
- 1小米汽车充电枪继电器信号
- 2arduino编译失败_arduino DTH温度程序出现编译错误的解决办法
- 3线性规划、整数规划开源求解器——OR-Tools_线性规划求解器
- 4Linux学习阶段划分及学习方法
- 5git克隆远程仓库的指定分支方法(附常用git配置命令)_git克隆至另一个远程项目
- 6敏捷考证?你应该知道的敏捷体系认证(最全名单)
- 7error: Two output files share the same path but have different contents: node_modules\.vite\..xxx.js
- 8【小罗的hdlbits刷题笔记2】补码运算中溢出的问题(Exams/ece241 2014 q1c)
- 9Centos7.5安装RabbitMQ3.8.8_rabbitmq-server-3.8.8-arm64.zip 下载
- 10免费邮件服务器安装,免费邮件服务器 hMailServer 试用(1)安装
Hive大数据开发_hive开发
赞
踩
1 Hive基本概念
1.1 Hive简介
1.1.1 什么是Hive
Hive由Facebook实现并开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据映射为一张数据库表,并提供**HQL(Hive SQL)**查询功能,底层数据是存储在HDFS上。Hive的本质是将SQL语句转换为 MapReduce任务运行,使不熟悉MapReduce的用户很方便地利用HQL处理和计算HDFS上的结构化的数据,适用于离线的批量数据计算。
主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高,Hive依赖于HDFS存储数据,Hive将HQL转换成MapReduce执行。
所以说Hive是基于hadoop的一个数据仓库工具,实质就是一款基于HDFS的MapReduce计算框架

1.1.2 为什么使用Hive
直接使用MapReduce所面临的问题:
-
人员学习成本太高
-
项目周期要求太短
-
MapReduce实现复杂查询逻辑开发难度太大
为什么要使用Hive:
-
更友好的接口:操作接口采用类SQL的语法,提供快速开发的能力
-
更低的学习成本:避免了写MapReduce,减少开发人员的学习成本
-
更好的扩展性:可自由扩展集群规模而无需重启服务,还支持用户自定义函数
1.1.3 Hive特点
优点:
1、可扩展性,横向扩展,Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
横向扩展:通过分担压力的方式扩展集群的规模
纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
2、延展性,Hive支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、良好的容错性,可以保障即使有节点出现问题,SQL语句仍可完成执行
缺点:
1、hive不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结果导入到文件中(当前选择的hive-1.2.1的版本支持记录级别的插入操作)
2、Hive的查询延时很严重,因为MapReduce Job的启动过程消耗很长时间,所以不能用在交互查询系统中。
3、hive不支持事务(因为不没有增删改,所以主要用来做OLAP(联机分析处理),而不是OLTP(联机事务处理),这就是数据处理的两大级别)。
1.2 Hive的体系架构
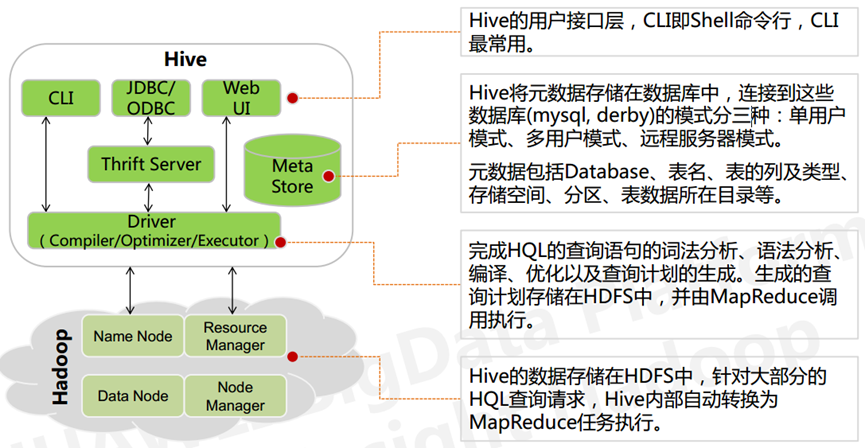
基本组成
用户接口:
-
CLI,Shell终端命令行,最常用(学习,调试,生产)
-
JDBC/ODBC,是Hive的基于JDBC操作提供的客户端,用户(开发员,运维人员)通过这连接至Hive server
-
Web UI,通过浏览器访问Hive
元数据存储:
- 元数据,通俗的讲,就是存储在Hive中的数据的描述信息。
Hive中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和外部表),表的数据所在目录
Metastore默认存在自带的Derby数据库中。缺点就是不适合多用户操作,并且数据存储目录不固定。数据库跟着Hive走,极度不方便管理
解决方案:通常存我们自己创建的MySQL库(本地 或 远程)
解释器,编译器,优化器,执行器
这四大组件完成HQL查询语句从词法分析,语法分析,编译,优化,以及生成查询计划的生成。生成的查询计划存储在HDFS中,并随后由MapReduce调用执行
执行流程
HiveQL通过命令行或者客户端提交,经过Compiler编译器,运用Metastore中的元数据进行类型检测和语法分析,生成一个逻辑方案(logical plan),然后通过的优化处理,产生一个MapReduce任务。
1.3 Hive和RDBMS的对比
| 对比项 | Hive | RDBMS |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行器 | MapReduce | Executor |
| 数据插入 | 支持批量导入/单条插入 | 支持单条或者批量导入 |
| 数据操作 | 覆盖追加 | 行级更新删除 |
| 处理数据规模 | 大 | 小 |
| 执行延迟 | 高 | 低 |
| 分区 | 支持 | 支持 |
| 索引 | 0.8版本之后加入简单索 | 支持复杂的索引 |
| 扩展性 | 高(好) | 有限(差) |
| 数据加载模式 | 读时模式(快) | 写时模式(慢) |
| 应用场景 | 海量数据查询 | 实时查询 |
总结:Hive具有SQL数据库的外表,但应用场景完全不同,Hive只适合用来做海量离线数据统计分析,也就是数据仓库。
1.4 Hive的数据存储
1、Hive的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对应HDFS上的一个目录。表数据对应HDFS对应目录下的文件。
2、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持TextFile,SequenceFile,RCFILE或者自定义格式等)
3、 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
4、Hive中包含以下数据模型:
database:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属database目录下一个文件夹
external table:与table类似,不过其数据存放位置可以指定任意HDFS目录路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录或者分区目录下根据hash散列之后的多个文件
view:与传统数据库类似,只读,基于基本表创建
5、Hive的元数据存储在RDBMS中,除元数据外的其它所有数据都基于HDFS存储。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
6、Hive中的表分为内部表、外部表、分区表和Bucket。
2 Hive基本使用
1、 创建库:create database mydb;
2、 查看库:show databases;
3、 切换数据库:use mydb;
