型“学会说话”:我们用深度神经网络来训练语言模型,先收集包含了各种语言(英文、中文、法文等)的尽可能多的文本,每次随机抽一段上文,让模型学会接着往下“背诵” (见图 2)。由于看过和背过的文字实在是太多了(实际训练使用了几乎所有能从各种渠道获得的文字和图书资源),模型就可以像模像样地说话了。训练时除了使用海量文本,还会包括大量的代码(就当普通文本一样对待)。一般认为代码有助于提高模型的“逻辑推理”能力,因为代码实现的算法就是对求解问题所需逻辑步骤的描述。
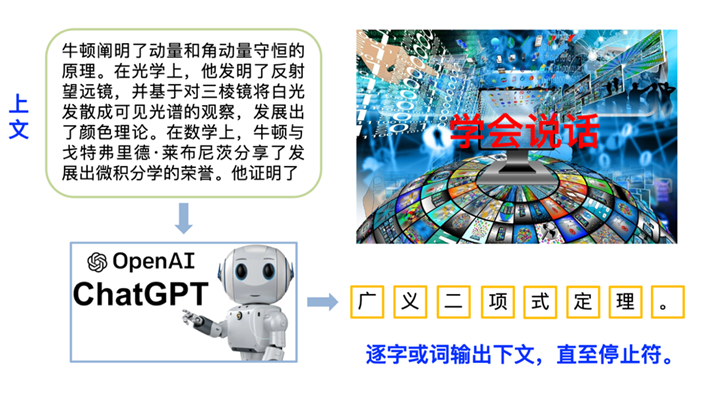
▲ 图2. 使用海量包含多种语言的文本训练语言模型
第二步提示精调“理解意图”:光会文字接龙肯定是不够的,最终目标是要用它来替我们干活的。所以这一步我们让模型统一以“给上文、补下文”方式来学习完成各种各样的任务。问答任务直接可以用“给上文(问题)、补下文(回答)”方式实现,但有些任务还需要在上文中加上提示(见图 3)。以翻译为例,除了告诉模型需要翻译的内容外,还要指示模型翻译成哪种目标语言。这一步提示学习完成之后,模型即已“博览群书”(第一步)而“胸有成竹”,又能“领会意图”(第二步)而“对答如流”,已经处于基本可用的状态了。
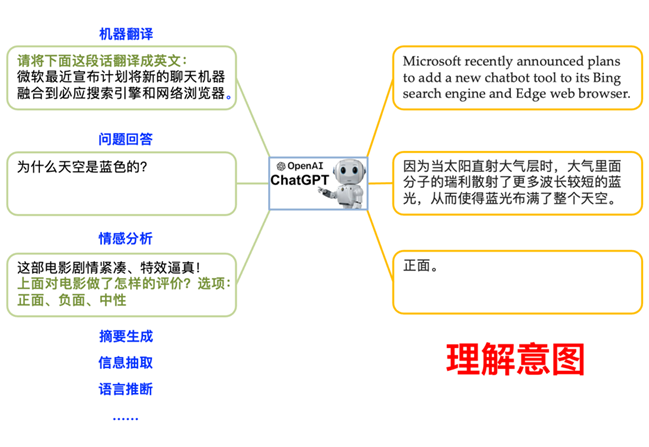
▲ 图3. 多任务提示学习让模型学会各种任务(绿色字体为提示语)
第三步强化学习“反馈择优”:对于某些问题,模型可能会生成带有偏见、歧视或者令人不适的回答。另外,之前提到过,对于同一个问题,模型能够生成多个不同的回答。这一步中我们让人们对同一问题的不同回答进行排序,然后采用强化学习算法(从交互中得到反馈,迭代优化模型的生成策略)进一步调整模型,使其输出更符合人们期望的回答,达到与人们期望对齐的效果(见图 4)。
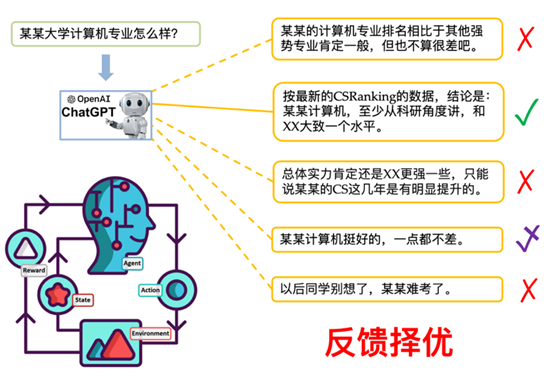
▲ 图4. 使用强化学习提高模型生成与人们期望相符回答的概率
经过以上学会说话、理解意图和反馈择优三个主要训练步骤,能够以自然语言对话方式完成各种任务的生成式大模型就构建出来了,之后当然还可以用领域数据或强化学习进一步对模型进行迭代精调。一般而言,模型的规模越大,能够存储和融合的信息和知识就越多,性能也就越好。

情景学习与思维链
用 ChatGPT 时,情景学习(In-context Learning)方法能够显著提高其回答的质量,它的原理其实也非常简单。比如:问一位年幼的孩子 4 乘以 5 等于多少,他可能答不上来。但你先告诉他:“1 乘以 5 等于 5;2 乘以 5 等于 10;3 乘以 5 等于 15。”接着再问他:“4 乘以 5 等于多少?”,他回答正确的可能性就增加了。同样,情景学习也是在提问前列举一些相似的例子作为输入喂给模型。
以影评的情感分析为例(见图 5),先给出三个影评及其情感极性(好评、中性和差评),然后让模型分析“看完后让人感慨万分,久久不能忘怀。”的极性。

▲ 图5. 影评情感分析中使用情景学习的例子
一般来讲,使用情景学习时,所给出的例子越多越好。这里有一个有趣的现象值得一提,测试表明在所给出的例子中标签(即图 5 中的“差评”、“中性”和“好评”)是否正确与性能关系不大。比如:我们将“主演表情作作、略显浮夸。”的标签改成“好评”,又将“这部电影叙事紧凑、特技一流。”的标签改成“差评”,并不会影响模型对于影评“看完后让人感慨万分,久久不能忘怀。”的分析结果。但是例子呈现的格式(图 5 为一则影评后跟相应的情感标签,中间以空格隔开)要与提问形式一致,并且文字内容要来自同一领域(图 5 中的例子不宜是餐馆或旅店评价的语句,因为问题是对电影评价的情感分析)。
