
- 1深度学习数据集制作_一篇文章搞定人工智能之深度学习创建训练数据集的方法
- 2list转树形,亲测可用
- 3大模型从入门到应用——LangChain:提示(Prompts)-[提示模板:基础知识]_大模型有官方prompt吗,叫什么
- 4人工智能如何帮助项目经理做出更好的决策_ai项目经理
- 5自动化测试 java调用adb命令_java 可以调用adb指令吗
- 6MacOS代理设置(桌面应用代理设置&Terminal代理设置)
- 7Joint European Conference on Machine Learning and Knowledge Discovery in Databases(ECML-PKDD)会议怎么样?
- 8NLP学习(5) 语言模型_nlp 模型如何做判断
- 9Vision Transformer代码
- 10扩散模型基础(一):基于BasicUNet的扩散模型算法搭建_扩散模型 unet
【网安AIGC专题10.19】论文6(顶会ISSTA 2023):提出新Java漏洞自动修复数据集:数据集 VJBench+大语言模型、APR技术+代码转换方法+LLM和DL-APR模型的挑战与机会_大模型漏洞修复
赞
踩
How Effective Are Neural Networks for Fixing Security Vulnerabilities
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
ISSTA 2023
How Effective Are Neural Networks for Fixing Security Vulnerabilities
论文地址:https://dl.acm.org/doi/10.1145/3597926.3598135
github代码:https://github.com/lin-tan/llm-vul
评测现有的大模型和基于深度学习的自动补丁修复模型对Java漏洞修复能力的工作
论文很长很系统,学姐读的很细节很深入
摘要
安全漏洞修复的两种方向
(1)LLM,已对源代码预训练,用于代码补全等任务
(2)基于深度学习的自动程序修复APR
贡献
【注意】没有构建一种自动java漏洞的技术
(1)提出数据集,并对当前工作进行测量
(2)设计代码转换,以解决训练和测试数据重叠对codex的威胁
(3)创建了新的Java漏洞修复基准VJBench及其转换版本VJBench-trans,以更好的评估
(4)评估
数据集上创建两个benchmark
通过代码转换,来减轻llm和黑盒codex训练数据中可以看到评估数据的威胁
发现
比较DL和LLMs,更多数据vs数据格式匹配
对更多数据加微调vs数据格式匹配
微调的有效性
我们的发现包括:
(1)现有的llm和APR模型修复的Java漏洞很少。Codex修复了10.2个(20.4%),漏洞数量最多。很多生成的补丁都是无法编译的补丁。
(2)利用一般APR数据进行微调,提高了llm修复漏洞的能力。
(3)新VJBench揭示了llm和APR模型无法修复许多常见弱点枚举(CWE)类型,例如CWE-325缺失加密步骤和CWE-444 HTTP请求走私。
(4)Codex修复了8.3个转换漏洞,优于所有其他llm
介绍
背景:漏洞修复需求和Java漏洞修复方向
1)漏洞修复的需求
- 及时性: 平均修复漏洞的时间(从发现到修复)应在60到79天之间。强调了及时应对漏洞的重要性,以降低潜在的安全风险。
- 完整性: 修复的漏洞修复必须被证明是充分有效的,不能存在后续漏洞。
2)Java漏洞修复方向需求
- 广泛的应用范围: Java广泛用于关键服务器应用,包括Web服务器和服务。这使得Java漏洞修复至关重要,涉及敏感数据和关键功能。
- 缺乏Java漏洞修复工作: 目前,大多数漏洞数据集和修复方案主要关注C/C++和二进制文件,Java领域存在漏洞修复的机会和需求。
- 难以迁移的其他语言解决方案: 例如,C/C++中最常见的漏洞类型是缓冲区溢出,但Java被设计成一种类型安全的语言,以避免此类漏洞,因此需要特殊的漏洞修复策略和工具。
动机
基于深度学习的自动程序修复技术 (APR) 和 LLM (预训练语言模型) 在Java漏洞修复方面的比较研究
- 基于深度学习的自动程序修复技术 (APR)
- 通过学习程序中的缺陷和相应的修复方法。
- LLM(预训练的语言模型)的应用于源代码
- 预训练的LLM在修复通用Java漏洞方面表现有竞争力。
- 本文工作:
- 不是构建一种自动修复Java漏洞的技术。
- 研究和比较两种技术类型:基于深度学习的自动程序修复和LLM,以探讨自动修复Java安全漏洞的可能性和适用性。
- 比较基于深度学习的APR技术和LLM修复Java漏洞的能力。
- LLM vs DL based APR:
- 问题是在更多的数据和数据格式匹配之间进行比较。
- 哪种方法更有效?更多的数据胜出还是数据格式匹配更为关键?
- Fine-tuned LLM vs DL based APR:
- 比较对更多数据进行微调和数据格式匹配的有效性。
- 这两种方法哪种更为有效?微调的LLM是否胜出?