4、 创建表:create table t_user(id string, name string)
或create table t_user2 (id string, name string) row format delimited fields terminated by ‘,’;
5、 插入数据:insert into table t_user values(‘001’,‘mazhonghua’);
6、 查询数据:select * from t_user;
7、 导入数据(后面会说动静态分区):
a) 导入HDFS数据: load data inpath ‘/mingxing.txt’ into table t_user1;
b) 导入本地数据:load data local inpath ‘/root/mingxing.txt’ into table t_user1;
小技能补充:
1、 进入到用户的主目录,使用命令cat /home/hadoop/.hivehistory可以查看到hive执行的历史命令
2、 执行查询时若想显示表头信息时,请执行命令:
Hive> set hive.cli.print.header=true;
3、 hive的执行日志的存储目录在 j a v a . i o . t m p d i r / {java.io.tmpdir}/ java.io.tmpdir/{user.name}/hive.log中,假如使用hadoop用户操作的hive,那么日志文件的存储路径为:/temp/hadoop/hive.log
2.1 Hive存储格式
- hive的存储格式分为行式存储和列式存储
- hive的默认存储方式是行式存储中的TextFile,除此之外,还有SequenceFile
- 列式存储也有两个:ORC和PARQUET
以下是行式存储和列式存储的示意图
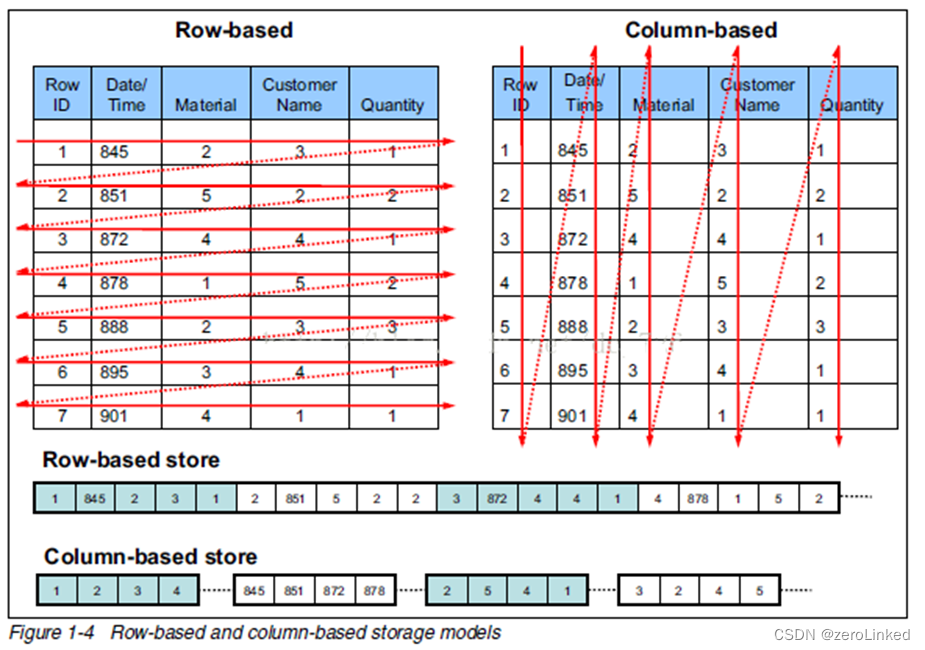
当我们选择使用行式存储,查询所有字段的时候,查询效率最高,如:
SELECT * FROM TABLE_NAME [WHERE CONDITION]
- 1
但是,如果查询具体某几个字段时,查询效率就比较低,但对于列式存储来说,效率却能得到很大提升。一般项目中,我们使用的是列式存储,一般使用的是ORC存储
- 建表时指定存储格式
这过程中,使用ORC列式存储方式的数据会进行压缩,使数据的摆放方式更加合理。
orc内部默认采用的压缩算法是zlib
-- 建表(默认) create table test_text ( id int, name string ) row format delimited fields terminated by '\t'; -- 加载数据到test_text load data inpath '/hive/text.log' into test_text; -- 建表(orc) create table test_orc ( id int, name string ) row format delimited fields terminated by '\t' stored as orc; -- 加载数据,查询并插入(执行MapReduce) insert into test_orc select * from test_text;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 建表时指定存储格式的压缩算法
上面说到ORC的默认压缩算法为zlib,我们也可以通过设置去指定其压缩算法
create table test_orc_snappy(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");
- 1
- 2
- 3
- 4
- 5
- 6
所以,结合压缩算法,我们对hive的分层中,可以通过存储格式和压缩方式进行结合,达到我们对每个分层的优化效果
| 层级 | 压缩方式 | 存储格式 | 原因 |
|---|---|---|---|
| ODS层 | zlib、gz、bz2 | ORC | 省空间 |
| DW层 | snappy | ORC | 速度快 |
| DA层 | snappy | ORC | 速度快 |
2.2 Hive中的数据模型
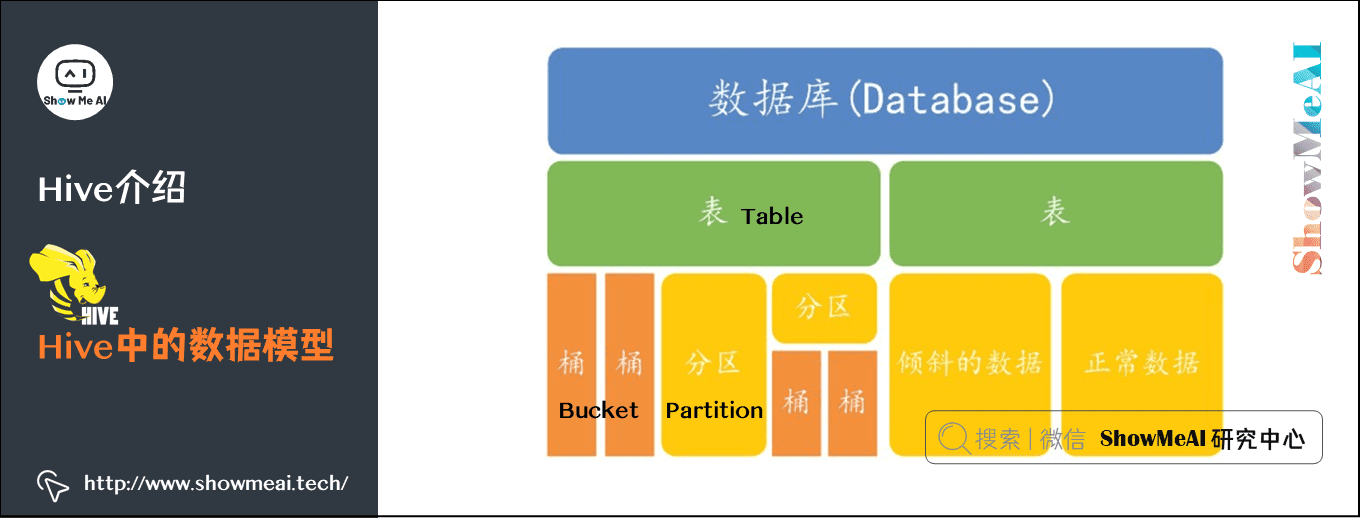
Hive 中所有的数据都存储在 HDFS 中Hive 中包含以下数据模型:
- 表(Table)
- 外部表(External Table)
- 分区(Partition)
- 桶(Bucket)
3 Hive应用
3.1 Hive内置函数
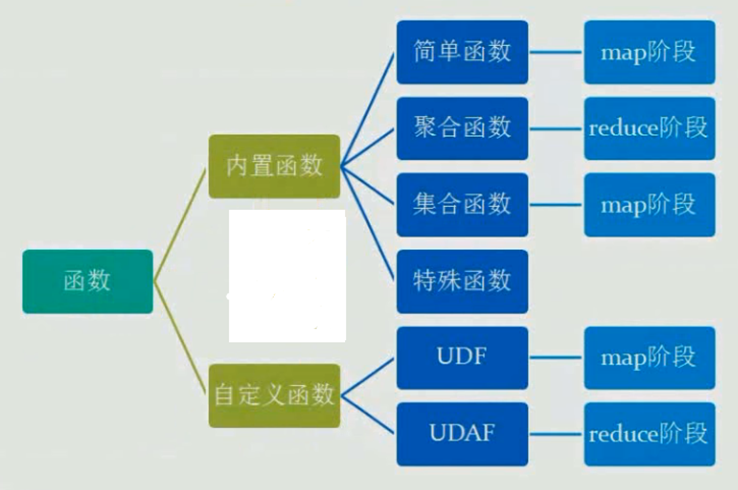
| 关系运算 | 数学运算 | 逻辑运算 | 复合类型构造函数 | 复合类型操作符 | 数值计算函数 | 集合操作函数 | 类型转换函数 | 日期函数 | 汇总统计函数(UDAF) |
|---|---|---|---|---|---|---|---|---|---|
| 等值比较: = | 加法操作: + | 逻辑与操作: AND 、&& | map结构 | 获取array中的元素 | 取整函数: round | map类型大小:size | 二进制转换:binary | UNIX时间戳转日期函数: from_unixtime | 个数统计函数: count |
| 等值比较:<=> | 减法操作: – | 逻辑或操作: OR 、|| | struct结构 | 获取map中的元素 | 指定精度取整函数: round | array类型大小:size | 基础类型之间强制转换:cast | 获取当前UNIX时间戳函数: unix_timestamp | 总和统计函数: sum |
| 不等值比较: <>和!= | 乘法操作: * | 逻辑非操作: NOT、! | named_struct结构 | 获取struct中的元素 | 向下取整函数: floor | 判断元素数组是否包含元素:array_contains | 日期转UNIX时间戳函数: unix_timestamp | 平均值统计函数: avg | |
| 小于比较: < | 除法操作: / | array结构 | 向上取整函数: ceil | 获取map中所有value集合 | 指定格式日期转UNIX时间戳函数: unix_timestamp | 最小值统计函数: min | |||
| 小于等于比较: <= | 取余操作: % | create_union | 向上取整函数: ceiling | 获取map中所有key集合 | 日期时间转日期函数: to_date | 最大值统计函数: max | |||
| 大于比较: > | 位与操作: & | 取随机数函数: rand | 数组排序 | 日期转年函数: year | 非空集合总体变量函数: var_pop | ||||
| 大于等于比较: >= | 位或操作: | 自然指数函数: exp | 日期转月函数: month | 非空集合样本变量函数: var_samp | |||||
| 区间比较 | 位异或操作: ^ | 以10为底对数函数: log10 | 日期转天函数: day | 总体标准偏离函数: stddev_pop | |||||
| 空值判断: IS NULL | 位取反操作: ~ | 以2为底对数函数: log2 | 日期转小时函数: hour | 样本标准偏离函数: stddev_samp | |||||
| 非空判断: IS NOT NULL | 对数函数: log | 日期转分钟函数: minute | 中位数函数: percentile | ||||||