我个人认为出现以上现象的原因是:ChatGPT 是一种集成了语言运用、语义理解和世界知识的模型。模型其实已经具备了回答所需要的知识,少量的例子并不足于改变模型对于问题的判断和回答,难点是如何引导模型准确提取出与问题相关的知识来。所以情景学习中的例子要来自同一领域,这有利于模型检索出回答问题所需的相关信息和知识。同时,以统一的格式呈现例子和问题,这有利于模型按格式规定的顺序依次生成回答。
思维链(Chain-of-Thought)可以看成是情景学习的扩展,它不仅给出例子及相应结果,还给出得到该结果的计算或推理步骤(见图 6)。本人猜想思维链有效的原因是给模型解题提供了一种模板或过程的指引,这种序列化的文本模板易于被生成模型所使用,它为生成较长内容的整体结构和中间步骤进行了预先的规划。这种模板也为模型在特定步骤上调取计算或推理所需知识提供了约束,从而引导模型得出正确的答案。

▲ 图6. 求解数学应用题时使用思维链的例子

修改提示语优化结果
提示语(本文第二节的第二步提到过)的好坏确实会影响 ChatGPT 的回答质量(情景学习和思维链都可以看成是特殊的提示),现在已经出现了提示工程(Prompt Engineering)这个研究方向和提示工程师这种职位。撰写好的提示语有两个基本原则:
(1)指令清晰并且具体;
(2)给模型思考的时间。
第一条原则比较好理解,一般不要担心指令写得过长。在没有冗余的情况下,宜长不宜短。第二条原则的意思是复杂问题不要让模型直接得出结论,而要详细指示所需步骤,然后让模型根据每一步得到的中间结果再给出最终的判断。比如:对于一道比较复杂的数学应用题,不要直接问某个答案是否正确。可以参考以下形式来写提示语:
第一步:先求解这道数学应用题;
第二步:将求解出的答案与给出的答案进行比较;
第三步:根据比较的结果,回答给出的答案是否正确。
如果以 API 方式批量调用 ChatGPT 的话,这里提醒一个小技巧。可以指示 ChatGPT 以 JSON、HTML 等结构化形式返回结果,以方便提取所需的内容。
最近斯坦福大学的 Andrew Ng 和 OpenAI 的 Isa Fulford 联合出了个 “ChatGPT Prompt Engineering for Developers” 的免费短课,值得听一下。课程的网络链接是:
https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/

能力评估和注意问题
2022 年 11 月所推出的 ChatGPT 已经非常可怕了,OpenAI 公司又于 2023 年 3 月推出比 ChatGPT 更为强大的 GPT-4,并且还开始支持网页搜索、图片生成、计算器等插件(Plugins),使其能够在必要时调用插件来提高解决问题的能力。
ChatGPT 在没有针对医学知识精调和强化的情况下,在美国医学执照考试的三个部分中达到或接近通过的门槛。Google 公司对 ChatGPT 进行了程序员招聘面试,结果其编程能力可匹敌一位三级水平的软件工程师,每年攒得工资可达 18.3 万美元。
ChatGPT 还在 MBA 核心课程《运营管理》的期末考试中的基本运营管理和流程分析方面表现出色,不仅答案正确,而且能给出合理的解释。 我们近期借助认知心理学习方面的理论对 ChatGPT 认知能力进行了评测,它在词汇的任务上表现相对出色,与英语母语的 16 岁左右高中生的认知能力相当,但逻辑推理和数字处理方面的能力相对较弱,相当于 10 岁左右的小学生水平,整体表现文强理弱。
