
- 1机器学习之增强学习DQN(Deep Q Network)
- 2idea 切换git仓库_在 IntelliJ IDEA 中这样使用 Git,效率提升2倍
- 3pod的生命周期
- 4使用docker在linux上安装mysql_linux docker 安装mysql
- 5深度学习01-tensorflow开发环境搭建_深度学习环境搭建 tensorflow
- 6Centos7 安装Git-cola
- 7Redis数据类型--Set类型详解及应用_redis set int
- 8Mac如何使用python创建Excel文件,并进行内容写入_mac电脑python操作写入数据
- 9vue-element-admin 的 npm install 报错npm ERR code 128 npm ERR An unknown git error occurred_vueelement-admin install 128
- 10Python2.7 xlrd读取、xlwt写入、xlutils读写Excel表格内容_xlrd 2.7
Python操作PDF-文本和图片提取(使用PyPDF2和PyMuPDF)_python提取pdf中的图片用什么模型
赞
踩
PDF文件格式
如今,可移植文档格式(PDF)属于最常用的数据格式。在1990年,PDF文档的结构由Adobe定义。PDF格式的思想是,对于通信过程中涉及的双方(创建者,作者或发送者以及接收者)而言,传输的数据/文档看起来完全相同。
工具和库
适用于Python的PDF工具,模块和库的可用解决方案范围有些混乱,需要花一点时间弄清楚什么是什么,以及哪些项目需要连续维护。根据我们的研究,以下是最新的候选人:
-
PyPDF2:一个Python库,用于提取文档信息和内容,逐页拆分文档,合并文档,裁剪页面并添加水印。PyPDF2支持未加密和加密的文档。
-
PDFMiner:完全用Python编写,适用于Python 2.4。对于Python 3,请使用克隆的包PDFMiner.six。这两个软件包都允许您解析,分析和转换PDF文档。这包括对PDF 1.7以及CJK语言(中文,日文和韩文)的支持,以及各种字体类型(Type1,TrueType,Type3和CID)。
-
pdflib for Python:Poppler库的扩展,为它提供了Python绑定。它使您可以解析,分析和转换PDF文档。不要将其与具有相同名称的商业吊坠相混淆。
-
PyFPDF:一个在Python下生成PDF文档的库。从FPDF PHP库移植而来,这是著名的PDFlib扩展替换,其中包含许多示例,脚本和派生类。
-
PDFTables:一项商业服务,提供从PDF文档附带的表格中提取的内容。提供一个API,以便PDFTables可以用作SAAS。
-
PyX -Python图形包:PyX是用于创建PostScript,PDF和SVG文件的Python包。它结合了PostScript绘图模型的抽象和TeX / LaTeX接口。这些基元可以构建复杂的任务,例如以可发布的质量创建2D和3D绘图。
-