| LIKE比较: LIKE | 幂运算函数: pow | 日期转秒函数: second | 近似中位数函数: percentile_approx | ||||||
| JAVA的LIKE操作: RLIKE | 幂运算函数: power | 日期比较函数: datediff | 直方图: histogram_numeric | ||||||
| REGEXP操作: REGEXP | 开平方函数: sqrt | 日期增加函数: date_add | 集合去重数:collect_set |
3.2 SQL介绍与Hive应用场景
3.2.1 数据库操作和表操作
| 作用 | HiveQL |
|---|---|
| 查看所有数据库 | SHOW DATABASES; |
| 使用指定的数据库 | USE database_name; |
| 创建指定名称的数据库 | CREATE DATABASE database_name; |
| 删除数据库 | DROP DATABASE database_name; |
| 创建表 | CREATE TABLE pokes (foo INT, bar STRING) |
| 查看所有的表 | SHOW TABLES |
| 支持模糊查询 | SHOW TABLES ‘TMP’ |
| 查看表有哪些分区 | SHOW PARTITIONS TMP_TABLE |
| 查看表结构 | DESCRIBE TMP_TABLE |
| 创建表并创建索引ds | CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING) |
| 复制一个空表 | CREATE TABLE empty_key_value_store LIKE key_value_store |
| 表添加一列 | ALTER TABLE pokes ADD COLUMNS (new_col INT) |
| 更改表名 | ALTER TABLE events RENAME TO 3koobecaf |
3.2.2 查询语句
| 作用 | HiveQL |
|---|---|
| 检索信息 | SELECT from_columns FROM table WHERE conditions; |
| 选择所有的数据 | SELECT * FROM table; |
| 行筛选 | SELECT * FROM table WHERE rec_name = “value”; |
| 多个限制条件 | SELECT * FROM TABLE WHERE rec1 = “value1” AND rec2 = “value2”; |
| 选择多个特定的列 | SELECT column_name FROM table; |
| 检索unique输出记录 | SELECT DISTINCT column_name FROM table; |
| 排序 | SELECT col1, col2 FROM table ORDER BY col2; |
| 逆序 | SELECT col1, col2 FROM table ORDER BY col2 DESC; |
| 统计行数 | SELECT COUNT(*) FROM table; |
| 分组统计 | SELECT owner, COUNT(*) FROM table GROUP BY owner; |
| 求某一列最大值 | SELECT MAX(col_name) AS label FROM table; |
| 从多个表中检索信息 | SELECT pet.name, comment FROM pet JOIN event ON (pet.name = event.name); |
4 HIVE数据的压缩与存储格式
4.1 压缩
4.1.1 压缩概述
压缩技术能够有效减少底层存储系统(HDFS)读写字节数。压缩提高了网络带宽和磁盘空间的效率。在运行MR程序时,I/O操作、网络数据传输、 Shuffle和Merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下,因此,使用数据压缩显得非常重要。
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。可以在任意MapReduce阶段启用压缩。不过,尽管压缩与解压操作的CPU开销不高,其性能的提升和资源的节省并非没有代价。
4.1.2 压缩策略与原则
压缩是提高Hadoop运行效率的一种优化策略。通过对Mapper、Reducer运行过程的数据进行压缩,以减少磁盘IO,
提高MR程序运行速度。
注意:采用压缩技术减少了磁盘IO,但同时增加了CPU运算负担。所以,压缩特性运用得当能提高性能,但运用不当也可能降低性能。
压缩基本原则:
- 运算密集型的job,少用压缩
- IO密集型的job,多用压缩
4.2 Hadoop压缩配置
4.2.1 MR支持的压缩编码
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| DEFLATE | DEFLATE | .deflate | 否 |
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .bz2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappy | 否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
按照Hive对数据的分层,我们可以在对应层使用这样的压缩方式:
| 层级 | 压缩方式 | 原因 |
|---|---|---|
| ODS层 | zlib、gz、bz2 | 省空间 |
| DW层 | snappy | 速度快 |
| DA层 | snappy | 速度快 |
- 相关参数设置
-- 开启Map端压缩
set hive.exec.compress.intermediate=true;
set mapreduce.map.output.compress=true;
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
-- 开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
-- 开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
-- 设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
-- 设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.2.2 压缩方式选择
4.2.2.1 Gzip压缩
优点:压缩率比较高,而且压缩/解压速度也比较快;Hadoop本身支持,在应用中处理Gzip格式的文件就和直接处理文本一样;大部分Linux系统都自带Gzip命令,使用方便。
缺点:不支持Split。
应用场景:当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用Gzip压缩格式。例如说一天或者一个小时的日志压缩成一个Gzip文件。
4.2.2.2 Bzip2压缩
优点:支持Split;具有很高的压缩率,比Gzip压缩率都高;Hadoop本身自带,使用方便。
缺点:压缩/解压速度慢。
应用场景:适合对速度要求不高,但需要较高的压缩率的时候;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持Split,而且兼容之前的应用程序的情况。