ChatGPT 和 GPT-4 等本质上是能够执行生成任务的机器学习模型,其天生会存在或衍生出以下一些问题:
(1)“幻觉”问题,即生成看起来似乎可信,但不准确或虚假的信息;
(2)容易生成带有偏见、歧视和不符合伦理内容;
(3)某些任务的返回结果受提示词的影响较大;
(4)缺乏及时更新信息和知识的方法(使用网页搜索插件会有所缓解);
(5)使用和交互时可能会泄露个人的隐私;
((6)可能被某些人滥用来制造虚假信息和内容等。

构建与训练类ChatGPT模型
第一步:语言模型
语言模型就是给定任意上文的情况下,预测下一个字或词(实际是 Token)的模型。模型结构一般选择 Transformer 结构的人工神经网络 [1](建议从 Hugging Face 上获取代码)。这一步需要考虑的主要设计因素包括:
(1)上下文建模的长度(从几千到几万个 Token 不等);
(2)模型参数的规模(从数十亿到数千亿不等);
(3)词表的大小和 Tokenization 方法(至少应包括中英文的字或词)。
一般在硬件条件宽裕和训练数据充分的情况下,能处理的上下文越长,模型的参数越多,模型性能也就越好。Tokenization 是将较长的、并且不常用的单词拆分成 Token,比如将 “Misunderstood” 拆成 “mis + under + stood” 三个部分,这样可以大幅减少词表的大小,同时也减少存储词向量所需要的参数数量,还能让模型在词表大小相近的情况下能够包括和处理更多种的人类语言。
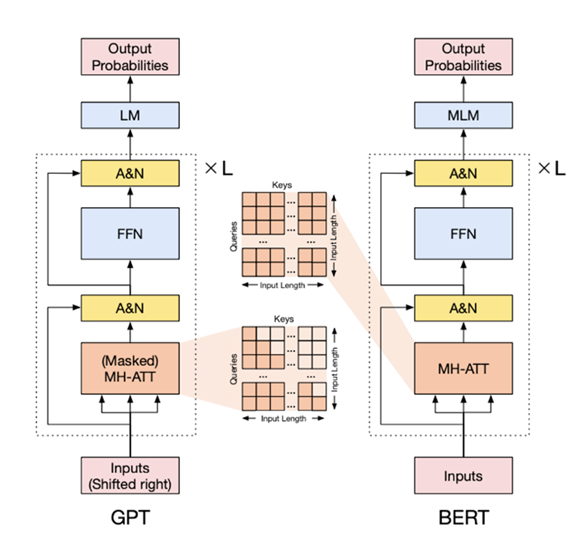
▲ 图7. GPT 采用左侧所示的单向注意力(只计算注意力矩阵下对角线部分),而 BERT 采用右侧所示的双向注意力机制 [3]。
Transformer 作为编码器(Encoder)和解码器(Decoder)使用时计算注意力方式略有不同,前者使用双向注意力(即文本中每个词的上下文相关表示会受到其前后词的影响),而后者采用单向注意力(即文本中每个词的上下文相关表示仅受其前文的影响)。其实双向和单向注意力都可以使用,但是构建 ChatGPT 选用了基于 Transformer 的解码器(如图 7 所示)。除了单向注意力计算代价较小外,文献 [2] 表明使用单向注意力对于下一个 Token 预测(语言模型)和零样本学习(Zero-Shot Learning)上表现更佳。不过双向注意力在填空等任务上表现更好。我们猜想类 ChatGPT 模型在信息抽取方面性能欠佳的原因可能是没有使用双向注意力机制,从而导致实体抽取时较难预测右侧边界(只融合了前文的语义信息)。
这一步的训练目标比较简单,就是给定任意前文,让模型预测下一个 Token。给定任意包含 个 Token 的文本 其损失函数为:
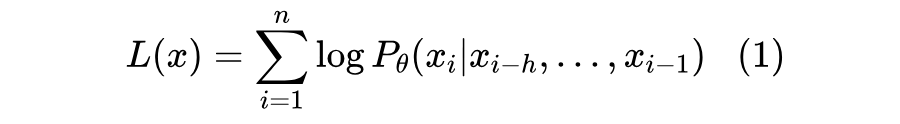
其中: 为最大的上下文建模长度, 是可调的网络参数。这一步骤过程中,训练技巧对语言模型最终效果影响并不是很显著。一般批次大小(Batch Size)开大一些,学习率(Learning Rate)选小一些,使用恒定学习率和 Adamw 优化器都可以,遍历一两个 Epoch 基本就结束了。关键是训练语料的收集和清洗,以及合理设置它们之间的比重。Facebook 的 LLaMA 采用了以下语料用于预训练语言模型 [4]:
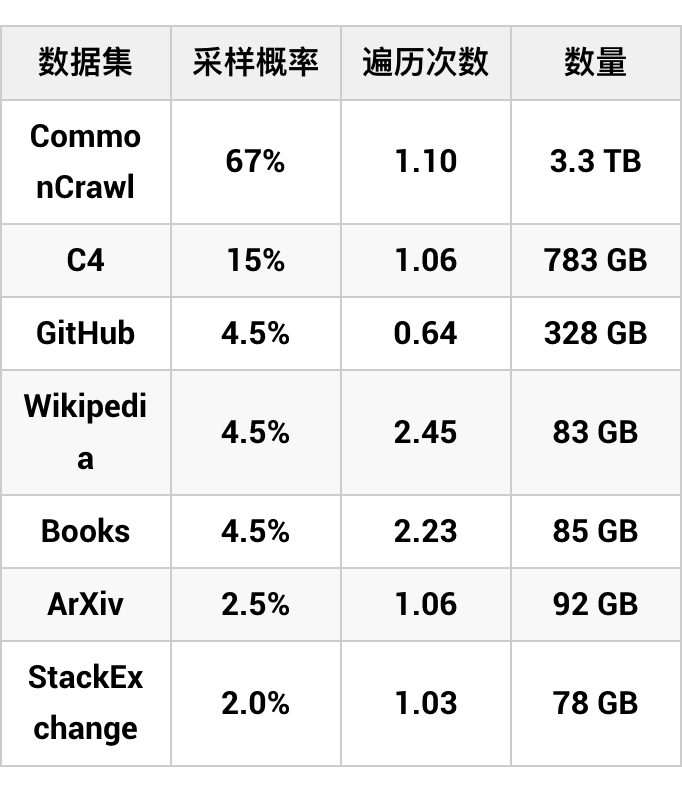
▲ 表1. LLaMA 预训练阶段所采用的文本语料 [4]
从表 1 可以看出,如 Wikipedia 和 Books 这些比较高质量的文本语料的遍历次数(Epoch)会多一些。如果希望增强中文处理能力,需要适当增加一些高质量的中文语料。训练时除了使用海量文本,还会包括大量的代码(就当普通文本一样处理)。一般认为代码有助于提高模型的“逻辑推理”能力,因为代码实现的算法就是对求解问题所需逻辑步骤的描述。语料的清洗至少要包括除劣、去重和脱敏三个步骤(可能的话,也设法删除带有偏见或歧视的语料)。
第二步:提示精调
多任务提示(或指令)精调的目标是使用各种任务相关数据集对第一步预训练后的语言模型进一步调整,使其能够理解指令并完成既定的任务。这一步的重点落在“精调”两字。因为经过第一步预训练,模型已经“看过”几乎所有能从各种渠道获得的文字、代码和图书资源,通过“博学强记”,模型将关于语言和世界知识都“压缩”到了上亿个参数中去了。提示精调这一步只需要在此基础上将模型稍微引向更恰当的输出结果。
如果将第一步预训练得到的模型能力看成如图 8 所示的大江,完成各种任务的能力就是从这条大江所衍生出来的支流。这些支流不能过长,也不能过粗,不然会产生对该支流(代表某个具体任务)的过拟合,从而导致模型整体泛化能力下降,影响完成其它任务的性能。同理,一般也不能只单独对一个任务进行精调,因为所有模型参数都会向优化这个任务的方向而调整(生成式语言大规模是为了多任务而生的),容易陷入不太好的局部最小值。
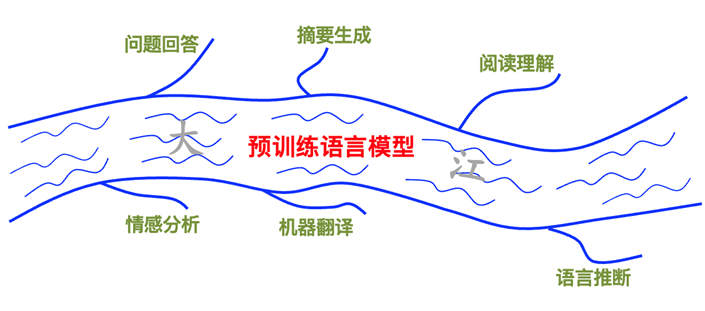
▲ 图8. 将预训练语言模型所具备的能力比作大江,各种任务能力就是通过精调从这条大江所细分出来的支流。
与第一步相似,提示精调也统一采用“给上文、补下文”方式训练各种任务。问答任务直接可以用“给上文(问题)、补下文(回答)”方式实现,但有些任务还需要在上文中加上提示。以翻译为例,除了告诉模型需要翻译的内容外,还要指示模型翻译成哪种目标语言(如图 3 绿色文字所示)。
每一个训练样本一般如图 9 所示,这一步的损失函数仍然用公式 ,但一般仅对“回答”部分计算误差。由于一般最终以对话方式来使用生式成语言大模型,所以建议将各种任务的训练样本都表示成多轮对话的形式,此时需要以特殊符号来分隔提示和各角色表述的内容。
此外,每一种任务需要多准备一些提示语(准备样本时随机选择其一与样本进行组合),让模型知晓同一意图有多种不同的表达方式,从而更好地“领会意图”(实际使用时会遇到各种各样的提问方式)。文献 [5] 附录中列出了多种任务的不同提示语,可供参考。

▲ 图9. 提示学习的样本表示形式
OpenAI 公司研究者所撰写的论文 [6] 中列出了他们在提示精调阶段所选择的任务及其比例(如表 2 所示)。构建垂直领域大模型时,一般先要做好需求调研,然后为满足各项需求准备精调阶段的训练样本(注意:精调阶段样本质量的重要性要高于样本的数量),并且根据需求重要性(与表 2 列出任务的训练数据合并后)合理确定各种任务训练样本的数量和比重。
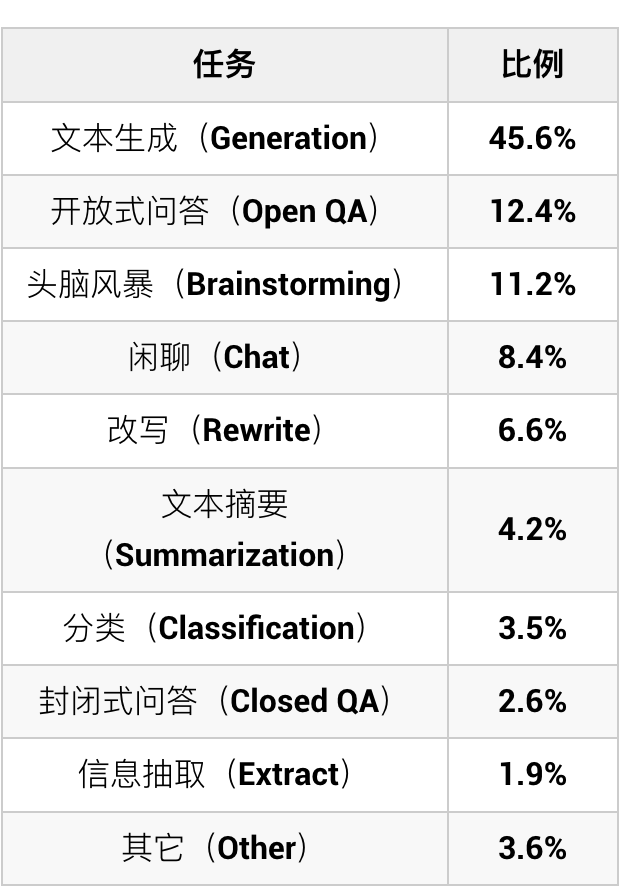
▲ 表2. 文献 [6] 提示精调阶段所选择的任务及其所占比例