这篇文章旨在比较两种不同的方法来自动修复Java漏洞,其中一种是基于深度学习的自动程序修复技术,另一种是使用预训练的语言模型(LLM)。
研究旨在探索:
1、哪种方法在不同条件下更为有效,是更多数据的支持更关键,还是数据格式匹配更为关键,
2、以及微调LLM是否有竞争力。
3、有助于指导未来的自动程序修复研究和实践。
方法
第一次开展评估和比较APR技术和LLM修复Java漏洞的能力的实验
这是一项初次评估和比较基于深度学习的自动程序修复技术(APR)和预训练语言模型(LLM)在Java漏洞修复方面的实验研究。在此过程中,出现了两个关键挑战:
-
数据集问题:
- Benchmark稀缺: 可用于评估的Benchmark数据集相对有限。
- Vul4J: 包含79个可重现的Java漏洞,但它们只涵盖了25个CWE(常见弱点枚举)类别。
- 不均衡: 数据集中60%的CWEs(15种漏洞类型)仅具有一个可重现的漏洞示例。
-
评估有效性问题:
- Codex训练集未公布: 缺乏Codex的训练数据的公开性,难以确定Vul4J和VJBench中的漏洞是否已经包含在Codex的训练数据中。
为了解决这些挑战,提出了以下解决方案:
-
构建新的Benchmark: 建议构建一个新的Benchmark数据集,以更全面地评估和比较APR技术和LLM在Java漏洞修复中的性能。这将有助于覆盖更多的CWE类别,并减轻现有数据集的不均衡性。
-
使用代码转换生成新的保留漏洞的等效程序: 另一个解决方案是通过对已有的漏洞程序进行代码转换,生成新的包含相同漏洞类型的等效程序。这将扩大可用于评估的数据集,同时也有助于解决评估有效性问题。
这些解决方案将有助于更全面和准确地评估APR技术和LLM在Java漏洞修复方面的能力。
贡献
实验结果关于LLM、Fine-tuned LLM和APR技术在Java漏洞修复能力的结论
实验初次评估了5个LLM、4个Fine-tuned LLM和4个APR技术在两个Benchmark数据集(Vul4J和VJBench)上对真实Java漏洞的修复能力,得出以下结论:
-
LLM和APR技术修复能力有限: 现有的LLM和APR技术修复了很少的Java漏洞,表现出其修复能力的局限性。
-
Codex表现最佳: 在比较中,Codex显示出最好的Java漏洞修复能力,相对于其他模型,它能够更有效地修复漏洞。
-
微调LLM: 使用一般的APR数据对LLM进行微调可以提高其漏洞修复能力,这表明微调对提高LLM的性能具有积极作用。
-
编译率问题: 生成修复的编译率是一个重要指标,Codex的最高编译率为79.7%,而其他LLM和APR技术的编译率都较低,表明它们在处理编译问题时存在困难。这也可能表明它们缺乏足够的语法领域知识。
-
漏洞类型限制: 除Codex外,其他模型只修复一些简单的漏洞类型,例如单一删除、变量或函数替换。这意味着它们在处理复杂漏洞方面存在局限性。
-
新VJBench数据集表现: 新的VJBench数据集揭示了LLM和APR模型的局限性,它们无法修复许多不同的CWE(常见弱点枚举)类型,包括CWE-172编码错误、CWE-325缺少加密步骤、CWE-444 HTTP请求窃取、CWE-668资源暴露到错误的领域,以及CWE-1295调试消息显示不必要的信息。
这些实验结果提供了有关LLM、Fine-tuned LLM和APR技术在Java漏洞修复方面性能,强调了Codex的优越性,同时指出了其他模型在处理特定漏洞类型和编译问题方面的限制。
普遍情况 微调效果
编译率 影响编译率,什么情况下不能编译?案例?
只修复的案例类型: CWE-172 Encoding error,CWE-325 Missing cryptographic step,
CWE-444 HTTP request smuggling, CWE-668 Exposure of resource to wrong
sphere, and CWE-1295 Debug messages revealing unnecessary information.
数据集和实验结果以及未来发展方向
-
数据集创建: 为了评估自动程序修复技术,研究人员创建了两个Java漏洞Benchmark数据集:
- VJBench: 包含42个可重复的真实世界Java漏洞,覆盖12种新的CWE类型。
- VJBench-trans: 包含150个转换过的Java漏洞,这扩展了可用于评估的数据集。
-
代码转换用于降低威胁: 研究人员使用代码转换来减轻LLM和黑盒Codex训练数据中可能已经看到评估数据的威胁。这有助于确保评估的准确性和可靠性。
-
实验结果: 在实验中,评估了LLM和APR技术对于转换漏洞(VJBench-trans)的修复能力。实验结果显示:
- 代码转换导致LLM和APR技术修复的漏洞数量减少。
- 一些模型,如Codex和微调的PLBART,对于代码转换更为健壮。
- 另一方面,有些转换使漏洞更容易修复。
-
未来发展方向: 提出了关于未来研究方向的启示和建议。
- 进一步改进LLM和APR技术,以提高对转换漏洞的修复能力。
- 开发更多的漏洞Benchmark数据集,以更全面地评估自动程序修复技术。
- 探索更多的代码转换方法,以了解它们对修复漏洞的影响。
- 研究如何提高LLM和APR技术在处理不同类型漏洞时的健壮性和性能。
数据集
先前的数据集和Java漏洞Benchmark
这些Benchmark和数据集用于评估和比较自动程序修复技术的性能和效果,以帮助改进漏洞修复方法。
先前的数据集和Java漏洞Benchmark用于评估自动程序修复技术:
-
Defects4j: 用于Java漏洞的Benchmark之一,提供了许多不同的项目和漏洞用例供研究和评估使用。
-
