
- 1人工智能与数学前沿综述:如何借助 AI 发现数学规律?
- 2大厂笔试攻略(一)之数据结构指南_无向图前缀树
- 3postgresql-存储过程_postgresql 存储过程
- 4php课后答案 唐四薪_2021年高校邦PHP语言程序设计课后习题答案
- 5数据结构期末复习(fengkao课堂)_怎么设置带宽代码不变
- 6Python tkinter控件全集之组合选择框 ttk.ComboBox_tkinter ttk
- 7【mysql】—— 表的约束_mysql 表数据约束
- 8ZooKeeper集群安装后显示ZooKeeper JMX enabled by defaultUsing config: /opt/app/zookeeper-3.4.13/bin/../conf
- 9凯撒密码(C语言)_凯撒密码c代码
- 10Mybatis-Plus多租户,配合@DS动态切换数据源_mybatisplus 多租户插件、动态数据源配合使用,有些数据源没有租户
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints(理论+代码实现)_gqa注意力 实现
赞
踩
原文链接:https://arxiv.org/pdf/2305.13245.pdf
看原论文只有简单的几张图,其他知乎和CSDN讲的也很模糊,所以写这一篇文章会分别介绍GQA、MQA和其代码的实现,使观看者能够单单看该文就能了解其操作过程。如果读者了解GQA的原理,那么直接看实验结果就行,如果不了解,建议看下面的代码实现。
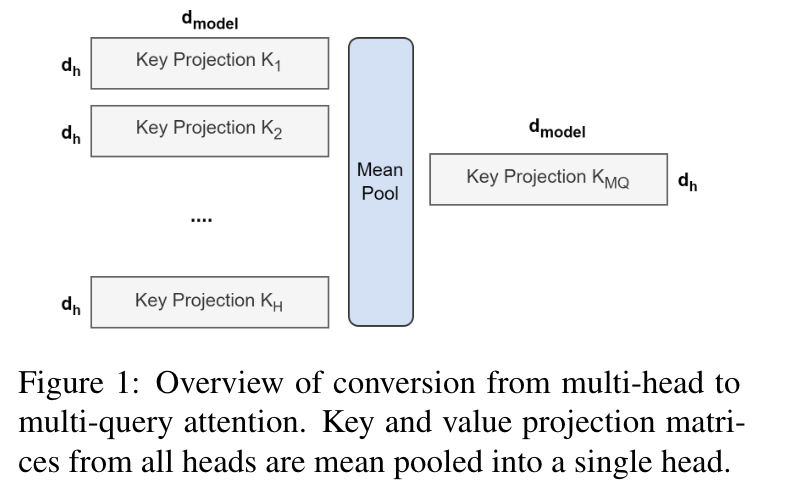
图1
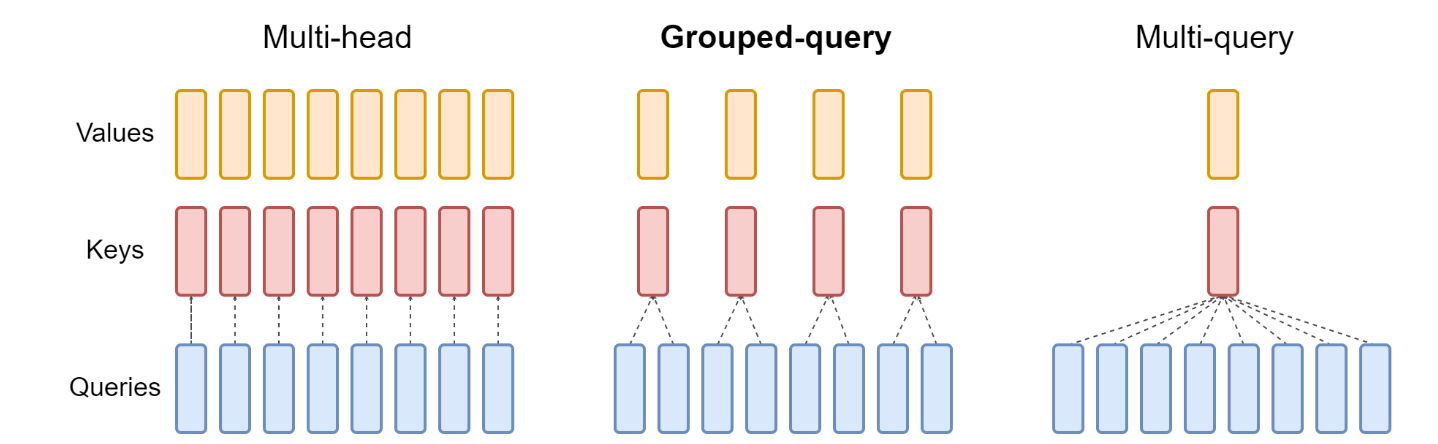
图2
方法
该论文提出了分组查询注意力(GQA),其性能优于多查询注意力(MQA),同时推理速度高于多头注意力机制(MHA)。
从多头模型生成多查询模型分为两个步骤:
(1)检查点转换,就是k_linear和v_linear要转换为新的适应组组查询注意力的线性映射。
(2)额外的预训练,使模型能够适应新的结构。
转换方式如图1所示,原始的key的线性映射的矩阵维度为[hidden_size, hidden_size],需要将其转换为[hidden_size, hidden_size // group_num]其中hidden_size为隐藏层的维度,group_num为组的数量,当group_num == attention_head_num,注意力变为多头注意力。当group_num == 1 ,注意力变为多查询注意力(MQA)。
键头和值头的投影矩阵被均值池化成单一的投影矩阵,作者发现这比选择单一的键头和值头,或者从头开始随机初始化新的键头和值头效果更好。
实验结果
作者选用T5-large作为模型基座进行笑容实验。
主要结果
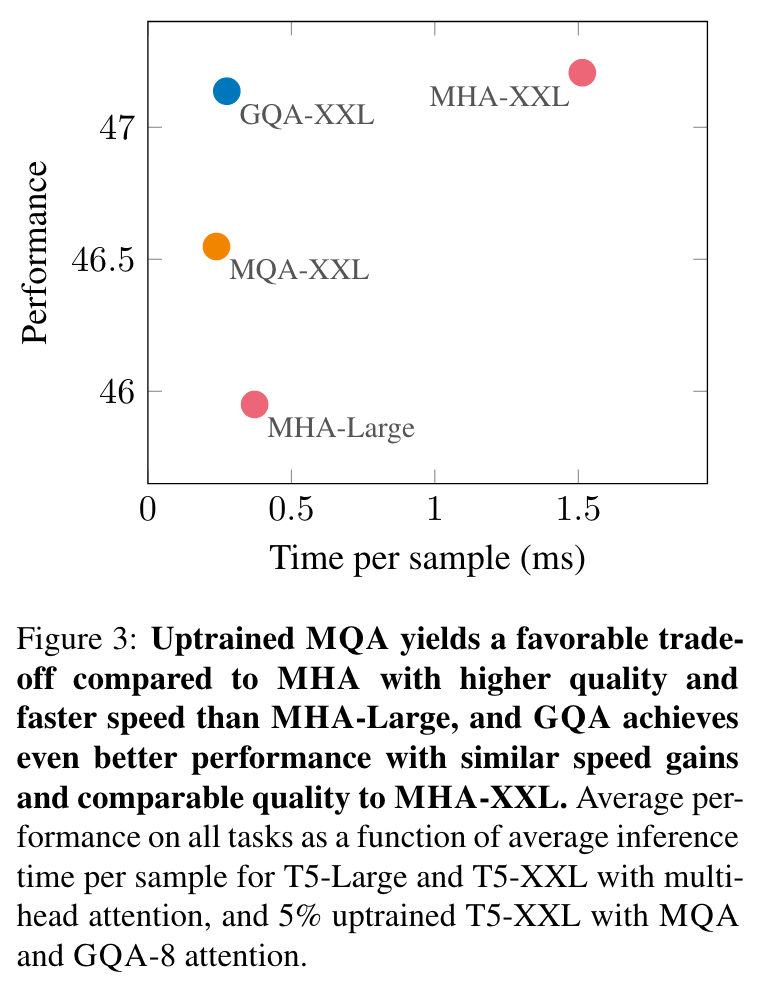
图3
图3显示了MHA T5-Large和T5-XXL以及升级的MQA和GQA-8 XXL模型在α = 0.05的升级比例下,所有数据集的平均性能与平均推理时间的关系。我们可以看到,较大的升级MQA模型相对于MHA模型提供了有利的权衡,质量更高且推理速度更快,超过了MHA-Large。此外,GQA实现了显著的额外质量提升,性能接近MHA-XXL,速度接近MQA。表1包含了所有数据集的完整结果。
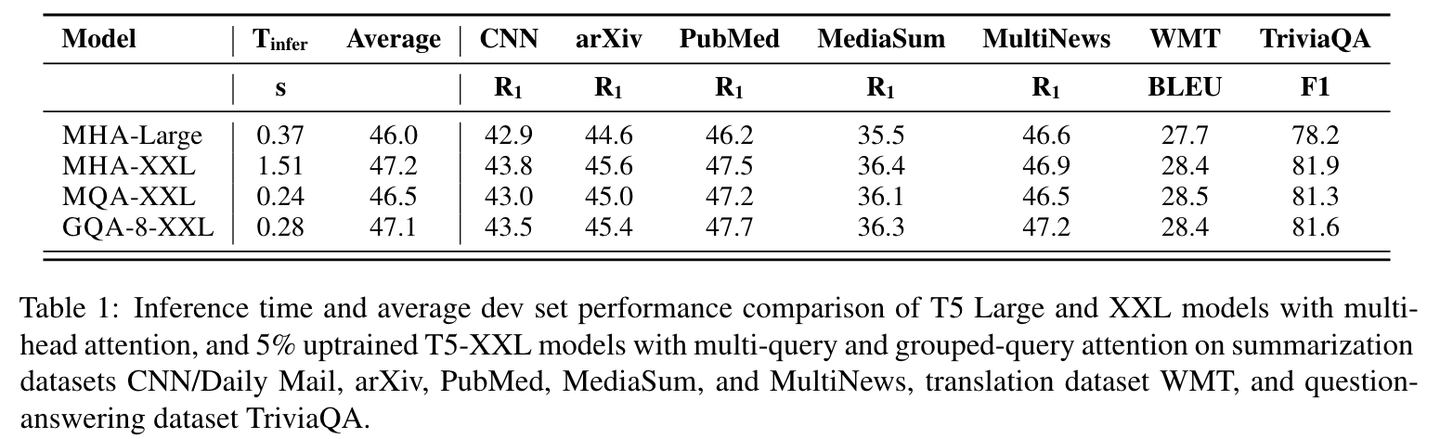
表1
