
- 1利用LightHouse进行合理的页面性能优化,看这一篇就够了!_enable text compression
- 2jquery——get方法解析xml文件和json文件和getjson_jquery xml get
- 3【雕爷学编程】Arduino动手做(27)---BMP280温湿度气压传感器模块2_gy-bmp 280
- 4Android常用屏幕适配方式_linearlayout布局适配
- 5HAProxy+Nginx 负载均衡_haporxy 代理nginx 版本低安全漏洞
- 6adb 指定设备调用命令_adb shell 某个设备执行命令
- 7偶遇ARJ,释放DOS时代记忆~_arj压缩软件dos
- 8adb logcat命令_adb logcat | findstr
- 9小白NLP入门,pyhanlp安装以及初步调试_pyhanlp miniconda 安装pyhanlp
- 10脑电公开数据集汇总
深度学习AI美颜系列---图像自动亮度对比度与调色_自动检测形成最佳调色参数
赞
踩
在人像美颜的拍照界面,往往由于光线和环境因素的影响,导致我们拍出的照片质量较差,包括噪声多,曝光度过低等等问题,因此,大多数相机应用都会在Camera界面添加一定的图片预处理,比如自动亮度对比度调整,降噪,调色等等。今天我们要说的是自动亮度对比度和调色问题。
对于自动亮度对比度的调节,主要分为了传统算法和基于深度学习的智能算法两类,我们先对目前算法做一个概述:
传统算法:
传统的算法一般主要以视网膜增强算法(Retinex)、基于局部直方图信息的增强算法为主,对应的论文举例如下:
视网膜增强算法举例:
Multi-Scale Retinex for Color Image Enhancement
A Multiscale Retinex for Bridging the Gap Between Color Images and the Human Observation of Scenes
基于局部直方图信息增强算法举例:
Real-Time Adaptive Contrast Enhancement
除了上述两种方法思路之外,2012年微软研究院出了一篇个人认为效果还不错的论文:
Automatic Exposure Correction of Consumer Photographs
据说微软的“微软自拍app”用的就是这个算法,对应效果如下:

传统算法对于这个问题的研究已经有几十年的时间,这期间积累了大量的论文资料,这里我们不在仔细说明,由于传统算法始终无法对各种情况和各种图像内容进行自动分析和自适应,因此,效果上依然存在很大问题。
AI算法:
基于深度学习的自动亮度对比度调节算法是近些年的热点,2019年最新的论文是腾讯的一篇论文:
Underexposed Photo Enhancement using Deep Illumination Estimation
论文的测试DEMO github地址:https://github.com/wangruixing/DeepUPE
对应效果如下:

论文参考了谷歌HDRNet中的部分原理,比如双边滤波网格部分等等,如下图所示:

这篇论文效果很惊艳,但是目前为止,本人还没有跑通DEMO,实际测试中存在各种问题,github中也没有朋友复现出来,很可惜。
上述总结,只是本人挑选的一部分内容所做的概述,下面来看本文重点内容。
本文目的是图像自动亮度对比度和调色算法,我们给出两种可行思路:
1,美图自动亮度对比度调节算法
该算法来自美图秀秀专利信息,算法流程如下:
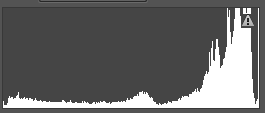
①根据直方图分布信息,将图像划分为以下几类:高光类,高光-中间调类,中间调类,中间调-阴影类,阴影类,高光-阴影类,直方图表示举例如下:

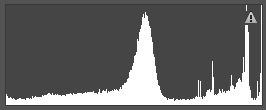
阴影类 高光-中间调类 高光类
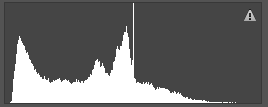
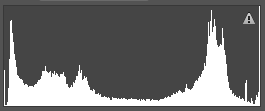