4.2.2.3 Lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率;支持Split,是Hadoop中最流行的压缩格式;可以在Linux系统下安装lzop命令,使用方便。
缺点:压缩率比Gzip要低一些;Hadoop本身不支持,需要安装;在应用中对Lzo格式的文件需要做一些特殊处理(为了支持Split需要建索引,还需要指定InputFormat为Lzo格式)。
应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,Lzo优点越越明显。
4.2.2.4 Snappy压缩
优点:高速压缩速度和合理的压缩率。
缺点:不支持Split;压缩率比Gzip要低;Hadoop本身不支持,需要安装。
应用场景:当MapReduce作业的Map输出的数据比较大的时候,作为Map到Reduce的中间数据的压缩格式;或者作为一个MapReduce作业的输出和另外一个MapReduce作业的输入。
4.2.3 压缩参数配置
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
4.3 开启Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。具体配置如下:
- 开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
- 1
- 开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
- 1
- 设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
- 1
- 2
- 执行查询语句
hive (default)> select count(ename) name from emp;
- 1
4.4 开启Reduce输出阶段压缩
当Hive将输出写入到表中时,输出内容同样可以进行压缩。属性hive.exec.compress.output控制着这个功能。用户可能需要保持默认设置文件中的默认值false,这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为true,来开启输出结果压缩功能。
-
开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;- 1
-
开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;- 1
-
设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;- 1
- 2
-
设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;- 1
-
测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;- 1
- 2
4.5 文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。(前两个行存,后两个列存)
4.5.1 列式存储和行式存储
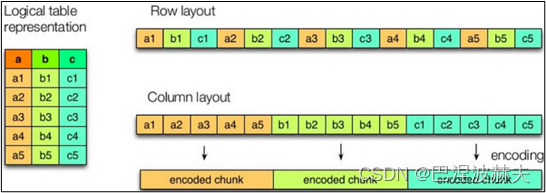
如图所示,左边为逻辑表,右边是底层存储格式,其中第一个为行式存储,第二个为列式存储。
-
行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
-
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
4.5.2 TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
4.5.3 Orc格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如下图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
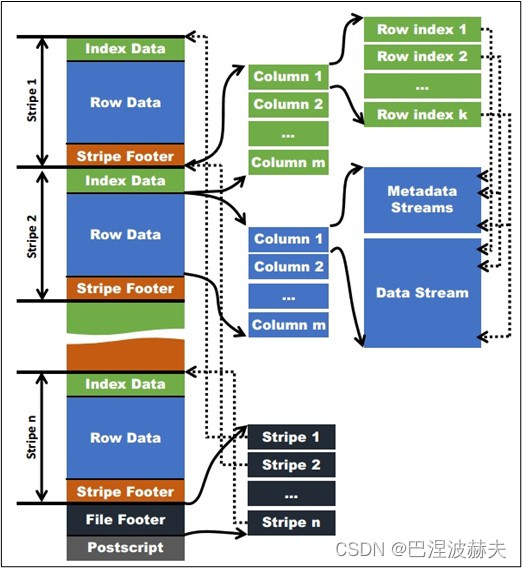
- Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
- Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
- Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到FileFooter长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
4.5.4 Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
- 行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
- 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式。
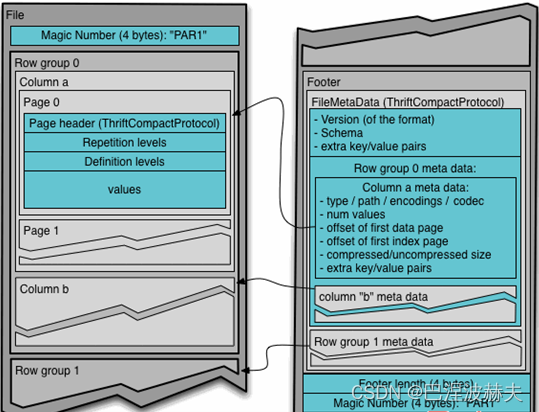
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
4.5.5 主流文件存储格式对比实验
log.data文件下载
链接:https://pan.baidu.com/s/1fvnZ29iMZqRtrdzy5JoAQg
提取码:9wi0
- TextFile
-- 创建表,存储数据格式为TEXTFILE create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as textfile; -- 向表中加载数据 hive (default)> load data local inpath '/opt/module/hive/datas/log.data' into table log_text ; -- 查看表中数据大小 hive (default)> dfs -du -h /user/hive/warehouse/log_text;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- ORC
-- 创建表,存储数据格式为ORC create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as orc tblproperties("orc.compress"="NONE"); -- 设置orc存储不使用压缩 -- 向表中加载数据(直接load会报编码格式不匹配的错误) hive (default)> insert into table log_orc select * from log_text ; -- 查看表中数据大小 hive (default)> dfs -du -h /user/hive/warehouse/log_orc/ ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- Parquet