ReportLab:一个雄心勃勃的,具有行业实力的图书馆,主要致力于精确创建PDF文档。免费提供开放源代码版本和名为ReportLab PLUS的商业增强版本。
-
PyMuPDF(又称“ fitz”):MuPDF的Python绑定,这是一种轻量级的PDF和XPS查看器。该库可以访问PDF,XPS,OpenXPS,epub,漫画和小说书格式的文件,并且以其最佳性能和高渲染质量而闻名。
-
pdfrw:一个基于Python的纯PDF解析器,用于读写PDF。它忠实地再现矢量格式而无需光栅化。与ReportLab结合使用时,它有助于在使用ReportLab创建的新PDF中重用现有PDF的一部分。
| 图书馆 | 用于 |
|---|---|
| PyPDF2 | 读 |
| PyMuPDF | 读 |
| pdflib | 读 |
| PDF表格 | 读 |
| PDFMiner.six | 读 |
| PDF查询 | 读 |
| pdfrw | 读,写/创作 |
| PyFPDF | 写/创作 |
我们将重点介绍PyPDF2和PyMuPDF,并说明如何以最简单的方式提取文本和图像。为了了解PyPDF2的用法,官方文档和许多其他资源提供的示例的组合对您有所帮助。相比之下,官方PyMuPDF文档更加清晰,并且使用该库的速度也大大加快。
使用PyPDF2提取文本
$ pip3 install PyPDF2
- 1
清单1首先导入了PdfFileReader该类。接下来,使用该类打开文档,并使用getDocumentInfo()方法提取文档信息,使用提取页数getDocumentInfo()以及第一页的内容。
请注意,PyPDF2从0开始计数页面,这就是该调用pdf.getPage(0)检索文档第一页的原因。最终,提取的信息被打印到stdout。
清单1:提取文档信息和内容。
#!/usr/bin/python from PyPDF2 import PdfFileReader pdf_document = "example.pdf" with open(pdf_document, "rb") as filehandle: pdf = PdfFileReader(filehandle) info = pdf.getDocumentInfo() pages = pdf.getNumPages() print (info) print ("number of pages: %i" % pages) page1 = pdf.getPage(0) print(page1) print(page1.extractText())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
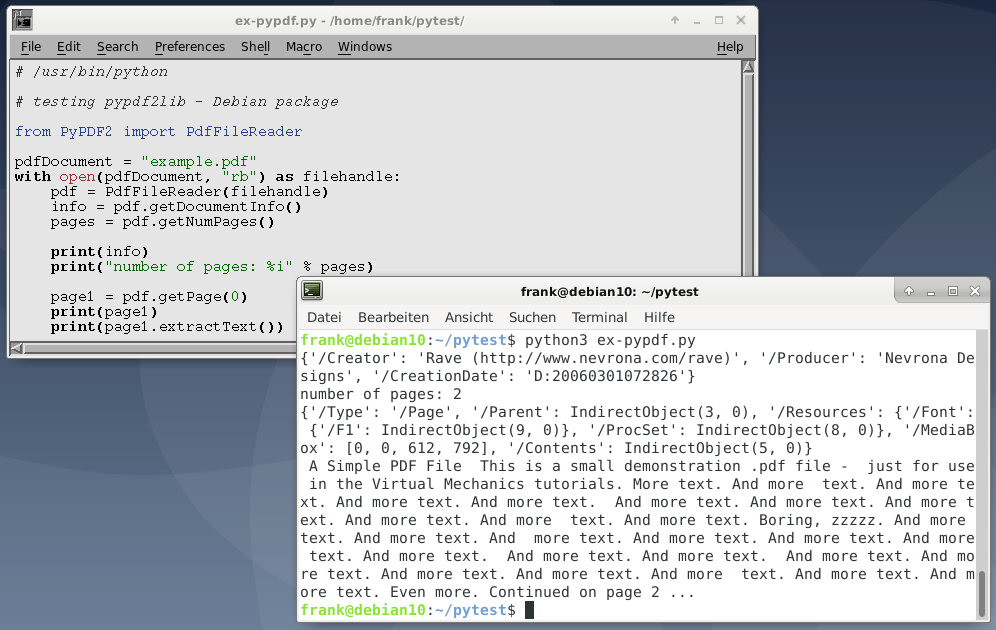
如上面的图1所示,提取的文本是连续打印的。没有段落或句子分隔。如PyPDF2文档中所述,所有文本数据都按照在页面内容流中提供的顺序返回,并且依靠它可能会导致一些意外。这主要取决于PDF文档的内部结构,以及PDF编写器过程如何生成PDF指令流。
使用PyMuPDF提取文本