文献 [7] 研究表明大规模语言模型会使用“工具”(其实类似调用第三方 API)。如果需求调研表明完成某些业务需要调用第三方 API,在精调阶段准备训练样本时也要提前考虑。以问答时需要实时访问数据库为例,可以在回答中插入类似 <<< SELECT price FROM table WHERE item = 'apple' >>> 语句。检测到回答中有类似的数据库查询语句时,就提取出来执行,然后将执行结果替换该语句即可。
更加通用的方式是定义能够转换成各种第三方 API 调用的形式化表示(由于在第一步预训练阶段使用了大量代码语料,经过精调之后模型处理形式化表示的能力还是比较强的)。此外,精调阶段加入使用思维链(Chain-of-Thought)的样本能够大幅提升推理时运用思维链方法的性能 [8](同时不会影响其他任务的性能),所以也可以根据需要在精调阶段就加入这样的训练样本。
第三步:强化学习
很多情况下,相同的上文(或前文),可以有多个不同的下文,所以模型输出实际上是不同字或词(实际是 Token)概率分布。基于这些概率分布,使用随机采样方法就可以为同一个上文生成不同的下文,这种能力对于 ChatGPT 这种聊天和对话模型非常有用,因为它可以带来回答的多样性。也是因为这种对于相同问题能够生成多个不同回答的能力使 ChatGPT 既可能生成好的回答,也可能生成不太好(甚至坏)的回答。
此外,对于某些问题,模型可能会生成带有偏见、歧视或者令人感到不适的回答。为了让模型偏向生成更符合人们期望的好回答,ChatGPT 训练时采用强化学习(利用人类反馈来迭代优化模型的生成策略)进一步调整模型。在此过程中我们要解决两个问题:一是如何获得人们的期望或偏好;二是如何利用所获得的期望或偏好信息来引导模型生成更好的回答(其实质是提高模型生成符合人们期望内容的概率)。
对于如何获得人们的期望或偏好,其方法就是构建奖励模型(Reward Model)。将第二步提示精调后所得到的模型记为 ,我们让模型 对同一问题生成多个回答,然后让标注人员对于这些回答进行排序,排序结果就体现了人们对于回答的偏好。如此,我们可以收集许多模型 所生成的回答对 <, >,其中 是相对好的回答, 则是相对坏的回答。
对奖励模型 (会用模型 的参数初始化)进行训练时,我们让模型 预测回答 和 每一个 token 的得分(通过增加一个线性层),其训练目标是要让好回答 的得分高于坏回答 的得分。具体的训练目标是让在每个对应 token 上 和 的得分之差(如图 10 所示的红色分差数值)高于设定阈值。
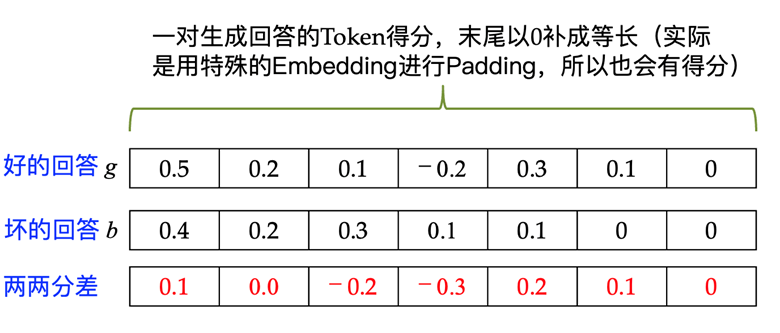
▲ 图10. 同一问题好回答 (长度为 6)与坏回答 (长度为5)每一对应位置 Token 得分差高于设定阈值为目标来训练奖励模型
通过上述目标训练所得到的奖励模型 实际上能够对生成回答的每一个 Token 得分进行评估,我们之后将会用模型 的参数来初始化强化学习所需要的价值函数(或模型)。在此之前,我们先用以下情感分析的例子解释为什么这样训练是有效的。这其实是一个半监督学习的过程,即从句子级别的人工标注信息学习到每一个 Token 的得分或贡献。
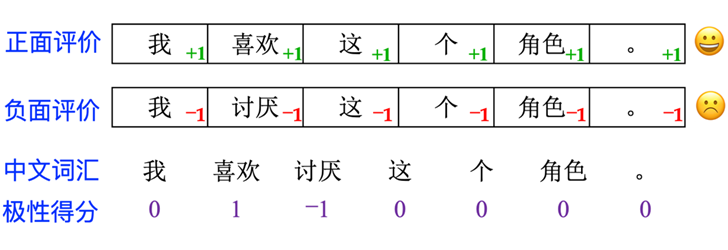
▲ 图11. 表达正面情感句子中所有词都加 1 分,而表达负面情感句子中所有词都减 1 分,当有一定数量句子级别的情感倾向语料,根据每个词的最终得分(图中最后一排数值)就可以获得其情感极性。