-- 创建表,存储数据格式为parquet create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as parquet ; -- 向表中加载数据 hive (default)> insert into table log_parquet select * from log_text; -- 查看表中数据大小 hive (default)> dfs -du -h /user/hive/warehouse/log_parquet/;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
TextFile:18.13 MB->18.13 MB,time: 0.504 s
ORC:18.13 MB->7.69 MB,time: 4.698 s
Parquet:18.13MB->13.09 MB,time: 5.506 s
4.5.6 存储和压缩结合
- ZLIB压缩的ORC存储方式
-- 建表
create table log_orc_zlib(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
-- 导数据
insert into log_orc_zlib select * from log_text;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 创建一个SNAPPY压缩的ORC存储方式
-- 建表
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
-- 导数据
insert into log_orc_snappy select * from log_text;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 创建一个SNAPPY压缩的parquet存储方式
-- 建表
create table log_parquet_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
-- 导数据
insert into log_parquet_snappy select * from log_text;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ORC_ZLIB:18.13 MB->2.78 MB,time: 4.949 s
ORC_SNAPPY:18.13 MB->3.75 MB,time: 3.87 s
Parquet_SNAPPY:18.13MB->6.07 MB,time: 3.877 s
5 Hive和HBase区别
5.1 Hive
1.Hive是hadoop数据仓库管理工具,严格来说,不是数据库,本身是不存储数据和处理数据的,其依赖于HDFS存储数据,依赖于MapReducer进行数据处理。
2.Hive的优点是学习成本低,可以通过类SQL语句(HSQL)快速实现简单的MR任务,不必开发专门的MR程序。
3.由于Hive是依赖于MapReducer处理数据的,因此有很高的延迟性,不适用于实时数据处理(数据查询,数据插入,数据分析),适用于离线数据的批处理。
5.2 HBase
1.HBase是一种分布式、可扩展、支持海量数据存储的NOSQL数据库
2.HBase主要适用于海量数据的实时数据处理(随机读写)
3.由于HDFS不支持随机读写,而HBase正是为此而诞生的,弥补了HDFS的不可随机读写。
5.3 共同点
hbase与hive都是架构在hadoop之上的。都是用HDFS作为底层存储。
Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
5.4 区别
-
Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。总的来说,hive是适用于离线数据的批处理,hbase是适用于实时数据的处理。
-
Hive本身不存储和计算数据,它完全依赖于HDFS存储数据和MapReduce处理数据,Hive中的表纯逻辑。
-
Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
- 通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
- 基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据;
-
hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
-
Hbase:Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
-
.由于HDFS的不可随机读写,hive是不支持随机写操作,而hbase支持随机写入操作。
-
HBase只支持简单的键查询,不支持复杂的条件查询

5.5 关系说明一
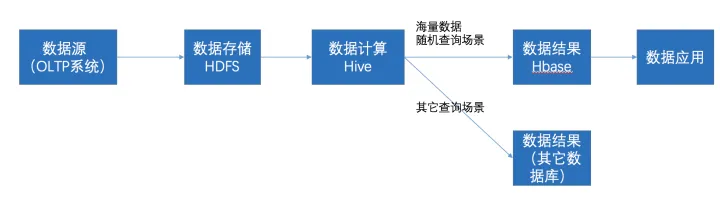
在大数据架构中,Hive和HBase是协作关系,这里就举例一种常用的协作关系,具体流程如下图:
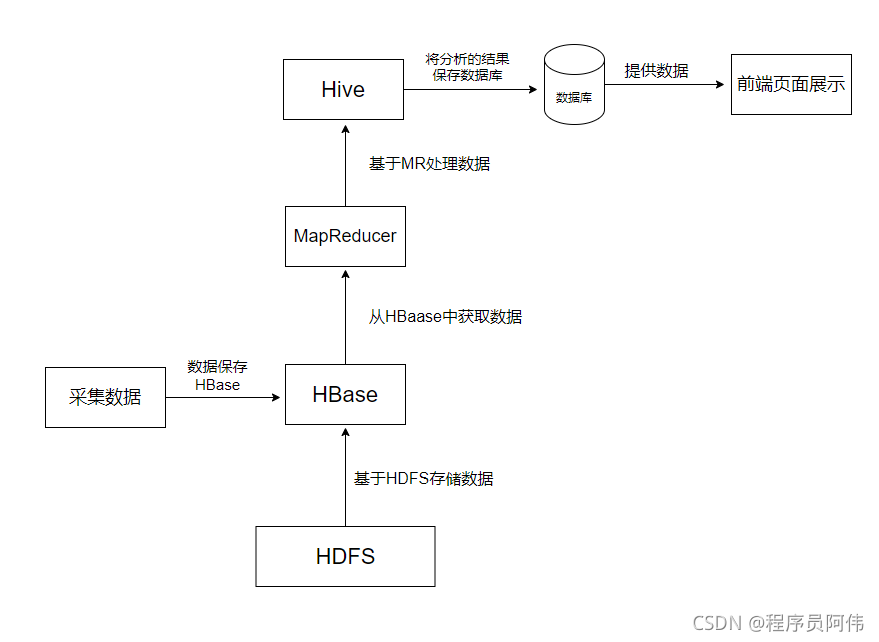
流程:
1.Hive创建一张外部表与HBase表关联,因此只需对Hive表进行查询即可,Hive表会自动从关联的HBase表中获取数据
2.采集的数据保存到HBase表,因为HBase表支持随机写操作,这个可以根据业务需求决定
3.Hive通过HSQ语句创建MR任务去处理分析数据
3.MR将分析的结果最终存储到常用的数据库(Mysql数据库)
4.web端从数据库获取数据进行可视化
5.6 关系说明二
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
6 Hive优化
6.1 Hive优化缘由
首先,我们来看看Hadoop的计算框架特性,在此特性下会衍生哪些问题?
- 数据量大不是问题,数据倾斜是个问题。
- jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,耗时很长。原因是map reduce作业初始化的时间是比较长的。
- sum,count,max,min等UDAF,不怕数据倾斜问题,hadoop在map端的汇总合并优化,使数据倾斜不成问题。
- count(distinct ),在数据量大的情况下,效率较低,如果是多count(distinct )效率更低,因为count(distinct)是按group by 字段分组,按distinct字段排序,一般这种分布方式是很倾斜的。举个例子:比如男uv,女uv,像淘宝一天30亿的pv,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
面对这些问题,我们能有哪些有效的优化手段呢?下面列出一些在工作有效可行的优化手段:
- 好的模型设计事半功倍。
- 解决数据倾斜问题。
- 减少job数。
- 设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。
- 了解数据分布,自己动手解决数据倾斜问题是个不错的选择。set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题。
- 数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
- 对小文件进行合并,是行至有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响。
- 优化时把握整体,单个作业最优不如整体最优。
而接下来,我们心中应该会有一些疑问,影响性能的根源是什么?