可从PyPi网站上获取PyMuPDF,并在终端中使用以下命令安装软件包:
$ pip3 install PyMuPDF
- 1
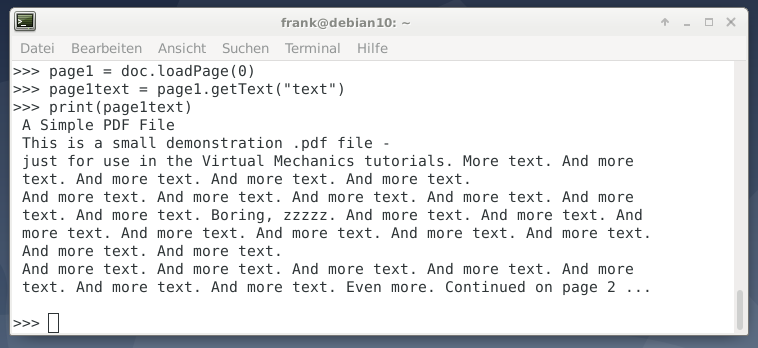
显示文档信息,打印页数以及提取PDF文档的文本的方式与PyPDF2相似(请参见清单2)。要导入的模块名为fitz,并返回到PyMuPDF的先前名称。
清单2:使用PyMuPDF从PDF文档中提取内容。
#!/usr/bin/python
import fitz
pdf_document = "example.pdf"
doc = fitz.open(pdf_document)
print ("number of pages: %i" % doc.pageCount)
print(doc.metadata)
page1 = doc.loadPage(0)
page1text = page1.getText("text")
print(page1text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
PyMuPDF的优点是可以保持原始文档结构完整-带有换行符的整个段落都保留在PDF文档中(参见图2)。
使用PyMuPDF从PDF提取图像
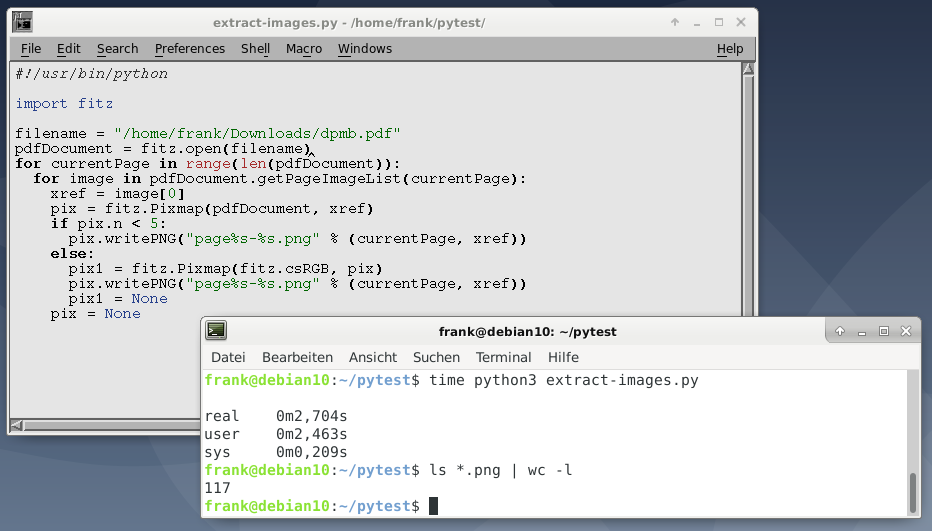
PyMuPDF使用该方法简化了从PDF文档提取图像的过程getPageImageList()。清单3基于PyMuPDF Wiki页面上的示例,并逐页地将PDF中的所有图像提取并保存为PNG文件。如果图像具有CMYK色彩空间,则将首先将其转换为RGB。
清单3:提取图像
#!/usr/bin/python import fitz pdf_document = fitz.open("file.pdf") for current_page in range(len(pdf_document)): for image in pdf_document.getPageImageList(current_page): xref = image[0] pix = fitz.Pixmap(pdf_document, xref) if pix.n < 5: # this is GRAY or RGB pix.writePNG("page%s-%s.png" % (current_page, xref)) else: # CMYK: convert to RGB first pix1 = fitz.Pixmap(fitz.csRGB, pix) pix1.writePNG("page%s-%s.png" % (current_page, xref)) pix1 = None pix = None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在400页PDF上运行此Python脚本,它在不到3秒的时间内提取了117张图像,这真是了不起。单个图像以PNG格式存储。为了保持原始图像的格式和大小,而不是转换为PNG,请查看PyMuPDF Wiki中脚本的扩展版本。
使用PyPDF2将PDF拆分为页面