以如图 11 的情感分析为例,我们有句子级别情感倾向的人工标注结果,但希望从中得到词汇的情感极性。最简单的做法是对于表达正向情感句子中的所有词都加 1 分,而对于表达负面情感句子中出现的所有词都减 1 分。当有一定数量这种人工标注的句子,根据句子情感倾向对所包含词进行简单的加 1 和减 1 操作就能够得到词级别的情感极性。最后得分越高的词的情感极性越正面,而得分越低的词的情感极性越负面,得分比较接近与 0 的词则是中性词。同理,从大量人工排序后的成对回答中,我们也可以类似学习到每一个 token 得分的近似估计。
训练得到奖励模型 之后,我们就可以开始强化学习了。强化学习有离线(Offline)和在线(Online)两种学习方式。与人类学习一样,我们可以旁观者身份,通过观察别人的行为及其结果来学习相关的经验和教训,也可以自己亲身在环境中体验和行动,然后从行为的结果或环境的反馈中获得经验和教训,进而不断增强自身的能力。同样地,模型可以通过观察其它模型的行为及结果来学习(离线学习),也可以自身不断与环境互动来进行学习(在线学习)。
ChatGPT 训练时选择用离线学习来与人类期望进行对齐,原因是模型在强化学习过程中会不断调整参数,从而改变生成内容的分布,而奖励模型 则是用精调后模型 生成的回答来训练的,因而用于评价模型 生成内容时比较可靠。所以在强化学习阶段,我们优化和调整的是新的模型 (虽然也会用模型 的参数初始化),而它观察的对象则是模型 ,即模型 从模型的行为及反馈中学习。注意模型 和 建模的都是根据上文 输出下一个 token(记为 )的概率,其中 为当前上文(或前文)的长度。
在强化学习中,Actor-Critic(行动者-评论家)是一种常见的框架,其主要的优点是通过引入价值函数来减小策略优化的方差,从而提高学习的稳定性和效率。对 ChatGPT 的强化学习也采用了 Actor-Critic 框架,其中 Actor 就是模型 (但通过代理模型 M 与环境交互),而 Critic 则需要引入另一个新的模型 (用奖励模型R的参数初始化)。模型 就是价值函数,它能对于任何状态 (包含了部分生成内容的上文)给出评分 ,价值函数或模型 V 也要在强化学习过程中不断调整,从而能够更准确地对生成内容的质量进行评价。
综上所述,强化学习过程中有四个不同的模型(都是深度网络):奖励模型 、价值函数 、代理模型 和目标模型 (训练的最终目标)。我们希望优化的是生成策略 ,即给定上文 时模型 输出下一个更好 的概率。为此,我们需要估算输出 较其它可选 Token 的优劣(即带来未来收益或得分的变化)。当前状态 下输出 可能带来的优势记为优势函数 。这种对于未来收益或得分的变化,我们可以向前看一步方式来估计:
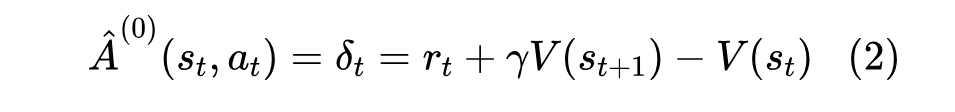
其中: 为当前状态 下输出 后即刻得到的收益, 为输出 后转入新状态 时价值函数的估计值, 则是对于未来收益的折扣系数( 之间的一个值,一般训练类 ChatGPT 模型时就设为 1 了)。对于 ,除了生成完整回答的最后一个 Token 有值外(这个值由奖励模型 R 给出),其它 一般都为 ,因为完整回答生成后才会得到奖励(人类反馈),奖励模型 R 对完整回答所给出的评分也相对更为准确。我们也可以向前看两步或三步来估计这种变化:
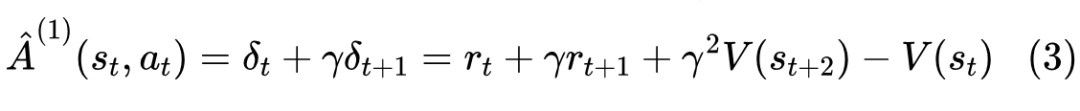
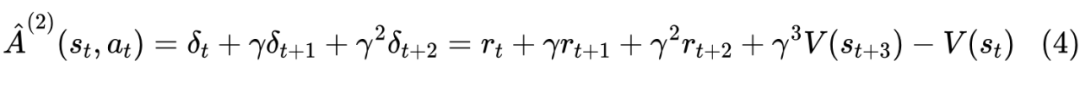
如果一直看到回答完全生成,则就是蒙特卡罗方法(Monte Carlo Method),如果仅向前看若干步就是时间差分学习(Temporal Difference Learning)。向前看一步是 TD(0),看两步是 TD(1),看三步是 TD(2),以此类推。Eligibility Traces 方法理论上统一了蒙特卡罗方法和时间差分学习。