检查点转换消融实验(就是K、V矩阵采用什么方法进行转换)

图4
图4比较了不同检查点转换方法的性能。均值池化似乎效果最好,其次是选择单个头部,然后是随机初始化。直观地说,结果按照从预训练模型中保留信息的程度排序。
升级步骤(就是模型通过多少比例的原始数据集能够和原始模型的能力对其)
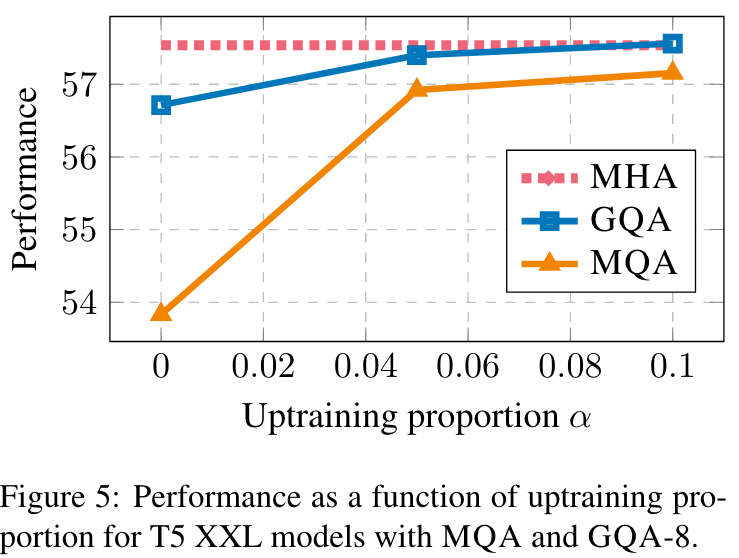
图5
图5显示了T5 XXL与MQA和GQA的升级比例变化对性能的影响。首先,我们注意到GQA在转换后已经实现了合理的性能,而MQA需要进行升级才能有用。无论MQA还是GQA,从5%的升级中获得了收益,而从10%开始,收益递减。
组数(设置为多少组和推理时间的消融实验)
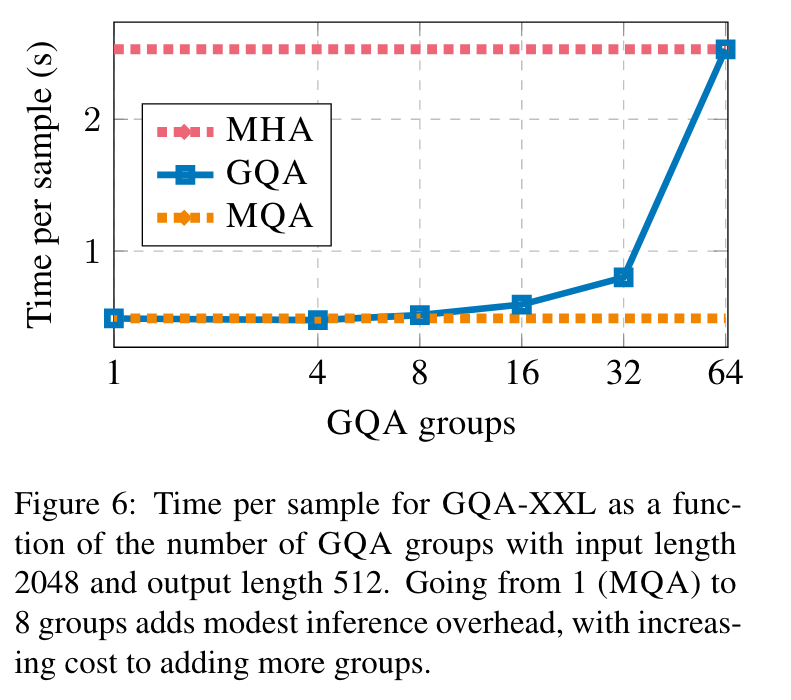
图6
图6展示了GQA组数对推理速度的影响。对于较大的模型,来自KV缓存的内存带宽开销不那么具约束性,而由于头数增加,键值大小的减小更为明显。因此,从MQA增加组数最初只会导致适度的减速,随着我们接近MHA,成本逐渐增加。我们选择了8组作为有利的中间地带。
总结:
分组查询注意力的模型的能力与多头注意力的的模型能力相近而且推理速度和多查询注意力相近,等同于同时融合了两者的优点,但是注意,分组查询注意力并没有减少模型的计算量,只是优化的显存的换入换出,在解码过程中由于key和value的数量级远远小于query的数量级,所以在自回归解码时可以将已经计算出来的key和value一直高速缓存中,减少数据换入换出的次数,以此来提升速度。
多头注意力机制
数学计算过程
多头注意力机制是Transformer模型中的核心组件。在其设计中,"多头"意味着该机制并不只计算一种注意力权重,而是并行计算多种权重,每种权重都从不同的“视角”捕获输入的不同信息。
首先,单头注意力的计算公式如下:
1. 为输入序列中的每个元素计算查询 、键 和值 ,这是通过将输入的词向量与三个权重矩阵相乘实现的:
其中, 是输入的词向量,
、
和
是查询、键和值的权重矩阵。
2. 使用查询和键计算注意力得分:
其中, 是键的维度。
3. 使用softmax得到注意力权重:
4. 使用注意力权重和值计算输出:
对于多头注意力,每个“头”都重复上述过程,但使用不同的权重矩阵集。因此,对于H个头,我们有:
其中i=1,2,...,H。
每个头产生的输出都会被拼接起来,并乘以一个线性变换矩阵,以得到最终的多头输出:
其中, 是输出的权重矩阵。
代码实现
- import torch
- from torch import nn
- class MutiHeadAttention(torch.nn.Module):
- def __init__(self, hidden_size, num_heads):
- super(MutiHeadAttention, self).__init__()
- self.num_heads = num_heads
- self.head_dim = hidden_size // num_heads
-
- ## 初始化Q、K、V投影矩阵
- self.q_linear = nn.Linear(hidden_size, hidden_size)
- self.k_linear = nn.Linear(hidden_size, hidden_size)
- self.v_linear = nn.Linear(hidden_size, hidden_size)
-
- ## 输出线性层
- self.o_linear = nn.Linear(hidden_size, hidden_size)