QuixBugs: 另一个用于Java漏洞的Benchmark,包含一系列有缺陷的程序用例,可用于自动程序修复研究。
-
bugs.jar: 一个包含Java漏洞的Benchmark,提供了用于测试和评估自动程序修复技术的数据集。
-
Bears: 也是一个用于Java漏洞的Benchmark,包括一系列漏洞用例,可用于研究漏洞修复。
-
Vul4J: 一个特定的Java漏洞Benchmark,数据来源包括National Vulnerability Database (NVD)和项目特定的网页。它包含了来自51个项目的79个漏洞,覆盖了25种CWE(常见弱点枚举)类型。值得注意的是,79个漏洞中有39个是single-hunk漏洞,由于某些原因,2个无法编译,2个无法用Vul4J作者提供的docker重现,最终只能重现35个single-hunk漏洞。这些单一修补程序的漏洞适用于基于深度学习的自动程序修复系统,因为它们只包含一个修补程序。
数据集扩展要求
i) 相关的漏洞只能是Java源代码。
ii) 修复提交必须包含至少一个测试用例 V_fix 通过,同时 V_bug 不通过。
iii) 修复补丁应该只包括与修复漏洞相关的变化,不应引入无关的变化或重构等特性。
iv) 漏洞不应出现在Vul4J数据集中。
数据处理工作
- 在2022年5月13日,从National Vulnerability Database(NVD)下载了所有可用的JSON格式漏洞数据。
- 解析这些数据以获取相关信息,包括GitHub项目的URL。
- 排除了Java代码少于50%的项目,最终留下了400个Java项目,其中包含了933个独特的漏洞。
- 进行手动检查,识别包含漏洞修复提交的项目,最终得到了698个漏洞的漏洞修复提交。
- 过滤掉了185个修复提交中包含非Java更改的漏洞,以及314个修复提交中没有测试用例的漏洞,剩下了199个漏洞,每个都有测试用例和相应的仅Java修复提交。
- 使用构建工具(如Maven或Gradle)来重现这些漏洞,确保它们可以在不同环境中成功编译和运行。
- 最终,得到了42个未包含在Vul4J数据集中的Java漏洞,这些漏洞满足了先前扩展数据集的要求。这些数据将用于进一步研究和实验。
最终数据集 VJBench
- 42个新的可重现的真实世界Java漏洞,这些漏洞来自30个开源项目。
- 其中,27个漏洞是 multi-hunk(包含多个补丁)漏洞,来自22个不同的项目;另外,15个漏洞是 single-hunk(只包含一个补丁)漏洞,来自11个项目。
- 这42个漏洞涵盖了23种不同的CWE(常见弱点枚举)类型。
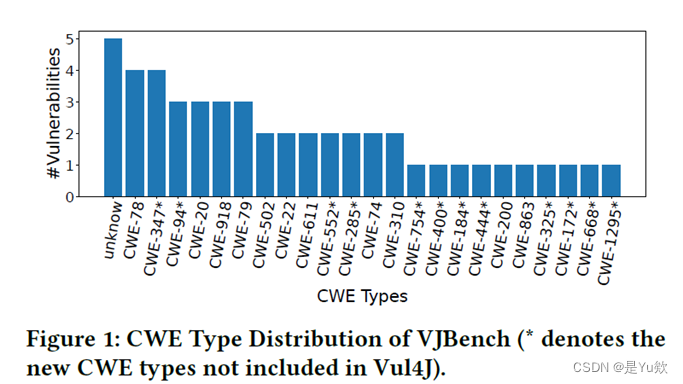
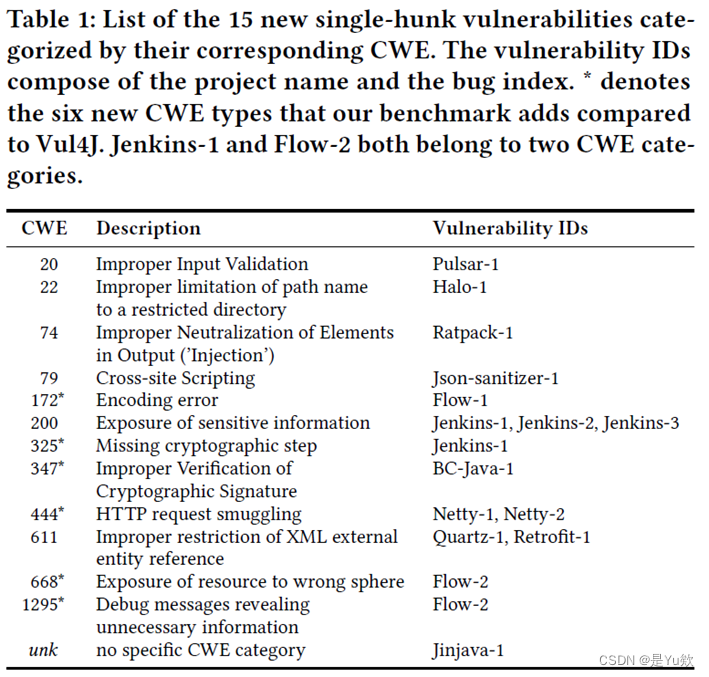
VJBench 与 Vul4J 的比较
- VJBench 扩展了 Vul4J 数据集,引入了12种新的CWE类型,这些类型在 Vul4J 中尚未包含。
- 此外,VJBench 补充了 Vul4J 中只有一个示例的4种CWE类型,包括 CWE-78、CWE-200、CWE-310 和 CWE-863。
在最终的研究中,研究人员使用了50个 single-hunk 漏洞,其中包括:
- 15个漏洞来自 VJBench。
- 35个漏洞来自 Vul4J 数据集。
这些数据将在研究中用于评估和比较自动程序修复技术的性能和效果,为进一步研究提供了丰富的实验数据。
大语言模型和APR技术
大型语言模型
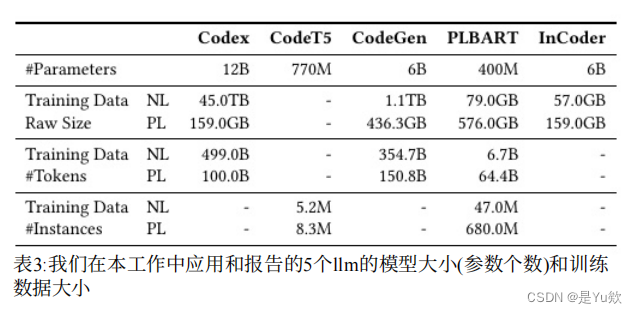
我们选择了五个llm,即Codex, PLBART, CodeT5,CodeGen和InCoder,因为它们是
⑴最先进的,
(2)能够在不修改模型或额外组件的情况下执行代码生成任务(例如,CodeBERT[26] GraphCode-BERT[33]除外)
(3)用足够的源代码训练,以便它们能够在一定程度上理解代码(例如,我们排除了T5[65],GPT-2 [64],GPT-Neo[13]和GPT-J[71],其训练数据超过90%是文本)。
在这项工作中,我们研究了两种设置下的llm:与一般APR数据进行微调。

CodeX[17]
CodeX是一个基于gpt -3[15,17]的语言模型,其中有12B个参数在自然语言和源代码上训练。我们使用达芬奇-002模型(截至2022年7月),这应该是最准确的llm模型[1]。我们关注的是llm插入模式,因为它在我们初步研究的三种主要模式(补全、插入和编辑)中提供了最好的结果。
CodeT5 [73]
CodeT5是一个编码器-解码器转换器模型[70],使用标识符感知降噪目标和双峰双生成任务进行预训练。它是在520万个代码函数和830万个自然语言句子的语料库上训练的,这些语料库来自包括Java在内的六种编程语言。在这项工作中,我们使用了目前发布的最大的CodeT5模型,它有770M个参数。
CodeGen [55]
CodeGen模型是一系列用于会话程序合成的自回归解码器转换器。它们的训练数据由来自pile数据集的354.7B自然语言到kens和从谷歌BigQuery数据库的子集中提取的150.8B编程语言token组成。在这项工作中,我们采用了包含6B个参数的CodeGen模型(由于我们机器的限制,没有使用包含16B个参数的较大模型)。
PLBART [8]
PLBART使用编码器-解码器转换器架构,在编码器和解码器上有一个额外的规范化层。它通过去噪自动编码对从Java和Python GitHub存储库中提取的函数进行预训练。有两个不同尺寸的PLBART模型,我们使用包含400M参数的较大模型。
InCoder [28]