该方法引入一个新的系数 ,当 时就是用蒙特卡罗方法,而 时则是 TD(0),取 之间的值时则介于两种极端之间。使用 Eligibility Traces 方法的优点是只要尝试和调整超参 的取值就好了(一般 设成较接近于 ),用此方法进行 估计公式为:
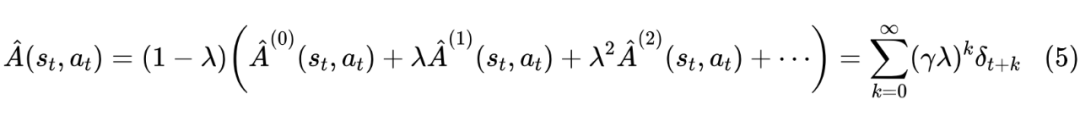
其中 取值从 到 是公式 推导过程中使 收敛到 的条件,实际训练过程中, 的最大取值由生成回答的长度确定。
此前我们提到预训练后的模型能力可以看成如图 2 所示的大江,完成各种任务的能力就是从这条大江所衍生出来的支流。为了防止强化学习过程中模型过于偏离这条“大江”,我们要加一个惩罚项,这个惩罚项是 和 之间的 KL 散度(Kullback-Leibler Divergence),它量化了从 到 的信息损失,或者用 来近似 时引入的误差,其实就是让 的分布不要离 太远。具体做法是在 中多包含以下一项:
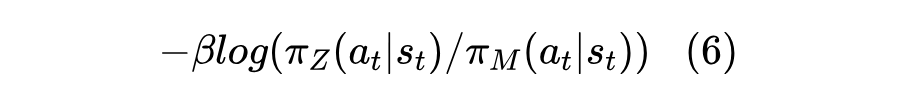
其中参数 控制施加这个惩罚项的强度。因为 KL 散度总是非负的,实际相当于在当前收益 中加上公式 计算得到的数值(前有负号,一定是负数)。
于我们采用离线强化学习,优化目标是模型 ,但训练样本则是由代理模型 生成的。即样本是从模型 采样出来的,但样本实际分布应该是由模型 确定。这时需要使用如图 12 所示的重要性采样方法,重要性采样比率越大,说明从 采出的分布越接近希望采样的分布 ,则这个样本的重要性就越高,模型调整的力度也就是越大。
优势函数 的值乘以这个重要性采样比率就会作为调整模型 在 状态时输出 概率增加或减少的误差。PPO(Proximal Policy Optimization)算法 [9] 其实只是对重要性采样比率进行了裁剪(Clip),即当 为正时,将重要性采样比率裁剪到 以下,当 为负时,将重要性采样比率裁剪到 以上(原文推荐 设为 ),目的也是为了让训练过程更加稳定。
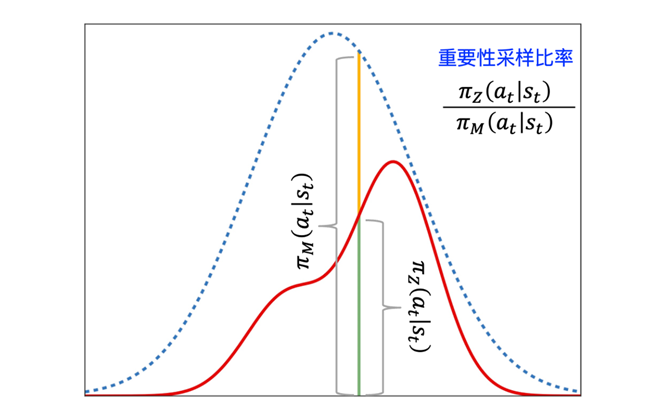
▲ 图12. 重要性采样比率计算方法
当不断优化模型 时,我们还会持续调整价值函数 ,使其对于状态的评分越来越准确。价值函数 V 调整方法比较简单,就是让 与新的估计 接近,即减少两者之间的 L2 平方损失(Squared Loss)。此时, 表示当前的样本对于 估计的增减变化。如图 13 所示,目标模型 Z 和价值函数 V 是迭代优化的过程,最终收敛到某个稳定状态。
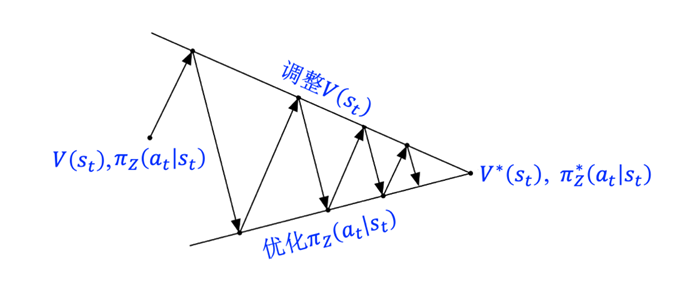
▲ 图13. 目标模型 Z 和价值函数 V 迭代优化过程的示意图
以上介绍了 ChatGPT 三个主要训练步骤:语言模型、提示精调和强化学习。其中第三步强化学习实施起来相对比较困难。除了强化学习本身对于初始值和超参设置比较敏感外,其间一般需要多次人工标注。因为目标模型 Z 经过多次调整和优化之后,之前获得的奖励模型 已经不再适用于模型 Z 生成内容的评价了(因为生成内容的分布已经发生了变化),所以还有较大的改进空间。
作者简介
郑骁庆
复旦大学计算机科学技术学院副教授、博士生导师,美国麻省理工学院 International Faculty Fellow,加州大学洛杉矶分校访问学者,主要研究方向为自然语言处理和机器学习,在 Computational Linguistics、NeurIPS、ICLR、ACL、AAAI、IJCAI、EMNLP、WWW、T-ASL 等自然语言处理和人工智能领域的顶级国际会议和期刊发表论文 50 余篇。

参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. Attention is All you Need. In the Proceedings of the International Conference on Neural Information Processing Systems (NIPS’17), 2017.
[2] Mikel Artetxe, Jingfei Du, Naman Goyal, Luke Zettlemoyer, Ves Stoyanov. On the Role of Bidirectionality in Language Model Pre-Training. In the Findings of the Conference on Empirical Methods in Natural Language Processing (EMNLP’22), 2022.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In the Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL’18), 2018.
[4] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971, 2023.
[5] Victor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Tali Bers, Stella Biderman, Leo Gao, Thomas Wolf, Alexander M. Rush. Multitask Prompted Training Enables Zero-Shot Task Generalization. arXiv:2110.08207, 2021.
[6] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. Training language models to follow instructions with human feedback. In the Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS’22), 2022.
[7] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761, 2023.
[8] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, Jason Wei. Scaling Instruction-Finetuned Language Models. arXiv:2210.11416, 2022.
[9] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov. Proximal Policy Optimization Algorithms. arXiv:1707.06347, 2017.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