-
- def forward(self, hidden_state, attention_mask=None):
- batch_size = hidden_state.size()[0]
-
- query = self.q_linear(hidden_state)
- key = self.k_linear(hidden_state)
- value = self.v_linear(hidden_state)
-
- query = self.split_head(query)
- key = self.split_head(key)
- value = self.split_head(value)
-
- ## 计算注意力分数
- attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))
-
- if attention_mask != None:
- attention_scores += attention_mask * -1e-9
-
- ## 对注意力分数进行归一化
- attention_probs = torch.softmax(attention_scores, dim=-1)
-
- output = torch.matmul(attention_probs, value)
-
- ## 对注意力输出进行拼接
- output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)
-
- output = self.o_linear(output)
-
- return output
-
-
- def split_head(self, x):
- batch_size = x.size()[0]
- return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)

多查询注意力MQA
如图2最右侧,直观上就是在计算多头注意力的时候,query仍然进行分头,和多头注意力机制相同,而key和value只有一个头。
正常情况在计算多头注意力分数的时候,query、key的维度是相同的,所以可以直接进行矩阵乘法,但是在多查询注意力(MQA)中,query的维度为[batch_size, num_heads, seq_len, head_dim],key和value的维度为[batch_size, 1, seq_len, head_dim]。这样就无法直接进行矩阵的乘法,为了完成这一乘法,可以采用torch的广播乘法
代码实现
- ## 多查询注意力
- import torch
- from torch import nn
- class MutiQueryAttention(torch.nn.Module):
- def __init__(self, hidden_size, num_heads):
- super(MutiQueryAttention, self).__init__()
- self.num_heads = num_heads
- self.head_dim = hidden_size // num_heads
-
- ## 初始化Q、K、V投影矩阵
- self.q_linear = nn.Linear(hidden_size, hidden_size)
- self.k_linear = nn.Linear(hidden_size, self.head_dim) ###