6.2 性能低下的根源
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。
Hadoop的核心能力是parition和sort,因而这也是优化的根本。
观察Hadoop处理数据的过程,有几个显著的特征:
- 数据的大规模并不是负载重点,造成运行压力过大是因为运行数据的倾斜。
- jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联对此汇总,产生几十个jobs,将会需要30分钟以上的时间且大部分时间被用于作业分配,初始化和数据输出。M/R作业初始化的时间是比较耗时间资源的一个部分。
- 在使用SUM,COUNT,MAX,MIN等UDAF函数时,不怕数据倾斜问题,Hadoop在Map端的汇总合并优化过,使数据倾斜不成问题。
- COUNT(DISTINCT)在数据量大的情况下,效率较低,如果多COUNT(DISTINCT)效率更低,因为COUNT(DISTINCT)是按GROUP BY字段分组,按DISTINCT字段排序,一般这种分布式方式是很倾斜的;比如:男UV,女UV,淘宝一天30亿的PV,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
- 数据倾斜是导致效率大幅降低的主要原因,可以采用多一次 Map/Reduce 的方法, 避免倾斜。
最后得出的结论是:避实就虚,用 job 数的增加,输入量的增加,占用更多存储空间,充分利用空闲 CPU 等各种方法,分解数据倾斜造成的负担。
6.3 配置角度优化
我们知道了性能低下的根源,同样,我们也可以从Hive的配置解读去优化。Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制, 以下举例介绍部分优化的策略以及优化控制选项。
6.3.1 列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。例如,若有以下查询:
SELECT a,b FROM q WHERE e<10;
- 1
在实施此项查询中,Q 表有 5 列(a,b,c,d,e),Hive 只读取查询逻辑中真实需要 的 3 列 a、b、e,而忽略列 c,d;这样做节省了读取开销,中间表存储开销和数据整合开销。
裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)
6.3.2 分区裁剪
可以在查询的过程中减少不必要的分区。例如,若有以下查询:
SELECT * FROM (SELECTT a1,COUNT(1) FROM T GROUP BY a1) subq WHERE subq.prtn=100; #(多余分区)SELECT * FROM T1 JOIN (SELECT * FROM T2) subq ON (T1.a1=subq.a2) WHERE subq.prtn=100;
- 1
查询语句若将“subq.prtn=100”条件放入子查询中更为高效,可以减少读入的分区 数目。Hive 自动执行这种裁剪优化。
分区参数为:hive.optimize.pruner=true(默认值为真)
6.3.3 JOIN操作
在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。所以对于同一个 key 来说,对应的 value 值小的放前,大的放后,这便是“小表放前”原则。若一条语句中有多个 Join,依据 Join 的条件相同与否,有不同的处理方法。
6.3.3.1 JOIN原则
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x ON (u.userid = x.userid);
- 1
- 2
- 3
- 4
- 如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce
- 一个 Map-Reduce 任务,而不是 ‘n’ 个
- 在做 OUTER JOIN 的时候也是一样
如果 Join 的条件不相同,比如:
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age FROM page_view p
JOIN user u ON (pv.userid = u.userid)
JOIN newuser x on (u.age = x.age);
- 1
- 2
- 3
- 4
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的:
INSERT OVERWRITE TABLE tmptable
SELECT * FROM page_view p JOIN user u
ON (pv.userid = u.userid);
INSERT OVERWRITE TABLE pv_users
SELECT x.pageid, x.age FROM tmptable x
JOIN newuser y ON (x.age = y.age);
- 1
- 2
- 3
- 4
- 5
- 6
6.3.4 MAP JOIN操作
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。比如查询:
INSERT OVERWRITE TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid);
- 1
- 2
- 3
- 4
可以在 Map 阶段完成 Join.
相关的参数为:
- hive.join.emit.interval = 1000
- hive.mapjoin.size.key = 10000
- hive.mapjoin.cache.numrows = 10000
6.3.5 GROUP BY操作
进行GROUP BY操作时需要注意一下几点:
- Map端部分聚合
事实上并不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
- 有数据倾斜时进行负载均衡
此处需要设定 hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
6.3.6 合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
- 是否合并Map输出文件:hive.merge.mapfiles=true(默认值为真)
- 是否合并Reduce 端输出文件:hive.merge.mapredfiles=false(默认值为假)
- 合并文件的大小:hive.merge.size.per.task=25610001000(默认值为 256000000)
6.4 程序角度优化
6.4.1 熟练使用SQL提高查询
熟练地使用 SQL,能写出高效率的查询语句。
场景:有一张 user 表,为卖家每天收到表,user_id,ds(日期)为 key,属性有主营类目,指标有交易金额,交易笔数。每天要取前10天的总收入,总笔数,和最近一天的主营类目。
解决方法 1
如下所示:常用方法
INSERT OVERWRITE TABLE t1
SELECT user_id,substr(MAX(CONCAT(ds,cat),9) AS main_cat) FROM users
WHERE ds=20120329 // 20120329 为日期列的值,实际代码中可以用函数表示出当天日期 GROUP BY user_id;
INSERT OVERWRITE TABLE t2
SELECT user_id,sum(qty) AS qty,SUM(amt) AS amt FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
SELECT t1.user_id,t1.main_cat,t2.qty,t2.amt FROM t1
JOIN t2 ON t1.user_id=t2.user_id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
下面给出方法1的思路,实现步骤如下:
第一步:利用分析函数,取每个 user_id 最近一天的主营类目,存入临时表 t1。
第二步:汇总 10 天的总交易金额,交易笔数,存入临时表 t2。
第三步:关联 t1,t2,得到最终的结果。
解决方法 2
如下所示:优化方法
SELECT user_id,substr(MAX(CONCAT(ds,cat)),9) AS main_cat,SUM(qty),SUM(amt) FROM users
WHERE ds BETWEEN 20120301 AND 20120329
GROUP BY user_id
- 1
- 2
- 3