InCoder模型遵循XGLM[45]的纯解码器架构,并在掩码跨度预测任务上进行预训练。它的预训练数据来自GitHub和GitLab上的开源项目,以及StackOverflow帖子。有两个不同大小的InCoder模型发布,我们使用较大的模型,包含6B个参数。
实验:对于带有注释错误行的输入
在研究中,由于不清楚带有注释错误行的输入会如何影响模型的修复能力,研究人员进行了实验,比较了带有注释错误行和不带注释错误行的输入对于每个模型的性能。这表示他们分别测试了两种情况的输入。
Suffix: 此外,文中提到了“Suffix”,这可能指的是一种用于截断后的代码的补充信息或后缀。这些信息可能有助于理解模型如何处理截断后的代码。

关于Large Language Models的微调
在研究中,使用了 Fine-tuned Large Language Models(微调的大型语言模型)来进行漏洞修复。
-
微调数据来源: 微调数据来自开源GitHub Java项目,共有143,666个实例。每个实例包括一对有bug的代码和相应的修复代码。
-
漏洞不在微调数据中: 本文研究的漏洞都不包含在用于微调LLMs的APR训练数据中。这确保了研究的漏洞是新的且未在微调数据中见过的。
-
微调设置: 微调过程中使用的设置包括学习率(Lr = 1e-5)、Adam优化器、批量大小(batch size = 1)以及训练周期(epoch = 1)。
-
微调的模型: 微调了LLMs,但除了Codex。Codex不提供用于微调的API,因此无法对其进行微调。
-
微调数据格式: 在微调中,有bug的行作为注释行给出,并将整个函数输入到经过微调的LLM中,以生成修复补丁。
-
微调方式: 微调的方式类似于基于深度学习的自动程序修复(DL-based APR)方法,使用相似的训练和微调流程。
这些微调的细节和设置用于训练大型语言模型,以提高其在漏洞修复方面的性能。微调的数据集的选择和独立性确保了模型在新的漏洞上的表现。
我们进行了搜索,并确认我们在这项工作中研究的漏洞都不存在于用于微调llm的APR训练数据中
微调的损失函数? Prior work [38] fine-tuned LLMs with a training dataset
containing 143,666 instances collected from open-source GitHub Java
projects微调模型的loss
四种基于深度学习的自动程序修复 (DL-based APR) 开源技术
在Java漏洞数据集上,研究人员进行了训练和比较四种最先进的基于深度学习的自动程序修复 (DL-based APR) 开源技术。
-
CURE (Code-aware Neural Networks for Automated Program Repair):
- 使用一个小型的语言模型(4.04M代码实例)应用于CoCoNuT的编码器-解码器架构。
- 学习代码语法并提出了一种新的代码感知策略,通过在推理过程中去除无效标识符来提高编译率。
- CURE 在训练中使用了272万个APR实例。
-
Recoder:
- 使用基于树的深度学习网络,在82.87K APR训练实例上进行训练。
- 侧重于生成编辑以修改有缺陷的抽象语法树 (AST),以形成修补的AST。
-
RewardRepair:
- 在计算模型的损失函数时,包含编译作为一项因素,以增加可编译(和正确)补丁的数量。
- 不同于CURE,损失函数在训练期间增加了可编译补丁的数量。
- RewardRepair 在训练中使用了3.51M APR训练实例。
-
KNOD (Knowledge-augmented Neural Program Repair with Overlap Decoding):
- 提出了一种新的三阶段树解码器来生成补丁的AST。
- 使用领域知识蒸馏来修改损失函数,使模型能够学习代码的语法和语义。
- KNOD 在训练中使用了576K APR训练实例,是最先进的基于DL的APR技术。
这些技术在训练和推理过程中采用不同的方法,以提高其在自动程序修复方面的性能。研究人员对它们进行了比较,以确定它们在Java漏洞修复中的相对性能。
代码转换:创建未见过的漏洞及其修复的目的和方法
研究的目的是为了解决训练-测试数据重叠的挑战,即确保训练和测试数据之间没有太大的重叠,以便更准确地评估自动程序修复(APR)技术的性能。为实现这一目的,研究人员采取以下方法:
目的: 创建漏洞和其修复,这些漏洞以前尚未在现有的大型语言模型(LLMs)或APR技术的训练数据中见过。
针对数据集: 主要针对两个数据集,即Vul4J和VJBench,这些数据集用于评估APR技术的性能。
两类转换:
-
Identifier Renaming(标识符重命名): 这种转换涉及更改有bug的代码和相应的修复代码中的标识符(例如变量名、函数名等)。这可以帮助创建新的漏洞和修复,以确保它们与训练数据中的不同。
-
Code Structure Change(代码结构变更): 这种转换涉及手动修改有bug的函数的代码结构。对于每个有bug的函数,会应用一系列可应用的转换,从而改变函数的结构。这也有助于创建新的漏洞和修复。
这些转换的目的是在不改变程序的整体功能的前提下,生成新的漏洞和相应的修复,以确保研究中使用的数据集包含未见过的情况,从而更准确地评估APR技术的性能。
标识符重命名过程

标识符重命名是一种转换方法,用于创建新的漏洞和修复,确保它们与训练数据中的不同。以下是标识符重命名的具体过程:
针对对象: 对项目中定义的所有变量、函数和类进行同义词重命名。这些标识符的原始名称必须符合Java规范,不修改Java默认库或外部库的标识符。
流程:
-
使用工具 src2abs,首先提取有bug的函数中的所有变量、函数和类名。从中排除了来自Java或第三方库中的标识符。