- self.v_linear = nn.Linear(hidden_size, self.head_dim) ###
-
- ## 输出线性层
- self.o_linear = nn.Linear(hidden_size, hidden_size)
-
- def forward(self, hidden_state, attention_mask=None):
- batch_size = hidden_state.size()[0]
-
- query = self.q_linear(hidden_state)
- key = self.k_linear(hidden_state)
- value = self.v_linear(hidden_state)
-
- query = self.split_head(query)
- key = self.split_head(key, 1)
- value = self.split_head(value, 1)
-
- ## 计算注意力分数
- attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))
-
- if attention_mask != None:
- attention_scores += attention_mask * -1e-9
-
- ## 对注意力分数进行归一化
- attention_probs = torch.softmax(attention_scores, dim=-1)
-
- output = torch.matmul(attention_probs, value)
-
- output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)
-
- output = self.o_linear(output)
-
- return output
-
-
-
-
- def split_head(self, x, head_num=None):
-
- batch_size = x.size()[0]
-
- if head_num == None:
- return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)
- else:
- return x.view(batch_size, -1, head_num, self.head_dim).transpose(1,2)
-
-
于多头注意力相比,多查询注意力的在 和 的维度映射上有所不同,还有就是计算注意力分数采用的是广播机制,计算最后的output也是广播机制,其他的与多头注意力机制完全相同
分组查询注意力(GQA)
如果明白了MQA的话,GQA就非常容易理解了,就是将MAQ中的key、value的注意力头数设置为一个能够被原本的注意力头数整除的一个数字,也就是group数。
代码实现
不同的模型使用GQA有着不同的实现方式,但是总体的思路就是这么实现的,注意,设置的组一定要能够被注意力头数整除。
- ## 分组注意力查询
- import torch
- from torch import nn
- class MutiGroupAttention(torch.nn.Module):
- def __init__(self, hidden_size, num_heads, group_num):
- super(MutiGroupAttention, self).__init__()
- self.num_heads = num_heads