阴影-中间调类 高光-阴影类 中间调类
②准备样本数据集,人工将数据集按照①中六类标准划分类别;
③指定亮度对比度调节公式,如下所示:
C=(100+contrast)/100, contrast范围[-100,100]
brightness+=128
cTable[i] = max(0,min(255,((i-128)*c+brightness+0.5)))
对于灰度级Gray的像素,亮度对比度调节后的结果值为:cTable[Gray]
④使用③中公式,将样本集中的样本进行人工亮度对比度调节,默认调到人工视觉最佳为止,然后记录对应的亮度对比度数值,存入数据库中,至此完成数据样本准备工作;
⑤构建一个简单的CNN分类网络,输入任意一张图像,输出对应的分类标签,共6类,对应①中6种情况;
⑥使用CNN对数据样本进行训练,根据训练结果进行验证,并计算样本集种的误差,然后调节网络参数,调节数据集中被错分的图像亮度对比度数值并检测标签是否错分,再次训练,依次反复,知道精确度小于某个阈值为止;
⑦使用训练模型对任意一张输入照片进行分类,根据分类找到对应类别数据集,使用直方图相似性来寻找数据集中最相似的样本,并找到该样本对应的亮度对比度数值;
⑧根据亮度对比度数值对输入照片进行亮度对比度调节,得到最终效果图。
上述过程就是美图的自动亮度对比度调节方案,理论上先分类,然后找到样本中直方图分布与其最接近的样本,按照样本的亮度对比度数值对输入照片进行调节,算法是可行的,而且,分类网络的速度是比较快的。由于样本问题,本人只进行了理论分析,给大家提供一种思路,当然,这种方法只能对图像进行亮度对比度调节,不能进行颜色调节。
2,端到端网络训练
本人使用了另一种方法,直接使用CNN对样本数据进行训练,得到最终的调节效果。本人使用Photo lemur3软件来得到样本数据,这个软件是国外一款基于深度学习算法开发的图像自动调节软件,可以对图像进行亮度对比度和调色处理。本人算法如下:
①使用Photolemur 3对300张样本进行处理,得到300张样本数据集,当然数据集比较少,这里仅做可行性测试;
②使用UNet网络对图像进行端到端的训练,使用adam优化器,mse loss,迭代500次,效果如图所示:



Unet的网络模型如下:
- def unet(input_size = (256,256,3)):
- inputs = Input(input_size)
- conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs)
- conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1)
- pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
- conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1)
- conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2)
- pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
- conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2)
- conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3)
- pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
- conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
- conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
- drop4 = Dropout(0.5)(conv4)
- pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
-
- conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
- conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
- drop5 = Dropout(0.5)(conv5)
-
- up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
- merge6 = merge([drop4,up6], mode = 'concat', concat_axis = 3)
- conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
- conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
-
- up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
- merge7 = merge([conv3,up7], mode = 'concat', concat_axis = 3)
- conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)
- conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)
-
- up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
- merge8 = merge([conv2,up8], mode = 'concat', concat_axis = 3)
- conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)
- conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)
-
- up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
- merge9 = merge([conv1,up9], mode = 'concat', concat_axis = 3)
- conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)
- conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
- conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
-
- res = Conv2D(3, (1, 1), activation=None)(conv9)
- model = Model(input = inputs, output = res)
- #model.compile(optimizer = Adam(lr = 1e-4), loss = 'mse', metrics = ['accuracy'])
- return model

上述方法思路比较简单,但是如果直接使用上述思路,虽然可以得到一定的效果,实时处理确实非常困难,正如HDRNet一样,也比较难以实时处理,尤其是不适用GPU的情况下实时处理。如何在CPU模式下,应用到camera实时预览中去,本人做了如下修改:
①优化网络模型,修改Unet,为了减少计算量和复杂度,可以减少通道数,减少网络层数,使用深度可分离卷积替代普通卷积等,最终本人的模型大小为9K,参数600多个,速度在PC端CPU模式下,使用MNN推理引擎,达到3ms,在终端android手机上测试可达到7.5ms,基本满足实时处理的需要,当然,图像大小为256×256;
②如何将256×256的小图效果转换为原图效果,这里我们可以直接输入原图来得到效果图,但是这种方式速度太慢,无法达到实时需求,因此,本人使用了颜色迁移算法,直接将小图颜色迁移到大图上,为此完成了此项工作。
上述两种思路就是本文的内容,抛砖引玉吧!