-
使用 Natural Language Toolkit (NLTK) WordNet 为每个单词生成同义词。WordNet是一种词汇数据库,包含单词之间的语义关系。
-
然后,重新组装这些同义词以形成一个完整的标识符。这些同义词可能是在转换后的标识符中的替代名称。
-
最后,通过手动检查和调整同义词,确保它们在代码的上下文中合适。这可以防止生成的标识符与代码的语法和语义不匹配。
这个过程有助于在不改变代码功能的情况下,为代码创建新的标识符,从而生成新的漏洞和修复,以用于评估自动程序修复技术的性能。
代码结构更改的六种转换规则
为了改变代码结构,研究人员定义了六种不同的转换规则。这些规则用于改变代码的结构,从而生成新的漏洞和修复,以用于评估自动程序修复技术的性能。


-
if条件翻转:
- 对if条件进行取反操作,并交换if和else分支中的代码块。
-
循环转换:
- 将for循环转换为while循环,或反之亦然。
-
条件语句转换:
- 转换一个三元表达式(
var = cond ? exprTrue : exprFalse;)为if-else语句(if (cond) { var = exprTrue; } else { var = exprFalse; }),或将一个switch语句转换为多个if和elseif语句,反之亦然。
- 转换一个三元表达式(
-
函数链:
- 将多个函数调用合并到一个调用链中,或反过来将一个函数调用链拆分为单独的函数调用。例如,
value.getClass().equals(...);可以拆分为Class value_class = value.getClass();和value_class.equals(...);。
- 将多个函数调用合并到一个调用链中,或反过来将一个函数调用链拆分为单独的函数调用。例如,
-
函数实参传递:
- 如果局部定义的变量或对象仅用作函数实参,可以用其定义语句替换函数实参,或将作为函数实参传递的函数调用提取到单独的变量/对象定义中。例如,可以提取参数
parentPath.normalize()并将其声明为一个本地对象normalizedParentPath。
- 如果局部定义的变量或对象仅用作函数实参,可以用其定义语句替换函数实参,或将作为函数实参传递的函数调用提取到单独的变量/对象定义中。例如,可以提取参数
-
代码顺序更改:
- 如果更改代码语句的顺序不影响执行结果,可以更改语句的顺序。例如,
funcA(); int n = 0;可以变换成int n = 0; funcA();,因为调用funcA()和声明int n之间互不影响。
- 如果更改代码语句的顺序不影响执行结果,可以更改语句的顺序。例如,
这些转换规则的目的是在不影响代码功能的情况下,生成新的漏洞和修复,以用于评估自动程序修复技术的性能。这确保了测试数据包含不同于训练数据的情况。
VJBench-trans 数据集转换的结果
VJBench-trans 是一个包含经过三组不同转换的 Java 漏洞的数据集,旨在解决训练和测试数据重叠的挑战。
转换的三组:
-
仅重命名标识符: 这组转换仅涉及标识符的同义词重命名,用以创建新的漏洞和修复。
-
仅更改代码结构: 这组转换专注于改变代码的结构,例如更改条件语句、循环等,以生成新的漏洞和修复。
-
同时进行重命名和更改代码结构: 这组转换结合了前两组的转换,旨在同时重命名标识符并更改代码结构。
创建过程:
- VJBench-trans 数据集是通过将这三组转换应用于 VJBench 和 Vul4J 数据集而创建的,从而生成了包含 150 个不同转换 Java 漏洞的数据集。每组转换应用了 50 次,因此共有 3 × 50 = 150 个转换漏洞。
验证转换后的代码:
- 转换后的代码仍然是真实的和人类可读的。为了评估可信补丁的正确性,维护了一个字典,其中存储了重命名标识符与其原始名称之间的映射。
- 为每个漏洞,还编写了相应的补丁程序,以针对经过代码结构转换的版本,以便将来的数据集用户参考。
这个数据集的创建和验证过程有助于确保其中包含了经过不同类型转换的漏洞和修复,以用于评估自动程序修复技术的性能,同时也提供了可信的补丁程序以验证其正确性。
实验
设置
- 数据集(Dataset): 研究使用了Vul4J、VJBench 和 VJBench-trans 数据集来评估自动程序修复(APR)技术的性能。
- LLM 设置(LLM Setups): 采用了四种最先进的基于深度学习的自动程序修复(DL-based APR)技术,包括 CURE、Recoder、RewardRepair 和 KNOD。
- 补丁验证(Patch Validation): 使用了字典来存储重命名标识符与原始名称之间的映射,以验证经过转换的代码中的补丁程序的正确性。
步骤
-
使用 VJBench 和原始数据集 Vul4J 作为基准进行测试。
- 每个语言模型为每个漏洞生成 10 个补丁。
- 每个 APR 模型使用其默认的波束搜索大小,并验证前 10 个补丁。
-
在 VJBench 和 Vul4J 上应用代码转换,生成 VJBench-trans,以评估代码转换对所有 LLMs、微调 LLMs 和 APR 技术的漏洞修复能力的影响。
数据集:
- 针对 single-hunk vulnerability(单一修补程序漏洞),共有 50 个,其中 35 个来自 Vul4J,15 个来自 VJBench。
- 使用开发人员补丁中修改的代码行作为错误行。
波束搜索
- 波束搜索(beam search)是一种搜索算法,它同时保持多个修复候选,然后根据评分函数的计算结果选择最有希望的修复候选路径。