- self.head_dim = hidden_size // num_heads
- self.group_num = group_num
-
- ## 初始化Q、K、V投影矩阵
- self.q_linear = nn.Linear(hidden_size, hidden_size)
- self.k_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)
- self.v_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)
-
- ## 输出线性层
- self.o_linear = nn.Linear(hidden_size, hidden_size)
-
- def forward(self, hidden_state, attention_mask=None):
- batch_size = hidden_state.size()[0]
-
- query = self.q_linear(hidden_state)
- key = self.k_linear(hidden_state)
- value = self.v_linear(hidden_state)
-
- query = self.split_head(query)
- key = self.split_head(key, self.group_num)
- value = self.split_head(value, self.group_num)
-
- ## 计算注意力分数
- attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))
-
- if attention_mask != None:
- attention_scores += attention_mask * -1e-9
-
- ## 对注意力分数进行归一化
- attention_probs = torch.softmax(attention_scores, dim=-1)
-
- output = torch.matmul(attention_probs, value)
-
- output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)
-
- output = self.o_linear(output)
-
- return output
-
-
-
-
- def split_head(self, x, group_num=None):
-
- batch_size,seq_len = x.size()[:2]
-
- if group_num == None:
- return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)
- else:
- x = x.view(batch_size, -1, group_num, self.head_dim).transpose(1,2)
- x = x[:, :, None, :, :].expand(batch_size, group_num, self.num_heads // group_num, seq_len, self.head_dim).reshape(batch_size, self.num_heads // group_num * group_num, seq_len, self.head_dim)
- return x
-
-