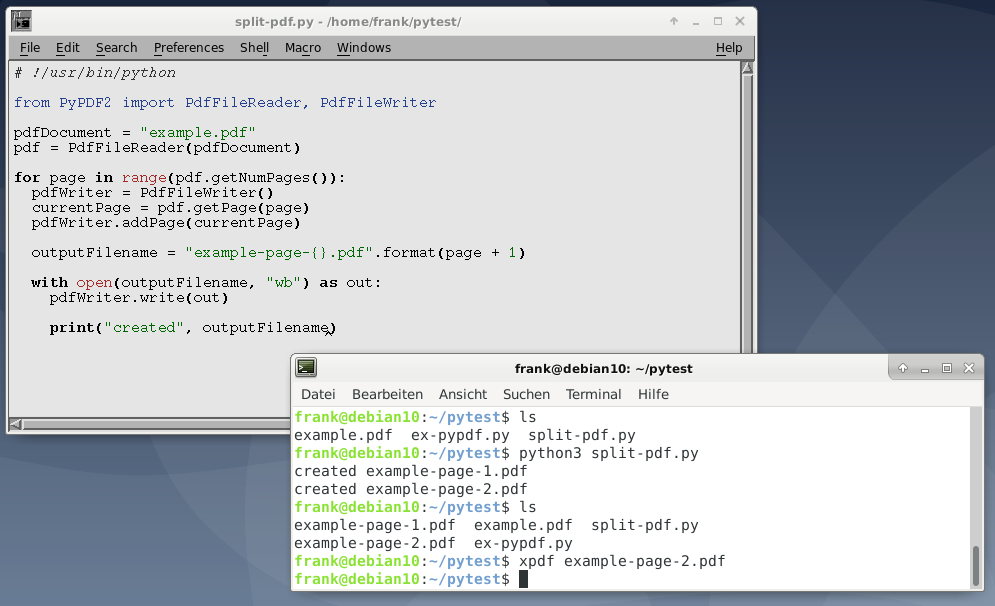
对于此示例,首先需要同时导入PdfFileReader和和PdfFileWriter类。然后,我们打开PDF文件,创建一个阅读器对象,并使用阅读器对象的getNumPages方法遍历所有页面。
在for循环内部,我们创建的新实例PdfFileWriter,该实例尚不包含任何页面。然后,使用pdfWriter.addPage()方法将当前页面添加到我们的writer对象。此方法接受一个页面对象,我们使用该PdfFileReader.getPage()方法获取该对象。
下一步是创建一个唯一的文件名,我们使用原始文件名加上单词“ page”以及页码来完成。我们在当前页码上加1,因为PyPDF2会计算从零开始的页码。
最后,我们以“写二进制”模式(mode wb)打开新文件名,并使用该类的write()方法pdfWriter将提取的页面保存到磁盘。
清单4:将PDF拆分为单个页面。
#!/usr/bin/python from PyPDF2 import PdfFileReader, PdfFileWriter pdf_document = "example.pdf" pdf = PdfFileReader(pdf_document) for page in range(pdf.getNumPages()): pdf_writer = PdfFileWriter() current_page = pdf.getPage(page) pdf_writer.addPage(current_page) outputFilename = "example-page-{}.pdf".format(page + 1) with open(outputFilename, "wb") as out: pdf_writer.write(out) print("created", outputFilename)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
查找所有包含文本的页面
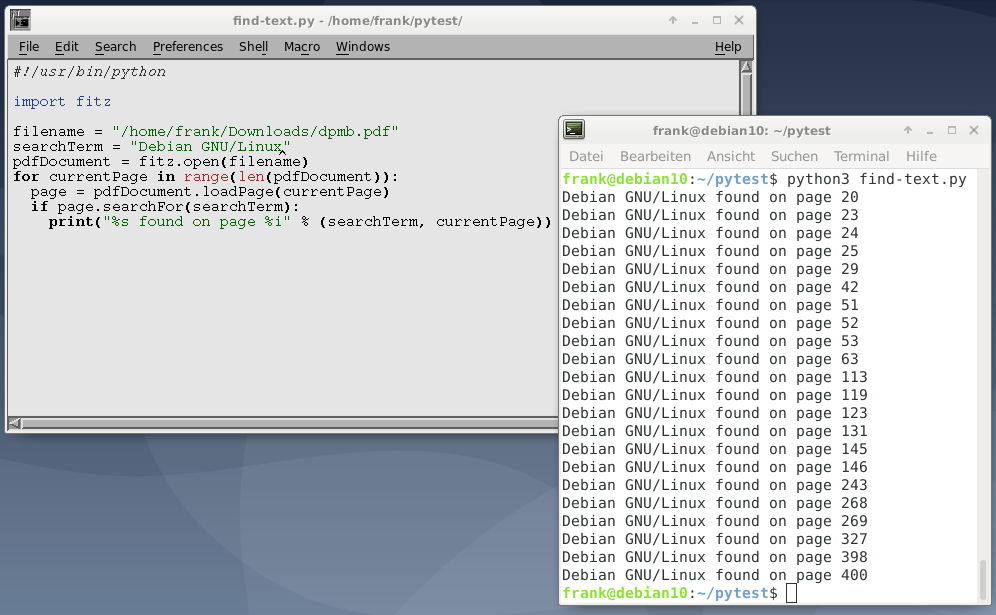
这个用例非常实用,并且工作方式类似于pdfgrep。该脚本使用PyMuPDF返回包含给定搜索字符串的所有页码。页面一页接一页地加载,借助该searchFor()方法,将检测到搜索字符串的所有出现情况。如果匹配则在上面印有相应的信息stdout。
清单5:搜索给定的文本。
#!/usr/bin/python
import fitz
filename = "example.pdf"
search_term = "invoice"
pdf_document = fitz.open(filename):
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面的图5显示了一本400页的书中“ Debian GNU / Linux”一词的搜索结果。
结论
此处显示的处理PDF方法非常强大。使用相对较少的代码行数,很容易获得结果。