- “beam search size”(波束搜索大小)是指用于生成修复建议的搜索空间的大小。它决定了算法在搜索过程中保留多少个备选解决方案。更大的波束搜索大小可以增加搜索空间,但也可能增加计算成本。波束搜索是常用的搜索算法,用于在大的搜索空间中找到最优解或最有可能的解。
LLM 设置


研究中使用了不同的 LLM 设置,包括两种输入方式,每种方式都观察到不同的性能表现。
-
两种输入方式:
- 将错误行作为注释输入: 在输入中将包含错误的行(buggy line)作为注释。
- 去除错误行: 在输入中去除错误的行,只保留修复前的代码。
-
观察到 InCoder 在输入包含错误行注释时修复了更多漏洞,而其他 LLMs 在没有错误行时表现更好。
-
针对每个模型,选择了最佳性能设置,并在该设置下生成 10 个补丁。
-
对于 微调的 LLMs,使用带有错误行注释的输入格式。
-
针对不同的 LLMs,设置波束搜索大小(beam search size):
- 对于 CodeT5、CodeGen、PLBART 和 InCoder,将波束搜索大小设置为 10。
- 对于 Codex,设置参数 n(要生成的候选数量)为 10。由于 Codex 采用的抽样方法具有随机性,对每个漏洞运行 25 次,然后取平均结果以减小误差范围。运行了 25 次以在 95% 的置信水平上控制误差范围(≤0.3)。
-
由于 Codex 的请求率限制,新生成令牌为 400 个,而所有其他 LLMs 的新生成令牌为 512 个。
这些设置用于确保在评估各种 LLMs 的漏洞修复能力时,使用了合适的输入方式和参数配置,以便比较它们的性能。
补丁验证(Patch Validation)
在研究中,采用了不同的补丁验证方法,具体取决于使用的自动程序修复(APR)技术。
-
Codex 插入模式: Codex 使用插入模式生成代码来替换原有的有 bug 行。它在前缀提示符和后缀提示符之间生成插入的代码。前缀提示符包含有 bug 行注释之前的代码,而后缀提示符包含有 bug 行注释之后的代码。因此,Codex 生成的代码替换原始的有 bug 代码。
-
CodeT5: CodeT5 生成代码来替换其输入中的屏蔽标签。
-
PLBART: PLBART 生成整个补丁函数,用来替换整个有 bug 的函数。
-
CodeGen 和 InCoder: 这两种模型生成代码的补全模型,根据前缀提示符生成代码。研究中使用了这两种模型生成的第一个完整函数来替换原有的有 bug 函数。
-
Fine-tuned LLMs(微调的 LLM): 经过微调的 CodeT5、CodeGen、PLBART 和 InCoder 直接生成补丁代码来替换有 bug 的代码。
对于每个 LLM 和 APR 技术,定义了不同类型的补丁:
-
合理的补丁(Plausible Patches): 通过所有测试用例的补丁。这些补丁在语法和语义上都是合理的。
-
正确的补丁(Correct Patches): 在语义上等同于开发人员的补丁。这些补丁不仅通过测试用例,还与开发人员的修复相匹配。
-
过拟合的补丁(Overfit Patches): 虽然通过了所有测试用例,但在语义上与正确的补丁不等同。
-
测试是否为合理的补丁: 检查生成的前 10 个补丁是否通过了测试用例。
-
测试是否为正确的补丁: 进行手动检查,以验证每个可能的补丁是否在语义上等同于开发人员的补丁。
这些补丁验证方式用于评估生成的补丁的质量和可行性,以确定哪些补丁是合理和正确的,从而可以进行性能比较。
结果列表
研究发现了现有LLMs和APR技术的局限性,并提出了可以改进自动程序修复技术的方向和启示。其中,微调LLMs使用一般的APR数据以提高漏洞修复能力是一个有希望的方法。同时,转换后的漏洞数据集有助于更严格地评估技术的性能。
RQ1: 漏洞修复能力
在这个问题下,作者评估了各种技术的漏洞修复能力。
方法
运行Codex 25次,报告修复漏洞的平均数量和误差范围;对于其他llm,我们只运行它们一次;考虑前十补丁,因为最近的一项研究表明,几乎所有的开发人员最多只愿意检查10个补丁
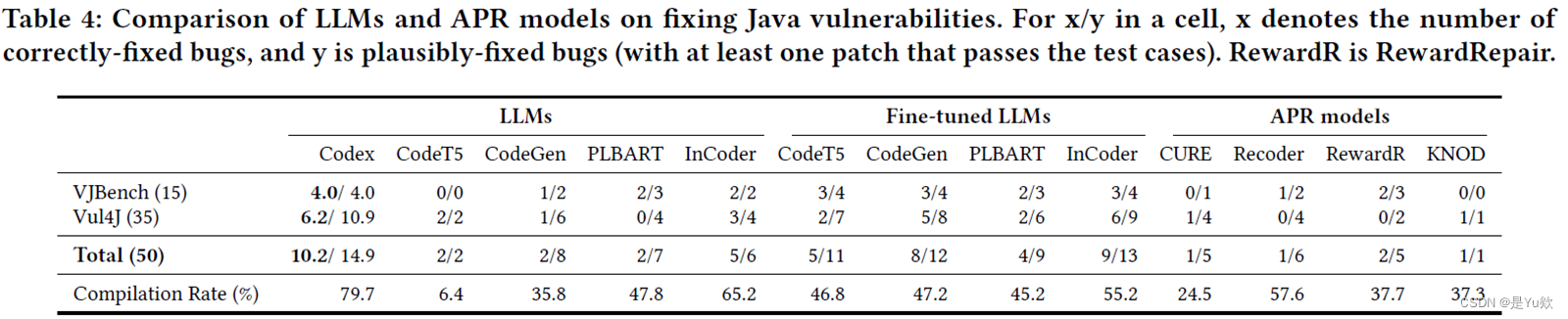
表4中的结果以 “X/Y” 形式报告,其中 “X” 是每种技术正确修复的漏洞数量,而 “Y” 是合理修复的漏洞数量。
这些结果为不同技术的漏洞修复能力提供了对比和评估。Codex 凭借其良好的性能在漏洞修复方面脱颖而出。
此外,考虑到开发人员通常只愿意检查前 10 个补丁,因此前十个补丁的质量对于技术的评估至关重要。
结果
LLMs vs. APR Techniques(LLMs与APR技术比较):
- 发现1:现有的大型语言模型和自动程序修复(APR)技术修复了相对较少的Java漏洞。其中,Codex表现最佳,平均修复了10.2个漏洞,占总漏洞的20.4%。
LLMs Fine-tuned with APR Data(使用APR数据微调的LLMs):
- 发现2:使用APR数据进行微调可以提高所有四个大型语言模型的漏洞修复能力。微调后的InCoder表现出竞争力,修复了9个漏洞,虽然不如Codex,但依然表现出良好的修复能力。
评估编译率:
- 发现3:在研究补丁的质量方面,研究考察了编译率(即成功生成补丁的比例)。结果显示,Codex的编译率最高,达到了79.7%。其他大型语言模型(无论是否经过微调)和APR技术的编译率相对较低,表明它们在语法领域知识方面存在不足。可能是因为Codex的模型规模和训练数据规模更大。
综合来看,Codex在修复Java漏洞方面表现最出色,而未经微调的大型语言模型也显示出有竞争力的修复能力。
然而,研究还指出,修复漏洞相对于一般的Bug更具挑战性,因为漏洞数据较少,这需要更多的特定领域知识。
此研究结果有助于我们理解不同技术在Java漏洞修复方面的能力。
RQ2: LLMs和基于学习的APR技术修复哪些类型的漏洞?