在工作中我们总结出:方案 2 的开销等于方案 1 的第二步的开销,性能提升,由原有的 25 分钟完成,缩短为 10 分钟以内完成。节省了两个临时表的读写是一个关键原因,这种方式也适用于 Oracle 中的数据查找工作。
SQL 具有普适性,很多 SQL 通用的优化方案在 Hadoop 分布式计算方式中也可以达到效果。
6.4.2 无效ID在关联时的数据倾斜问题
问题:日志中常会出现信息丢失,比如每日约为 20 亿的全网日志,其中的 user_id 为主 键,在日志收集过程中会丢失,出现主键为 null 的情况,如果取其中的 user_id 和 bmw_users 关联,就会碰到数据倾斜的问题。原因是 Hive 中,主键为 null 值的项会被当做相同的 Key 而分配进同一个计算 Map。
解决方法 1:user_id 为空的不参与关联,子查询过滤 null
SELECT * FROM log a
JOIN bmw_users b ON a.user_id IS NOT NULL AND a.user_id=b.user_id
UNION All SELECT * FROM log a WHERE a.user_id IS NULL
- 1
- 2
- 3
解决方法 2 如下所示:函数过滤 null
SELECT * FROM log a LEFT OUTER
JOIN bmw_users b ON
CASE WHEN a.user_id IS NULL THEN CONCAT(‘dp_hive’,RAND()) ELSE a.user_id END =b.user_id;
- 1
- 2
- 3
调优结果:原先由于数据倾斜导致运行时长超过 1 小时,解决方法 1 运行每日平均时长 25 分钟,解决方法 2 运行的每日平均时长在 20 分钟左右。优化效果很明显。
我们在工作中总结出:解决方法2比解决方法1效果更好,不但IO少了,而且作业数也少了。解决方法1中log读取两次,job 数为2。解决方法2中 job 数是1。这个优化适合无效 id(比如-99、 ‘’,null 等)产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。因为空值不参与关联,即使分到不同 的 Reduce 上,也不会影响最终的结果。附上 Hadoop 通用关联的实现方法是:关联通过二次排序实现的,关联的列为 partion key,关联的列和表的 tag 组成排序的 group key,根据 pariton key分配Reduce。同一Reduce内根据group key排序。
6.4.3 不同数据类型关联产生的倾斜问题
问题:不同数据类型 id 的关联会产生数据倾斜问题。
一张表 s8 的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。s8 的日志中有 32 为字符串商品 id,也有数值商品 id,日志中类型是 string 的,但商品中的 数值 id 是 bigint 的。猜想问题的原因是把 s8 的商品 id 转成数值 id 做 hash 来分配 Reduce, 所以字符串 id 的 s8 日志,都到一个 Reduce 上了,解决的方法验证了这个猜测。
解决方法:把数据类型转换成字符串类型
SELECT * FROM s8_log a LEFT OUTERJOIN r_auction_auctions b ON a.auction_id=CASE(b.auction_id AS STRING)
- 1
调优结果显示:数据表处理由 1 小时 30 分钟经代码调整后可以在 20 分钟内完成。
6.4.4 利用Hive对UNION ALL优化的特性
多表 union all 会优化成一个 job。
问题:比如推广效果表要和商品表关联,效果表中的 auction_id 列既有 32 为字符串商 品 id,也有数字 id,和商品表关联得到商品的信息。
解决方法:Hive SQL 性能会比较好
SELECT * FROM effect a
JOIN
(SELECT auction_id AS auction_id FROM auctions
UNION All
SELECT auction_string_id AS auction_id FROM auctions) b
ON a.auction_id=b.auction_id
- 1
- 2
- 3
- 4
- 5
- 6
比分别过滤数字 id,字符串 id 然后分别和商品表关联性能要好。
这样写的好处:1 个 MapReduce 作业,商品表只读一次,推广效果表只读取一次。把 这个 SQL 换成 Map/Reduce 代码的话,Map 的时候,把 a 表的记录打上标签 a,商品表记录 每读取一条,打上标签 b,变成两个<key,value>对,<(b,数字 id),value>,<(b,字符串 id),value>。
所以商品表的 HDFS 读取只会是一次。
6.4.5 解决Hive对UNION ALL优化的短板
Hive 对 union all 的优化的特性:对 union all 优化只局限于非嵌套查询。
- 消灭子查询内的 group by
示例 1:子查询内有 group by
SELECT * FROM
(SELECT * FROM t1 GROUP BY c1,c2,c3 UNION ALL SELECT * FROM t2 GROUP BY c1,c2,c3)t3
GROUP BY c1,c2,c3
- 1
- 2
- 3
从业务逻辑上说,子查询内的 GROUP BY 怎么都看显得多余(功能上的多余,除非有 COUNT(DISTINCT)),如果不是因为 Hive Bug 或者性能上的考量(曾经出现如果不执行子查询 GROUP BY,数据得不到正确的结果的 Hive Bug)。所以这个 Hive 按经验转换成如下所示:
SELECT * FROM (SELECT * FROM t1 UNION ALL SELECT * FROM t2)t3 GROUP BY c1,c2,c3
- 1
调优结果:经过测试,并未出现 union all 的 Hive Bug,数据是一致的。MapReduce 的 作业数由 3 减少到 1。
t1 相当于一个目录,t2 相当于一个目录,对 Map/Reduce 程序来说,t1,t2 可以作为 Map/Reduce 作业的 mutli inputs。这可以通过一个 Map/Reduce 来解决这个问题。Hadoop 的 计算框架,不怕数据多,就怕作业数多。
但如果换成是其他计算平台如 Oracle,那就不一定了,因为把大的输入拆成两个输入, 分别排序汇总后 merge(假如两个子排序是并行的话),是有可能性能更优的(比如希尔排 序比冒泡排序的性能更优)。
- 消灭子查询内的 COUNT(DISTINCT),MAX,MIN。
SELECT * FROM
(SELECT * FROM t1
UNION ALL SELECT c1,c2,c3 COUNT(DISTINCT c4) FROM t2 GROUP BY c1,c2,c3) t3
GROUP BY c1,c2,c3;
- 1
- 2
- 3
- 4
由于子查询里头有 COUNT(DISTINCT)操作,直接去 GROUP BY 将达不到业务目标。这时采用 临时表消灭 COUNT(DISTINCT)作业不但能解决倾斜问题,还能有效减少 jobs。
INSERT t4 SELECT c1,c2,c3,c4 FROM t2 GROUP BY c1,c2,c3;
SELECT c1,c2,c3,SUM(income),SUM(uv) FROM
(SELECT c1,c2,c3,income,0 AS uv FROM t1
UNION ALL
SELECT c1,c2,c3,0 AS income,1 AS uv FROM t2) t3
GROUP BY c1,c2,c3;
- 1
- 2
- 3
- 4
- 5
- 6
job 数是 2,减少一半,而且两次 Map/Reduce 比 COUNT(DISTINCT)效率更高。
调优结果:千万级别的类目表,member 表,与 10 亿级得商品表关联。原先 1963s 的任务经过调整,1152s 即完成。
- 消灭子查询内的 JOIN
SELECT * FROM
(SELECT * FROM t1 UNION ALL SELECT * FROM t4 UNION ALL SELECT * FROM t2 JOIN t3 ON t2.id=t3.id) x
GROUP BY c1,c2;
- 1
- 2
- 3
上面代码运行会有 5 个 jobs。加入先 JOIN 生存临时表的话 t5,然后 UNION ALL,会变成 2 个 jobs。
INSERT OVERWRITE TABLE t5
SELECT * FROM t2 JOIN t3 ON t2.id=t3.id;