发现4: 大型语言模型和APR技术(除了Codex)通常只能修复需要简单更改的漏洞,例如删除语句或替换变量/方法名。这意味着它们在处理复杂漏洞时表现较差。

发现5: 新的VJBench基准测试显示,大型语言模型和APR技术无法修复许多不同的Common Weakness Enumeration(CWE)类型,包括CWE-172(编码错误)、CWE-325(缺少加密步骤)、CWE-444(HTTP请求偷窃)、CWE-668(资源暴露于错误领域)和CWE-1295(调试消息透露不必要的信息)。这表明这些技术在修复特定类型的漏洞方面存在挑战。
这些发现强调了两个主要问题,即大型语言模型修复Java漏洞时的限制:
- LLMs通常只能提供关于错误行的信息,而
无法生成漏洞修复的具体补丁。因此,为了提高其效用,需要提供更多关于漏洞的信息,如CWE类型。 - LLMs可能
需要更多的项目特定信息,包括在有错误的函数之外声明的相关方法和变量,以更好地理解和修复漏洞。
这些发现有助于我们理解LLMs和APR技术在特定漏洞类型上的表现,并为未来的改进提供了方向。
RQ3: 在转换后的漏洞上的修复能力
- VJBench-trans 数据集上的修复能力(Fixing Capabilities on Transformed Vulnerabilities): 转换后的漏洞被认为是独立于训练数据的,使得测试更具挑战性。这有助于更准确地评估APR技术的性能。
RQ3: Fixing Capabilities on Transformed Vulnerabilities(对转换后的漏洞修复能力)
研究发现了以下关键结论:
发现6: 代码转换会对大型语言模型和APR技术的漏洞修复能力产生影响。一些模型,如Codex和微调的CodeT5,对于代码转换更加健壮。另一方面,一些代码转换使漏洞更容易修复。这些结果表明,对漏洞修复的影响在很大程度上取决于具体的代码转换。

为什么修改标识符变量名会影响?
现象: 对于微调的LLM,不同的转换具有不同的效果,但每个转换至少会显著影响一个LLM;例如,尽管标识符重命名对CodeT5和CodeGen的影响很小,但它将InCoder修复的漏洞数量减少了4个。
讨论: 修改标识符变量名(标识符重命名)可能会影响漏洞修复能力,因为标识符的名称在代码的语法和语义中起着关键作用。当标识符重命名后,它们的语义可能会发生变化,导致修复模型在生成补丁时受到影响。某些模型对这种更改比其他模型更敏感,因此修复的能力可能会受到不同标识符名称的影响。
一些模型能够在代码转换后提高漏洞修复率,因为这些转换可能将原始漏洞代码片段转换为更简单的形式,使其更容易被大型语言模型或APR技术修复。这反映了代码转换的复杂性和对修复模型性能的重要性。
结论:代码转换可以显著影响漏洞修复能力,但影响因具体的模型和转换类型而异。这些发现有助于了解漏洞修复技术的鲁棒性和在特定上下文中的表现。
三个主要威胁以及相应的应对措施
-
Java漏洞多样性威胁: 由于Java漏洞种类多样,现有的漏洞基准难以代表所有情况。为了解决这一问题,研究通过使用新的漏洞数据集扩展现有的Java漏洞基准,以涵盖更多类型的漏洞。这样可以增加研究的覆盖范围,更全面地了解漏洞修复技术的性能。
-
开发人员补丁犯错威胁: 文中指出,依靠开发人员的补丁来评估漏洞修复存在误差,因为开发人员可能犯错误。为了应对这一问题,研究仅依赖于公开披露的可重复漏洞数据集,同时包括表明特定版本不再可被利用的测试用例。这样一来,可以减少开发人员可能犯错的影响,提高数据的可信度。
-
LLMs已经接受过漏洞补丁的训练威胁: 由于LLMs可能已经接受过漏洞数据集中的补丁的训练,研究采用了代码转换来创建语义上等效的漏洞,这些漏洞不包含在LLMs的训练数据集中。然后,使用LLMs来尝试修复这些转变后的项目,以验证其修复能力。这个方法帮助确保LLMs不仅仅是重复学习已知漏洞的补丁,而是能够处理新的漏洞情况。
这些应对措施有助于增加研究的可靠性,减轻了数据的不确定性和偏差,使研究结果更有说服力。同时,它们帮助研究团队更好地理解漏洞修复技术的实际性能。
相关工作
这项研究通过综合先前工作,包括漏洞修复技术、漏洞基准、大型语言模型的其他应用以及零样本学习和提示工程,为理解深度学习在漏洞修复领域的性能和挑战提供了更全面的观点。
-
DL-based Vulnerability Fixing Techniques(基于深度学习的漏洞修复技术): 文献提到了先前的研究,这些研究探讨了使用深度学习技术来修复漏洞。然而,它指出了一些差异,例如使用序列准确性作为评估指标而不是实际的APR设置。本研究旨在更全面地评估漏洞修复技术,包括其在真实漏洞数据上的表现。
-
Vulnerability Benchmarks(漏洞基准): 研究提到了一个名为Maestro的漏洞基准测试工具平台,用于Java和C++漏洞。然而,Maestro不支持运行大型语言模型和APR模型。因此,本研究选择使用相同的Java漏洞数据集Vul4J来进行评估。
-
LLMs for Repair and Other Tasks(用于修复和其他任务的大型语言模型): 先前的研究已经探索了大型语言模型在自动程序修复等任务中的应用。这些研究还考察了LLMs对软件开发人员的影响以及其局限性。本研究则探索了LLMs在漏洞修复领域的性能,并指出了其中的挑战和差异。
-
Zero-shot Learning and Prompt Engineering(零样本学习和提示工程): 先前的研究使用零样本学习来修复手工制作的C/Python漏洞和真实的C漏洞。这些研究还探索了不同的提示模板对任务的有效性。本研究建立在这些工作的基础上,但使用更大的数据集并应用了代码转换来缓解数据泄漏问题。
结论
这项工作提供了关于大型语言模型(LLMs)和基于深度学习的自动程序修复(APR)技术在Java漏洞修复领域的有价值的见解。以下是这项研究的主要结论和亮点:
-
研究目的: 本研究的主要目的是调查LLMs和DL-based APR技术在Java漏洞修复方面的能力。这是一个具有挑战性的领域,因为Java漏洞多种多样,而现有技术的表现相对有限。
-
评估范围: 该研究广泛评估了5个LLMs、4个微调后的LLMs以及4个基于DL的APR技术,使用两个真实Java漏洞基准数据集,包括新创建的基准测试工具VJBench。
-
数据集增强: 通过引入代码转换,该研究增强了数据集,以解决LLMs在训练和测试数据上的重叠问题。这有助于更全面地评估这些技术的性能。
-
低修复能力: 结果表明现有的LLMs和APR技术在修复Java漏洞方面的表现较差,只修复了相对较少数量的漏洞。Codex是在这方面表现最佳的技术。
-
微调改进: 通过微调LLMs使用一般APR数据,可以提高它们的漏洞修复能力。微调后的LLMs在某些情况下甚至与Codex具有竞争力。
-
转换影响: 通过引入代码转换,该研究还研究了LLMs和APR技术在转换后的漏洞上的表现。结果显示,某些转换可以使漏洞更容易修复,但也有一些转换对于这些技术来说是具有挑战性的。
-
未来研究方向: 该研究提出了未来研究方向,包括创建更大的漏洞修复数据集、微调LLMs以提高性能、探索few-shot学习以及利用简化的转换来改进程序修复能力。
综上所述,这项研究为自动化Java漏洞修复领域提供了有关LLMs和DL-based APR技术的有用见解,强调了目前的挑战并指出未来的改进方向。这对于改进软件安全性和可维护性方面具有重要意义。
讨论——Java漏洞修复的自动化:LLM和DL-APR模型的挑战与机会
论文主要贡献
- 数据集贡献: 本研究提供了一个新的Java漏洞修复数据集VJBench,旨在解决现有数据集不足的问题。同时,利用代码转换技术创建了VJBench-trans,以评估代码转换对修复能力的影响。
- 探索Code Transfer: 本文探讨了使用代码转换技术来解决LLM训练和测试数据重叠问题,这是关于漏洞修复的一项创新性工作。
关注内容和结论
-
学习内容: 这项研究为读者提供了以下关键见解和内容:
- 对Java漏洞数据集的现状,其中现实世界的高质量(可重现性)数据缺乏的问题。
- 了解漏洞修复任务如何应用于大型语言模型(LLM)和基于深度学习的自动程序修复(DL-APR)。
- 理解输入数据格式和输出要求,以评估漏洞修复模型。
-
实验合理性和完整性: 关于实验的合理性和完整性,有一些需要考虑的方面:
- Codex在实验中执行了25次以获得平均结果,而其他LLM则只运行了一次。这种差异可能会影响实验的可靠性,因此可以考虑运行其他LLM多次以获得更可靠的结果。
- 实验中未考虑误报情况。未来的研究可以通过评估模型的误报率来提供更全面的性能指标。
-
实验结论的启示: 本研究的实验结论提供了以下启示和未来研究方向:
- 强调了现有漏洞修复模型的不足之处,包括修复能力有限以及主要修复简单漏洞的问题。
- 提出了对于复杂Java漏洞的高质量数据集的需求。同时,指出微调(fine-tuning)可以提高模型的修复能力。
- 提出了使用代码转换技术的潜在机会,例如对漏洞的理解和在漏洞检测中的应用。
探索的问题和未来方向(学姐的思考)
- 为什么要强调漏洞数据的可复现性和可编译性,是否与CVE漏洞修复提交的真实性验证有关?
- 对于C/C++语言的研究,是否存在高质量的可复现漏洞数据集?代码转换技术是否可以用于扩充这些数据集?
- 漏洞修复模型对于漏洞的理解能力如何,是否可以应用于漏洞检测?微调是否能帮助减少误报?
- 如何使用代码转换技术来辅助漏洞检测和修复,以更好地定位漏洞部分?
- 为什么代码转换中的标识符重命名会对检测结果产生影响?如何解决这个问题?
- 有关复杂的multi-hunk漏洞,有什么进一步的研究方向可以探索?
chatgpt对其的回答
你提出了一些关于这项研究的讨论和进一步探索的有趣观点和问题。这些问题可以帮助深化对这一领域的理解以及未来的研究方向。以下是对你提出的问题的一些思考:
数据集问题: 你正确地指出了真实世界高质量漏洞数据集的缺乏。这是一个挑战,因为漏洞修复模型的性能评估需要具有可重现性和可编译性的数据。关于这一问题,未来研究可以尝试以下方法:
- 创建更多可复现漏洞数据集,或鼓励开发者提交更多可重现漏洞。
- 考虑与现有漏洞数据库(如CVE)合作,以提供更多修复的可重现数据。
- 探索使用代码转换技术(类似于本文中使用的方式)来扩充数据集,以解决数据不足问题。
测量方法问题: 对于LLMs的性能测量方式值得深入思考。尽管Codex进行了多次实验以获得平均结果,但其他LLMs可能可以通过多次实验来获得更可靠的性能评估。另外,考虑到误报问题,可以进一步评估模型的误报率,以获得更全面的性能指标。
漏洞理解与检测: 您提出了关于漏洞修复模型对漏洞的理解和应用于漏洞检测的有趣问题。这是一个潜在的研究领域。可以进一步探讨以下方向:
- 漏洞修复模型是否可以应用于漏洞检测,以帮助找到潜在的漏洞?
- 如何通过微调APR模型来降低误报率?
- 使用代码转换技术辅助漏洞检测和修复,以更好地定位漏洞部分。
Code Transfer的影响: 您提出了对于代码重命名的影响的问题。这是一个重要的问题,因为代码重命名可能会导致模型难以理解代码的上下文。这值得进一步研究,以确定为什么重命名会对检测结果产生影响。
Multi-hunk漏洞: 你提到了对于multi-hunk漏洞的修复。这是一个有趣的领域,可以探讨如何扩展这些修复模型以处理更复杂的漏洞情况。
总的来说,你的讨论点提供了有关这项研究的深层见解,同时也为未来的研究方向提供了有价值的建议。这些问题有望引导更多的研究,以改进漏洞修复和检测的自动化技术。