SELECT * FROM (t1 UNION ALL t4 UNION ALL t5);
- 1
- 2
- 3
调优结果显示:针对千万级别的广告位表,由原先 5 个 Job 共 15 分钟,分解为 2 个 job 一个 8-10 分钟,一个3分钟。
6.4.6 GROUP BY替代COUNT(DISTINCT)达到优化效果
计算 uv 的时候,经常会用到 COUNT(DISTINCT),但在数据比较倾斜的时候 COUNT(DISTINCT) 会比较慢。这时可以尝试用 GROUP BY 改写代码计算 uv。
- 原有代码
INSERT OVERWRITE TABLE s_dw_tanx_adzone_uv PARTITION (ds=20120329)SELECT 20120329 AS thedate,adzoneid,COUNT(DISTINCT acookie) AS uv FROM s_ods_log_tanx_pv t WHERE t.ds=20120329 GROUP BY adzoneid
- 1
关于COUNT(DISTINCT)的数据倾斜问题不能一概而论,要依情况而定,下面是我测试的一组数据:
测试数据:169857条
#统计每日IP
CREATE TABLE ip_2014_12_29 AS SELECT COUNT(DISTINCT ip) AS IP FROM logdfs WHERE logdate=’2014_12_29′;
- 1
- 2
耗时:24.805 seconds
#统计每日IP(改造)
CREATE TABLE ip_2014_12_29 AS SELECT COUNT(1) AS IP FROM (SELECT DISTINCT ip from logdfs WHERE logdate=’2014_12_29′) tmp;
- 1
- 2
耗时:46.833 seconds
测试结果表名:明显改造后的语句比之前耗时,这是因为改造后的语句有2个SELECT,多了一个job,这样在数据量小的时候,数据不会存在倾斜问题。
6.5 空key问题
- 谓词下推
在做join操作的时候,如果本身数据存在null值,那么联表时会造成很多非必要的链表操作,此时我们可以在联表前做空key的过滤操作
select * from A a where 过滤条件
select * from B a where 过滤条件
select * from (select * from A a where 过滤条件) a left join (select * from B b 过滤条件) b on 连接条件
- 1
- 2
- 3
- 4
- 加盐操作
针对null值的待连接的表数据,有时候它本身的存在是有意义的,这时候不应该被过滤掉,可以考虑加盐操作,加盐还有个好处,就是防止数据在reduce端造成倾斜的情况
SELECT a.*
FROM Table1 a
LEFT JOIN Table2 b ON CASE WHEN a.id IS NULL THEN concat('table1', rand()) ELSE a.id END = b.id;
- 1
- 2
- 3
6.6 去重
- distinct: 注意,在Hive中distinct必须只有一个reduce才能完成整体的去重,效率极低,千万不要用
- group by
- row_number() over():生产环境使用
select distinct * from 表;
select sid,sname,sbirth,ssex from student2 group by sid,sname,sbirth,ssex;
with t as (
select
*,
row_number() over (partition by sid ) rk
from student2
)
select * from t where rk = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6.7 优化总结
优化时,把hive sql当做mapreduce程序来读,会有意想不到的惊喜。理解hadoop的核心能力,是hive优化的根本。这是这一年来,项目组所有成员宝贵的经验总结。
- 长期观察hadoop处理数据的过程,有几个显著的特征:
- 不怕数据多,就怕数据倾斜。
- 对jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,没半小时是跑不完的。map reduce作业初始化的时间是比较长的。
- 对sum,count来说,不存在数据倾斜问题。
- 对count(distinct ),效率较低,数据量一多,准出问题,如果是多count(distinct )效率更低。
- 优化可以从几个方面着手:
- 好的模型设计事半功倍。
- 解决数据倾斜问题。
- 减少job数。
- 设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。
- 自己动手写sql解决数据倾斜问题是个不错的选择。set hive.groupby.skewindata=true;这是通用的算法优化,但算法优化总是漠视业务,习惯性提供通用的解决方法。Etl开发人员更了解业务,更了解数据,所以通过业务逻辑解决倾斜的方法往往更精确,更有效。
- 对count(distinct)采取漠视的方法,尤其数据大的时候很容易产生倾斜问题,不抱侥幸心理。自己动手,丰衣足食。
- 对小文件进行合并,是行至有效的提高调度效率的方法,假如我们的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的影响。
优化时把握整体,单个作业最优不如整体最优。
6.8 优化的常用手段
主要由三个属性来决定:
- hive.exec.reducers.bytes.per.reducer #这个参数控制一个job会有多少个reducer来处理,依据的是输入文件的总大小。默认1GB。
- hive.exec.reducers.max #这个参数控制最大的reducer的数量, 如果 input / bytes per reduce > max 则会启动这个参数所指定的reduce个数。 这个并不会影响mapre.reduce.tasks参数的设置。默认的max是999。
- mapred.reduce.tasks #这个参数如果指定了,hive就不会用它的estimation函数来自动计算reduce的个数,而是用这个参数来启动reducer。默认是-1。
6.8.1参数设置的影响
如果reduce太少:如果数据量很大,会导致这个reduce异常的慢,从而导致这个任务不能结束,也有可能会OOM、如果reduce太多: 产生的小文件太多,合并起来代价太高,namenode的内存占用也会增大。如果我们不指定mapred.reduce.tasks,hive会自动计算需要多少个reducer。
7 Hive整合HBase
7.1 数据实时写Hbase,实现在Hive中用sql查询
以下操作的 Hive版本:2.3.6 ,HBase版本:2.0.4
- 1
-
在HBase中创建表:t_hbase_stu_info
create 't_hbase_stu_info','st1'- 1
-
在Hive中创建外部表:t_hive_stu_info
create external table t_hive_stu_info (id int,name string,age int,sex string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,st1:name,st1:age,st1:sex") tblproperties("hbase.table.name"="t_hbase_stu_info");- 1
- 2
- 3
- 4
- 5
-
在Hbase中给t_hbase_stu_info插入数据
put 't_hbase_stu_info','1001','st1:name','zs' put 't_hbase_stu_info','1001','st1:age','23' put 't_hbase_stu_info','1001','st1:sex','man' put 't_hbase_stu_info','1002','st1:name','ls' put 't_hbase_stu_info','1002','st1:age','56' put 't_hbase_stu_info','1002','st1:sex','woman'- 1
- 2
- 3
- 4
- 5
- 6
-
查看Hbase中的数据
scan 't_hbase_stu_info'- 1

-
查看Hive中的数据
select * from t_hive_stu_info;- 1


